大家好! 最近发现了Rust语言。 他在上一篇文章中分享了他的第一印象。 现在,我决定更深入地进行研究,为此,您需要的是比清单更严重的东西。 我的选择落在了默克尔树上。 在本文中,我想要:
- 谈论这个数据结构
- 看看Rust已经有什么
- 提供您的实施
- 比较效果
默克尔树
这是一个相对简单的数据结构,并且在Internet上已经有很多有关它的信息,但是我认为我的文章如果没有对树的描述,将是不完整的。
有什么问题
Merkle树是在1979年发明的,但是由于区块链的缘故,它得到了普及。 网络中的区块链非常大(对于比特币,它超过200 GB),并且并非所有节点都可以将其抽出。 例如,电话或收银机。 但是,他们需要知道在该块中包含该事务或该事务的事实。 为此,发明了协议SPV-简化付款验证 。
一棵树如何运作
这是一棵二叉树,其叶子是任何对象的哈希。 为了建立下一个级别,将成对的相邻叶子的哈希值成对进行连接,并计算来自连接结果的哈希,如标题中的图片所示。 因此,树的根是所有叶子的散列。 如果删除或添加元素,则根将更改。
一棵树如何工作?
有了默克尔树,您可以建立将交易包含在块中的证据,作为从交易哈希到根的路径。 例如,我们对事务Tx2感兴趣,因为它的证明将是(Hash3,Hash01)。 此机制也用于SPV。 客户端仅下载带有其散列的块标题。 进行了感兴趣的交易后,他向包含整个链的节点请求证明。 然后进行检查,对于Tx2,它将为:
hash(Hash01, hash(Hash2, Hash3)) = Root Hash
将结果与块头的根进行比较。 这种方法不可能伪造证据,因为在这种情况下,测试结果不会与标头的内容收敛。
哪些实现已经存在
Rust是一门年轻的语言,但是Merkle树的许多实现已经写在上面。 由Github判断,目前56岁,这比C和C ++的总和还多。 尽管Go使它们具有80种实现方式。
为了进行比较,我根据存储库中的星数选择了此实现。
该树以最明显的方式构造,即它是对象的图。 正如我已经指出的,这种方法并不完全对Rust友好。 例如,不可能从孩子到父母进行双向通信。
证据的构建是通过深入研究而实现的。 如果找到具有正确哈希值的工作表,则将得到结果的路径。
有什么可以改善的
对我来说,做一个简单的(n + 1)实现并不有趣,所以我想到了优化。 我的vector-merkle-tree的代码在Github上 。
资料储存
首先想到的是将树移动到数组。 就数据局部性而言,此解决方案会更好:更多的缓存命中率和更好的预加载。 在内存中分散的对象周围走动需要更长的时间。 一个方便的事实是,所有散列的长度相同,因为 由一种算法计算。 数组中的Merkle树将如下所示:

证明
初始化树时,可以创建具有所有叶索引的HashMap。 因此,当没有叶子时,您不需要遍历整棵树,如果有叶子,则可以立即转到它并升至根,构建证明。 在我的实现中,我将HashMap设置为可选。
串联和散列
看来这里可以改进吗? 毕竟,一切都很清楚-取两个哈希值,将它们粘合起来并计算一个新的哈希值。 但是事实是该函数是不可交换的,即 哈希(H0,H1)≠哈希(H1,H0)。 因此,在构造证明时,您需要记住相邻节点位于哪一侧。 这使算法更难以实现,并增加了存储冗余数据的需求。 一切都很容易修复,只需在哈希之前对两个节点进行排序。 例如,我引用了Tx2,并考虑了可交换性,检查将如下所示:
hash(hash(Hash2, Hash3), Hash01) = Root Hash
当您不必担心顺序时,验证算法看起来就像是数组的简单卷积:
pub fn validate(&self, proof: &Vec<&[u8]>) -> bool { proof[2..].iter() .fold( get_pair_hash(proof[0], proof[1], self.algo), |a, b| get_pair_hash(a.as_ref(), b, self.algo) ).as_ref() == self.get_root() }
零元素是所需对象的哈希,第一个是其邻居。
走吧
如果不进行性能比较,那么故事将是不完整的,这使我花了比树本身实现多几倍的时间。 为此,我使用了标准框架。 测试本身的来源在这里 。 所有测试都是通过TreeWrapper接口进行的,这两个主题均已实现:
pub trait TreeWrapper<V> { fn create(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); fn find(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); fn validate(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); }
两棵树都使用相同的环密码。 在这里,我将不比较不同的库。 我选了最普通的。
作为哈希对象,使用随机生成的字符串。 在各种长度的数组上比较树:(500,1000,1500,2000,2500 3000)。 2500-3000是目前比特币区块中的大概交易数量。
在所有图形上,X轴表示数组元素的数量(或块中事务的数量),Y轴表示完成操作的平均时间(以微秒为单位)。 即,越差。
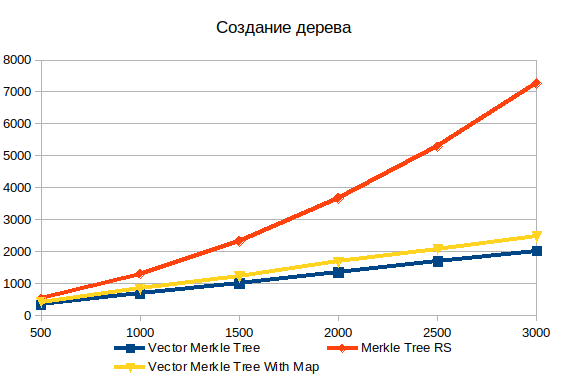
造树
所有树数据在一个阵列中的存储大大超过了对象的性能图。 对于具有500个元素的数组,是1.5倍,而对于3000个元素,则已经是3.6倍。 在标准实现中,复杂度对输入数据量的依赖性具有非线性特性。
另外,相比之下,我添加了向量树的两个变体:有和没有HashMap 。 填充其他数据结构会增加大约20%的空间,但是它使您在建立证据时可以更快地搜索对象。
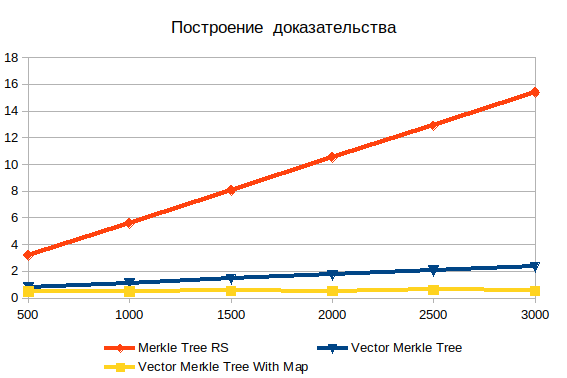
建立证据
在这里,您可以看到深度搜索的明显效率低下。 随着输入的增加,它只会变得更糟。 重要的是要了解您要查找的对象是工作表,因此不会有log(n)复杂性。 如果对数据进行预哈希处理,则操作时间实际上与元素数量无关。 如果不进行散列,复杂度将线性增长,并且涉及蛮力搜索。
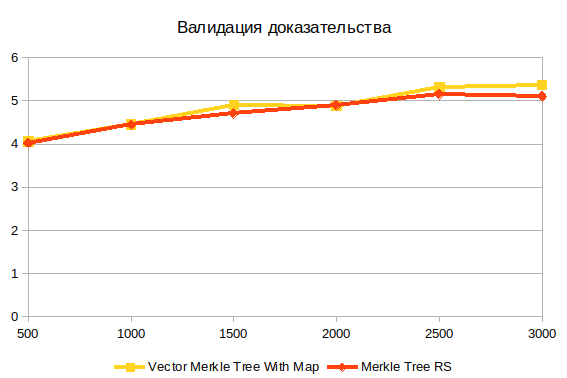
证据验证
这是最后的操作。 它不依赖于树的结构,因为 结合构造证据的结果。 我相信这里的主要困难是哈希计算。
总结
- 数据的存储方式极大地影响了性能。 当一个阵列中的所有内容都快得多时。 序列化这样的结构将非常简单。 代码的总量也减少了。
- 通过排序将节点连接在一起可以极大地简化代码,但并不能使其更快。
关于Rust的一点
- 喜欢标准框架。 平均值和带有图表的偏差给出了清晰的结果。 能够比较同一代码的不同实现。
- 缺乏继承不会极大地影响生活。
- 宏是一种强大的机制。 我在树测试中使用它们进行参数化。 我认为,如果使用不当,您可以做的事情自己以后不会满意。
- 在某些地方,编译器无聊其内存检查。 我最初的假设是开始用Rust编写东西根本行不通,这是正确的。
参考文献