
5月14日,当特朗普准备向华为发射所有狗时,我在深圳举行的华为STW 2019和平会议上-一次有1000人参加的大型会议-其中包括台积电(TSMC)副总裁
Philip Wong关于非冯·诺依曼计算前景的报告架构,以及华为研究员,华为2012实验室首席科学家廖恒(Heng Liao)就张量处理器和神经处理器的新架构的开发进行了研究。 如果您知道的话,台积电使用7纳米技术(
很少有人拥有 )为苹果和华为制造神经加速器,而华为准备在神经处理器方面与Google和NVIDIA竞争。
在中国,谷歌被禁止使用,我没有费心在平板电脑上放置VPN,因此我
爱国使用Yandex,以查看其他类似铁制造商的情况以及一般情况。 总的来说,我看着这种情况,但是只有在这些报告之后,我才意识到公司的肠胃正准备进行一场大规模的革命,而科学室的寂静也正在酝酿之中。
仅去年一年,在该主题上的投资就超过30亿美元。 谷歌早就宣布神经网络为战略领域,正在积极建立其硬件和软件支持。 NVIDIA感觉到宝座是惊人的,正在神经网络加速库和新硬件方面做出巨大的努力。 英特尔在2016年斥资8亿美元收购了两家涉及神经网络硬件加速的公司。 尽管主要购买尚未开始,而且玩家数量已超过50,并且还在迅速增长,但事实并非如此。
TPU,VPU,IPU,DPU,NPU,RPU,NNP-这一切意味着什么,谁将赢得胜利? 让我们尝试找出答案。 谁在乎-欢迎来到猫!
免责声明:作者必须完全重写视频处理算法,才能在ASIC上有效实现,并且客户在FPGA上进行了原型设计,因此对架构差异的深度有一个想法。 但是,作者最近没有直接与铁工作。 但他预计他将不得不深入研究。
问题背景
所需计算的数量正在迅速增长,人们希望采用更多的层,更多的架构选择,更积极地使用超参数,但是……这取决于性能。 同时,例如,随着优质旧处理器生产率的提高,这是一个大问题。 万事俱备:众所周知,摩尔定律即将耗尽,处理器性能增长率下降:
与VAX11-780相比,在SPECint上整数运算的实际性能的计算,此后通常为对数标度如果从80年代中期到2000年代中期(在计算机鼎盛时期),每年的平均增长率为52%,但近年来却下降到了每年3%。 这是一个问题(牧师约翰·轩尼诗(John Hennessey)最近发表的一篇有关现代建筑的问题和前景的文章的翻译
是在哈布雷(Habré )
上进行的 )。
有很多原因,例如,处理器的频率停止增长:
减小晶体管的尺寸变得更加困难。 严重降低生产率(包括已经发布的CPU的性能)的最后一个不幸是(鼓声)……对,安全。
Meltdown ,
Spectre和
其他 漏洞对CPU处理能力的增长速度造成了极大的损害(
禁用超线程 (!)
的示例 )。 这个话题变得很流行,
几乎每月都会发现这种新的漏洞。 这是一场噩梦,因为它会损害性能。
同时,许多算法的开发与处理器能力的增长紧密相关。 例如,当今许多研究人员并不担心算法的速度-他们会提出一些建议。 学习时会很好-网络变得庞大且难以使用。 这在视频中尤其明显,原则上大多数方法不适用于高速。 而且它们通常只有实时才有意义。 这也是一个问题。
同样,正在开发新的压缩标准,这暗示着解码器功率的增加。 如果处理器能力没有提高? 老一辈人记得在2000年代,在当时较新的
H.264电脑上播放高清视频时出现了问题。 是的,使用较小的尺寸质量会更好,但是在快速场景中,图片会挂起或声音被撕裂。 我必须与新的
VVC / H.266 (计划于明年发布)的开发人员进行交流。 您不会羡慕他们的。
那么,鉴于应用于神经网络的处理器性能增长率的下降,未来的世纪对我们有什么准备?
中央处理器
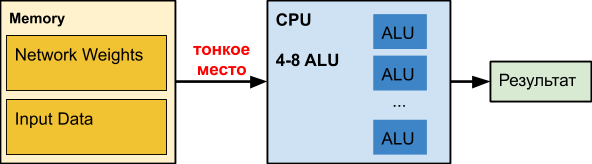
常规的
CPU是经过数十年完善的众多破碎机。 las,其他任务。
当我们使用神经网络(尤其是深度神经网络)时,我们的网络本身可能占据数百兆字节。 例如,
对象检测网络的内存需求如下:
根据我们的经验,用于处理
半透明边界的深层神经网络的系数可以占用150-200 MB。 神经网络中的同事确定年龄和性别的大小系数约为50 MB。 并且在针对移动版本的降低精度的优化过程中-大约25 MB(float32⇒float16)。
同时,根据数据大小访问存储器时的延迟图
大致如下分布(水平标度是对数的):
即 如果数据量增加超过16 MB,则延迟将增加50倍或更多,这将严重影响性能。 实际上,大多数时候,CPU在使用深度神经网络时都会
愚蠢地等待数据。
英特尔关于各种网络加速
的数据很有趣,实际上,加速仅在网络变小(例如,由于权重量化的结果)时才发生,以便至少部分地与处理后的数据一起进入缓存。 请注意,现代CPU的缓存最多消耗处理器能量的一半。 在重型神经网络的情况下,它是无效的,并且无法合理地使用昂贵的加热器。
对于神经网络在CPU上的依附者根据我们的内部测试,即使在许多网络体系结构(尤其是在带宽对于单线程模式下的实时数据处理很重要的简单体系结构)上,甚至
Intel OpenVINO都失去了矩阵乘法+ NNPACK框架的实现。 这种情况与图像中对象的各种分类器有关(神经网络需要运行大量次-就图像中的对象数量而言为50–100),并且启动OpenVINO的开销会变得过高。
优点:- “每个人都拥有”,通常是闲置的,即 计费和实施的入门价格相对较低。
- 同事们称,有单独的非CV网络非常适合CPU,同事们称其为Wide&Deep和GNMT。
减号:- 当使用深度神经网络时(当网络层数和输入数据的大小很大时),CPU效率很低,一切工作都非常缓慢。
显卡

该主题众所周知,因此我们简要概述了主要内容。 对于神经网络,
GPU在大规模并行任务中具有显着的性能优势:
请注意如何对72核
Xeon Phi 7290进行退火,而“蓝色”也是服务器Xeon,即 英特尔不会轻易放弃,这将在下面进行讨论。 但更重要的是,视频卡的存储最初设计为要高出约5倍的性能。 在神经网络中,使用数据进行计算非常简单。 一些基本操作,我们需要新数据。 结果,数据访问速度对于神经网络的有效运行至关重要。 GPU上的“高速”内存和比CPU上更灵活的缓存管理系统可以解决此问题:
蒂姆·德特默斯(Tim Detmers)多年来一直在支持有趣的评论
“哪些GPU可以用于深度学习:我在深度学习中使用GPU的经验和建议” 。 显然,特斯拉和泰坦统治训练,尽管架构上的差异会引起有趣的爆发,例如在递归神经网络的情况下(领导者通常是TPU,请留意未来):
但是,对于美元来说,有一个非常有用的性能图表,当然,如果您有足够的内存,在
RTX上 (可能是由于
它们的 Tensor核心 ),美元:
当然,计算成本很重要。 排名第一的第二名和第二名的最后一个
-Tesla V100的售价为70万卢布,就像10台“普通”计算机一样(如果要在多个节点上进行训练,则需要昂贵的Infiniband交换机)。 真正的V100可以使用十个。 人们愿意为实际的学习加速付出高昂的代价。
总计,总结!
优点:- 基数-是CPU的10-100倍-加速。
- 对训练极为有效(但使用效果较差)。
减号:- 高端视频卡(具有足够的内存来训练大型网络)的成本超过了其余计算机的成本...
现场可编程门阵列
 FPGA
FPGA已经变得更加有趣。 这是一个由数百万个可编程块组成的网络,我们也可以通过编程方式进行互连。 网络和块
看起来像这样(瓶颈是瓶颈,请注意,再次位于芯片内存的前面,但是更容易,这将在下面进行描述):
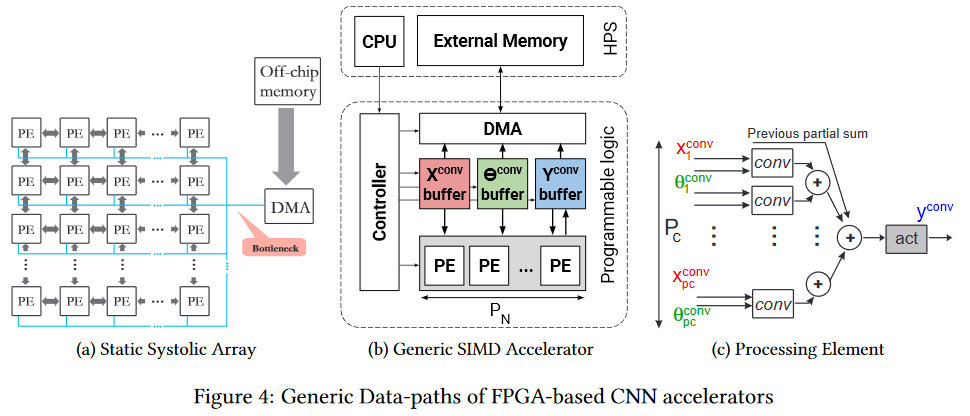
自然,在使用神经网络的阶段就已经使用FPGA是有意义的(在大多数情况下,没有足够的内存用于训练)。 而且,FPGA上的执行主题现已开始积极发展。 例如,这里是
fpgaConvNet框架 ,该
框架可以显着加速CNN在FPGA上的使用并降低功耗。
FPGA的关键优势在于我们可以将网络直接存储在单元中,即 每秒以相同方向每秒传输25次(对于视频)的数百兆字节相同数据形式的稀疏点神奇地消失了。 这允许较低的时钟速度和高速缓存的存在,而不是较低的性能,以获得明显的提高。 是的,并且可以大大降低每单位计算量的
全球变暖能耗。
英特尔积极参与了这一进程,并于
去年在开源中发布了
OpenVINO Toolkit ,其中包括
Deep Learning Deployment Toolkit (
OpenCV的一部分)。 此外,在不同网格上的FPGA上的性能看起来非常有趣,并且与GPU(尽管Intel集成GPU)相比,FPGA的优势非常明显:
尤其是温暖作者灵魂的是-比较FPS,即 每秒帧数是视频的最实用指标。 鉴于英特尔在2015年收购了FPGA市场第二大厂商
Altera ,该图表为我们提供了深思熟虑的参考。
而且,显然,此类架构的入门门槛更高,因此必须经过一段时间才能出现方便的工具,以有效地考虑根本不同的FPGA架构。 但是低估技术潜力是不值得的。 她绣了许多薄薄的地方。
最后,我们强调对
FPGA进行
编程是另一回事。 因此,该程序不在此处执行,并且所有计算都是根据数据流,流延迟(影响性能)和使用的门(始终缺乏)进行的。 因此,为了开始有效的编程,您需要彻底
更改自己的固件 (在您的耳朵之间的神经网络中)。 效率很高,根本无法获得。 但是,新框架很快将使研究人员看不到外部差异。
优点:- 可能更快地执行网络。
- 与CPU和GPU相比,功耗大大降低(这对于移动解决方案尤为重要)。
缺点:- 大多数情况下,它们有助于加快执行速度;与GPU不同,对其进行培训明显较不方便。
- 与以前的选项相比,编程更加复杂。
- 专家数量明显减少。
专用集成电路

接下来是
ASIC ,它是
专用集成电路 (即
专用集成电路 )的缩写。 集成电路来完成我们的任务。 例如,实现放置在铁中的神经网络。 但是,大多数计算节点可以并行工作。 实际上,只有数据依赖和网络不同级别的计算不均衡才能阻止我们不断使用所有工作的ALU。
近年来,也许加密货币挖矿已经在公众中成为最大的ASIC广告。 刚开始时,在CPU上进行挖掘是非常有利可图的,后来我不得不购买GPU,然后是FPGA,然后再购买专用的ASIC,因为人们(阅读市场)已经成熟,可以使他们的生产开始获利的订单。
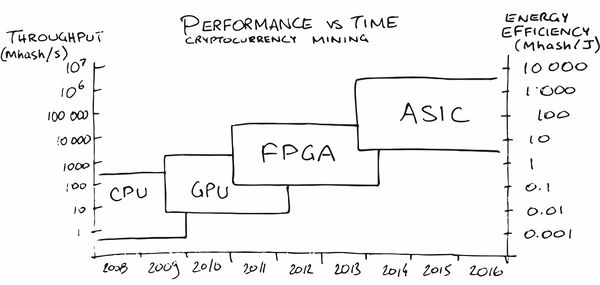
在我们地区,
服务也已经出现(自然!),
这有助于在铁上放置神经网络,该网络具有能耗,FPS和价格的必要特征。 神奇地同意!
但是! 我们正在失去网络定制。 而且,当然,人们也会考虑这一点。 例如,这里有一篇文章,上面写着:“
可重新配置的架构可以胜过ASIC作为CNN加速器吗? ”(“可配置的架构可以胜过ASIC像CNN加速器吗?”)。 关于这个主题的工作已经足够,因为这个问题不是闲着的。 ASIC的主要缺点是在将网络驱动到硬件中之后,我们很难对其进行更改。 当我们已经需要一个运行良好的网络以及数百万个具有低功耗和高性能的芯片的网络时,它们是最有益的。 例如,这种情况正在自动驾驶汽车市场中逐渐发展。 或在监控摄像机中。 或在机器人真空吸尘器的腔室内。 或放在家用冰箱的隔间中。 或在咖啡壶室中。
或在铁室中。 好吧,
简而言之 ,您了解这个想法!
重要的是,在批量生产中,芯片要便宜,能快速工作并消耗最少的能量。
优点:- 与所有以前的解决方案相比,芯片成本最低。
- 单位操作的最低功耗。
- 相当高的速度(如果需要,包括记录)。
缺点:- 更新网络和逻辑的能力非常有限。
- 与所有以前的解决方案相比,开发成本最高。
- 使用ASIC主要在大批量运行时具有成本效益。
热塑性聚氨酯
回想一下,在使用网络时,有两个任务-训练和执行(推理)。 如果FPGA / ASIC主要专注于加快执行速度(包括某些固定网络),那么TPU(张量处理单元或张量处理器)要么是基于硬件的学习加速,要么是任意网络的相对通用的加速。 这个名字很漂亮,可以接受,尽管事实上,仍在使用连接到高带宽内存(HBM)的带有混合乘法单元(MXU)的2级
张量 。 以下是TPU Google第2和第3版的架构图:
TPU Google
总体而言,谷歌为TPU名称做广告,揭示了2017年的内部发展:
他们早在2006年就开始使用神经网络专用处理器进行初步工作,2013年他们创建了一个资金充裕的项目,2015年开始使用首批对神经网络有很大帮助的Google Translate云服务等芯片。 我们强调,这
就是网络的加速。 数据中心的一个重要优势是,与CPU相比,TPU的能效提高了两个数量级(TPU v1的图形):
同样,通常,与GPU相比,网络
性能要好10-30倍:
差异甚至是10倍。 显然,与GPU的差异在20-30倍之间决定了这个方向的发展。
而且,幸运的是,谷歌并不孤单。
TPU华为
如今,饱受苦难的华为也于几年前以华为Ascend的名义开始开发TPU,并同时推出了两个版本-用于数据中心(例如Google)和移动设备(谷歌最近也开始这样做)。 如果您相信华为的资料,他们会以FP16 2.5倍和NVIDIA V100 2倍取代新的Google TPU v3:

与往常一样,这是一个很好的问题:该芯片在实际任务中的表现如何。 如您所见,图中的峰值性能。 此外,Google TPU v3在许多方面都很出色,因为它可以在1024个处理器的集群中有效地工作。 华为还宣布了Ascend 910的服务器群集,但没有详细信息。 总的来说,华为工程师在过去的十年中表现出了自己的才能,并且很有可能使用与Google TPU v3相比2.8倍的峰值性能,并结合最新的7纳米制程技术。
内存和数据总线对于性能至关重要,幻灯片显示了对这些组件的关注(包括与内存的通信速度比GPU快得多):
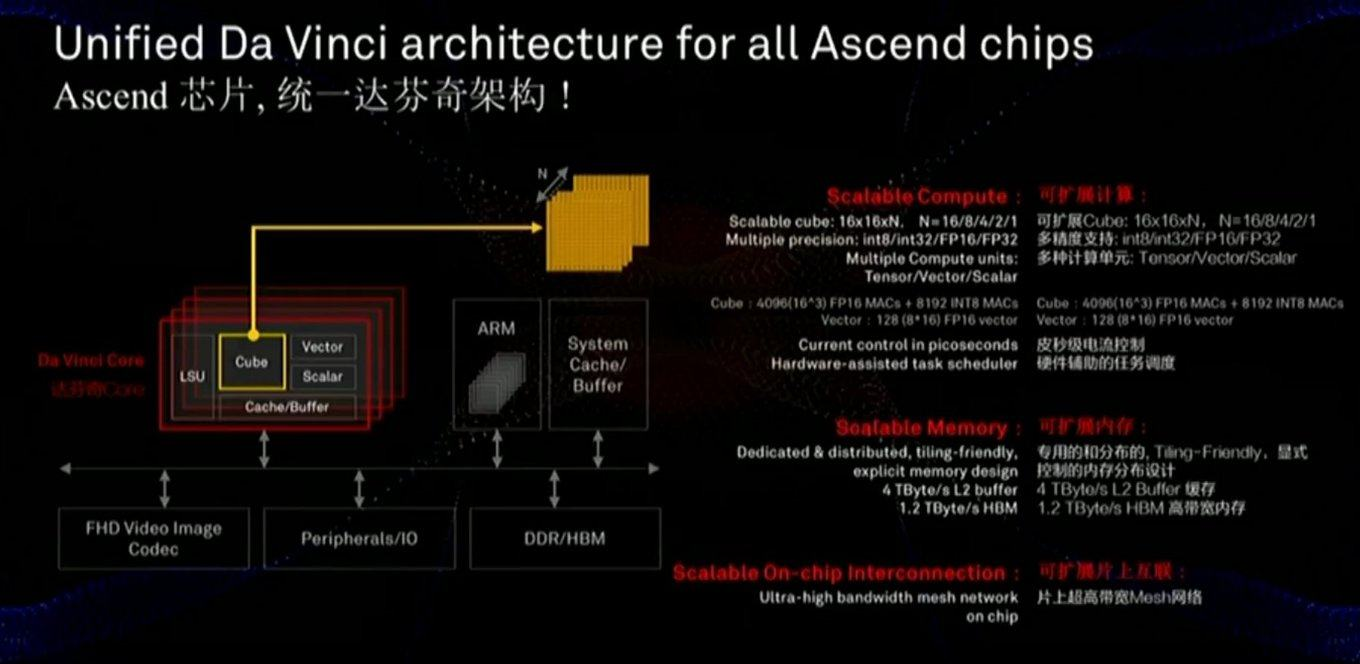
该芯片还使用略有不同的方法-不是二维MXU 128x128标度,而是在尺寸较小的16x16xN的三维立方体中进行计算,其中N = {16.8,4,2,1}。 因此,关键的问题是它在特定网络的真实加速方面的性能如何(例如,立方体中的计算对于图像来说很方便)。 另外,对幻灯片的仔细研究表明,与Google不同,该芯片可立即将压缩的FullHD视频与视频合并。 对于作者来说,这听起来
非常令人鼓舞!
如上所述,同一行中,针对移动设备开发了处理器,对于这些设备而言,能源效率至关重要,并且主要在其上运行网络(即,分别是用于云学习的处理器和单独用于执行的处理器): 使用此参数,一切至少与NVIDIA相比,它看起来不错(请注意,它们没有与Google进行比较,但是Google并未提供云TPU)。他们的移动芯片将与苹果,谷歌和其他公司的处理器竞争,但是现在要在这里进行库存还为时过早。很明显,新的Nano,Tiny和Lite芯片应该更好。很清楚
使用此参数,一切至少与NVIDIA相比,它看起来不错(请注意,它们没有与Google进行比较,但是Google并未提供云TPU)。他们的移动芯片将与苹果,谷歌和其他公司的处理器竞争,但是现在要在这里进行库存还为时过早。很明显,新的Nano,Tiny和Lite芯片应该更好。很清楚为什么特朗普害怕 为什么许多制造商正在仔细研究华为的成功(在收入方面,华为的表现超过了所有美国钢铁公司,包括英特尔在内)。模拟深度网络
如您所知,当旧的和被遗忘的方法在新一轮中变得重要时,技术通常会螺旋式发展。类似的事情很可能发生在神经网络上。您可能已经听说过,一旦通过电子管和晶体管进行了乘法和加法运算(例如,直到90年代中期,彩色空间的转换(矩阵的典型乘法)就出现在每台彩色电视中)?提出了一个很好的问题:如果我们的神经网络相对抵抗内部的不准确计算,那么如果将这些计算转换为模拟形式该怎么办?我们立即获得了显着的计算加速,并且一次操作的能耗可能大大降低:通过这种方法,可以快速,高效地计算DNN(深度神经网络)。但是有一个问题-这些是DAC / ADC(DAC / ADC)-从数字到模拟,反之亦然的转换器,会降低能效和过程精度。但是,早在2017年,IBM Research就提出了用于RPU(电阻处理单元)的模拟CMOS,它允许您以模拟形式存储处理后的数据,并显着提高了该方法的整体效率:此外,除了模拟内存外,降低神经网络的准确性也可以提供极大帮助-这是使RPU小型化的关键,这意味着增加芯片上的计算单元数量。在这里,IBM也是一个领导者,特别是在今年最近,他们非常成功地将网络的粗略度提高到2位精度,并将精度提高到1位(在培训期间为2位),这将使效率提高100倍!现代GPU:现在详细讨论模拟神经芯片还为时过早,因为尽管所有这些都在早期原型的水平上进行了测试:但是,模拟计算的潜在方向看起来
非常有趣。
唯一令人困惑的是它是IBM,
它已经为此
主题申请了数十项专利 。 根据经验,由于公司文化的特殊性,它们与其他公司的合作相对较弱,并且拥有某些技术可能会减慢其发展速度,而不是有效地共享它。 例如,IBM一次拒绝将JPEG的算术压缩许可给
ISO委员会,尽管事实上标准草案是算术压缩的一种选择。 结果,JPEG通过霍夫曼压缩变得栩栩如生,并且刺痛了10-15%。 视频压缩标准也是如此。 而且只有在12年后有5项IBM专利到期时,该行业才大规模转向编解码器中的算术压缩。希望我们这次能够更倾向于合作,因此,我们
希望与该公司无关的所有人在该领域取得最大的成功。 ,
这样的人和公司的利益
是很多的 。
如果解决了,
那将是神经网络使用的一场革命,也是计算机科学许多领域的一场革命。杂项其他字母
总体而言,加速神经网络的话题已成为时尚,所有主要公司和数十家初创公司都参与其中,到2018年初,
其中至少有5家吸引了超过1亿美元的投资。 2017年,总共向与芯片开发相关的初创公司投资了15亿美元。 尽管投资者已经有15年没有注意到芯片制造商的事实了(因为在巨头的背景下没有什么可以抓住的)。 总的来说-现在确实有进行小规模铁革命的机会。 而且,很难预测哪种架构将获胜,革命的需求已经成熟,提高生产率的可能性很大。 经典的革命形势已经成熟:
摩尔不再可以,
迪恩还没有准备好。
好吧,由于最重要的市场法则-有所不同,因此有很多新的字母,例如:
- 神经处理单元( NPU ) -神经处理器 ,有时是精美的-神经形态芯片-一般而言,是神经网络加速器的总称,被称为Samsung , Huawei等芯片,并在列表中进一步列出...
在本节的以下部分,将主要以公司介绍幻灯片的形式给出技术自名的示例
显然,直接比较是有问题的,但是这里有一些有趣的数据,将芯片与苹果和华为的神经处理器进行了比较,这些芯片最初由台积电生产。 可以看出,竞争很艰难,新一代显示出2到8倍的生产率提高和技术流程的复杂性:
- 神经网络处理器(NNP) -神经网络处理器。
这就是其芯片家族的名称,例如英特尔 (最初是Nervana Systems公司 ,英特尔于2016年以400美元+百万美元的价格收购了该公司)。 但是,在文章和书籍中, NNP 的名称也很常见。
- 智能处理单元(IPU) -智能处理器-Graphcore推广的芯片名称(顺便说一句,该芯片已经获得了3.1亿美元的投资)。
它生产用于计算机的特殊卡,但专门用于训练神经网络,其RNN训练性能比NVIDIA P100高180-240倍。
- 数据流处理单元(DPU) -数据处理处理器-由WAVE Computing推广,该公司已经获得了2.03亿美元的投资。 它产生与Graphcore相同的加速器:
由于他们的收入减少了1亿,因此他们宣布培训速度仅比在GPU上快25倍以上(尽管他们保证很快就会提高1000倍)。 让我们来看看...
- 视觉处理单元( VPU ) -计算机视觉处理器:
该术语用于多家公司的产品,例如Movidius的Myriad X VPU (也于2016年被Intel收购 )。
- IBM的竞争对手之一(我们还记得使用术语RPU ) -Mythic-正在移动Analog DNN ,后者还将网络存储在芯片中并且执行速度相对较快。 到目前为止,他们只有诺言, 尽管很认真 :
这仅列出了开发中已投资数亿美元的最大领域(这在开发铁时很重要)。
如我们所见,一般来说,所有的花都盛开得很快。 逐渐地,公司将消化数十亿美元的投资(通常需要1.5至3年的时间来生产芯片),尘埃落定,领导者将变得清晰,获胜者将像往常一样写一个故事,市场上最成功的技术的名字将被普遍接受。 这已经发生了不止一次(“ IBM PC”,“智能手机”,“施乐”等)。
关于正确比较的几句话
如上所述,正确比较神经网络的性能并不容易。 这就是Google发布图表的原因,其中TPU v1制作了NVIDIA V100。 NVIDIA看到这样的耻辱后,发布了时间表,其中Google TPU v1失去了V100。 (如此!)Google发布了以下图表,其中V100在Google TPU v2和v3上输了。 最后,华为是每个人都输掉华为Ascend的时间表,但是V100比TPU v3更好。 简而言之,马戏团。 特点是什么-
每个图表
都有自己的真实性!
这种情况的根本原因很明显:
- 您可以衡量学习速度或执行速度(以更方便为准)。
- 可以测量不同的神经网络,因为由于网络体系结构和所需数据量的不同,在特定体系结构上执行/训练不同神经网络的速度可能会显着不同。
- 您可以测量加速器的峰值性能(也许是以上所有方法中最抽象的)。
为了使这个动物园中的
事物井井有条,出现了
MLPerf测试,该测试现在具有可用的版本0.5,即 他正在开发一种比较方法,该方法计划于今年
第三季度发布到第一个版本:
由于作者是TensorFlow的主要贡献者之一,因此有机会找到最佳的培训方式并可能使用它(因为随着时间的推移,TF的移动版本很可能也包含在其中)。
最近,国际组织
IEEE出版了有关无线电电子,计算机和电气工程的世界技术文献的第三部分,
从小孩子的
脸上禁止了华为 ,但很快
取消了该禁令。 华为尚未在
当前的 MLPerf排名中排名靠前,而华为TPU则是Google TPU和NVIDIA卡的重要竞争对手(即,除了政治上的原因外,出于经济原因,坦率地说,华为也是如此)。 我们将毫无保留地关注事件的发展!
全部上天堂! 靠近云!
而且,由于它是关于培训的,因此有必要对它的细节说几句话:
- 随着对神经网络的广泛研究(具有数十层的结构,确实使每个人撕裂),必须研磨数百兆的系数,这立即使前几代的所有处理器缓存失效。 同时,经典的ImageNet 讨论了网络大小与其准确性之间的严格相关性(越高越好,越正确,网络越大,水平轴是对数):
- 神经网络内部的计算过程遵循固定方案,即 在绝大多数情况下,所有“分支”和“转换”(就上个世纪而言)都将在此处进行,因此事先就已经确切知道了,这使得推测性的指令执行无需工作,从而大大提高了生产率:
这使得堆积的超标量预测机制无法用于分支和前几十年处理器改进的预计算(不幸的是,芯片的这一部分也像DNN缓存上的DNN一样,导致了全球变暖)。
- 此外,神经网络训练在水平方向上相对较弱。 即 我们无法拥有1000台强大的计算机,而无法获得1000倍的学习加速。 甚至只有100人,我们也无法做到(至少在解决了大批量批量训练质量下降的理论问题之前)。 一般而言,我们很难在几台计算机上分发某些东西,因为一旦访问网络所在的统一内存的速度降低,其学习速度就会急剧下降。 因此,如果研究人员
可以免费访问1000台功能强大的计算机,那么他一定会很快将它们全部带走,但是最有可能的是(如果没有infiniband + RDMA),将有许多具有不同超参数的神经网络。 即 总培训时间仅比使用一台计算机少几倍。 可以处理批量的大小,继续教育以及其他新的流行技术,但是主要结论是肯定的,随着计算机数量的增加,工作效率和获得结果的可能性将增加,但不是线性的。 如今,数据科学研究员的时间非常昂贵,而且通常可以花很多车(尽管不合理)却获得加速-可以做到这一点(请参见下面的示例,其中有1、2和4辆昂贵的V100在云中)。
正是这些观点解释了为什么这么多人急于开发用于深度神经网络的专用铁的原因。 他们为什么要拿到数十亿美元。 隧道的尽头确实有可见光,不仅是Graphcore(回想起来,它加速了240倍RNN训练)。
例如,IBM Research的先生们
乐观地认为,开发特殊芯片将在5年后将计算效率提高一个数量级(而在10年后将2个数量级提高,则比该图表上的2016年水平提高了1000倍)。 ,每瓦效率,但核心功率也会增加):
所有这些都意味着铁片的出现,培训相对较快,但费用昂贵,这自然导致了在研究人员之间共享使用这种昂贵铁片的时间的想法。 今天,这个想法自然也将我们引向了云计算。 长期以来,学习向云的过渡一直在积极进行。
请注意,现在对相同模型的训练在时间上可能会因不同的云服务而有所不同。 亚马逊领先,谷歌的免费Colab排名最后。 请注意,领导者之间V100数量的结果如何变化-卡数增加了4倍(!),从蓝色到紫色的生产率提高了不到三分之一(!!!),而Google却更少:
似乎在未来几年中,差异将增长到两个数量级。 主啊! 煮钱! 我们将友好地将数十亿美元的投资返还给最成功的投资者...
简而言之
让我们尝试总结平板电脑中的关键点:
关于软件加速的几句话
公平地说,我们今天提到的主要话题是深度神经网络的执行和训练的软件加速。 主要由于所谓的网络量化,可以大大加快执行速度。 首先,也许是这样,因为使用的权重范围不是很大,并且通常可以将权重从4字节浮点值粗化为1字节整数(并且记住IBM的成功,甚至更强)。 其次,受过训练的网络作为一个整体对计算噪声具有相当的抵抗力,并且向
int8过渡的准确性会略有下降。 同时,尽管事实上操作数量甚至可以增加(由于计算时的缩放比例),但网络的大小减少了4倍,可以被视为快速向量操作,这一事实大大提高了整体执行速度。 这对于移动应用程序尤其重要,但是它也可以在云中运行(在Amazon云中加速执行的示例):
还有其他方法可以通过算法
加快网络执行速度 ,甚至还有更多方法可以
加快学习速度 。 但是,这些是单独的大主题,而这次不是。
而不是结论
投资者和作家
托尼·塞巴 (
Tony Ceba)在他的演讲中
举了一个宏伟的例子:2000年,容量为1 teraflops的1号超级计算机占地150平方米,耗资4,600万美元,消耗了850 kW:
15年后,性能达到2.3 teraflops(两倍多)的NVIDIA GPU装在手中,成本为59美元(提高了约一百万倍),消耗了15瓦特(提高了56千倍):
Google在今年3月
推出了TPU Pods ,它实际上是基于TPU v3的液冷超级计算机,其主要特点是它们可以在1024 TPU的系统中协同工作。 他们看起来非常令人印象深刻:
没有给出确切的数据,但是据说该系统可以与世界上排名前五的超级计算机相提并论。 TPU Pod可以大大提高学习神经网络的速度。 为了提高交互速度,TPU通过高速线连接成环形结构:

似乎经过15年,这种功能强大的神经
处理器也可以像
天网处理器一样适合您的手部(您
必须承认,这有点类似):
从电影《终结者2》的导演版拍摄考虑到目前深度神经网络硬件加速器的改进速度以及上面的示例,这是完全真实的。 在几年内,您将有机会选择性能与今天的TPU Pod相似的芯片。
顺便说一句,有趣的是,影片中的芯片制造商(显然是在想象自我训练网络可能会导致什么),默认情况下关闭了重新训练。 具有特色的是,
T-800本身无法启用训练模式,而只能在推理模式下工作(请参阅较长的
导演版 )。 此外,它的
神经网络处理器得到了改进,并且在重新训练时可以使用以前累积的数据来更新模型。 1991年还不错。
本文始于炎热的第13百万深圳。 我坐在这座城市的27,000辆电动出租车之一中,非常感兴趣地看着汽车的4个液晶屏。 驾驶员前面的设备中有一个很小的设备,仪表板中央的两个设备中的一个,后视镜中的最后一个设备是半透明的,与DVR,视频监控摄像头和板上的android结合在一起(从最上面的一行判断充电和与网络的通信水平)。 它显示了驾驶员数据(如果有人抱怨的话),最新的天气预报,并且似乎与出租车队有联系。 驾驶员不懂英语,也没有成功地询问他对电机的印象。 因此,他懒惰地踩了踏板,在交通拥堵的情况下使汽车略微移动。 我以一种充满未来感的眼神看着窗户-穿着夹克的中国人正从电动踏板车和单轮车的工作中开车...想知道在15年后它们的外观如何...
实际上,今天已经有了后视镜,它利用DVR摄像机的数据和
神经网络的
硬件加速来控制汽车的行驶并确定路线。 至少在下午)。 15年后,该系统显然不仅能够驾驶汽车,而且还很高兴为我提供新鲜的中国电动汽车的特性。 自然是俄语(作为一种选择:英语,中文……最后是阿尔巴尼亚语)。 这里的驾驶员是多余的,训练有素的链接。
主啊!
极其有趣的 15年正等着我们!
敬请期待!
我会回来的! )))
 UPD:
UPD:最有趣的评论:
关于FPGA上计算的量化和加速
评论@Mirn
在FPGA上,不仅可以使用任意精度的算法,而且还具有保存和处理任意位数据的重要功能。 例如,烦人的MobileNetV2 W和B中的系数太多,您可以对它们进行量化而不会损失太多的精度,只有16位,否则您将不得不重新训练。 但是,如果您查看内部并收集有关通道和层的统计信息,那么您会发现所有16位仅在前1000 W系数的输入处使用,其余的分别为8-11位,其中只有2-3个高级位和正负号非常重要,以及关于信道使用情况的统计数据,使得有许多信道通常为零或较小的值,或者几乎所有值均为8-11位的信道,即 有可能在编译时用钉子钉住参展商而不保存,即 实际上,可以在ROM存储器中存储的不是16位而是4位值,您甚至可以将整个神经网络存储在便宜的FPGA上而不会损失太多准确性(小于1%),并且处理速度高达数万个FPS,并且存在延迟,因此我们可以立即获得神经网络响应帧的接收如何结束。
关于量化:我的想法是,如果在计算W的多个阶段中,通道0的系数仅从+50变为-50,则将位压缩为7是有意义的;如果从-123压缩为+124,则将位数压缩为8(包括符号) ) FPGA , 7, 8 ROM . , .
(, , ), RTL , , . GCC AVX256 bitperfect ( FPGA ) FPS ( W B, ).
W fc , .. -100 +100 +10000 255 9 ( ).
! 因为 dephwise .
u-law ( ! ).
, , 6, , .
( ). — , FixedPoint dot product — Fractional part, — , , fc .
关于在GPU,FPGA,ASIC和其他硬件上自动优化模型的编译评论来自@BigPack
- TVM ( tvm.ai/about), ( Keras) . , — «»- (bare metal, ISA, FPGA .) edge computing. TVM HLS TVM FPGA. HLS FPGA «» , ( ) FPGA , GPU/TPU .
PS FPGA transparent hardware ( — open-source hardware), , ( «» ) . -. , FPGA —
关于宣布FPGA架构创新,使用Microsoft FPGA和神经网络自动优化的公告很棒的评论@ Brak0delFPGA, 2019 , . — . / dsp-
Xilinx Achronix , DDR.
, , , FPGA ASIC-. FPGA : , ASIC , FPGA - . 即 - . , ASIC-, , . , FPGA , ASIC.
, CPU, FPGA , , .
, GPU , FPGA , : , - , GPU , , , - ( , , , , FPGA , GPU ,
). , FPGA , , , ASIC-.
Microsoft (
Catapult v.2 ), FPGA-. , FPGA. () .
FPGA
Ristretto Deephi , , Deephi FPGA. , , , .
FPGA .
关于FPGA与ASIC相比的发展经济学评论来自@Mirn
, FPGA :
, ASIC.
:
FPGA
( ), ( , , IP 30-50 5 ).
, 10 ( ), 5*(N+1)
, , — 10 , , 120*N
( , — )
: (120+50+5)*N, 5 880
ASIC
( 2 )
(3-4 )
ASIC « » — : ,
, ( ), , — , .
: — , , .
( MiT — , , , )
, , 10 3-5 , ( — , , — , — ) , : .
! ! . NEC SONY (c , 10-15 , )
: FPGA ASIC.
致谢:
- . .. ,
- , , ,
- , , ,
- , , , , , , , , , , , , !