回想一下,Elastic Stack基于非关系型Elasticsearch数据库,Kibana Web界面和数据收集器(最著名的Logstash,各种Beats,APM等)。 使用机器学习算法进行数据分析是对整个列出的产品堆栈的不错补充之一。 在本文中,我们了解了这些算法是什么。 我们要猫。
机器学习是共享软件Elastic Stack的一项付费功能,并且是X-Pack的一部分。 要开始使用它,激活后就足以激活30天试用版。 试用期到期后,您可以请求扩展支持或购买订阅。 订阅成本不是根据数据量来计算的,而是根据所使用的节点数来计算的。 不,数据量当然会影响所需的节点数,但是相对于公司的预算,这种许可方式仍然更加人性化。 如果不需要高性能-您可以节省。
Elastic Stack中的ML用C ++编写,并且在运行Elasticsearch本身的JVM之外运行。 也就是说,该进程(顺便说一下,称为自动检测)消耗了JVM不会吞咽的所有内容。 在演示台上,这并不是很关键,但是在生产环境中,突出显示ML任务的单独节点很重要。
机器学习算法分为两类-
有 教师和
无教师 。 在Elastic Stack中,该算法来自“没有老师”类别。
该链接使您可以查看机器学习算法的数学工具。
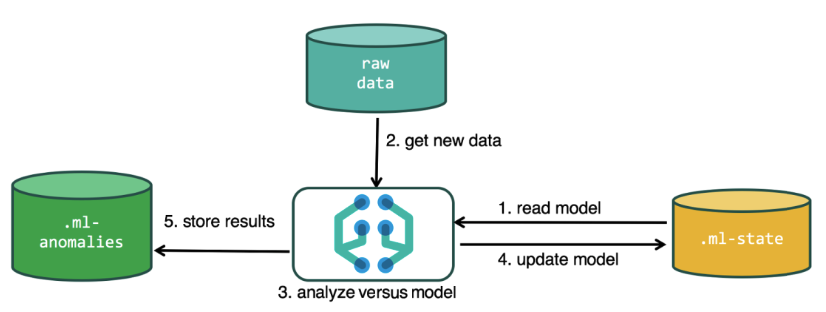
为了执行分析,机器学习算法使用存储在Elasticsearch索引中的数据。 您可以从Kibana界面和API创建分析任务。 如果您通过Kibana进行此操作,则无需了解某些事情。 例如,算法在流程中使用的其他索引。
分析过程中使用的其他索引.ml-state-有关统计模型的信息(分析设置);
.ml-anomalies- *-ML算法的工作结果;
.ml-notifications-基于分析结果的通知设置。
Elasticsearch数据库中的数据结构由存储在其中的索引和文档组成。 如果与关系数据库进行比较,则可以将索引与数据库模式进行比较,并将索引与表中的条目进行比较。 这种比较是有条件的,旨在简化那些仅了解Elasticsearch的人员对其他材料的理解。
API通过Web界面提供了相同的功能,因此,为使概念清晰和理解,我们将展示如何通过Kibana进行配置。 左侧菜单中有一个机器学习部分,您可以在其中创建新作业。 在Kibana界面中,如下图所示。 现在,我们将分析每种任务,并显示可以在此处构建的分析类型。
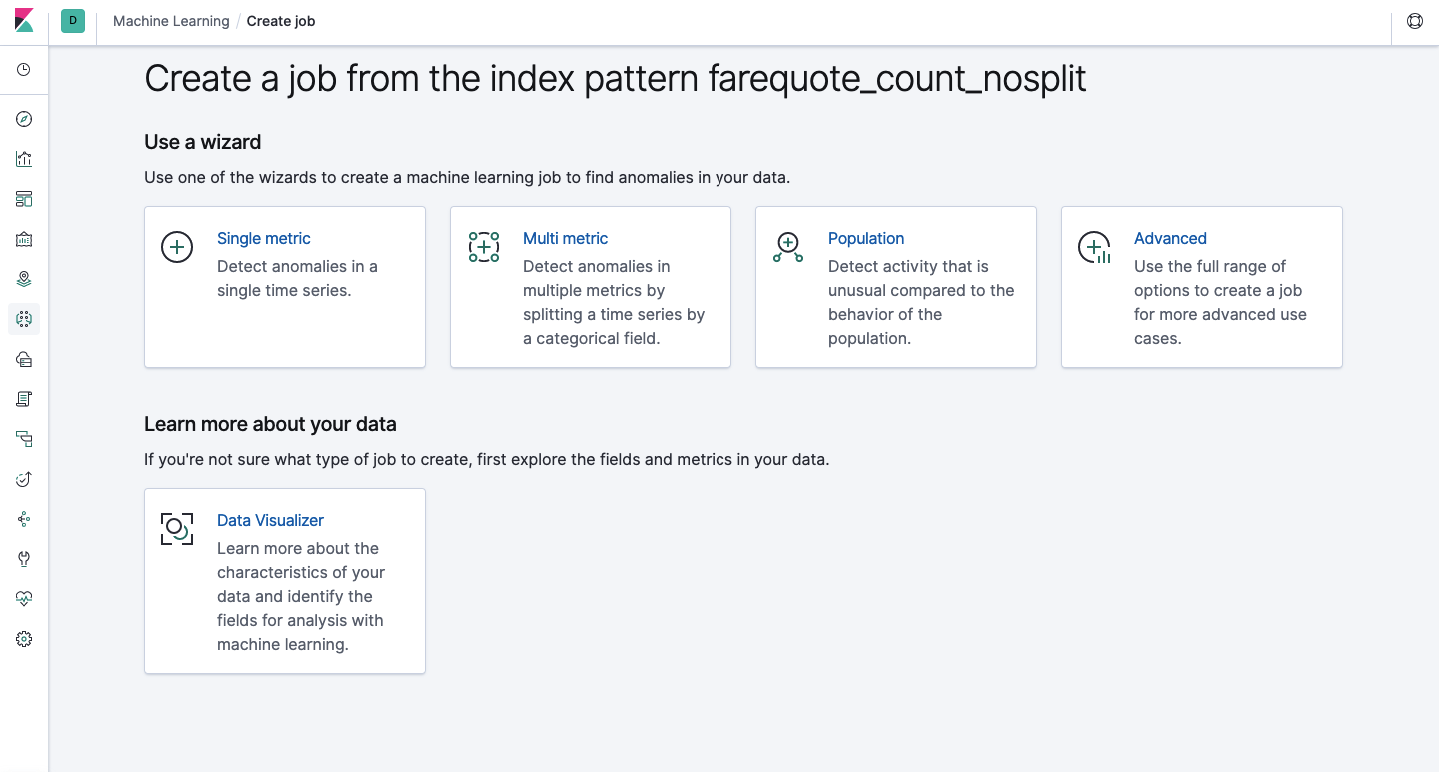
单指标-分析一个指标,多指标-分析两个或多个指标。 在这两种情况下,每个指标都是在隔离的环境中进行分析的,即 该算法未考虑并行分析的度量标准的行为,就像在多度量标准的情况下那样。 要考虑各种指标的相关性来进行计算,可以应用总体分析。 而Advanced是对算法的微调,其中包含针对某些任务的其他选项。
单一指标
您可以在此处执行最简单的操作,即分析单个度量标准中的更改。 单击创建作业后,算法将查找异常。
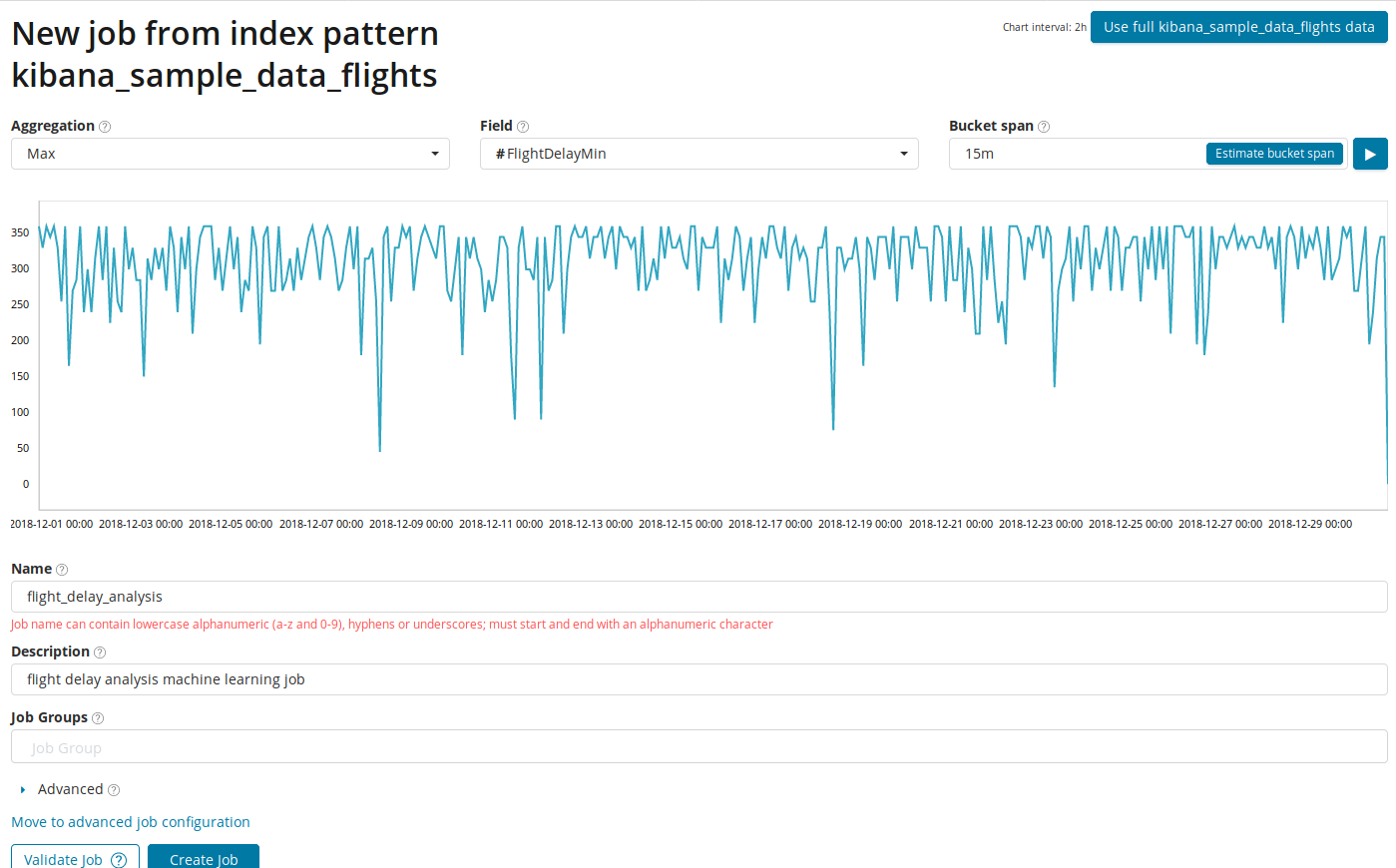
在
聚合字段中,您可以选择一种搜索异常的方法。 例如,对于
Min,异常值将被认为低于典型值。 有
最大,高均值,低,均值,不同等。 可以在
此处找到所有功能的说明。
字段字段指示我们将通过其分析的文档中的数字字段。
在“
桶跨度”字段中,将在时间线上进行分析的间隔的粒度。 您可以信任自动化或手动选择。 下图显示了粒度太低的示例-您可以跳过异常。 使用此设置,您可以将算法的敏感性更改为异常。

收集数据的持续时间是影响分析有效性的关键因素。 在分析中,该算法确定重复间隔,计算置信区间(基线)并识别异常-与度量标准行为的非典型偏差。 例如:
具有较小数据范围的基准:
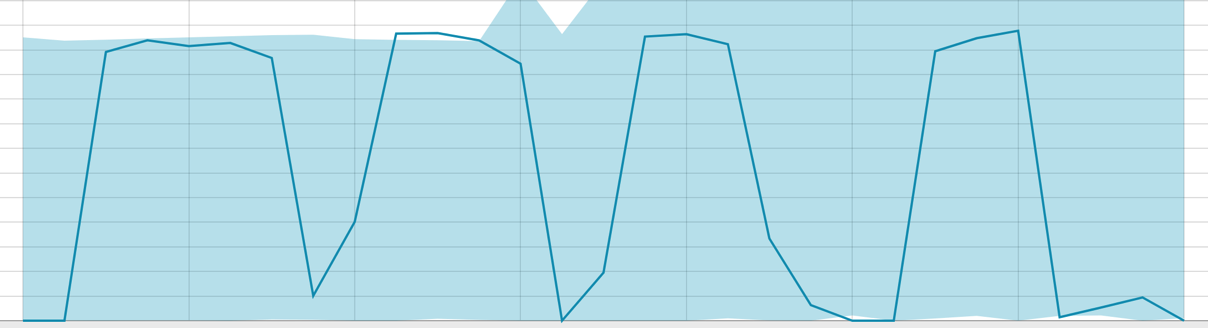
当算法需要学习时,基线看起来像这样:
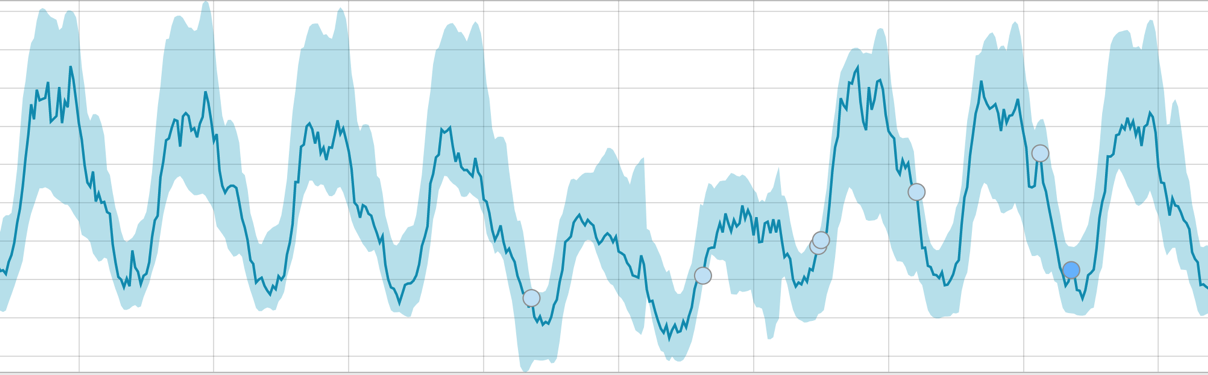
在开始任务之后,算法确定与标准的异常偏差,并根据异常的可能性对它们进行排序(相应标签的颜色显示在方括号中):
警告(青色):小于25
次要(黄色):25-50
大(橙色):50-75
严重(红色):75-100
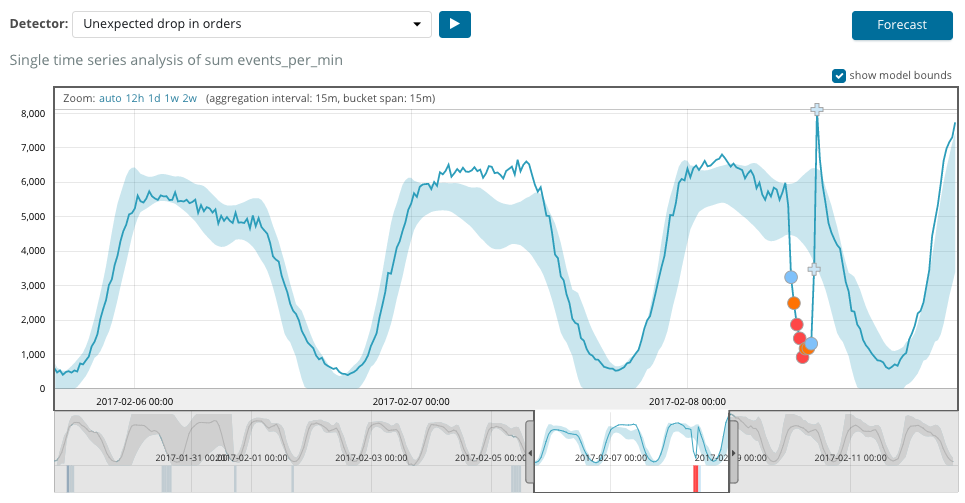
下图显示了发现异常的示例。
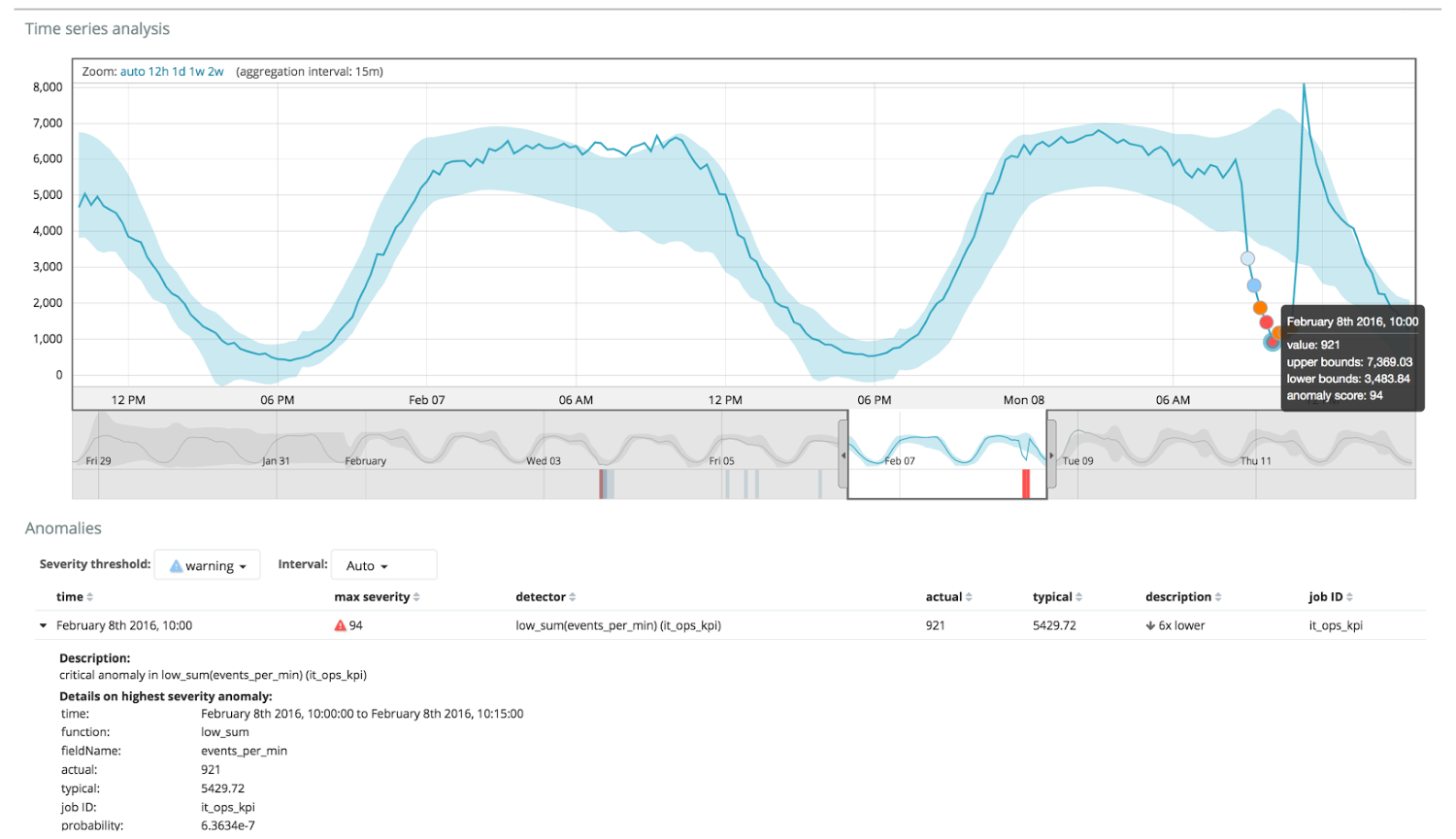
在这里您可以看到数字94,它表示发生异常的可能性。 显然,由于该值接近100,因此表示异常。 图表下方的栏显示该度量值出现的贬损概率为0.000063634%。
除了在Kibana中搜索异常外,您还可以运行预测。 这是通过基本方法并从具有异常的同一视图中完成的-右上角的“
预测”按钮。

预测基于最多提前8周进行。 即使您确实想要,也不能再通过设计。
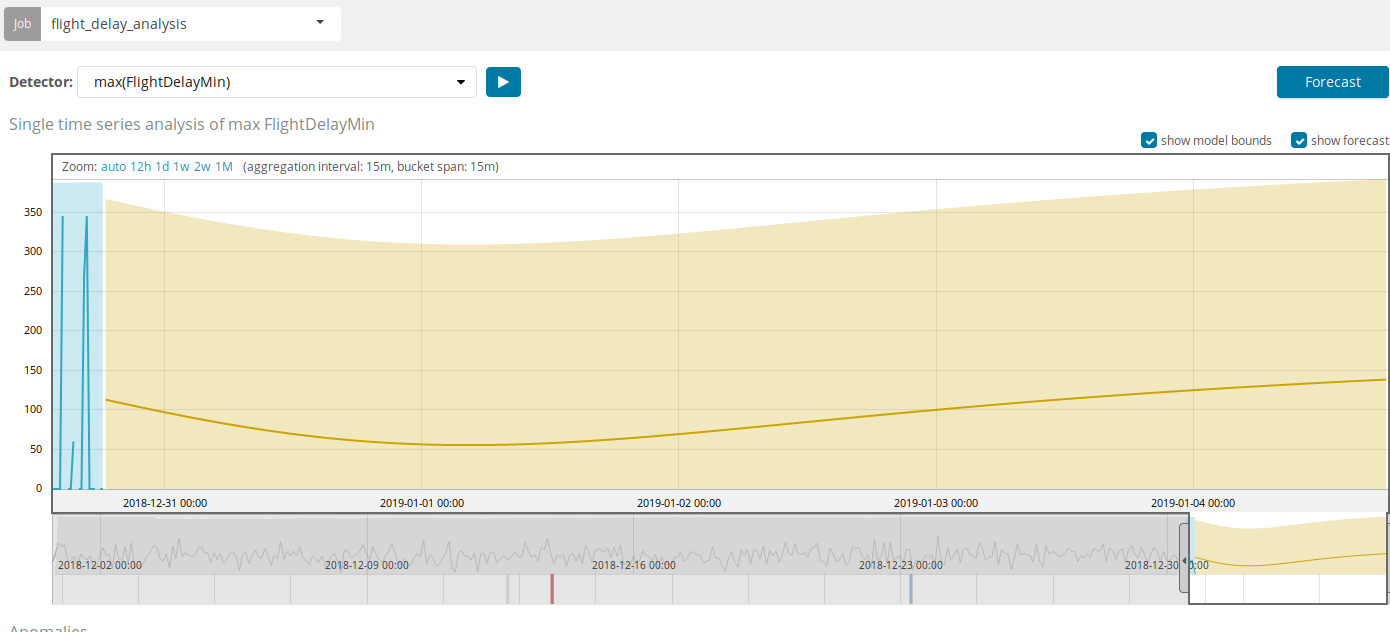
在某些情况下,例如在监视基础结构上的用户负载时,预测将非常有用。
多指标
我们继续进行弹性堆栈中的下一个ML功能-捆绑分析多个指标。 但这并不意味着将分析一个度量对另一度量的依赖性。 这与“单一指标”相同,一个屏幕上只有很多指标,可以轻松比较一个指标对另一个指标的影响。 我们将讨论“人口”部分中一种度量对另一种度量的依赖性分析。
单击具有多度量标准的正方形后,将显示一个设置窗口。 我们将更详细地介绍它们。
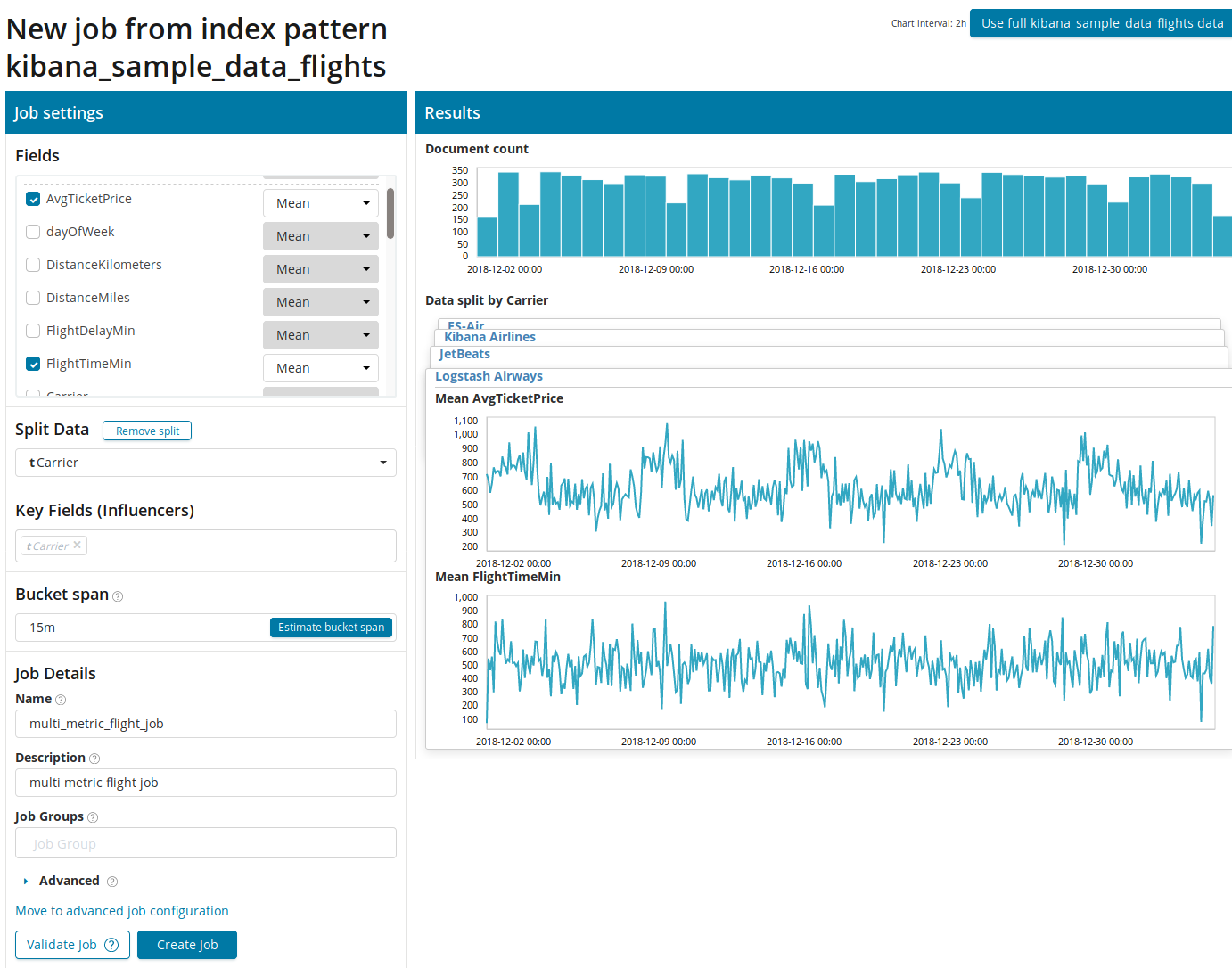
首先,您需要选择用于分析和汇总数据的字段。 此处的聚合选项与“单指标”相同(
最大值,高均值,低,均值,差异和其他)。 此外,该数据可选地分为多个字段之一(字段
Split Data )。 在示例中,我们使用
OriginAirportID字段进行了此操作。 请注意,右侧的指标图现在显示为多个图。
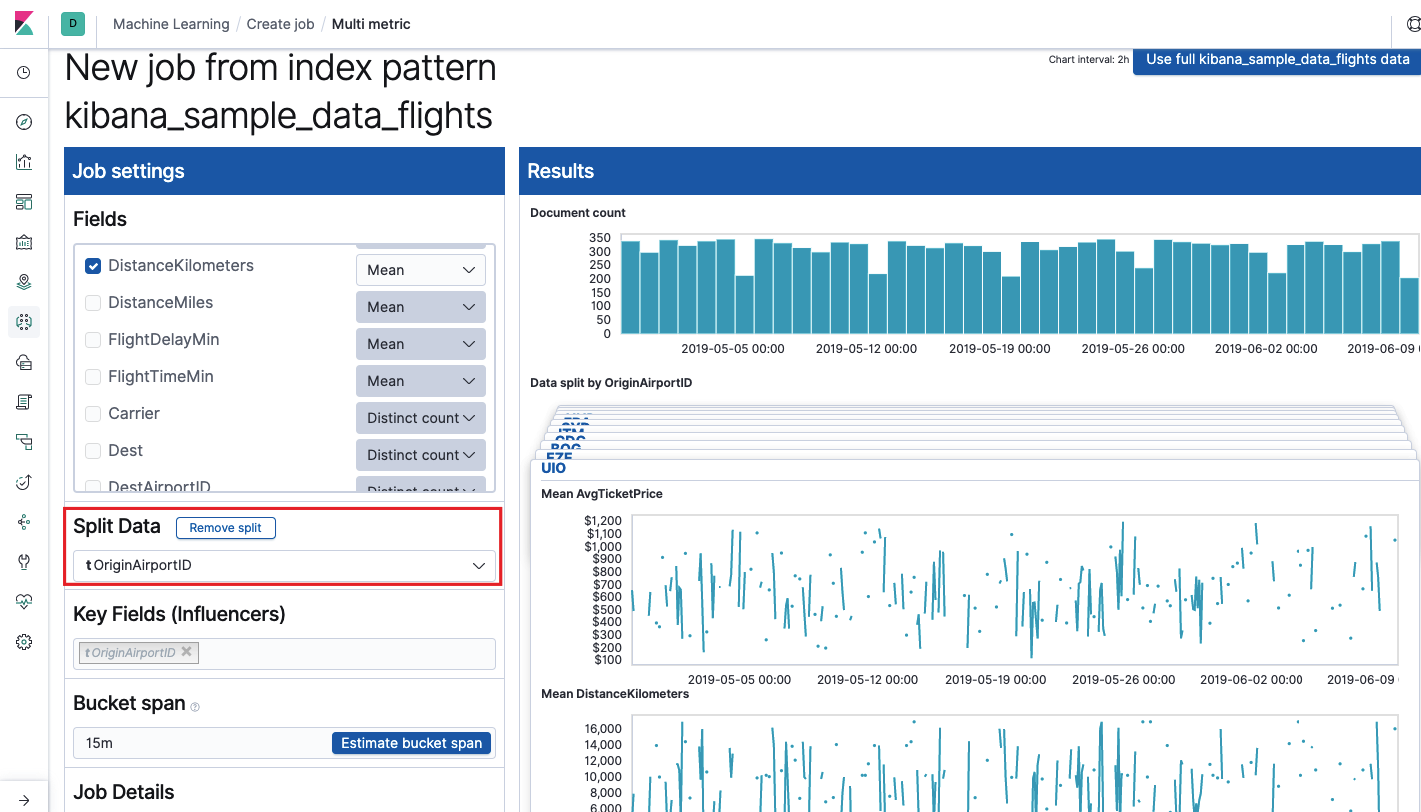 关键字段(影响者)
关键字段(影响者)字段直接影响发现的异常。 默认情况下,将始终至少有一个值,您可以添加其他值。 该算法将在分析中考虑这些字段的影响,并显示出最“有影响力”的值。
启动后,以下图片将出现在Kibana界面中。
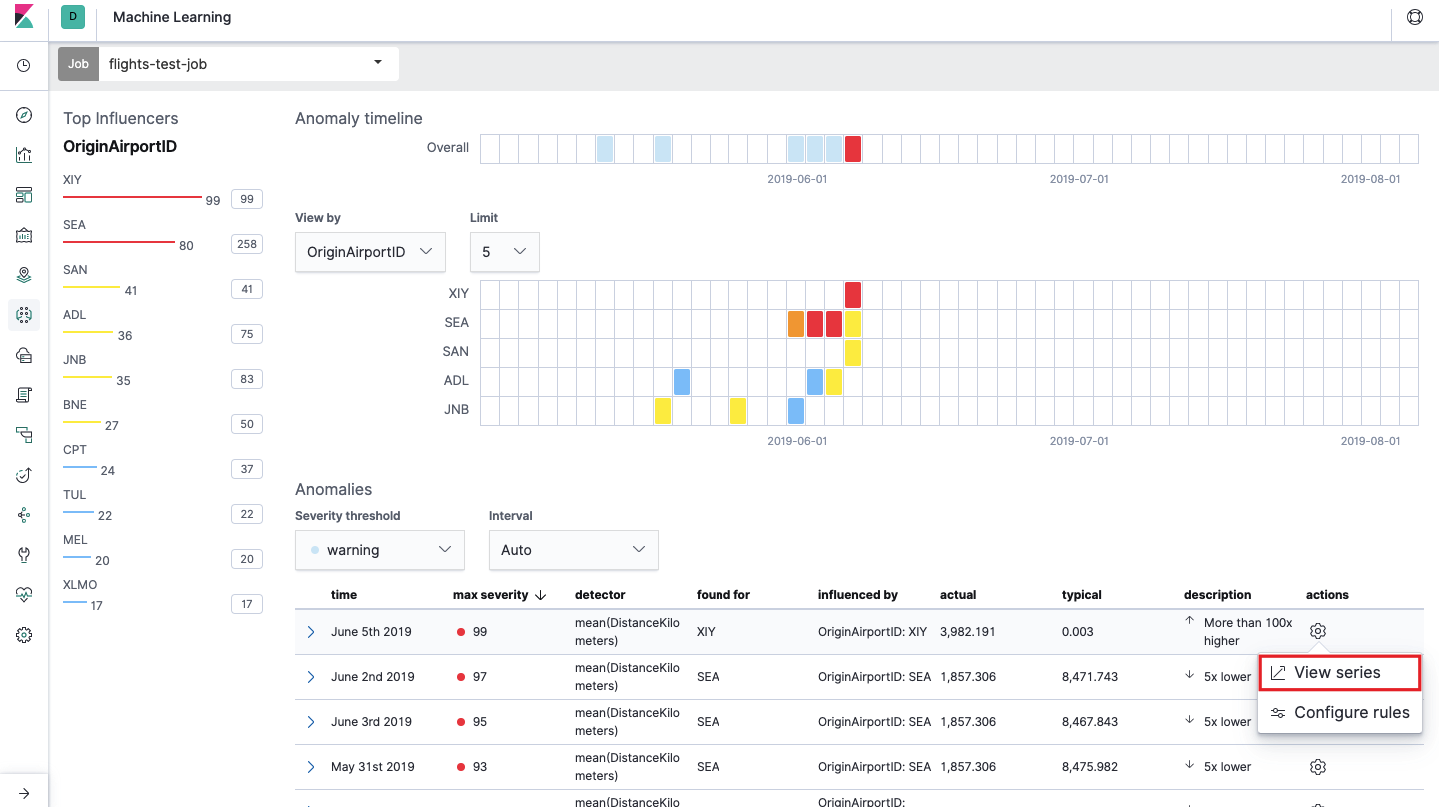
这就是所谓的 我们在
分割数据中指定的
OriginAirportID字段的每个值的异常热图。 与“单指标”一样,颜色表示异常偏差的级别。 在工作站上进行类似的分析很方便,例如,跟踪那些可疑的地方有很多授权等。 我们已经
在EventLog Windows中撰写了
有关可疑事件的文章,也可以在此处进行收集和分析。
热图下方是异常列表,每一个异常都可以转到“单一度量”视图进行详细分析。
人口
为了在不同指标之间的相关性之间搜索异常,Elastic Stack具有专门的人口分析。 借助它,您可以搜索服务器性能(与其他服务器相比)的异常值,例如,增加对目标系统的请求数量。
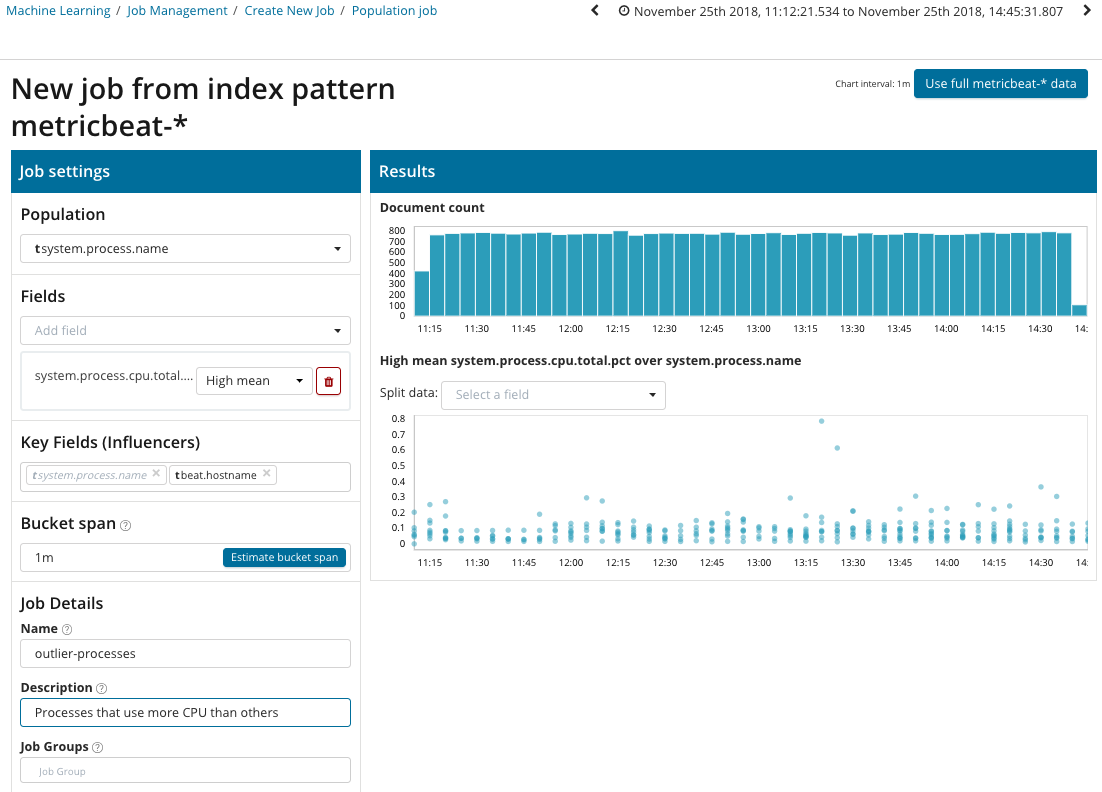
在此图示中,“人口”字段指示分析的指标将与之相关的值。 这是进程的名称。 结果,我们将看到每个进程的处理器负载如何相互影响。
请注意,所分析数据的图形与“单指标”和“多指标”的情况不同。 这是在Kibana中通过设计完成的,目的是改善对分析数据值分布的感知。

该图显示
poipu服务器上的
压力过程(顺便说一下,由一个特殊的实用程序生成)
表现异常 ,从而影响了(或证明是影响者)此异常的发生。
进阶
精细分析。 使用Advanced Analysis,其他设置将显示在Kibana中。 单击“高级”图块上的“创建”菜单后,将出现一个选项卡式窗口。 故意跳过了“
作业详细信息”选项卡,那里的基本设置与分析设置没有直接关系。
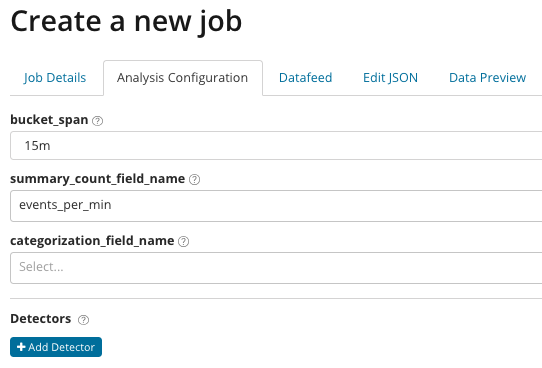
在
summary_count_field_name中,可以选择从包含聚合值的文档中指定字段的名称。 在此示例中,每分钟的事件数。
categorization_field_name指示文档中字段值的名称,其中包含某种变量值。 通过在此字段上屏蔽,可以将分析的数据细分为子集。 请注意上图中的“
添加检测器”按钮。 以下是单击此按钮的结果。

这是用于为特定任务设置异常检测器的附加设置块。 我们计划在以下文章中分析特定的用例(尤其是安全性)。 例如,
查看其中一个分解案例。 它与对极少出现的值的搜索相关联,
并由稀有函数实现 。
在
功能字段中,您可以选择一个特定的功能来搜索异常。 除了
罕见的功能外 ,还有一些有趣的功能
-time_of_day和time_of_week 。 他们分别确定一天或一周内指标行为的异常情况。 其余的分析功能
在文档中 。
field_name指示将要分析的文档的字段。
By_field_name可用于分隔此处指定的文档字段的每个单独值的分析结果。 如果您填写
over_field_name,则会获得总体分析,我们已在上面进行了分析。 如果在
partition_field_name中指定一个值,则将在此文档字段中计算每个值的单独基准(例如,服务器的名称或服务器上的进程可以用作该值)。 在
exclude_frequent中,您可以选择
all或
none ,这意味着排除(或包含)经常遇到的文档字段值。
在本文中,我们试图给出关于Elastic Stack中机器学习的可能性的最简洁的想法,但幕后仍有许多细节。 在评论中告诉我们您在Elastic Stack的帮助下成功解决了哪些情况以及使用了哪些任务。 要与我们联系,您可以使用Habré
上的个人消息或
网站上的反馈表 。