我提请您注意亚历山大·库兹曼科 ( Alexander Kuzmenko) (自今年4月起正式担任Haxe编译器的开发人员)关于自Haxe 3.4发行以来Haxe语言发生的更改的报告的译文 。

自Haxe 3.4发布以来已经过去了两年半。 在此期间,发布了7个修补程序版本,5个Haxe 4预览版本和2个Haxe 4候选发布版本,距离新版本还有很长的路要走,并且几乎已经准备就绪( 大约有20个问题需要解决)。

Alexander感谢Haxe社区报告了bug,并希望参与该语言的开发。 由于haxe-evolution项目 ,类似以下内容将出现在Haxe 4中:

另外,在该项目的框架内,还对以下可能的创新进行了讨论: Promises , polymorphic this和default type (默认类型参数)。
接下来,亚历山大谈到了语言语法的变化 。

第一个是用于描述函数类型语法的新语法。 旧的语法有点奇怪。
Haxe是一种多范式编程语言,始终支持一流的功能,但是用于描述函数类型的语法是从功能语言继承的(与其他范式不同)。 而且熟悉函数式编程的程序员希望使用这种语法的函数来支持自动循环。 但是在Haxe中并非如此。
据亚历山大说,旧语法的主要缺点是无法确定参数的名称,这就是为什么必须编写带有参数说明的长注释注释的原因。
但是现在我们有了一种用于描述函数类型的新语法(顺便说一句,它是作为haxe-evolution倡议的一部分添加到该语言中的),存在这样的机会(尽管这是可选的,但建议使用)。 新语法更易于阅读,甚至可以视为代码文档的一部分。
用于描述函数类型的旧语法的另一个缺点是它Void->Void -即使函数不接受任何参数,也需要指定函数参数的类型: Void->Void (此函数不带参数也不返回任何内容)。
在新语法中,这实现得更加优雅: ()->Void

第二个是箭头函数或lambda表达式-描述匿名函数的缩写。 社区一直在要求将它们添加到语言中,终于发生了!
在此类函数中, ->字符序列->而不是return关键字(因此语法名称为“箭头功能”)。
在新语法中,仍然可以设置参数的类型(因为自动类型推断系统无法始终按照程序员希望的方式执行此操作,例如,编译器可以决定使用Float而不是Int )。
新语法的唯一限制是无法显式设置返回类型。 如有必要,则可以选择使用旧语法或在函数主体中使用check-type语法 ,这将告诉编译器返回类型。

箭头函数在语法树中没有特殊表示;它们的处理方式与常规匿名函数相同。 序列->被return关键字替换。

第三个更改-final现在已成为关键字(在Haxe 3中final是内置在编译器中的meta标签之一)。
如果将其应用于类,它将禁止从其继承,这同样适用于接口。 将final限定符应用于类方法将防止其在子类中被覆盖。
但是,在Haxe中,有一种方法可以解决由final关键字施加的限制-您可以为此使用@:hack meta标签(但是,仅在绝对必要的情况下才应这样做)。
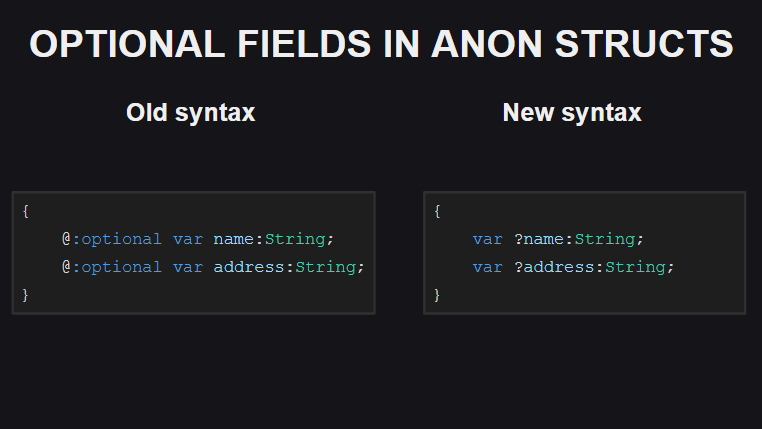
第四个更改是在匿名结构中声明可选字段的方法。 以前, @:optional元标记用于此目的,现在只需在字段名称前面添加问号。

第五,抽象枚举已成为Haxe类型家族的正式成员,现在使用@:enum关键字代替@:enum meta标签。
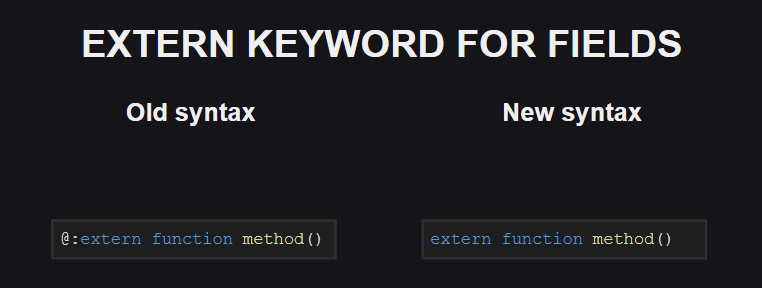
类似的变化影响了@:extern元标记。

第七是一种新型的交集语法,可以更好地反映扩展结构的本质。
相同的新语法用于限制类型参数约束;它可以更准确地传达对类型施加的约束。 对于不熟悉Haxe的人,可以将旧语法MyClass<T:(Type1, Type2)>视为将参数T的类型设置为Type1或Type2 。 新语法明确告诉我们T必须同时为Type1和Type2 。
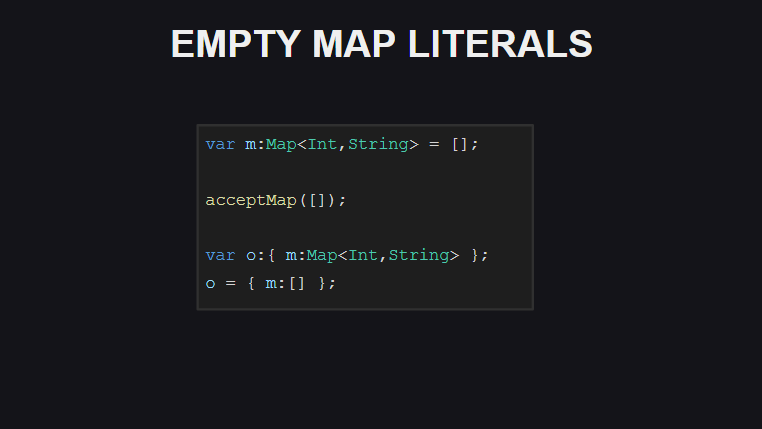
第八种能力是使用[]声明一个空的Map容器的能力(但是,如果您未显式指定变量的类型,则在这种情况下,编译器会将类型输出为数组)。
讨论了语法的变化之后,让我们继续介绍该语言中的新功能 。
让我们从新的键值迭代器开始
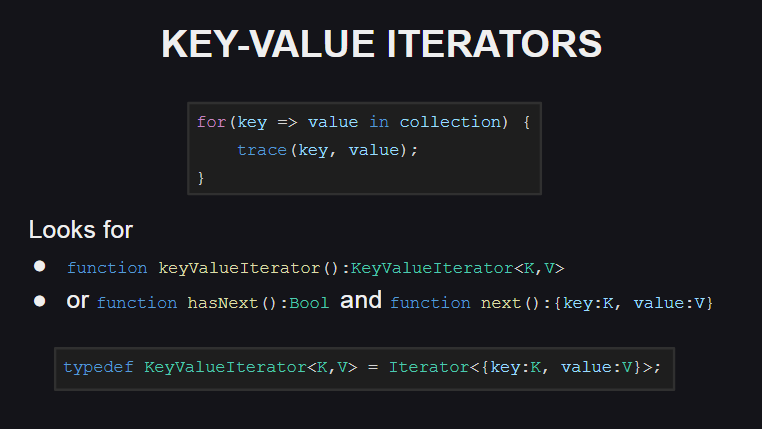
已添加新语法供其使用。
为了支持此类迭代器,该类型必须实现keyValueIterator():KeyValueIterator<K, V>方法keyValueIterator():KeyValueIterator<K, V>或hasNext():Bool方法hasNext():Bool和next():{key:K, value:V} 。 同时,类型KeyValueIterator<K, V>是匿名结构Iterator<{key:K, value:V}>常规迭代器的同义词。
已从Haxe标准库( String , Map , DynamicAccess )中为某些类型实现键值迭代器,并且正在为数组实现它们。
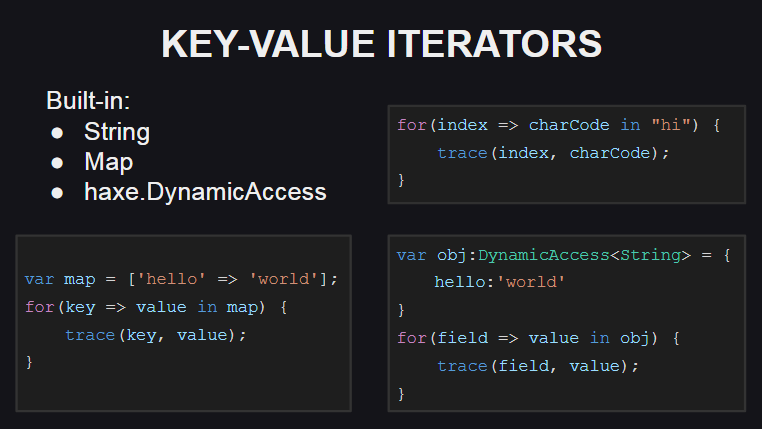
对于字符串,将字符串中的字符索引用作键,并将给定索引处的字符代码用作值(如果需要字符本身,则可以使用String.fromCharCode()方法)。
对于Map容器,新的迭代器的工作方式与旧的迭代方法相同,即,它在容器中接收一个键数组,并通过它,从而为每个键请求值。
对于DynamicAccess (匿名对象的包装器),迭代器使用反射工作(使用Reflect.fields()方法获取对象的字段列表,并使用Reflect.fields()方法按名称获取字段值)。

Haxe 4使用了全新的宏解释器“ eval”。 口译的作者西蒙·克拉耶夫斯基(Simon Krajewski) 在Haxe官方博客以及去年的进度报告中对此进行了详细描述。
口译员工作的主要变化:
- 它比旧的宏解释器快几倍(平均四倍)
- 支持交互式调试(以前,对于宏,只能使用控制台输出)
- 它用于在解释器模式下运行编译器(以前使用neko。顺便说一句,eval在速度上也超过了neko)。

对所有平台(neko除外)的Unicode支持是Haxe 4中最大的变化之一。西蒙在去年详细讨论了这一点 。 但是,这是Haxe中Unicode字符串支持的当前状态的简要概述:
- 对于Lua,PHP,Python和eval(宏解释器),实现了完全的Unicode支持(UTF8编码)
- 对于其他平台(JavaScript,C#,Java,Flash,HashLink和C ++),使用UTF16编码。
因此,Haxe中的线条对于包含在多语言主平面中的字符的工作方式相同,但是对于该平面之外的字符(例如,表情符号),根据平台使用线条的代码可以产生不同的结果(但这仍然更好,而不是Haxe 3中的情况,当时每个平台都有自己的行为)。

对于Unicode编码的字符串(在UTF8和UTF16中都是),已向Haxe标准库添加了特殊的迭代器,该迭代器在所有平台上对所有字符(在主要多语言平面内及以后)均适用:
haxe.iterators.StringIteratorUnicode haxe.iterators.StringKeyValueIteratorUnicode

由于字符串的实现因平台而异,因此有必要牢记其工作的某些细微差别。 在UTF16中,每个字符占用2个字节,因此按索引访问字符串中的字符很快,但是只能在主多语言平面内进行。 另一方面,在UTF8中支持所有字符,但这是以缓慢搜索字符串中的字符为代价的(由于字符可以占用内存中不同数量的字节,因此按索引访问字符需要从头开始每次都在行中进行迭代)。 因此,在Lua和PHP中使用大型字符串时,需要记住访问任意字符的速度非常慢(同样在这些平台上,每次都会再次计算字符串长度)。
但是,尽管声明了对Python的完全Unicode支持,但此限制并不适用于它,因为其中的行以略有不同的方式实现:对于主多语言平面内的字符,它使用UTF16编码,而对于较宽的字符(3和更多字节)Python使用UTF32。
为eval宏解释器实现了其他优化:字符串“知道”它是否包含Unicode字符。 如果它不包含此类字符,则该字符串将被解释为由ASCII字符组成(每个字符占1个字节)。 还优化了eval中按索引的顺序访问:最后访问的字符的位置缓存在该行中。 因此,如果您首先转向字符串中的第10个字符,那么当您下次转向第20个字符时,eval并不是从行的开头而是从第10个开始寻找它。 另外,将缓存eval中的字符串长度,即仅在第一个请求时才计算得出。
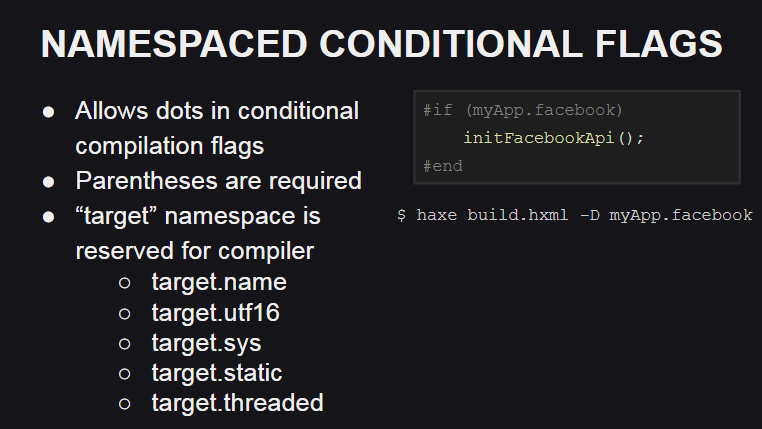
Haxe 4引入了对用于编译标志的名称空间的支持,这对于例如在编写自定义库时组织代码很有用。
同样,出现了用于编译标志的保留名称空间-target,编译器使用它来描述目标平台及其行为:
target.name平台名称(js,cpp,php等)target.utf16表示使用UTF16实现Unicode支持target.sys指示sys软件包中的类是否可用(例如,用于文件系统)target.static指示平台是否为静态(在静态平台上,基本类型Int , Float和Bool的值不能为null )target.threaded指示平台是否支持多线程
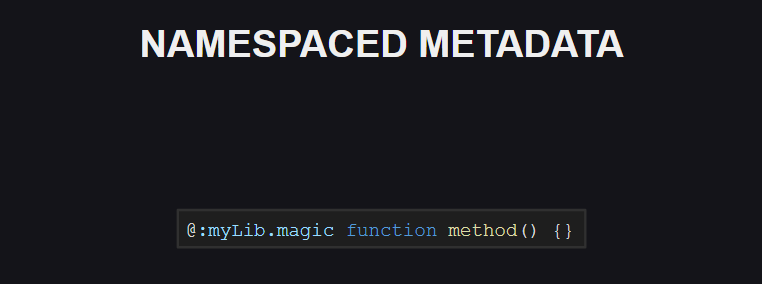
同样,出现了对元标记的名称空间支持。 到目前为止,该语言还没有为元标记保留的命名空间,但是这种情况将来可能会改变。

ReadOnlyArray类型添加到Haxe标准库中-常规数组的抽象,其中常规方法仅可用于从数组中读取数据。

语言的另一项创新是最终领域和局部变量。
如果在声明类字段或局部变量时使用final而不是var关键字,则这意味着无法重新分配给定的字段或变量(如果编译器尝试执行此操作,则将引发错误)。 但是同时,它的状态可以更改,因此最终字段或变量不是常量。
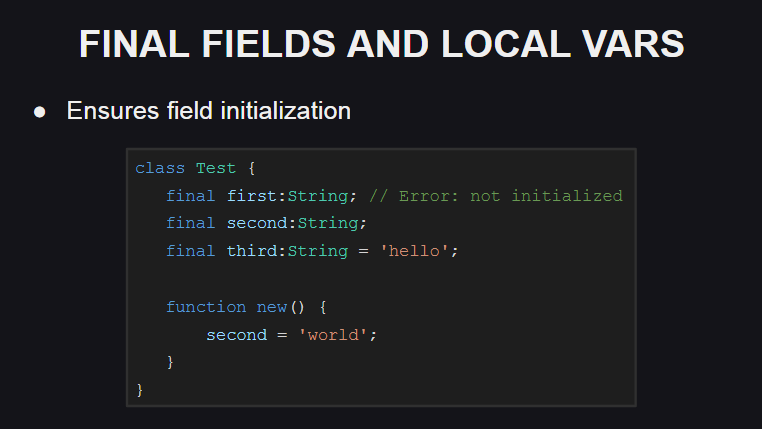
final字段的值必须在声明时或在构造函数中初始化,否则编译器将引发错误。

HashLink是一个具有自己的虚拟机的新平台,专门为Haxe创建。 HashLink支持所谓的“双重编译”-代码可以以字节码(速度非常快,可加快开发应用程序的调试过程)或C代码(以提高性能为特征)进行编译。 尼古拉斯将HashLink专门用于Haxe的几篇博客文章,并在去年的西雅图会议上谈到了他。 HashLink技术用于诸如Dead Cells和Northgard之类的流行游戏。

Haxe 4的另一个新的有趣功能是Null安全性,它仍处于试验阶段(由于误报和代码安全性检查不足)。
什么是空安全性? 如果您的函数没有明确声明它可以接受null作为参数值,那么当您尝试向其传递null时,编译器将抛出相应的错误。 此外,对于可以将null作为值的函数参数,编译器将要求您编写其他代码以验证和处理这种情况。
默认情况下,此功能是禁用的,但是它不会影响代码执行的速度(如果仍然启用),因为所描述的检查仅在编译阶段执行。 可以为所有代码启用它,也可以为单个字段,类和包逐渐启用它(从而提供了向更安全代码的逐步过渡)。 您可以为此使用特殊的元标记和宏。
可以使用Null-security的模式有: Strict (最严格), Loose (默认模式)和Off (用于禁用对单个程序包和类型的检查)。

对于幻灯片上显示的功能,启用了Null安全检查。 我们看到这个函数有一个可选参数s ,也就是说,我们可以将null作为参数值传递给它。 尝试使用此类函数编译代码时,编译器将产生许多错误:
- 尝试访问对象
s某些字段时(因为它可能为null ) - 尝试分配变量str时,如我们所见,该变量不应为
null (否则,我们应将其声明为String ,而不是Null<String> ) - 尝试从函数返回对象
s (因为该函数不应返回null )
如何解决这些错误?
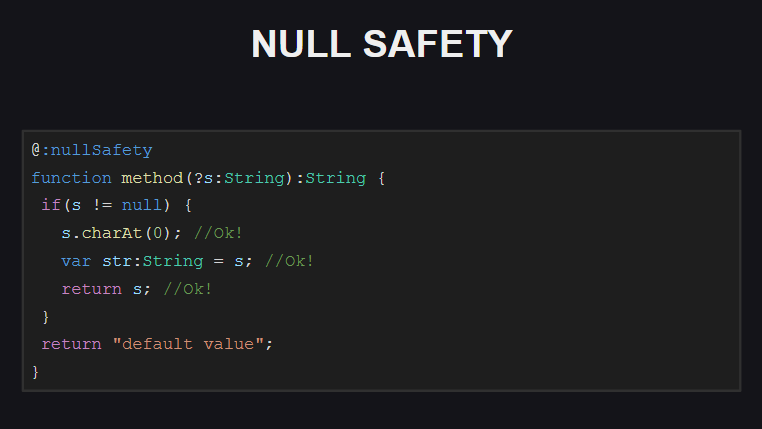
我们只需要向代码中添加null检查(在具有null检查的代码块内,编译器“知道” s不能为null并可以安全地使用它),并且还要确保该函数不会返回null !

另外,在执行Null安全性检查时,编译器会考虑程序执行的顺序。 例如,如果在将参数s的值检查为null以终止函数(或引发异常)之后,编译器将“知道”在执行此检查后,参数s不再可以为null ,并且可以安全地使用它。

如果编译器启用了严格的Null安全性检查模式,则在初始检查null与尝试访问对象字段之间执行任何可能将其设置为null代码之间的情况下,它将要求对null进行其他检查。 。
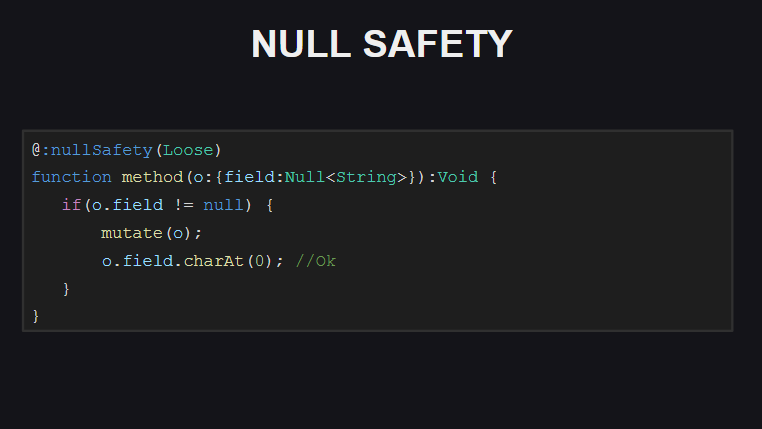
在松散模式(默认情况下使用)下,编译器将不需要进行此类检查(顺便说一下,默认情况下TypeScript中也使用此行为)。

另外,打开Null安全性检查时,编译器将检查类中的字段是否已初始化(直接在声明它们时或在构造函数中)。 否则,在尝试传递此类对象以及尝试在此类对象上调用方法时,编译器将引发错误,直到初始化该对象的所有字段为止。 可以通过使用元标记@:nullSafety(Off)标记类的各个字段来关闭此类检查。
去年10月,亚历山大(Alexander)进一步谈论了Haxe中的Null安全性。

Haxe 4引入了为JavaScript生成ES6类的功能;使用编译标志js-es=6启用了该功能。
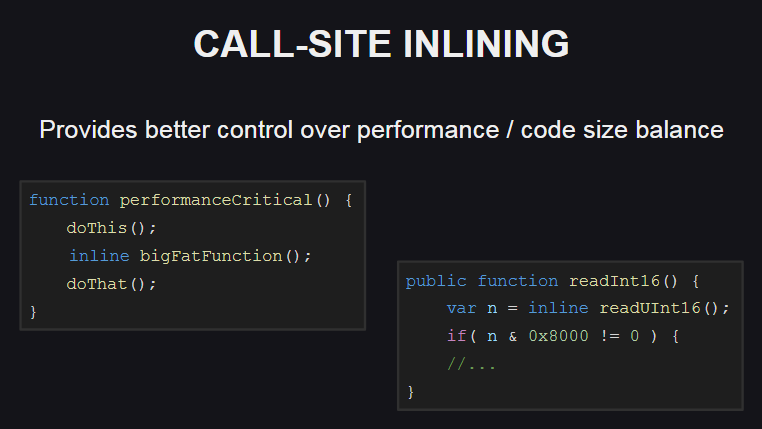
调用位置的嵌入功能(调用站点内联)提供了更多选项来控制代码性能和大小之间的平衡。 Haxe标准库中也使用了此功能。
她是什么样的人? 它允许您仅在需要确保高性能的那些位置(例如,如有必要,在循环中调用足够大的方法)中嵌入函数体(使用inline ),而在其他地方未嵌入函数体。 结果,所生成代码的大小将略有增加。
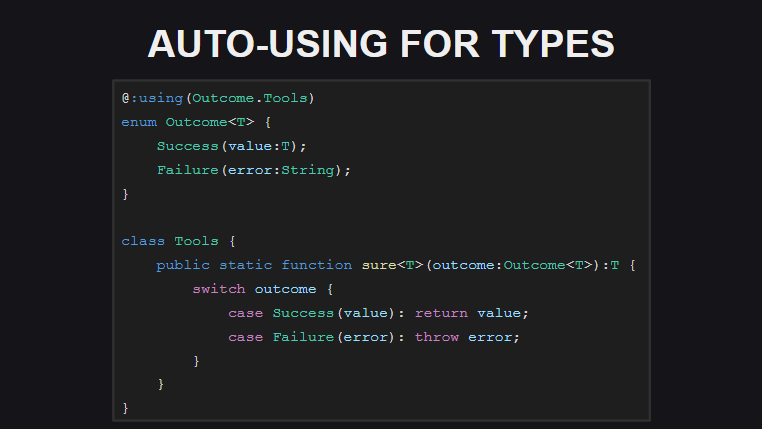
自动使用(类型的自动扩展)意味着现在对于类型,您可以在类型声明的位置声明静态扩展。 这消除了每次使用use using type;构造的需要using type; 在每个使用类型和扩展方法的模块中。 目前,这种扩展仅用于传输,但是在最终发行版(和夜间构建)中,它不仅可以用于传输。

在Haxe 4中,可以重新定义用于访问抽象类型的对象字段的运算符(仅针对该类型中不存在的字段)。 为此,请使用标有@:op(ab)元标记的方法。

内置标记是Haxe的另一个实验功能。 内置标记代码没有被编译器作为xml文档处理-编译器将其视为包装在@:markup元标记中的字符串。 .
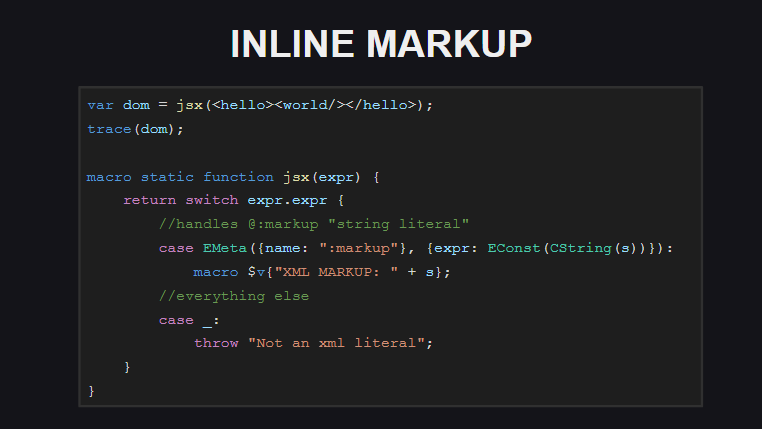
-, - @:markup , .

( untyped ). . , , Js.build() - @:markup , <js> , js-.

Haxe 4 - - , — .

. , . , Int , , C.
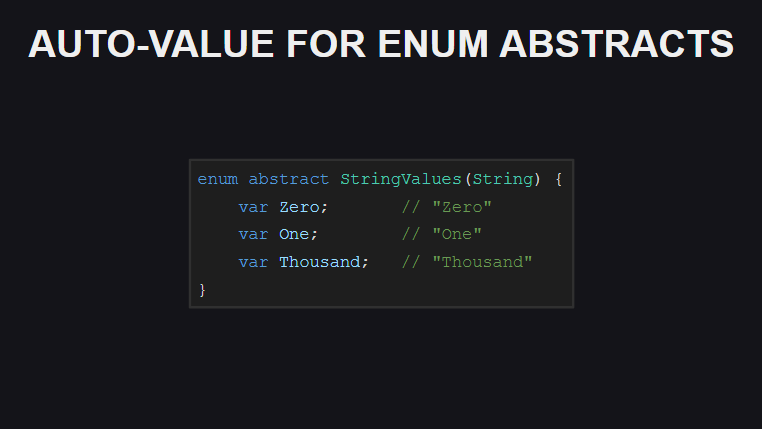
— .
:

JVM- JDK, Java-. . .

, async / await yield . ( C#, ). Haxe github.

Haxe , . ( ) . , .

API . , , API .
Haxe 4 !