我们从与
隔离有关的问题开始,对
低级组织数据进行了讨论,并详细
讨论了行版本以及如何从版本中获取
快照 。
然后,我们检查了不同类型的清洁:
页内 (以及HOT更新),
常规和
自动 。
到了这个周期的最后一个话题。 今天我们将讨论事务ID环绕和冻结的问题。
交易计数器溢出
PostgreSQL为事务编号分配了32位。 这是一个相当大的数字(约40亿),但是随着服务器的活跃运行,它很可能会用尽。 例如,在每秒1000个事务的负载下,这种情况只会在连续运行一个半月之后发生。
但是我们谈到了以下事实:多版本控制机制依赖于编号顺序-然后在两个事务中,可以认为编号较小的事务较早开始。 因此,很明显,您不能仅重置计数器并再次继续编号。
为什么没有为事务号分配64位-因为这样可以完全消除问题? 事实是(
如前所述 )在该行的每个版本的标题中都存储了两个事务编号-xmin和xmax。 标头已经很大,至少23个字节,并且位深度的增加将导致其头再增加8个字节。 绝对没有办法。
我们公司的产品Postgres Pro Enterprise中实现了64位交易号,但那里也不完全诚实:xmin和xmax仍然是32位,并且页面标题包含整个页面的通用“时代开始”。
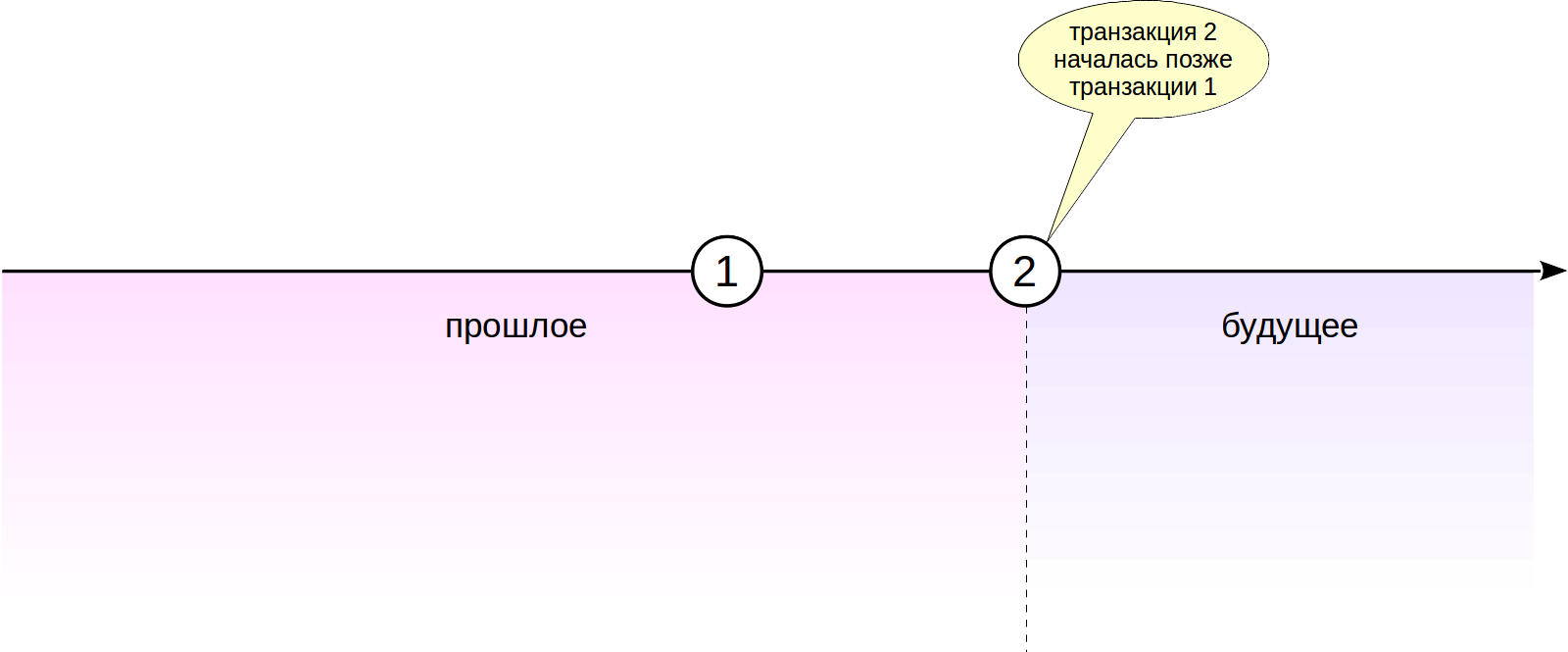
怎么办 代替线性图,所有交易号都是循环的。 对于任何交易,“逆时针”数字的一半都属于过去,而“顺时针”数字的一半则属于未来。
交易的期限是自交易出现在系统中以来经过的交易数量(无论计数器是否通过零)。 当我们想了解某笔交易是否早于另一笔交易时,我们比较它们的年龄而不是数字。 (因此,顺便说一下,没有为xid数据类型定义“更大”和“更少”操作。)

但是在这样的环路中,出现了不愉快的情况。 一段时间后,过去的交易(图中的交易1)将处于与未来有关的那半圈。 当然,这违反了可见性规则,并会导致问题-事务1所做的更改只会从视图中消失。
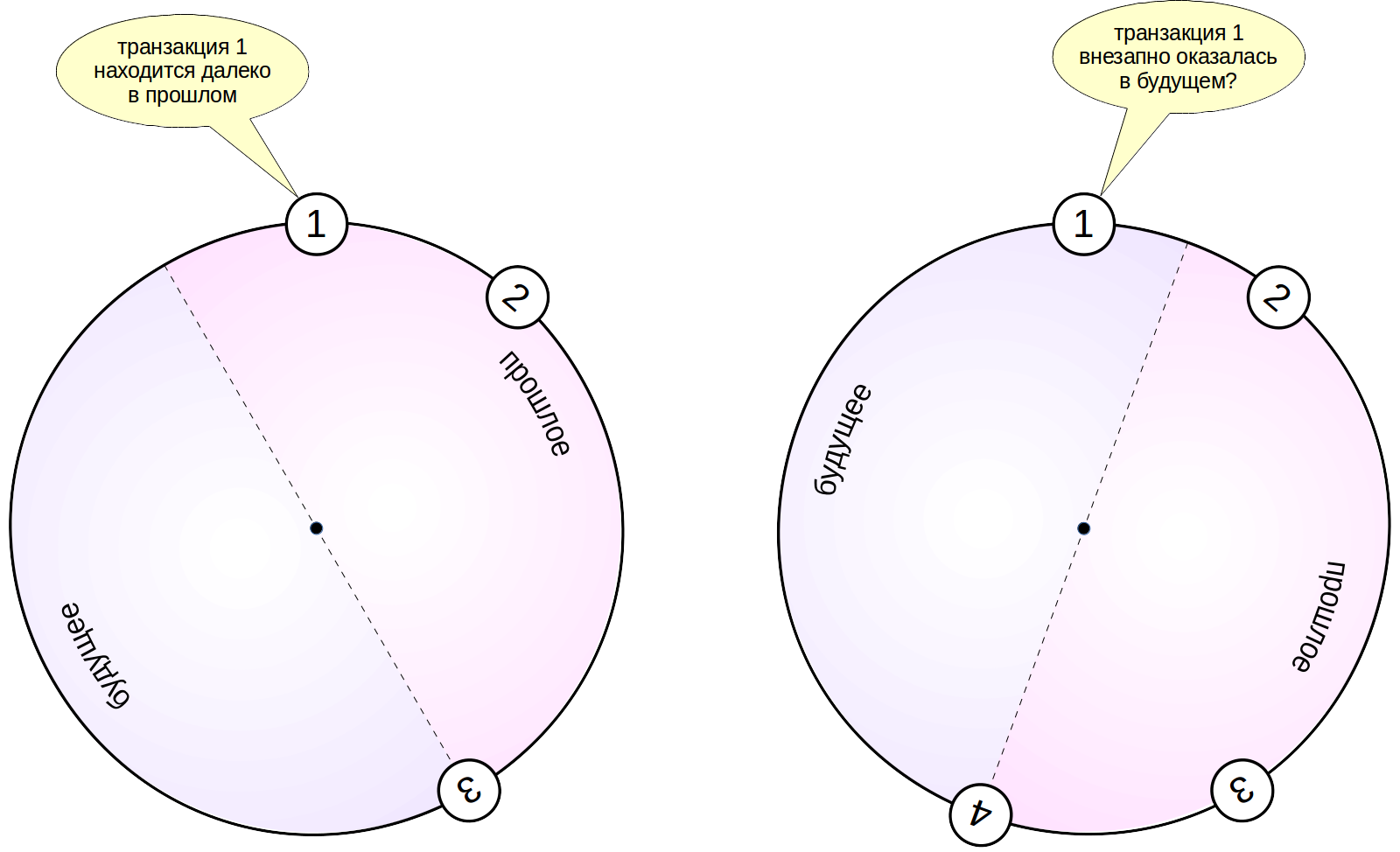
版本冻结和可见性规则
为了防止这种“旅行”过去和将来,清洁过程(除了释放页面中的空间之外)还执行另一项任务。 他发现线条的过旧和“冷”版本(在所有图片中都可见,并且已经不太可能更改),并以特殊方式标记它们-“冻结”它们。 该行的冻结版本被认为比任何常规数据都旧,并且在所有数据快照中始终可见。 而且,不再需要查看事务编号xmin,并且可以安全地重用该编号。 因此,字符串的冻结版本始终保留在过去。
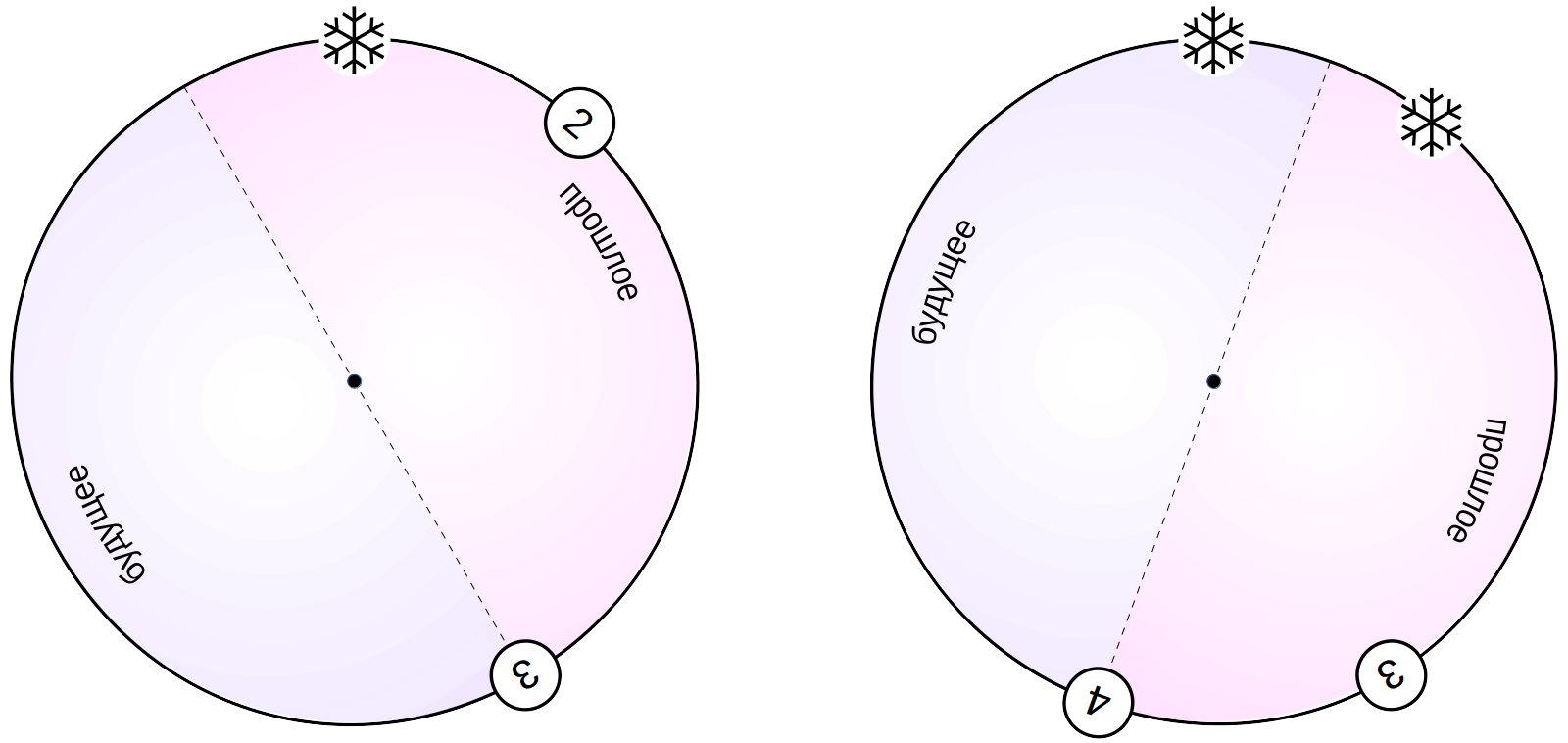
为了将事务编号xmin标记为冻结,两个提示位(提交位和取消位)同时设置。
请注意,不需要冻结xmax事务。 它的存在意味着该字符串版本不再相关。 在数据快照中不再显示该行之后,将清除该版本的行。
对于实验,创建一个表。 我们为其设置了最小填充因子,以便每页仅容纳两行-这样对于我们观察情况将会更加方便。 并关闭自动控制以自行控制清洁时间。
=> CREATE TABLE tfreeze( id integer, s char(300) ) WITH (fillfactor = 10, autovacuum_enabled = off);
我们已经创建了该函数的多个变体,这些变体使用pageinspect扩展名显示了页面上各行的版本。 现在,我们将创建相同功能的另一个变体:现在它将一次显示多个页面并显示xmin事务的使用期限(为此使用系统功能使用年龄):
=> CREATE FUNCTION heap_page(relname text, pageno_from integer, pageno_to integer) RETURNS TABLE(ctid tid, state text, xmin text, xmin_age integer, xmax text, t_ctid tid) AS $$ SELECT (pageno,lp)::text::tid AS ctid, CASE lp_flags WHEN 0 THEN 'unused' WHEN 1 THEN 'normal' WHEN 2 THEN 'redirect to '||lp_off WHEN 3 THEN 'dead' END AS state, t_xmin || CASE WHEN (t_infomask & 256+512) = 256+512 THEN ' (f)' WHEN (t_infomask & 256) > 0 THEN ' (c)' WHEN (t_infomask & 512) > 0 THEN ' (a)' ELSE '' END AS xmin, age(t_xmin) xmin_age, t_xmax || CASE WHEN (t_infomask & 1024) > 0 THEN ' (c)' WHEN (t_infomask & 2048) > 0 THEN ' (a)' ELSE '' END AS xmax, t_ctid FROM generate_series(pageno_from, pageno_to) p(pageno), heap_page_items(get_raw_page(relname, pageno)) ORDER BY pageno, lp; $$ LANGUAGE SQL;
请注意,冻结的迹象(我们在括号中以字母f表示)由同时安装已提交和已中止的提示确定。 许多来源(包括文档)都提到了特殊数字FrozenTransactionId = 2,该数字表示冻结的交易。 这样的系统在9.4版之前一直运行,但是现在已由工具提示位代替-这使您可以将原始交易号保存在线路版本中,这方便了支持和调试。 但是,编号为2的事务仍然可以在较旧的系统中进行,甚至可以升级到最新版本。
我们还需要pg_visibility扩展,它允许您查看可见性图:
=> CREATE EXTENSION pg_visibility;
在PostgreSQL 9.6之前,可见性映射每页只包含一位。 它标记了仅包含“相当古老”版本的字符串的页面,这些版本已经保证在所有图片中都可见。 这里的想法是,如果页面在可见性图中标记,那么对于其行的版本,您无需检查可见性规则。
从9.6版开始,将冻结图添加到同一层-每页增加一位。 冻结映射标记所有行版本都被冻结的页面。
我们将几行插入表中,并立即执行清理以创建可见性图:
=> INSERT INTO tfreeze(id, s) SELECT g.id, 'FOO' FROM generate_series(1,100) g(id); => VACUUM tfreeze;
并且我们看到两个页面现在都已在可见性地图中标记为(all_visible),但尚未冻结(all_frozen):
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno) ORDER BY g.blkno;
blkno | all_visible | all_frozen -------+-------------+------------ 0 | t | f 1 | t | f (2 rows)
创建行(xmin_age)的事务的年龄为1-这是在系统上执行的最后一个事务:
=> SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid -------+--------+---------+----------+-------+-------- (0,1) | normal | 697 (c) | 1 | 0 (a) | (0,1) (0,2) | normal | 697 (c) | 1 | 0 (a) | (0,2) (1,1) | normal | 697 (c) | 1 | 0 (a) | (1,1) (1,2) | normal | 697 (c) | 1 | 0 (a) | (1,2) (4 rows)
最低冷冻年龄
三个主要参数控制冻结,我们将依次考虑它们。
让我们从
vacuum_freeze_min_age开始,它定义了可以冻结字符串版本的最小事务年龄xmin。 该值越小,可能导致不必要的间接费用就越多:如果我们处理的是“热”数据,主动更改数据,那么冻结越来越多的新版本将毫无益处。 在这种情况下,最好等待。
此参数的默认值设置为,自从出现其他五千万笔交易以来,交易开始冻结:
=> SHOW vacuum_freeze_min_age;
vacuum_freeze_min_age ----------------------- 50000000 (1 row)
为了查看冻结如何发生,我们将此参数的值减小为1。
=> ALTER SYSTEM SET vacuum_freeze_min_age = 1; => SELECT pg_reload_conf();
然后,我们将在零页上更新一行。 由于fillfactor值较小,因此新版本将进入同一页面。
=> UPDATE tfreeze SET s = 'BAR' WHERE id = 1;
这是我们现在在数据页面中看到的内容:
=> SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid -------+--------+---------+----------+-------+-------- (0,1) | normal | 697 (c) | 2 | 698 | (0,3) (0,2) | normal | 697 (c) | 2 | 0 (a) | (0,2) (0,3) | normal | 698 | 1 | 0 (a) | (0,3) (1,1) | normal | 697 (c) | 2 | 0 (a) | (1,1) (1,2) | normal | 697 (c) | 2 | 0 (a) | (1,2) (5 rows)
现在,要冻结早于
vacuum_freeze_min_age = 1的行。 但是请注意,可见性图中未标记零线(该位已由UPDATE命令重置,从而更改了页面),并且第一个保留选中状态:
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno) ORDER BY g.blkno;
blkno | all_visible | all_frozen -------+-------------+------------ 0 | f | f 1 | t | f (2 rows)
我们
已经说过 ,清除仅扫描在可见性图中未标记的页面。 事实证明:
=> VACUUM tfreeze; => SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid -------+---------------+---------+----------+-------+-------- (0,1) | redirect to 3 | | | | (0,2) | normal | 697 (f) | 2 | 0 (a) | (0,2) (0,3) | normal | 698 (c) | 1 | 0 (a) | (0,3) (1,1) | normal | 697 (c) | 2 | 0 (a) | (1,1) (1,2) | normal | 697 (c) | 2 | 0 (a) | (1,2) (5 rows)
在零页上,一个版本被冻结,但是第一页根本不考虑清除。 因此,如果页面上只剩下当前版本,则清洗将不会到达该页面,也不会冻结它们。
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno) ORDER BY g.blkno;
blkno | all_visible | all_frozen -------+-------------+------------ 0 | t | f 1 | t | f (2 rows)
冻结整个表的年龄
为了仍然冻结清理未查看页面中剩余行的版本,提供了第二个参数:
vacuum_freeze_table_age 。 它确定事务的期限,在该期限内,清理将忽略可见性图,并遍历表的所有页面以进行冻结。
每个表都存储一个事务编号,已知所有冻结的旧事务都将被冻结(pg_class.relfrozenxid)。 根据该记住的事务的
期限 ,将
vacuum_freeze_table_age参数的值进行
比较 。
=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age --------------+----- 694 | 5 (1 row)
在PostgreSQL 9.6之前,清理执行全表扫描以确保所有页面均已爬网。 对于大桌子,此操作是漫长而可悲的。 如果清洗无法进行到最后(例如,急躁的管理员中断了命令的执行),就必须从头开始,这使问题变得更加严重。
从9.6版开始,多亏了冻结映射(我们在pg_visibility_map输出的all_frozen列中看到了),清除仅绕过那些尚未在映射中标记的页面。 这不仅减少了工作量,而且还耐中断:如果清洗过程停止并再次开始,他将不必再次查看他上次已在冻结图中标记的页面。
一种或另一种方式是,表中的所有页面在(
vacuum_freeze_table_age -
vacuum_freeze_min_age )事务中被冻结一次。 使用默认值,这种情况每百万交易发生一次:
=> SHOW vacuum_freeze_table_age;
vacuum_freeze_table_age ------------------------- 150000000 (1 row)
因此,很明显,不应设置太多
vacuum_freeze_min_age ,因为这将代替增加开销,而不是减少开销。
让我们看看如何冻结整个表,并执行以下操作,将
vacuum_freeze_table_age减小为5,以便满足冻结条件。
=> ALTER SYSTEM SET vacuum_freeze_table_age = 5; => SELECT pg_reload_conf();
让我们清理一下:
=> VACUUM tfreeze;
现在,由于已保证可以验证整个表,因此可以增加冻结事务的数量-我们确信页面没有较旧的未冻结事务。
=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age --------------+----- 698 | 1 (1 row)
现在,首页上所有行的版本都将冻结:
=> SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid -------+---------------+---------+----------+-------+-------- (0,1) | redirect to 3 | | | | (0,2) | normal | 697 (f) | 2 | 0 (a) | (0,2) (0,3) | normal | 698 (c) | 1 | 0 (a) | (0,3) (1,1) | normal | 697 (f) | 2 | 0 (a) | (1,1) (1,2) | normal | 697 (f) | 2 | 0 (a) | (1,2) (5 rows)
此外,第一页在冻结地图中被标记:
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno) ORDER BY g.blkno;
blkno | all_visible | all_frozen -------+-------------+------------ 0 | t | f 1 | t | t (2 rows)
“积极”回应的年龄
行版本冻结时间很重要。 如果出现尚未冻结的事务冒着进入未来的风险,PostgreSQL将崩溃以防止潜在的问题。
这可能是什么原因? 原因有很多。
- 可以关闭自动清洁,并且常规清洁也不会开始。 我们已经说过这不是必须的,但从技术上讲是可能的。
- 甚至包括的自动清除功能也不会出现在未使用的数据库中(请记住track_counts参数和template0数据库)。
- 正如我们上次看到的那样,清理将跳过仅添加数据而不删除或更改数据的表。
在这种情况下,将提供“激进”的
自动清洁操作,并由
autovacuum_freeze_max_age参数进行调节。 如果在任何数据库的任何表中可能有一个未冻结的事务,早于该参数中指定的期限,则将自动启动自动清理(即使已禁用)(即使已禁用),迟早它也会到达问题表(不管通常的标准如何)。
默认值非常保守:
=> SHOW autovacuum_freeze_max_age;
autovacuum_freeze_max_age --------------------------- 200000000 (1 row)
autovacuum_freeze_max_age的限制为20亿个交易,并且使用的值小10倍。 这是有道理的:增加价值会增加以下风险:在剩余时间内,自动清洗只是没有时间冻结所有必要的生产线版本。
另外,此参数的值确定XACT结构的大小:由于系统中应该没有任何较旧的事务可能需要了解其状态,因此自动清理将删除不必要的XACT段文件,从而释放空间。
让我们以tfreeze为例,看看清理如何处理仅追加表。 对于此表,通常禁用自动清洁功能,但这不会成为障碍。
更改
autovacuum_freeze_max_age参数需要重新启动服务器。 但是,上面讨论的所有参数也可以使用存储参数在单个表的级别上设置。 通常,只有在确实需要特殊注意的情况下,才需要在特殊情况下执行此操作。
因此,我们将在表级别设置
autovacuum_freeze_max_age (并同时返回正常的填充因子)。 不幸的是,最小值可能是100,000:
=> ALTER TABLE tfreeze SET (autovacuum_freeze_max_age = 100000, fillfactor = 100);
不幸的是,因为我们必须完成100,000笔交易才能重现我们感兴趣的情况。 但是,当然,从实际出发,这是一个非常非常低的价值。
由于我们要添加数据,因此我们将在表中插入100,000行-每行都在事务中。 再一次,我必须保留一点,即实际上不应该这样做。 但是现在我们可以探索了。
=> CREATE PROCEDURE foo(id integer) AS $$ BEGIN INSERT INTO tfreeze VALUES (id, 'FOO'); COMMIT; END; $$ LANGUAGE plpgsql; => DO $$ BEGIN FOR i IN 101 .. 100100 LOOP CALL foo(i); END LOOP; END; $$;
我们可以看到,表中最后冻结的事务的寿命已超过阈值:
=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age --------------+-------- 698 | 100006 (1 row)
但是,如果您稍等片刻,则服务器的消息日志中将有一个有关表“ test.public.tfreeze”的自动主动清除的条目,冻结的事务数将发生变化,并且其使用期限将恢复为正态:
=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age --------------+----- 100703 | 3 (1 row)
还有冻结多事务之类的事情,但是我们暂时不会谈论它-我们将推迟到讨论锁之前,以免超越自己。
手动冻结
有时,手动控制冻结比等待自动清洁的到来更方便。
您可以使用VACUUM FREEZE命令手动冻结命令-所有行版本都将被冻结,而与事务的
期限无关(就像
autovacuum_freeze_min_age = 0参数一样)。 使用VACUUM FULL或CLUSTER命令重建表时,所有行也会被冻结。
要冻结所有数据库,可以使用该实用程序:
vacuumdb --all --freeze
通过指定FREEZE参数,还可以使用COPY命令在初始加载期间冻结数据。 为此,必须在同一位置创建表(或用TRUNCATE命令清空)。
交易为COPY。
由于冻结行具有单独的可见性规则,因此这些行将在违反常规隔离规则的其他事务的数据快照中可见(这适用于具有“可重复读取”或“可序列化”级别的事务)。
要验证这一点,请在另一个会话中以“可重复读取”隔离级别启动事务:
| => BEGIN ISOLATION LEVEL REPEATABLE READ; | => SELECT txid_current();
请注意,此事务建立了数据快照,但没有访问tfreeze表。 现在,我们将清空tfreeze表,并在一个事务中将新行加载到其中。 如果并行事务读取tfreeze的内容,则TRUNCATE命令将被锁定,直到事务结束。
=> BEGIN; => TRUNCATE tfreeze; => COPY tfreeze FROM stdin WITH FREEZE;
1 FOO 2 BAR 3 BAZ \.
=> COMMIT;
现在,并行事务看到了新数据,尽管这破坏了隔离:
| => SELECT count(*) FROM tfreeze;
| count | ------- | 3 | (1 row)
| => COMMIT;
但是,由于这种数据加载不太可能定期发生,因此这通常不是问题。
更糟糕的是,COPY WITH FREEZE无法与可见性图一起使用-加载的页面未标记为仅包含所有人可见的行的版本。 因此,当您第一次访问该表时,强制执行清理以重新处理所有表并创建可见性图。 更糟糕的是,数据页在其自己的标头中具有完全可见性的迹象,因此清洗不仅读取整个表,而且还完全重写了表,从而放下了所需的位。 不幸的是,解决此问题的方法不必早于版本13(
讨论 )。
结论
总结了我有关PostgreSQL隔离和多版本的系列文章。 感谢您的关注,尤其是您的评论-它们会改善材料,并经常指出需要我特别注意的方面。
和我们在一起,继续!