我叫Marko,今年我在
Gophercon Russia上发表了关于一种非常有趣的索引,称为“位图索引”的演讲。 我不仅想以视频格式,而且想作为文章与社区分享。 这是英文版本,您可以
在这里阅读俄语。 请尽情享受!

其他材料,幻灯片和所有源代码可以在这里找到:
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019原始录像:
让我们开始吧!
引言

今天我要谈的是
- 什么是索引。
- 什么是位图索引?
- 使用的地方。 为什么在不使用的地方不使用它。
- 我们将在Go中看到一个简单的实现,然后在编译器中试用。
- 然后,我们将看一下Go汇编中一个稍微不那么简单但明显更快的实现。
- 然后,我将一一解决位图索引的“问题”。
- 最后,我们将看到现有的解决方案。
那么什么是索引?
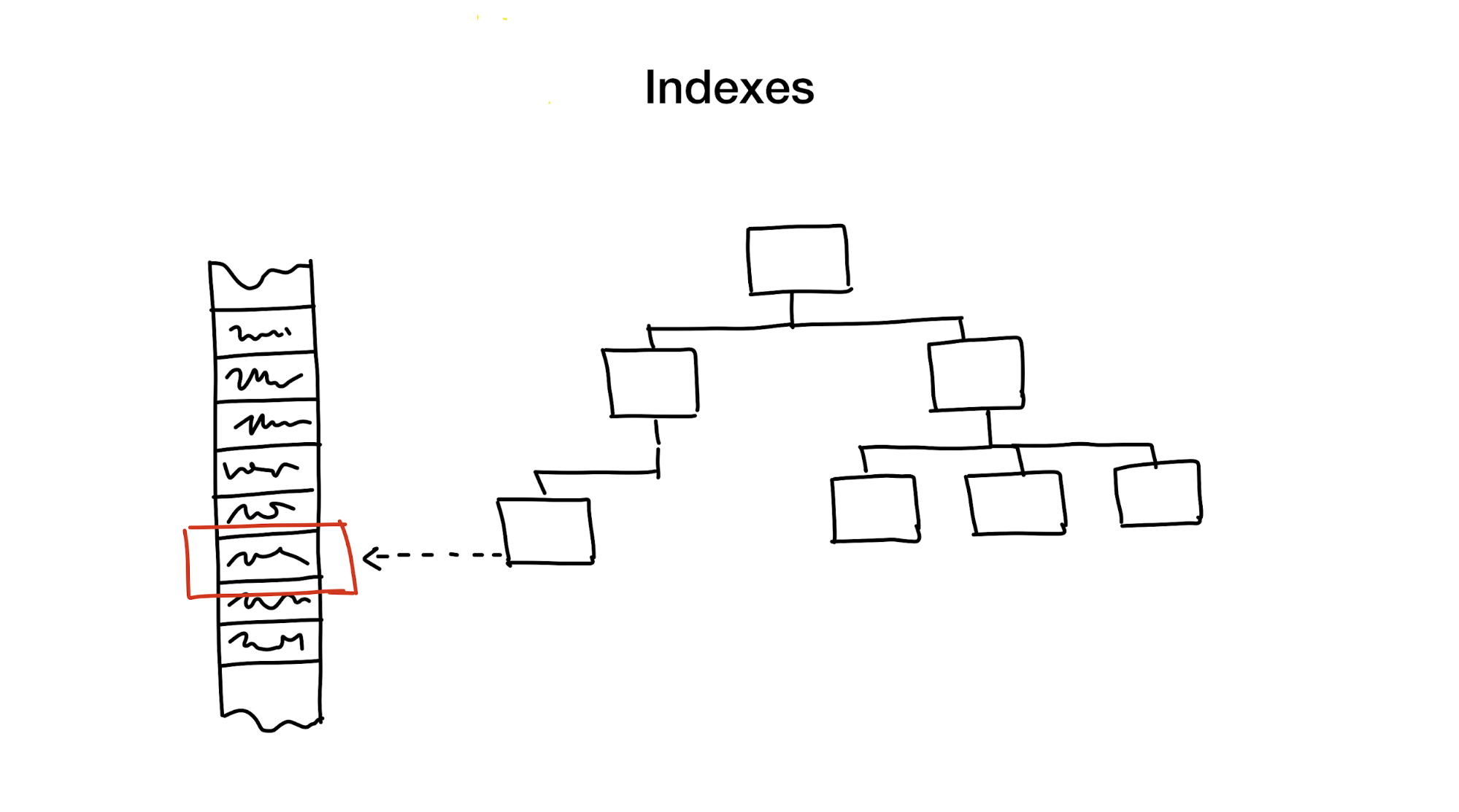
索引是一种独特的数据结构,除了主要数据外,还可以保持更新,以加快搜索请求的速度。 没有索引,搜索将涉及遍历所有数据(在一个过程中也称为“全扫描”),并且该过程具有线性算法复杂度。 但是数据库通常包含大量数据,因此线性复杂度太慢。 理想情况下,我们希望达到对数甚至恒定的复杂度。
这是一个巨大而复杂的主题,涉及很多折衷,但是回顾过去几十年的数据库实现和研究,我认为只有几种常用的方法:

首先,通过将整个区域分成多个较小的部分来缩小搜索区域。
通常,这是使用树来实现的。 这类似于在衣柜中放几箱盒子。 每个盒子都包含一些材料,这些材料被进一步分类为更小的盒子,每个盒子都有特定的用途。 如果我们需要材料,则最好查找标记为“ material”的框,而不是标记为“ cookies”的框。
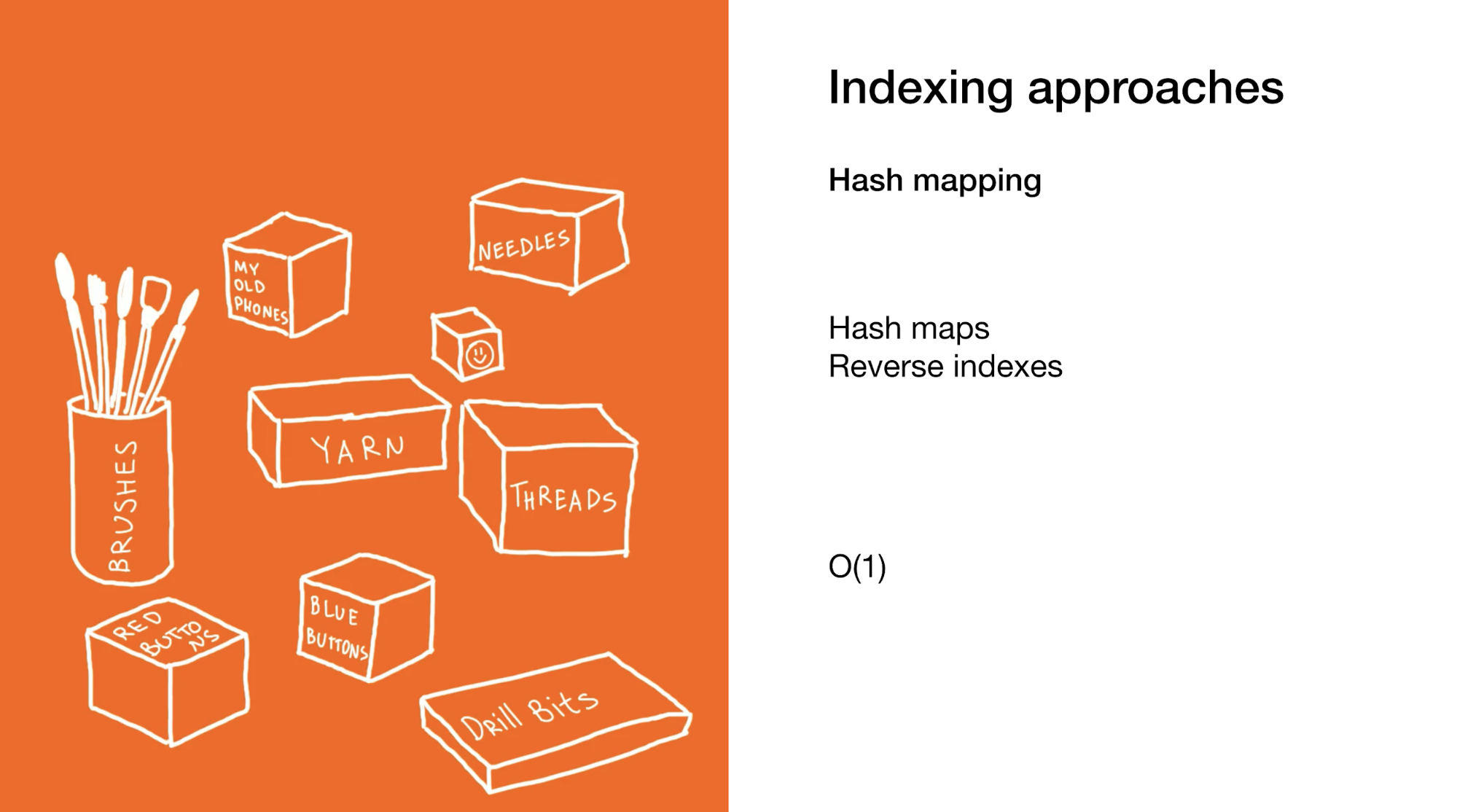
第二个是像哈希图或反向索引中那样立即精确定位特定元素或元素组。 使用哈希映射与前面的示例相似,但是您使用了许多较小的盒子,这些盒子本身并不包含盒子,而是包含最终物品。

第三种方法是根本不需要像布隆过滤器或布谷鸟过滤器中那样进行搜索。 Bloom筛选器可以立即为您提供答案,并节省您在搜索上花费的时间。
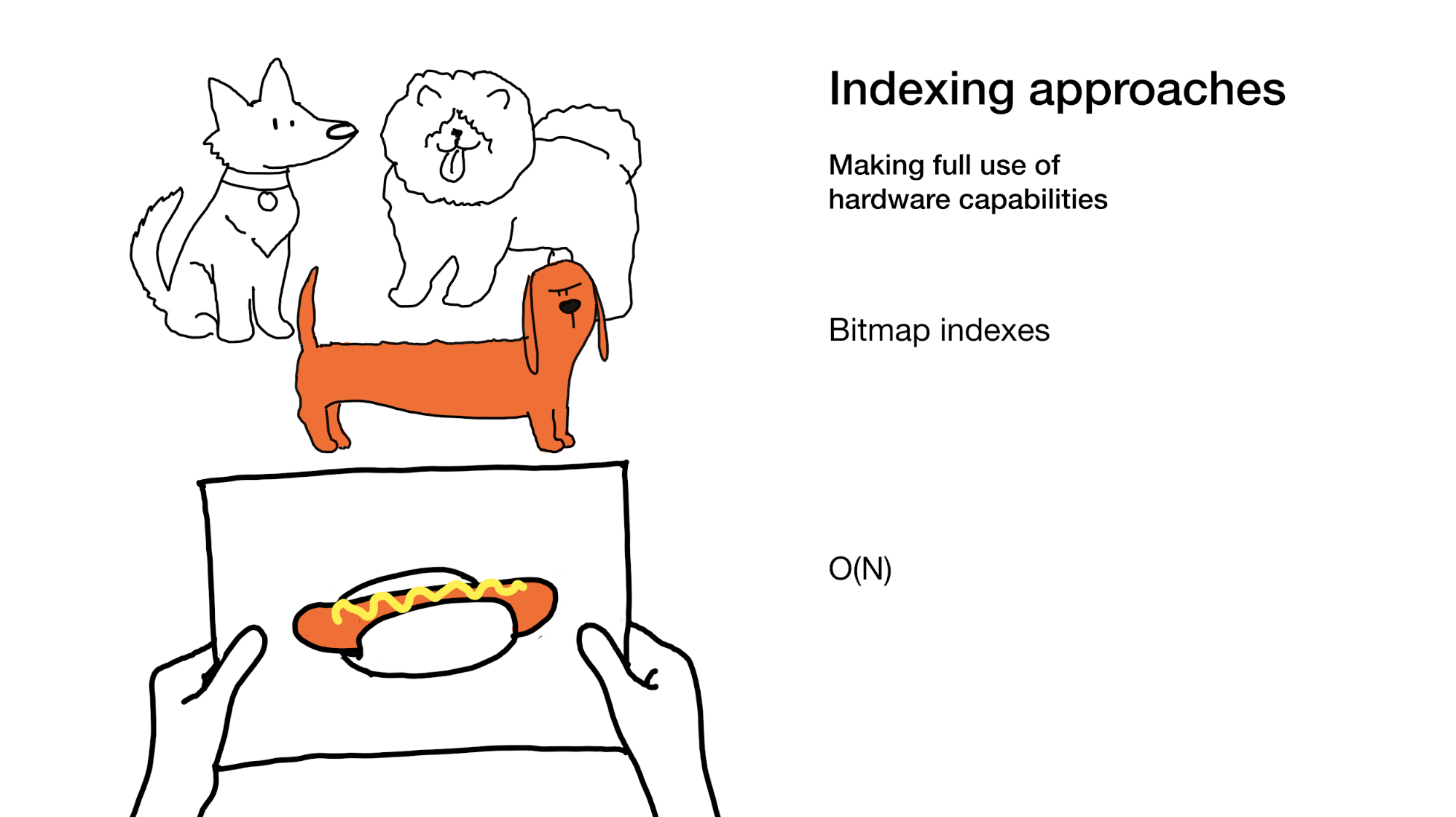
最后一个是通过更好地利用我们的硬件功能(如位图索引)来加快搜索速度。 位图索引有时确实涉及遍历整个索引,是的,但这是以非常有效的方式完成的。
正如我已经说过的那样,搜索具有很多折衷,因此我们经常会使用几种方法来进一步提高速度或覆盖我们所有潜在的搜索类型。
今天,我想谈谈一种鲜为人知的方法:位图索引。
但是我要和谁谈这个话题?
我是Badoo的团队负责人(也许您知道我们的另一个品牌:Bumble)。 我们在全球拥有超过4亿用户,我们所涉及的许多功能都在为您寻找最佳匹配! 对于这些任务,我们使用定制服务,其中使用位图索引。
现在,什么是位图索引?
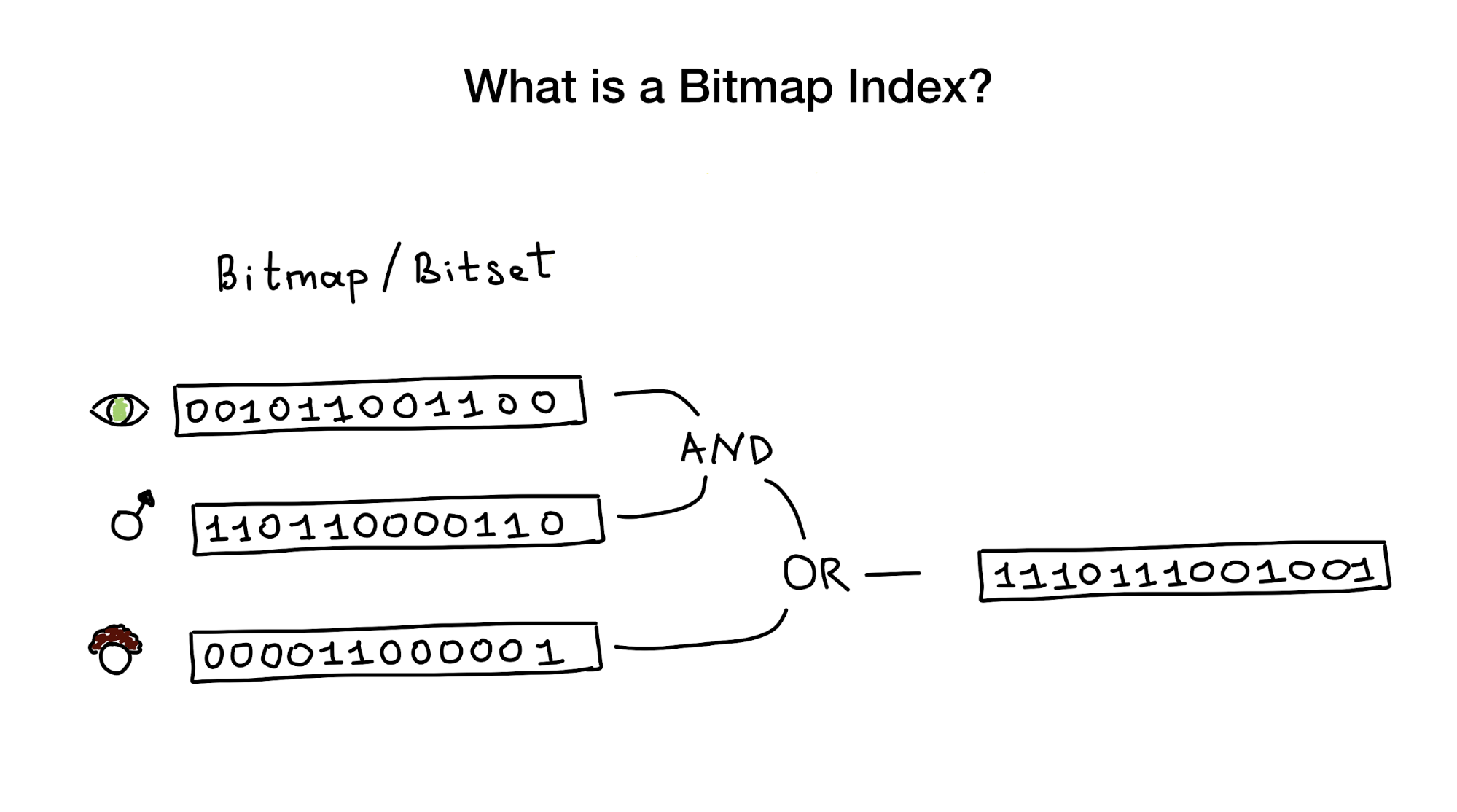
顾名思义,位图索引使用位图(也称为位集)来实现搜索索引。 从鸟瞰的角度来看,该索引由一个或几个表示实体(例如人)及其参数(例如年龄或眼睛颜色)的位图以及一种使用AND,OR,NOT等按位运算来回答搜索查询的算法组成。

如果您的搜索必须将具有低基数(例如,眼睛颜色或婚姻状况)的几列与距基数无限的城市之类的东西组合在一起,则位图索引被认为非常有用且性能较高。
但是,在本文的后面,我将展示位图索引甚至可以用于基数较高的列。
让我们看一个最简单的位图索引示例...

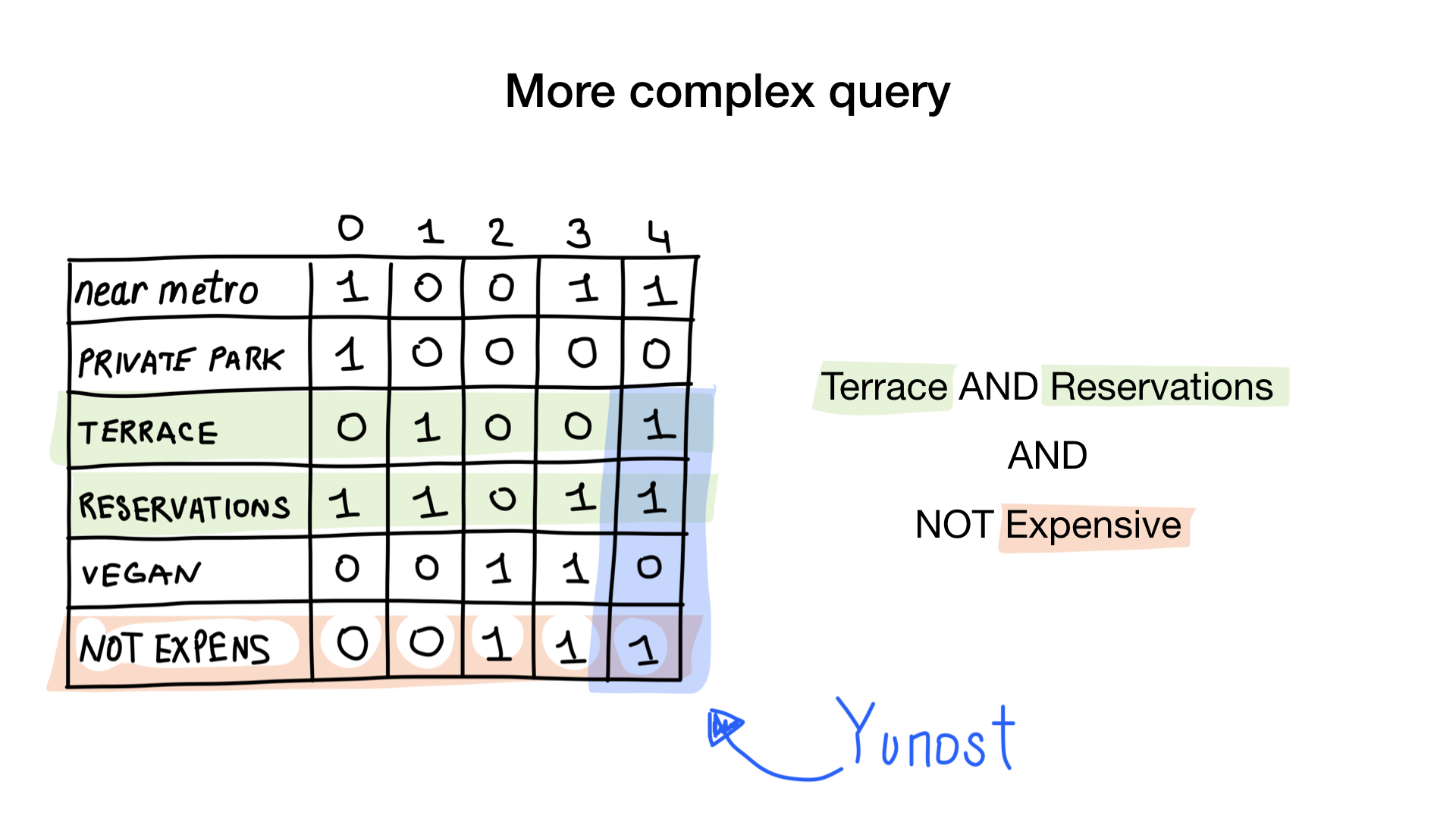
想象一下,我们有一个具有二进制特征的莫斯科餐厅列表:
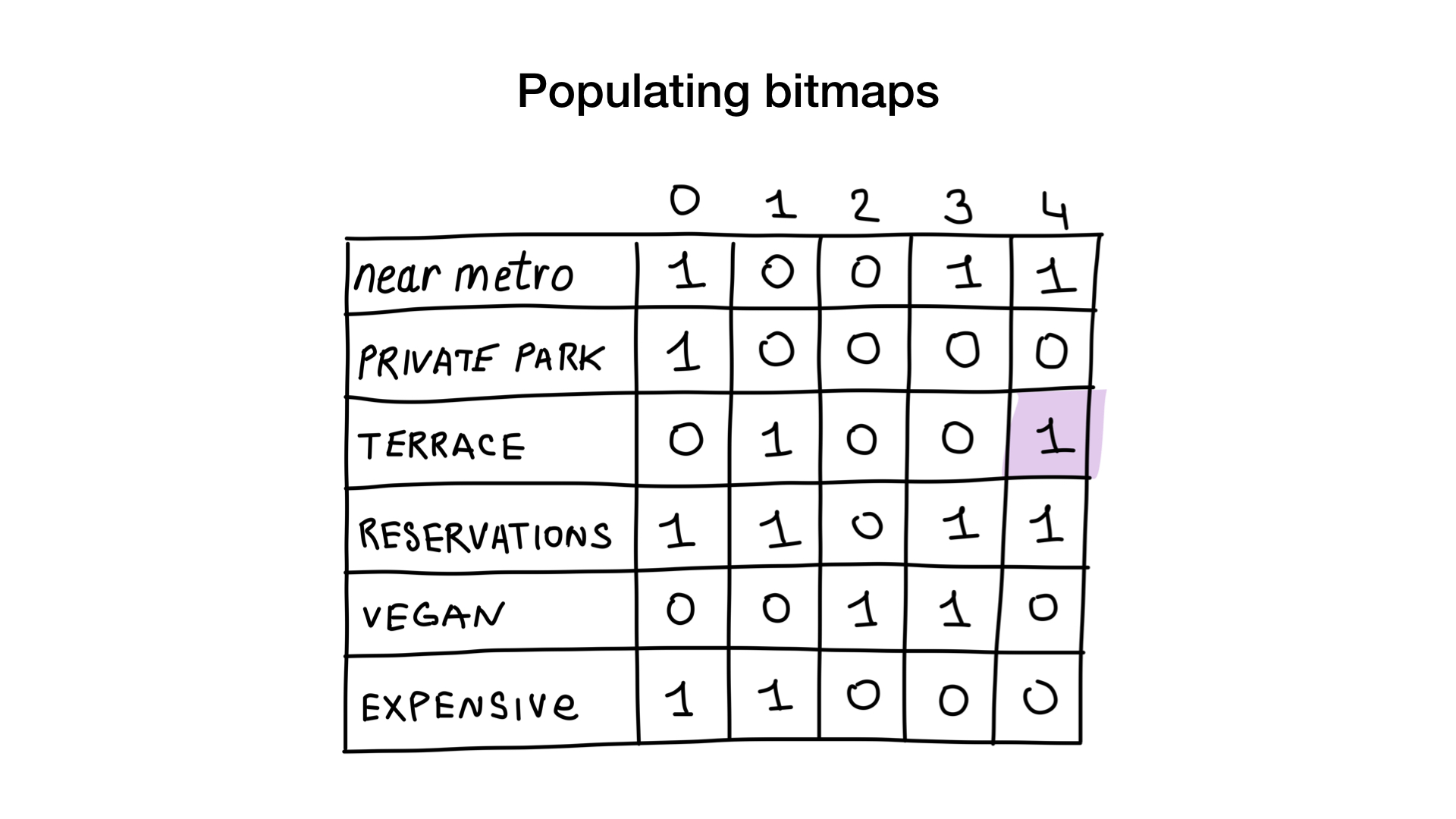
让我们给每个餐厅一个从0开始的索引,并分配6个位图(每个特征一个)。 然后,我们将根据餐厅是否具有特定特征来填充这些位图。 如果4号餐厅有露台,则“露台”位图中的4号位将设置为1(否则为0)。

现在,我们有了最简单的位图索引,可以用来回答诸如
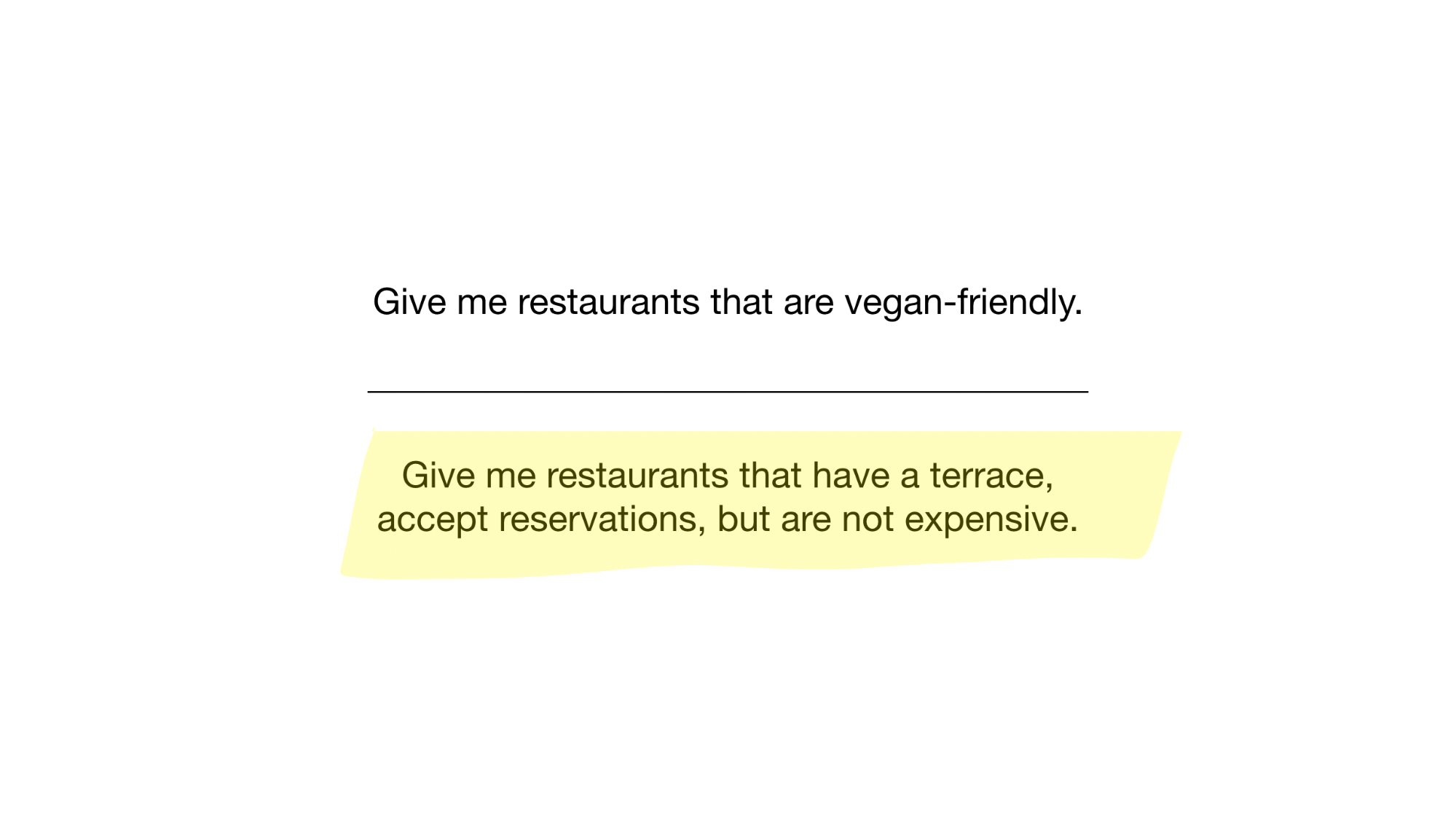
- 给我素食主义者友好的餐厅
- 给我带露台的餐厅,可以接受预订,但价格不贵


怎么了 让我们看看。 第一个问题很简单。 我们只使用“纯素食主义者”位图,并返回所有已设置位的索引。

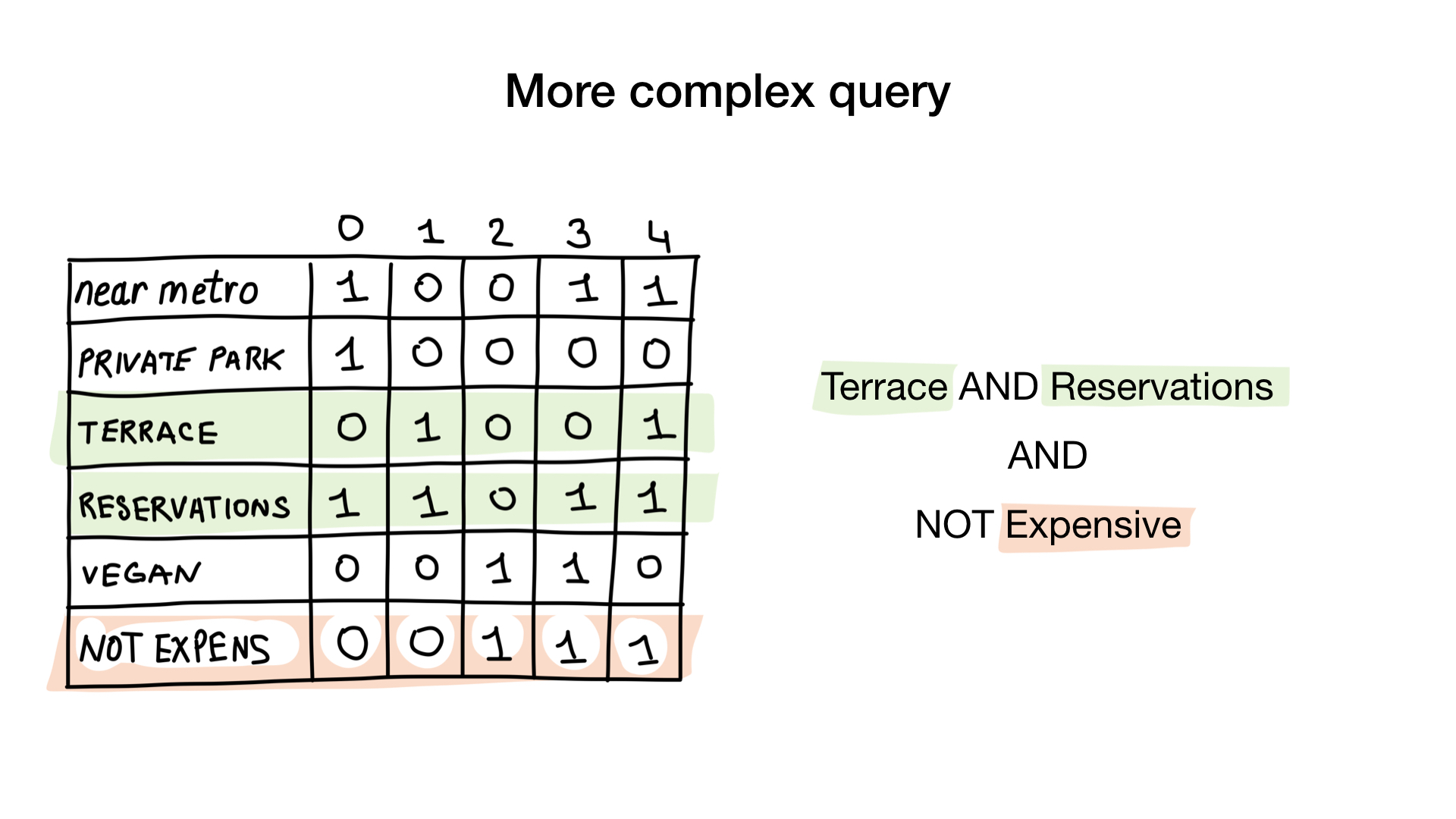
第二个问题稍微复杂一些。 我们将对“昂贵”的位图使用按位操作NOT来获取非昂贵的餐厅,将其与“接受预订”位图和与“具有露台位图”一起使用。 最终的位图将由具有我们想要的所有这些特征的餐厅组成。 在这里,我们看到只有Yunost具有所有这些特征。
这可能看起来有点理论性,但是请放心,我们将在短期内讨论代码。
使用位图索引的位置

如果您使用Google“位图索引”,则90%的结果将指向具有基本位图索引的Oracle DB。 但是,当然,其他DBMS也使用位图索引,不是吗? 不,实际上,他们没有。 让我们一个个地审视通常的嫌疑犯。


- 但是,有一个新男孩正在上路:皮洛萨(Pilosa)。 Pilosa是一种用Go语言编写的新DBMS(请注意,这里没有R,它不是关系型),它基于位图索引。 稍后我们将讨论Pilosa。
实施中
但是为什么呢? 为什么很少使用位图索引? 在回答这个问题之前,我想向您介绍Go中基本的位图索引实现。

位图表示为一块内存。 在Go中,我们为此使用字节片。
每个餐厅特征都有一个位图。 位图中的每个位代表特定餐厅是否具有此特征。

我们将需要两个辅助函数。 一种用于随机填充位图,但具有指定特征的概率。 例如,我认为很少有餐厅不接受预订,大约20%的餐厅是纯素食主义者。
另一个功能将通过位图为我们提供餐厅列表。


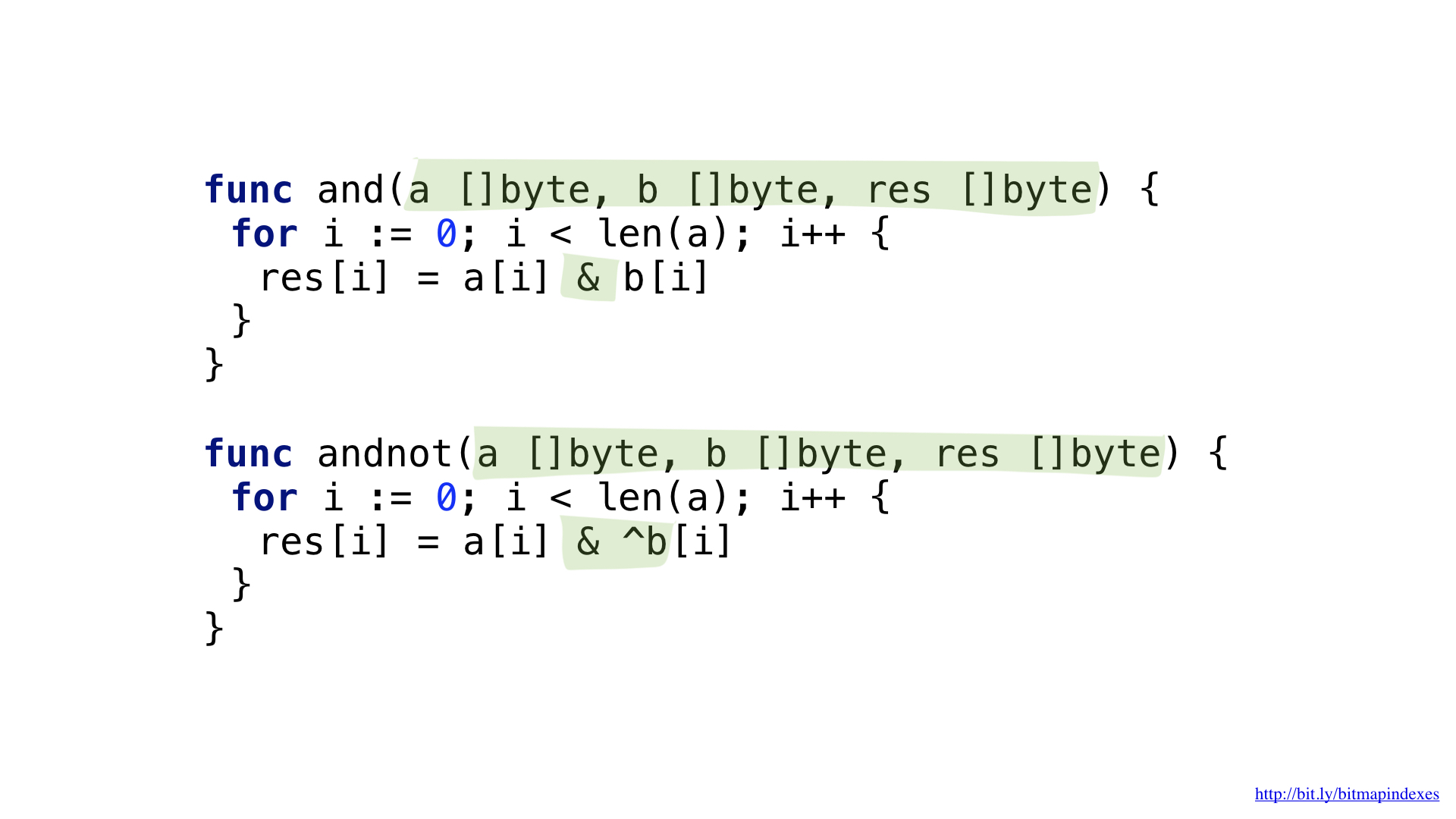
为了回答“给我带露台的餐厅接受预订但并不昂贵”的问题,我们需要两个操作:NOT和AND。
我们可以通过引入复杂的操作AND NOT来稍微简化代码。
我们具有每个功能。 这两个函数都要经过我们的切片,每个切片中都获取对应的元素,然后进行运算并将结果写入所得的切片中。
现在,我们可以使用位图和函数来获取答案。

即使我们的函数非常简单,此处的性能也不是很好,并且通过在每次函数调用时不返回新的分片,我们节省了很多分配。
在使用pprof进行性能分析之后,我注意到go编译器错过了非常基本的优化之一:函数内联。
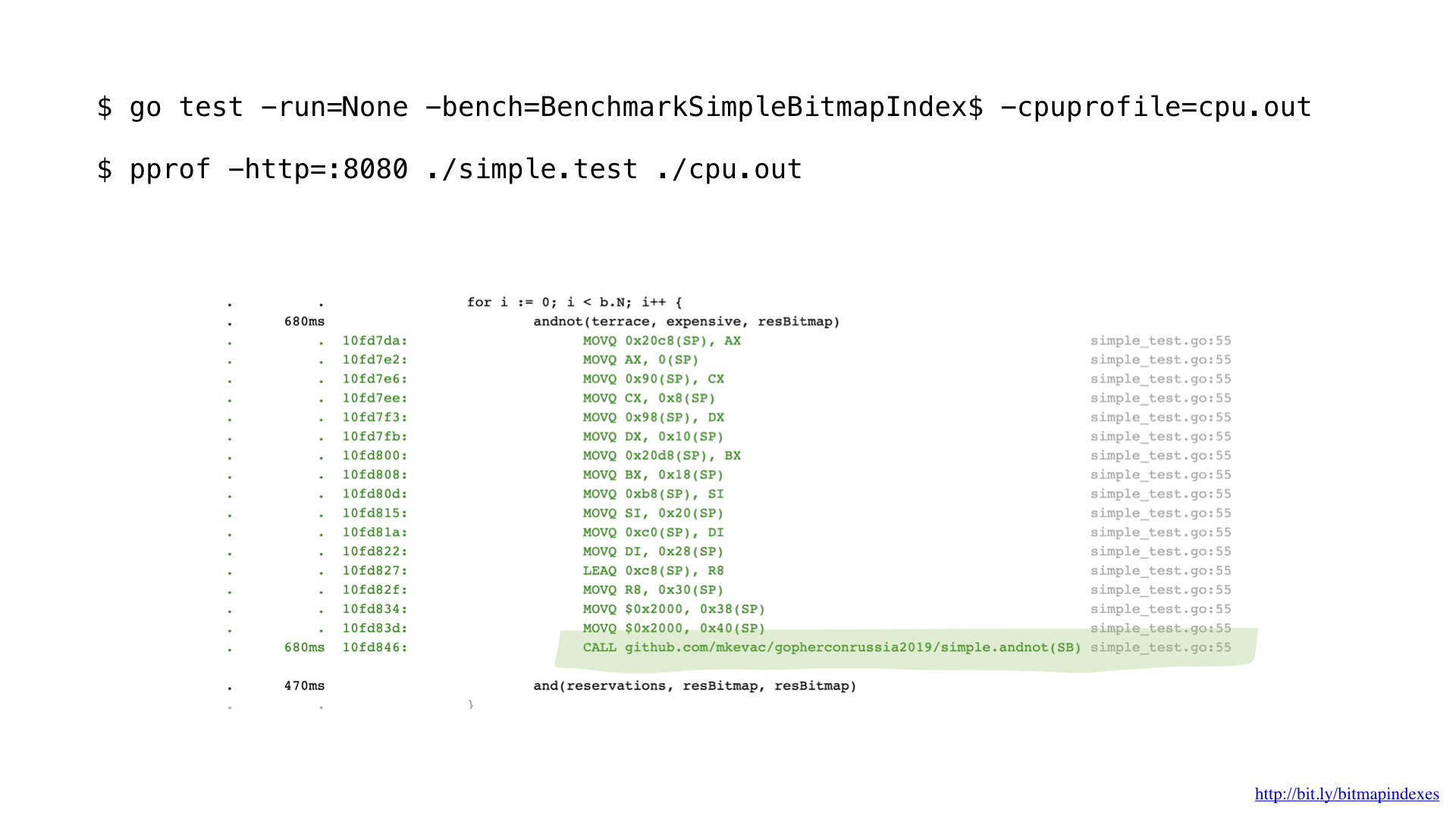
您会发现,Go编译器在病理上害怕通过切片循环,并拒绝内联具有切片的任何函数。
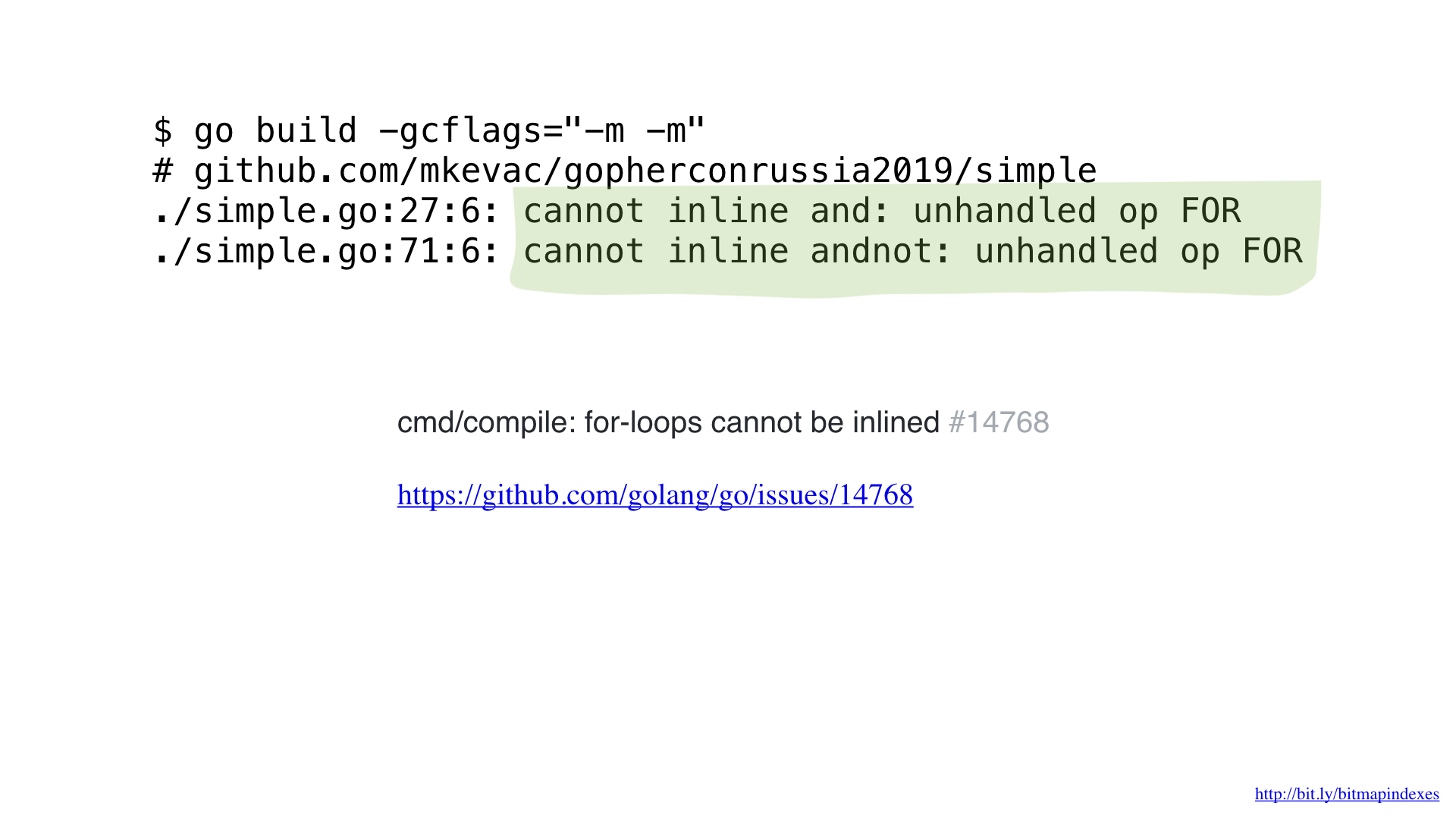
但是我不怕它们,可以通过将goto用于我的循环来欺骗编译器。


如您所见,内联为我们节省了大约2微秒。 还不错!

当您仔细查看装配输出时,很容易发现另一个瓶颈。 Go编译器在我们的循环中包括范围检查。 Go是一种安全的语言,编译器担心我的三个位图的长度可能不同,并且缓冲区可能溢出。
让我们让编译器平静下来,向我证明我的所有位图的长度都相同。 为此,我们可以在函数开头添加一个简单的检查。
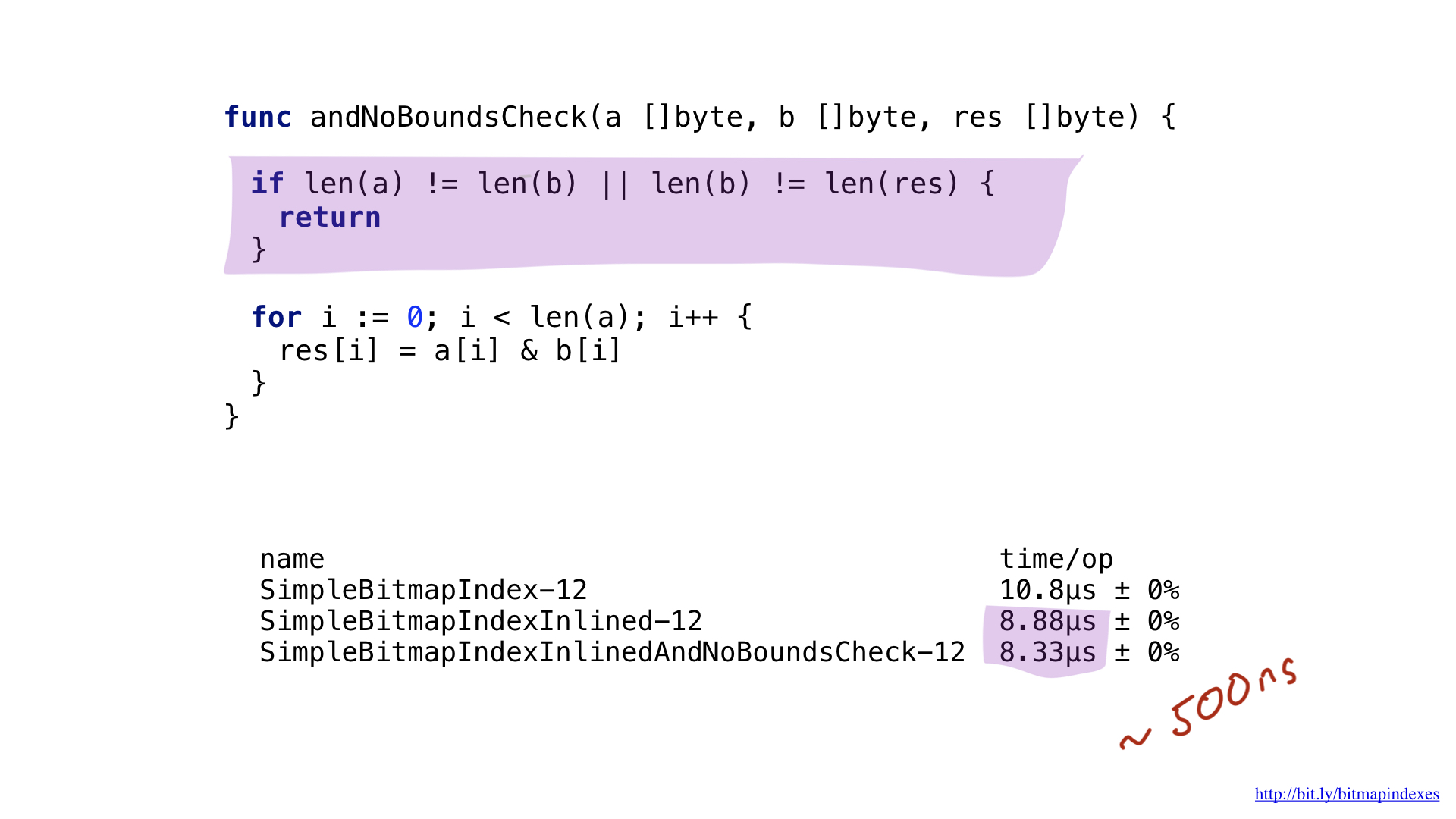
有了此检查,go编译器将很乐意跳过范围检查,我们将节省几纳秒。
组装实施
好了,因此我们设法通过简单的实现压缩了更多性能,但是这个结果远不如当前的硬件差。
您会看到,我们正在做的是非常基本的按位运算,而我们的CPU则非常有效。
不幸的是,我们正在为CPU提供很小的工作量。 我们的函数逐字节进行操作。 通过使用uint64的切片,我们可以轻松地调整实现以使用8字节块。

如您在此处看到的,对于8倍的批处理大小,我们获得了大约8倍的性能,因此性能提高几乎是线性的。
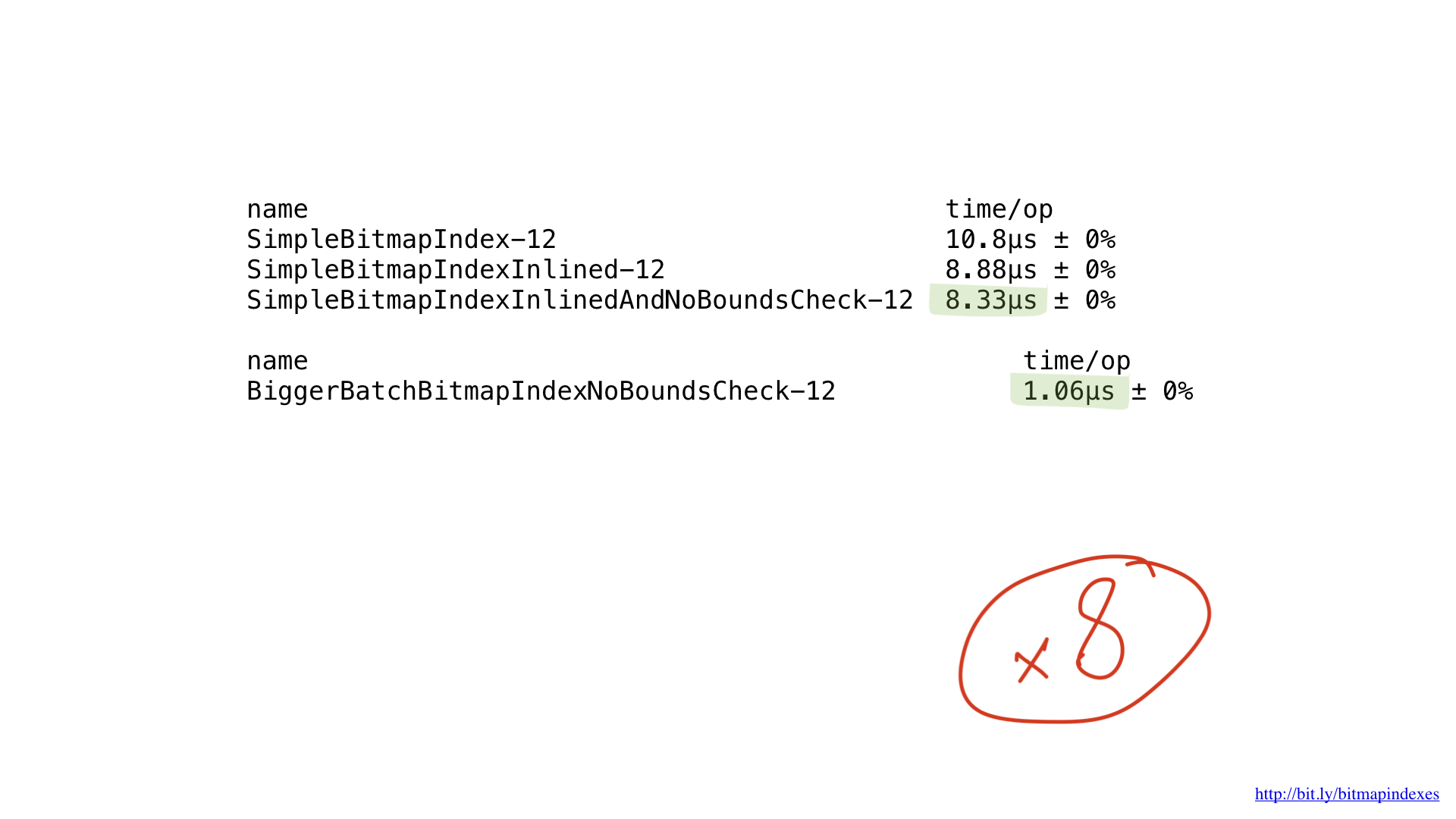

但这还不是终点。 我们的CPU能够处理16字节,32字节甚至64字节的块。 这些操作称为SIMD(单指令多数据),而使用此类CPU操作的过程称为矢量化。
不幸的是,Go编译器在矢量化方面不是很好。 现在,我们唯一可以向量化代码的方法就是使用Go汇编并自己添加这些SIMD指令。

去组装是一种奇怪的野兽。 您可能会认为汇编是与您要编写的体系结构绑定的东西,但是Go的汇编更像是IRL(中间表示语言):它与平台无关。 几年前,罗伯·派克(Rob Pike)对此进行了精彩的演讲。
此外,Go使用了一种不寻常的plan9格式,该格式与AT&T和Intel格式均不同。

可以肯定地说编写Go汇编代码很无聊。
对我们来说幸运的是,已经有两个更高级的工具可以帮助编写Go汇编:PeachPy和avo。 两者都分别从用Python和Go编写的高级代码生成go汇编。

这些工具简化了寄存器分配和循环之类的事情,总之降低了进入Go汇编程序设计领域的复杂性。
我们将在这篇文章中使用避免,以便我们的程序看起来几乎像普通的Go代码。

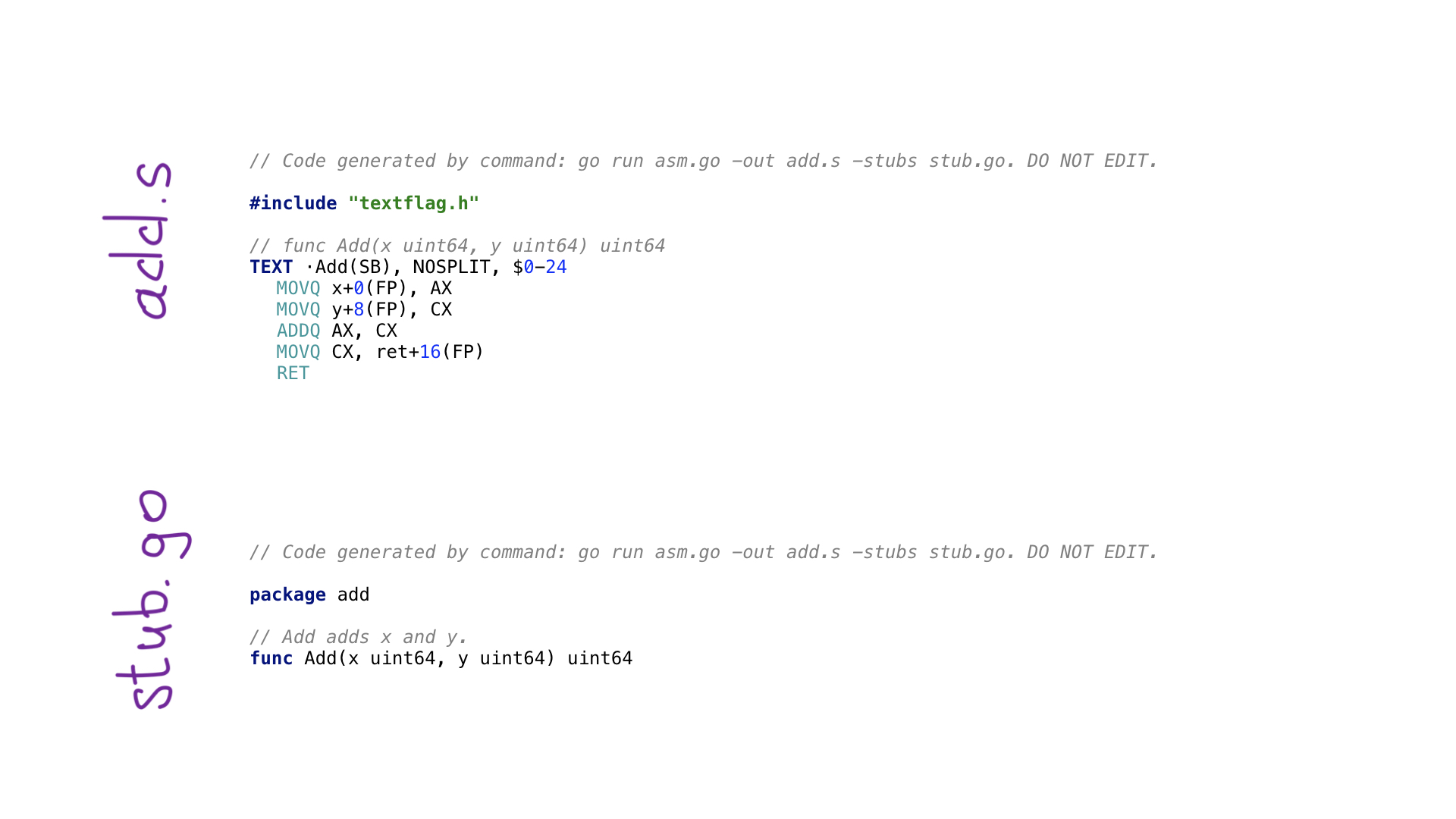
这是avo程序的最简单示例。 我们有一个main()函数,该函数定义了一个称为Add()的函数,该函数将两个数字相加。 有一些辅助函数,用于按名称获取参数并获取可用的常规寄存器之一。 这里有每个汇编操作的功能,例如ADDQ,还有一些辅助功能,用于将寄存器中的结果保存为结果值。

调用go generate将执行此avo程序,并将创建两个文件
- 用生成的汇编代码添加
- stub.go带有连接我们的go和汇编代码所需的函数头
现在我们已经了解了avo的功能,让我们看一下我们的功能。 我已经实现了我们函数的标量和SIMD(矢量)版本。
让我们先看看标量版本的外观。

如前面的示例所示,我们可以要求一个通用注册簿,而避免给我们合适的注册簿。 我们不需要为参数跟踪以字节为单位的偏移量,从而避免了这种情况。

以前,出于性能原因和欺骗go编译器,我们从循环切换为使用goto。 在这里,我们从一开始就使用goto(跳转)和标签,因为循环是更高级别的构造。 在组装中,我们只有跳跃。

其他代码应该很清楚。 我们使用跳转和标签模拟循环,从两个位图中获取一小部分数据,使用按位操作之一将其合并,然后将结果插入到生成的位图中。

这是我们得到的结果汇编代码。 我们不必计算偏移量和大小(绿色),也不必处理特定的寄存器(红色)。
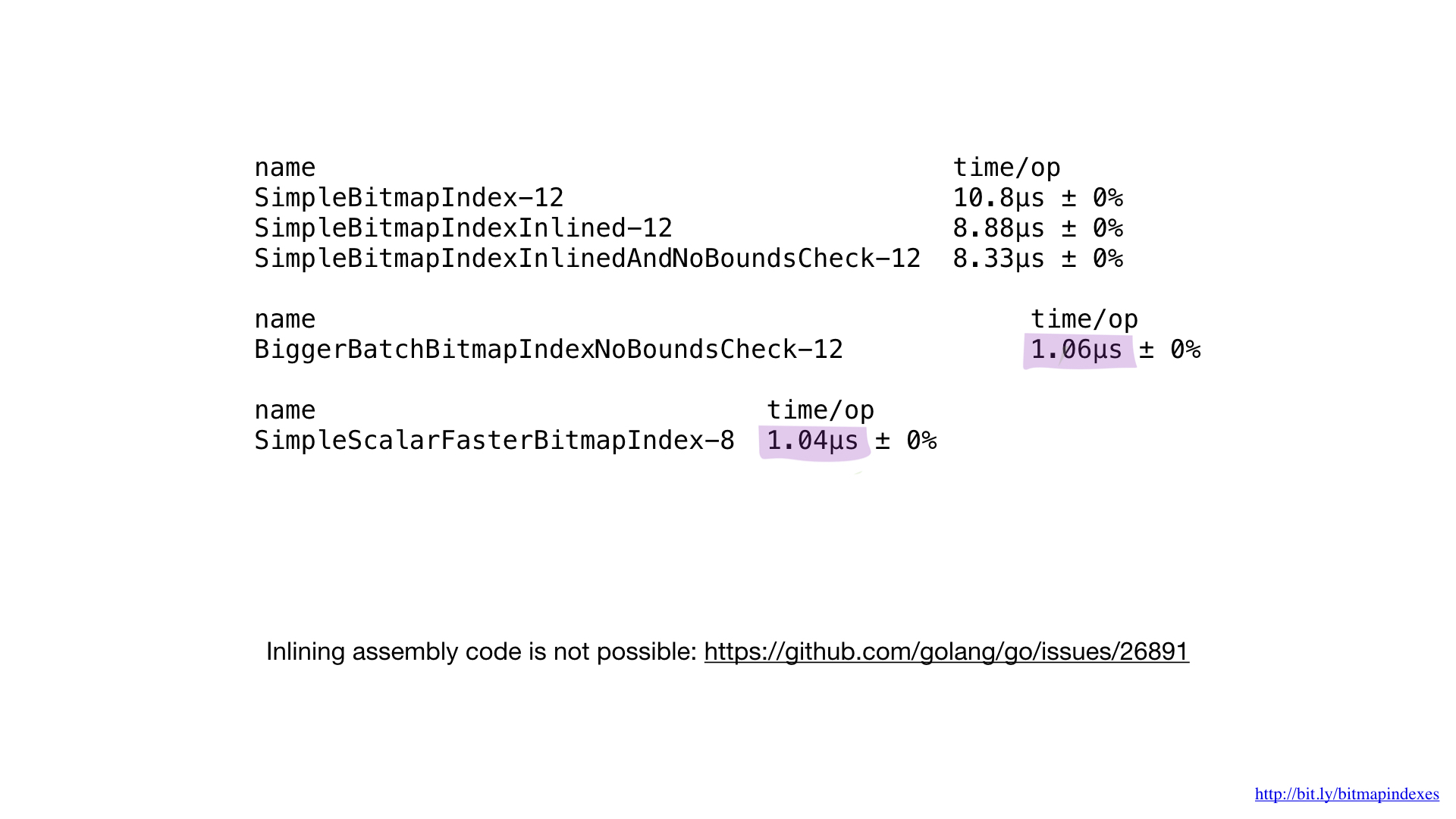
如果将汇编中的该实现与之前编写的最佳实现进行比较,我们将看到性能与预期相同。 我们没有做任何不同的事情。
不幸的是,我们不能强迫Go编译器内联以asm编写的函数。 它完全不支持它,并且对此功能的要求已经存在了一段时间。 这就是为什么小型的asm函数无法发挥作用的原因。 您要么需要编写更大的函数,使用新的软件包math / bit,要么完全跳过asm。
现在让我们编写函数的矢量版本。

我选择使用AVX2,因此我们将使用32字节的块。 它在结构上与标量非常相似。 我们加载参数,要求通用寄存器等。
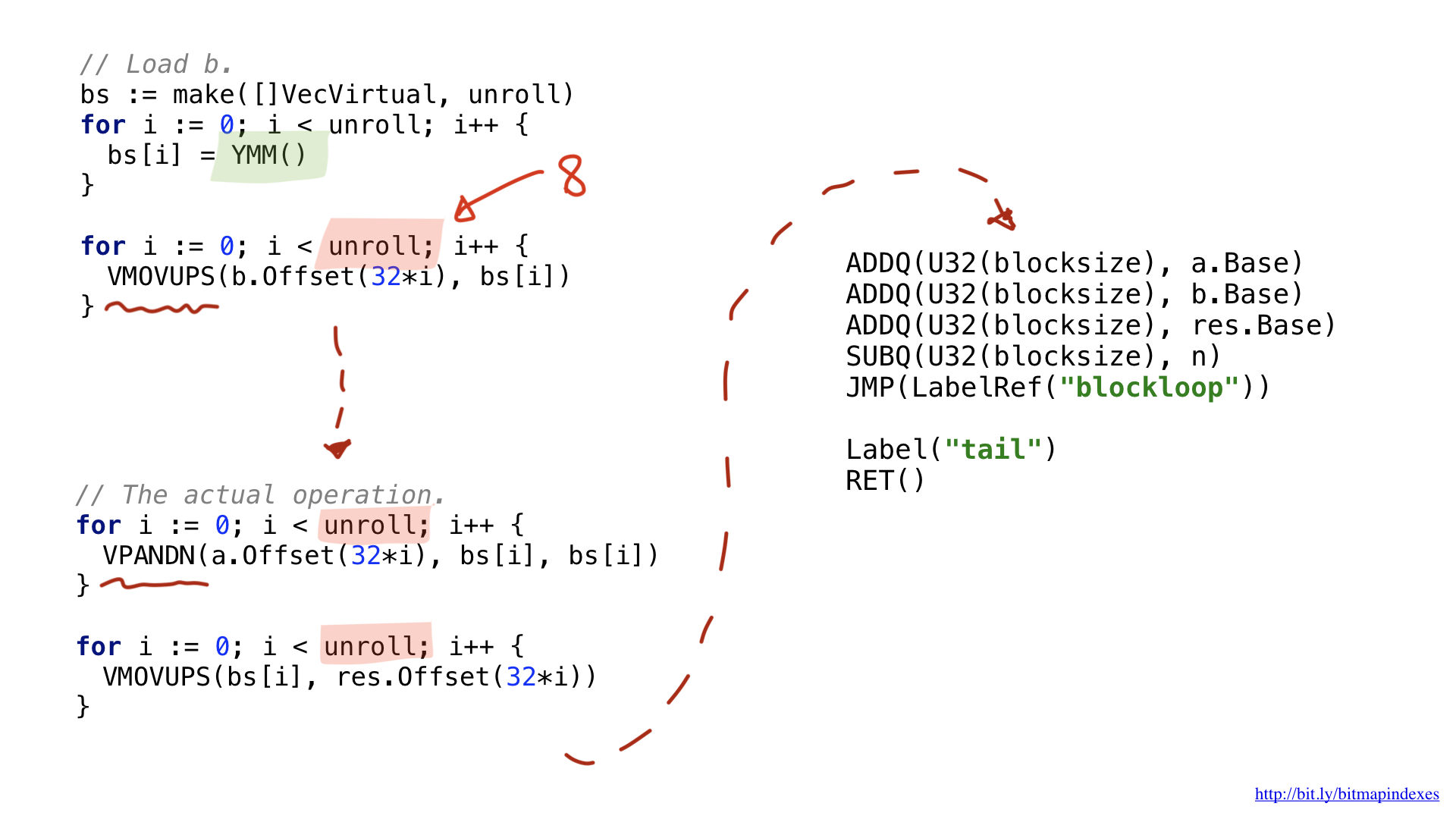
更改之一与向量操作使用特定的宽寄存器有关。 对于32个字节,它们具有Y前缀,这就是为什么在那里看到YMM()的原因。 对于64字节,它们将具有Z前缀。
另一个差异与我执行的称为展开或循环展开的优化有关。 我选择部分展开循环并按顺序执行8次循环操作,然后再返回。 这种技术通过减少我们拥有的分支来加快代码的速度,并且它几乎受到我们可用寄存器数量的限制。
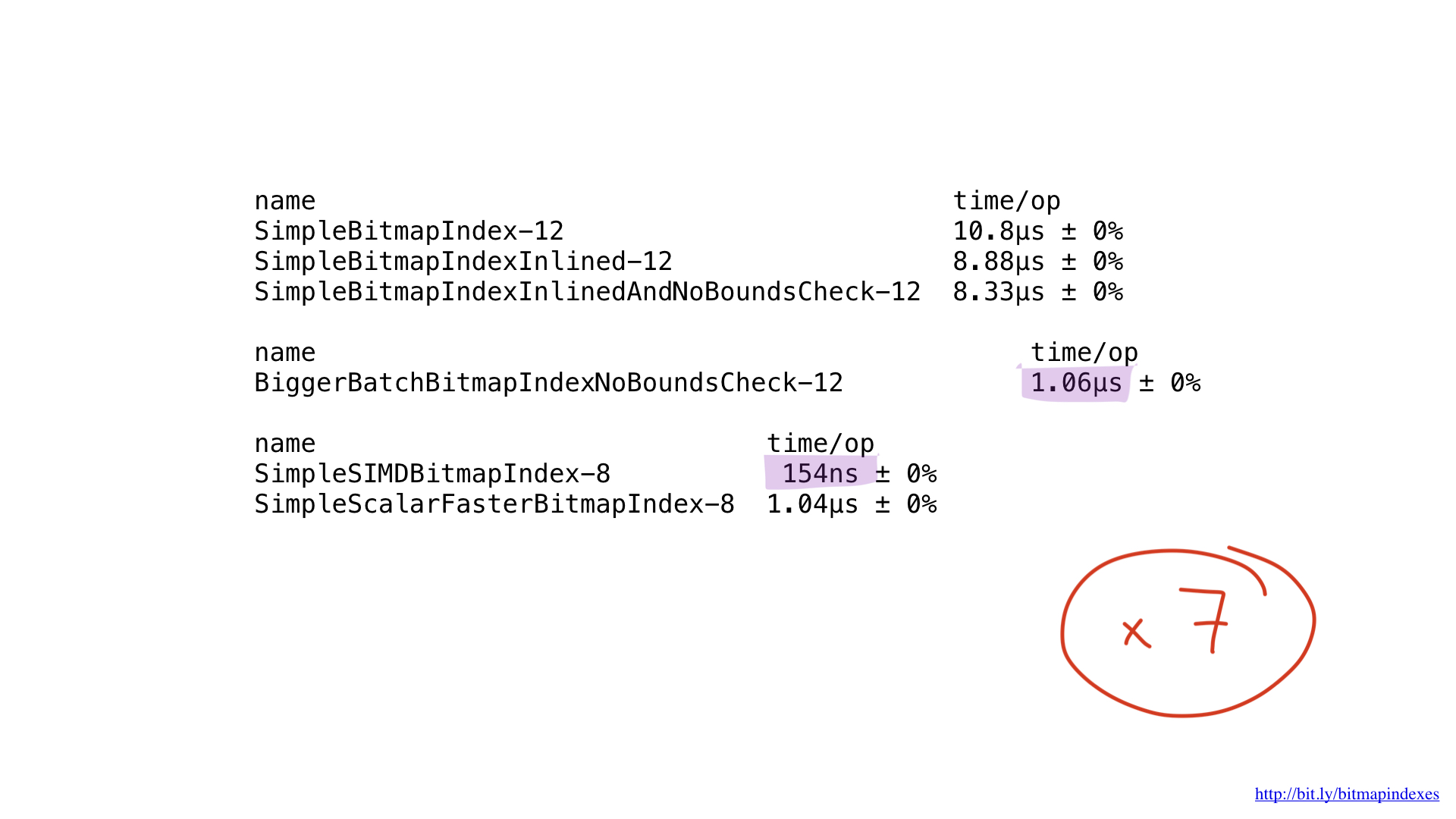
至于性能……太神奇了。 与之前的最佳产品相比,我们获得了大约7倍的改进。 令人印象深刻,对不对?
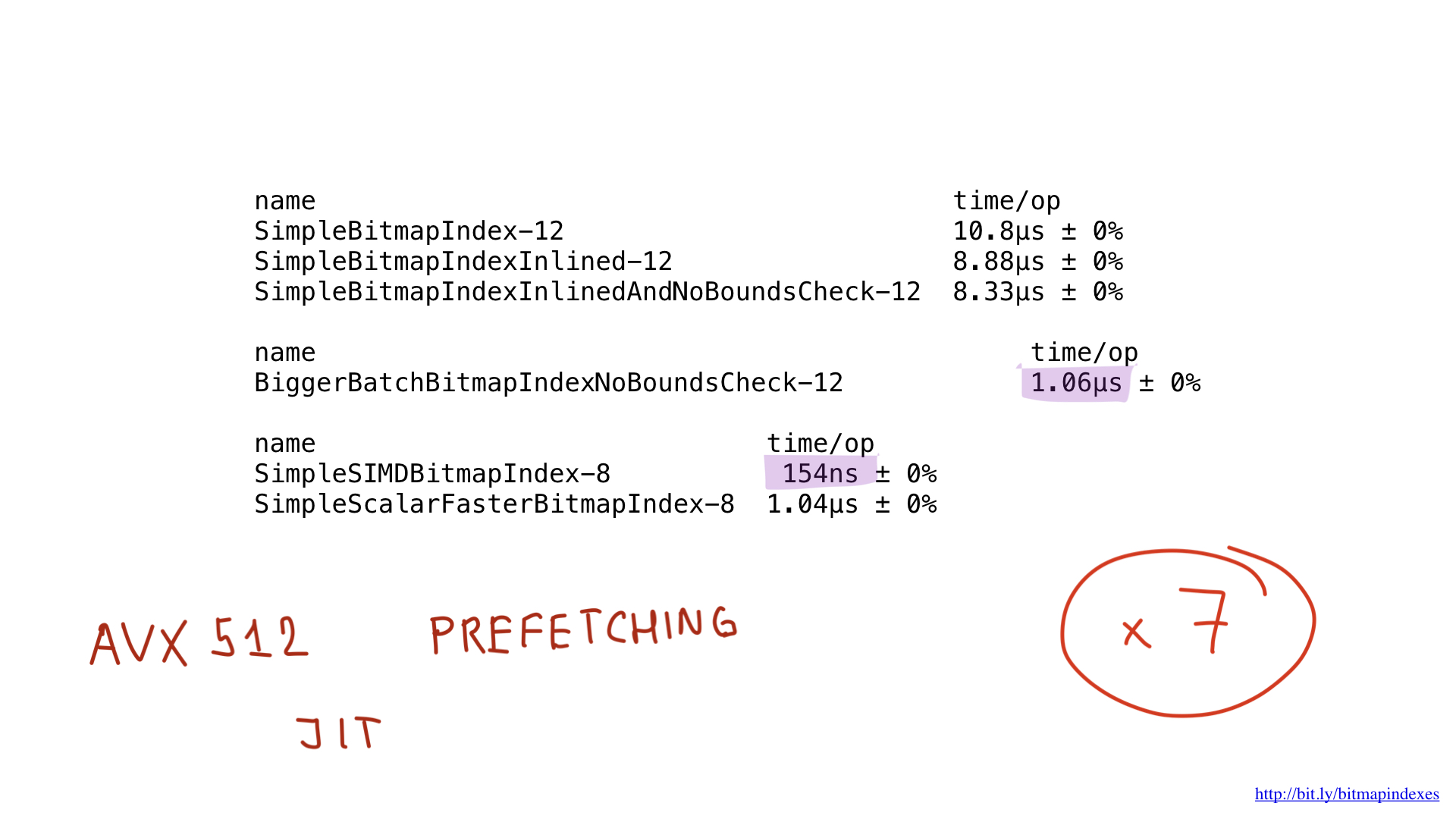
通过使用AVX512,预取甚至使用JIT(及时)编译代替“手动”查询计划生成器,应该甚至可以进一步改善这些结果,但这将是一个完全不同的主题。
位图索引问题
既然我们已经了解了asm的基本实现和令人印象深刻的实现速度,那么让我们谈谈位图索引没有得到广泛使用的事实。 怎么会这样

较早的出版物为我们提供了这三个原因。 但是我认为最近的这些问题现在已经“修复”或处理了。 由于我们的时间不多,在这里我不会对此进行详细介绍,但是值得快速浏览一下。
高基数问题
因此,我们被告知位图索引仅适用于低基数字段。 即,字段具有很少的不同值,例如性别或眼睛颜色。 原因是对于高基数值,通用表示(每个不同的值一位)可能会变得很大。 结果,即使人口稀少,位图也可能变得巨大。
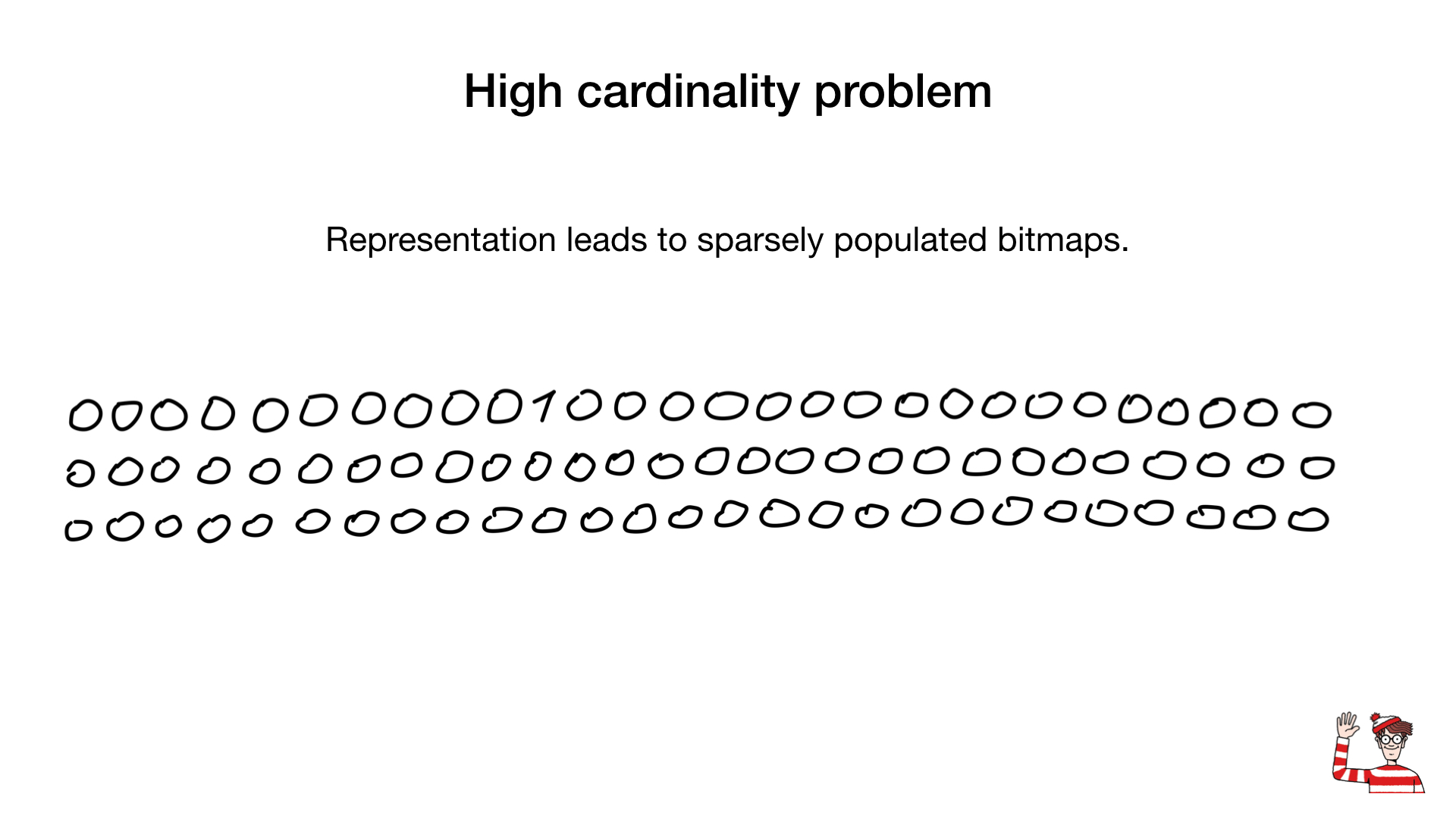
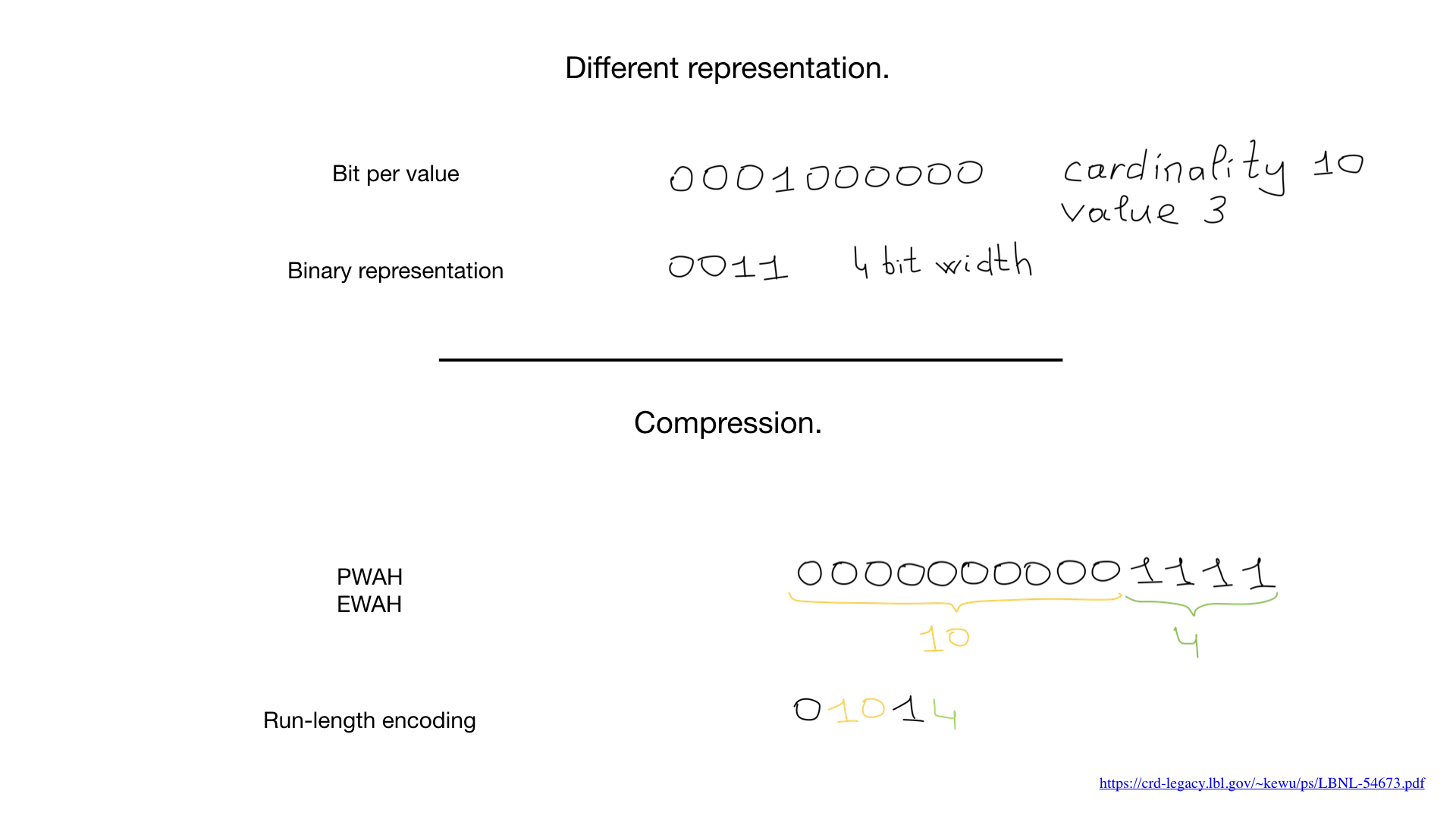
有时,可以将不同的表示形式用于这些字段,例如此处所示的二进制数字表示形式,但最大的改变规则是压缩。 科学家们提出了惊人的压缩算法。 几乎所有的算法都是基于广泛的游程算法,但是更令人惊奇的是,我们不需要解压缩位图就可以对它们进行按位运算。 普通的按位操作适用于压缩的位图。

最近,我们已经看到混合方法看起来像“咆哮的位图”。 咆哮的位图使用三种独立的位图表示形式:位图,数组和“位运行”,它们平衡了这三种表示形式的使用,以最大程度地提高速度并最小化内存使用。
咆哮的位图可以在一些使用最广泛的应用程序中找到,并且有许多语言的实现,包括Go的几种实现。
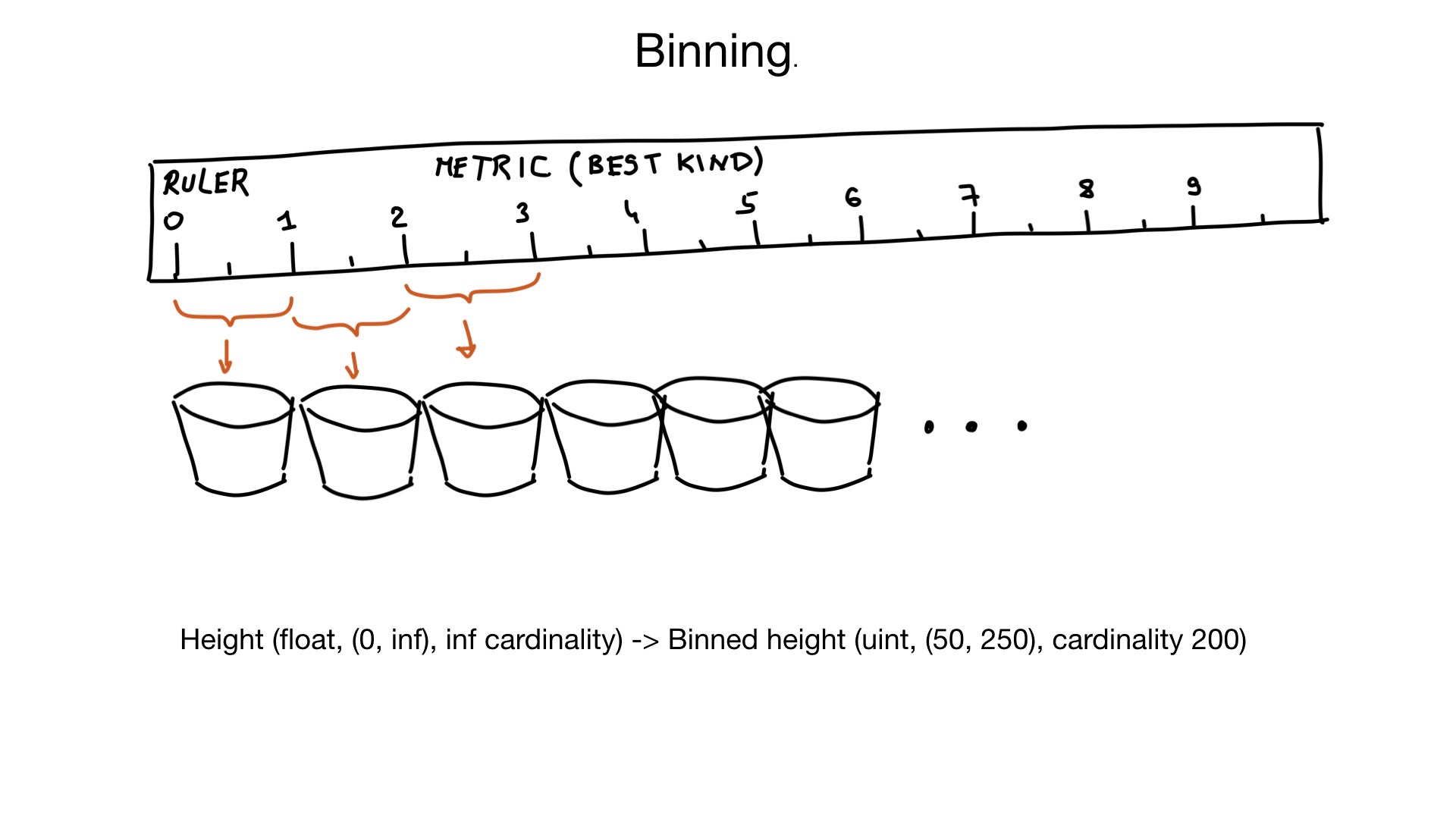
可以帮助处理高基数字段的另一种方法称为合并。 想象一下,我们有一个代表人的身高的字段。 高度是浮动的,但我们不这么认为。 没人关心您的身高是185.2还是185.3厘米。 因此,我们可以使用“虚拟垃圾箱”将相似的高度挤压到同一垃圾箱中:在这种情况下为1厘米垃圾箱。 而且,如果您假设身高小于50厘米或大于250厘米的人很少,我们可以将身高转换为具有大约200个元素基数的字段,而不是几乎无限的基数。 如果需要,我们可以稍后对结果进行其他过滤。
高通量问题
位图索引不好的另一个原因是更新位图可能会很昂贵。
数据库并行执行更新和搜索,因此,当可能有数百个线程通过位图进行搜索时,您必须能够更新数据。 为了防止数据争用或数据一致性问题,将需要使用锁。 在有一个大锁的地方,存在锁争用。
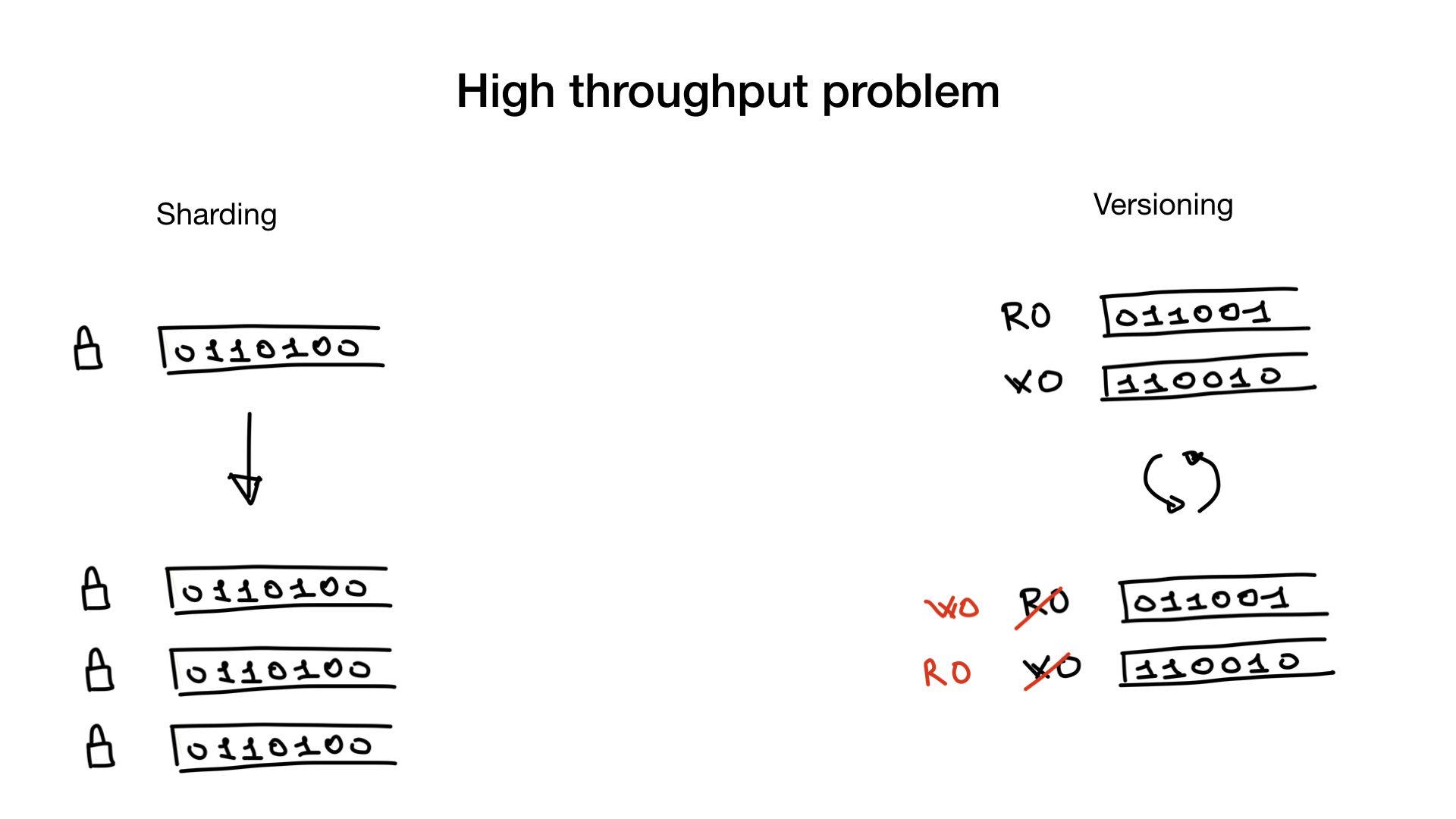
如果确实有此问题,可以通过分页索引或使用索引版本(如果适用)来解决。
分片很简单。 您可以像在数据库中分片用户那样分片它们,现在,您拥有多个锁,而不是一个锁,这大大减少了锁争用。
有时可行的另一种方法是使用版本索引。 您具有用于搜索的索引,并且具有用于写入和更新的索引。 然后以较低的频率(例如100或500 ms)复制和切换它们。
但是,仅当您的应用程序能够忍受过时的过时搜索索引时,这种方法才可行。
当然,这两种方法也可以一起使用。 您可以使用分片的版本索引。
非平凡查询
另一个位图索引问题与在范围查询中使用位图索引有关。 乍一看,“与”或“或”之类的按位运算对于范围查询(例如“给我每晚200至300美元的酒店房间”)似乎非常有用。

一个幼稚且效率很低的解决方案是获取每个价格点(从200到300)的结果,然后对结果进行或。

更好的方法是使用分箱,将我们的酒店放入价格范围为50美元的价格范围内。 这种方法将使我们的搜索费用减少约50倍。
但是,通过使用一种特殊的编码可以使范围查询成为可能和快速,也可以很容易地解决此问题。 在文献中,这种位图称为范围编码位图。

在范围编码的位图中,我们不仅将特定位设置为200,而且还将所有位设置为200或更高。 300也一样。
因此,通过使用这种范围编码的位图表示,仅两次通过位图就可以回答范围查询。 我们得到所有价格小于或等于300美元的酒店,并从结果中删除所有价格小于或等于199美元的酒店。 完成

您会感到惊讶,但使用位图甚至可以进行地理查询。 诀窍是使用Google S2之类的表示法或类似的表示法,该表示法将坐标包围在可以表示为三个或更多索引线的几何图形中。 如果使用这种表示形式,则可以将地理查询表示为这些线索引上的多个范围查询。
现成的解决方案
好吧,我希望我引起了您的兴趣。 现在,您有了更多的工具可以使用,如果您需要在服务中实施类似的操作,那么您将知道在哪里寻找。
一切都很好,但是并不是每个人都有时间,耐心和资源来自己实现位图索引,特别是在涉及更高级的东西(如SIMD指令)时。
不用担心,有两种开源产品可以为您提供帮助。

咆哮
首先,有一个我已经提到过的库,叫做“咆哮的位图”。 该库实现了咆哮的“容器”以及如果要实现完整的位图索引时将需要的所有按位操作。
不幸的是,go实现不使用SIMD,因此它们的性能要比C实现低。
皮洛萨
另一个产品是称为Pilosa的DBMS,它仅具有位图索引。 这是一个最近的项目,但是最近获得了很多关注。
E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0“>
Pilosa在下面使用咆哮的位图,并给出,简化或解释了我今天一直在告诉您的几乎所有内容:装箱,范围编码的位图,字段的概念等。
让我们简要地看一下使用中的Pilosa的示例...

您看到的示例与我们之前看到的非常相似。 我们创建pilosa服务器的客户端,为我们的特征创建索引和字段。 如前所述,我们使用具有某些概率的随机数据填充字段,然后执行搜索查询。
您在这里看到相同的基本模式。 相交或与AND-ed与露台相交,并与保留相交,并不昂贵。
结果是预期的。

最后,我希望将来的某个时候,像mysql和postgresql这样的数据库将获得新的索引类型:位图索引。

结束语

如果您仍然醒着,我感谢您。 时间的紧缺意味着我不得不略过这篇文章中的很多内容,但是我希望它是有用的,甚至是鼓舞人心的。
即使您现在不需要位图索引,它也是了解和理解的有用信息。 将它们作为投资组合中的另一个工具。
在我的演讲中,我们看到了我们可以使用的各种性能技巧以及Go当时遇到的困难。 这些绝对是每个Go程序员都需要知道的事情。
这就是我现在为您准备的。 非常感谢!