服务的用户越多,他们需要帮助的可能性就越高。 技术支持聊天是一个显而易见的解决方案,但费用昂贵。 但是,如果您使用机器学习技术,则可以节省一些钱。
该机器人现在可以回答简单的问题。 此外,可以训练聊天机器人确定用户的意图并捕获上下文,以便他可以在无需人工干预的情况下解决用户的大多数问题。 受欢迎的助手Oleg的开发商Vladislav Blinov和Valery Baranova将如何解决这个问题。
在开发聊天机器人的任务中,从简单的方法过渡到更复杂的方法,我们将分析实际的实现问题,并查看可获得的质量提升以及成本提升。
Vladislav Blinov是
Tinkoff对话系统的高级开发人员,经常抛出缩写:ML,NLP,DL等。 此外,研究生院还通过机器学习和神经网络研究幽默的建模。
瓦莱里亚·巴拉诺娃(Valeria Baranova)在Python的NLP领域中写了很酷的东西已有5年了。 现在,在互动系统团队中,Tinkoff制作了聊天机器人,并为学生开设了机器学习课程。 他还从事计算幽默领域的研究,也就是说,他教AI了解笑话并提出新的笑话-Valeria和Vladislav
将在UseData Conf上
谈论这一点。
Tinkoff银行的服务已被数百万人使用。 为了为如此众多的用户提供全天候的支持,需要大量的人员,这导致高昂的服务成本。 使用聊天机器人可以自动回答用户的常见问题似乎很合逻辑。
用户意图或意图
聊天机器人需要做的第一件事就是了解
用户的需求 。 此任务称为意图或意图分类。 此外,将在此任务的框架内考虑所有模型和方法。
让我们看一个意图分类的例子。 如果您写:“转移一百个Lera”,则聊天机器人Oleg将会理解这是汇款的目的,即用户转移资金的意图。 或者更确切地说,莱拉需要转移100卢布的金额。
我们将比较方法并在测试样本中测试其工作质量,该样本由与用户的真实对话组成。 我们的样本包含30,000多个标记示例和170个意图,例如:去电影院,搜索餐厅,开设或关闭存款等。 奥列格(Oleg)也有很多自己的见解,他可以与您聊天。
字典分类
在对意图进行分类的任务中,最简单的事情就是
使用字典 。 例如,如果单词“ translate”出现在用户的短语中,请考虑进行汇款。
让我们看一下这种简单方法的质量。
如果分类器仅通过“翻译”一词将用户的意图定义为“汇款”,那么质量已经很高。 精度-88%,而完整性很低,仅等于23%。 这是可以理解的:“翻译”一词并不能描述“向某人汇款”的所有可能性。
但是,这种方法具有以下优点:
- 不需要标记的采样(如果您不研究模型,则不需要采样)
- 如果您能很好地编译字典,则可以得到很高的准确性(但这会花费时间和资源)。
但是,由于很难描述任何类别的所有变体,因此这种解决方案的完整性可能很低。
考虑一个反例。 如果除了汇款意图之外,“转移”还可以包括第二个意图-“向运营商转移”。 当我们向运算符添加新的翻译意图时,我们得到不同的结果。
准确性下降了18点,而完整性当然没有提高。 这表明需要更高级的方法。
文字分析
在使用机器学习之前,您需要了解如何将文本表示为矢量。 最简单的方法之一是
使用tf-idf向量 。
tf-idf向量考虑了用户短语中每个单词的出现,并考虑了集合中单词的总出现。 在不同的文本中经常发现的单词在此向量表示中的权重较小。
让我们看一下tf-idf表示形式上的线性模型的质量(在我们的例子中为logistic回归)。
结果,
完整性急剧
增加 ,并且准确性仍然可以与字典的使用相媲美,f1度量(准确性和完整性之间的加权谐波均值)也有所增加。 也就是说,模型本身已经了解了哪些词对哪种意图都很重要-您无需自己发明任何东西。
数据可视化
数据可视化有助于了解意图的外观以及它们在空间中的分组情况。 但是由于尺寸较大,我们无法直接可视化tf-idf表示形式,因此我们将使用
尺寸压缩方法-t-SNE 。
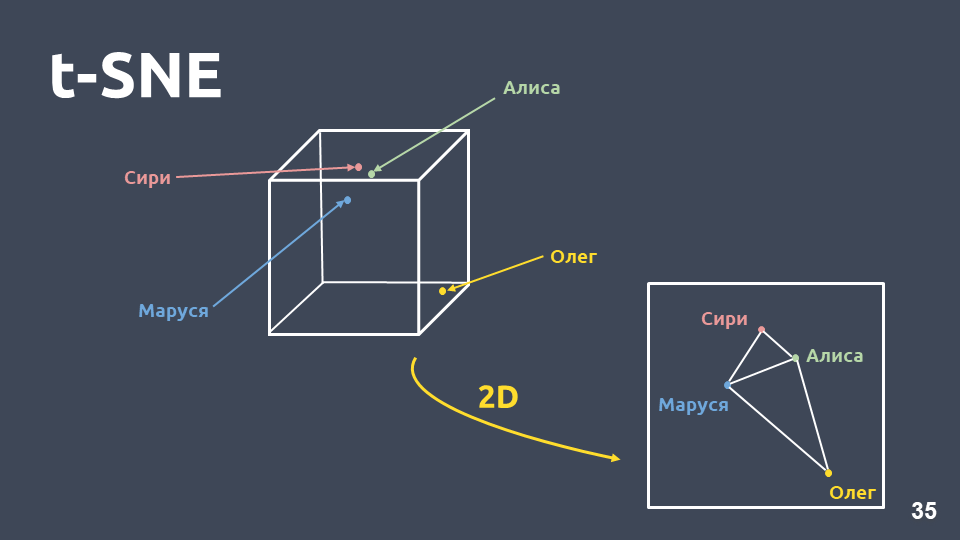
此方法与PCA之间的主要区别在于,当转移到二维空间时,将
保留对象之间的相对距离 。
tf-idf上的t-SNE(前10个意图),F1得分0.92上面列出了我们集合中出现的前10个意图。 有不属于任何意图的绿点,并且用不同颜色标记的10个簇是不同的意图。 可以看出,其中一些分组得很好。 加权
f1量度为0.92-这很多,您已经可以使用它。
因此,在tf-idf上使用线性分类器:
- 与使用字典相比,完整性要高得多,并且精度相当;
- 无需思考哪个词对应哪个意图。
但是也有缺点:
- 词汇量有限,您只能对训练样本中出现的那些单词权重;
- 不考虑改写;
- 不考虑单词在文本中出现的顺序。
改写
让我们更详细地考虑换词问题。
Tf-idf向量只能在单词相交的文本中接近。 向量之间的接近度可以通过它们之间的角度的余弦值来计算。 对于特定示例,计算了矢量表示tf-idf中的余弦接近度。
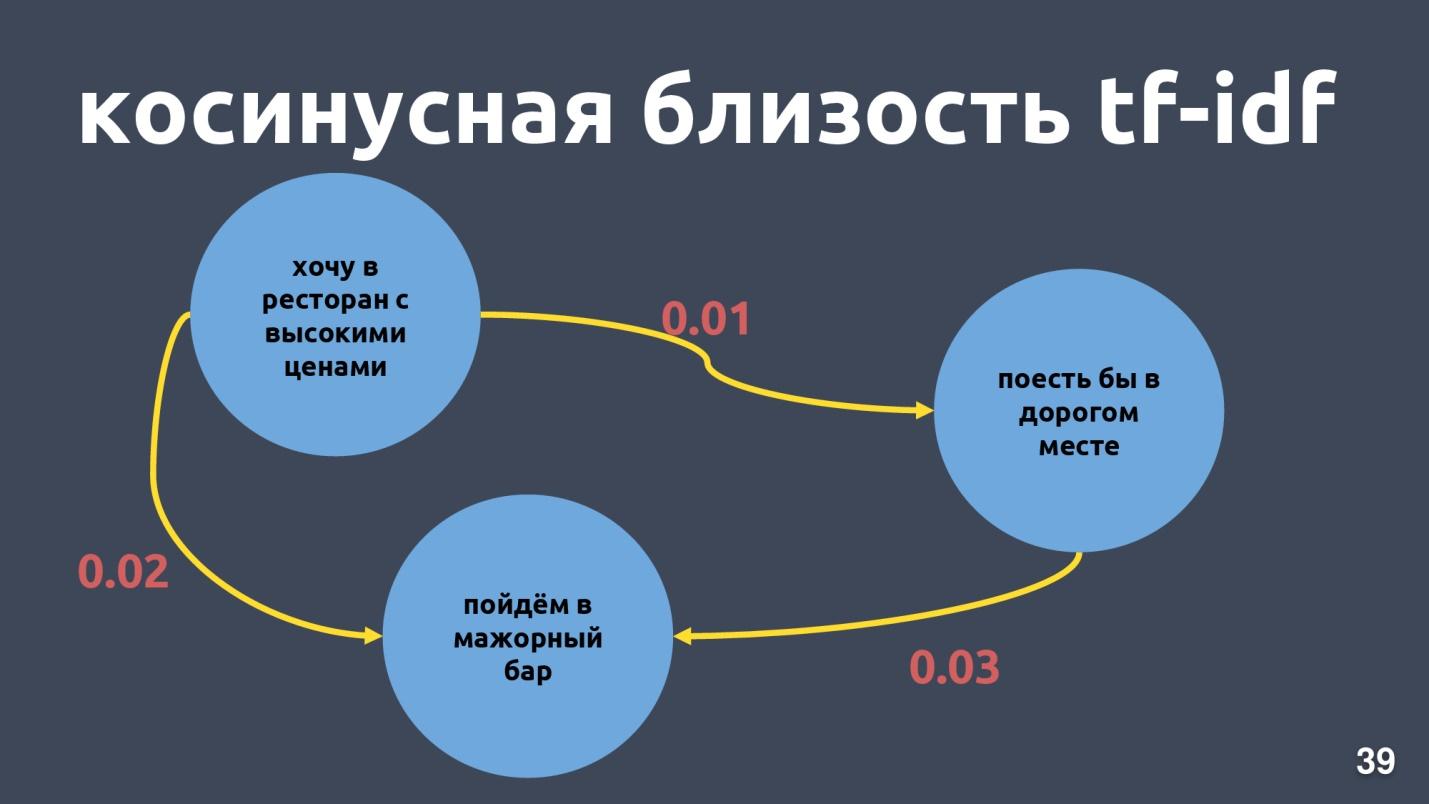
对于tf-idf的矢量表示,它们不是非常接近的短语,尽管对我们而言,它是相同的意图和相同的类。
该怎么办? 例如,您可以将一个单词表示为一个整体,而不是一个数字,这称为“单词嵌入”。
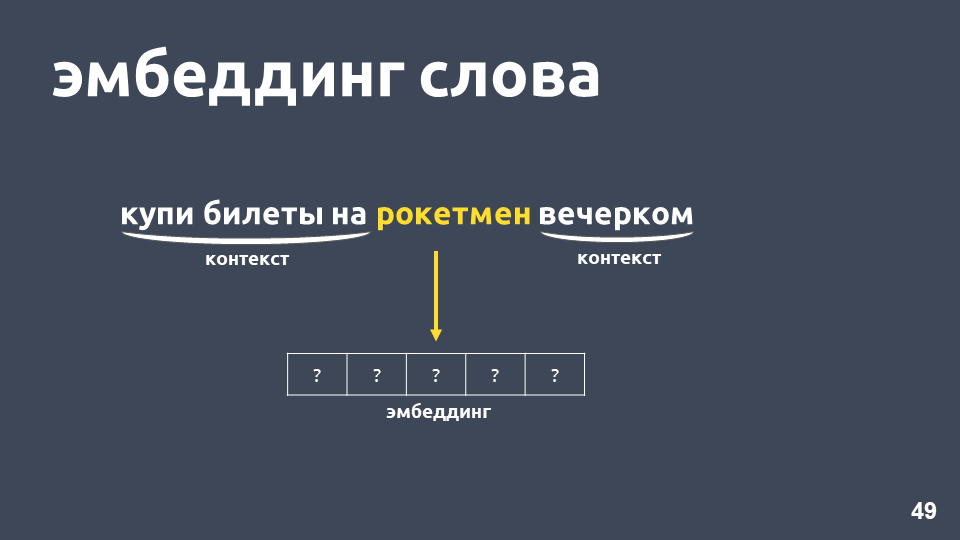
解决此问题的最流行模型之一是在2013年提出的。 此后被称为
word2vec,并已被广泛使用。
学习Word2vec的一种方法大致如下:我们获取文本,从上下文中获取一个单词,然后将其丢弃,然后从上下文中获取另一个随机单词,并将这两个单词作为一个热门矢量呈现。 一键热向量是根据字典维数的向量,其中只有与字典中单词索引对应的坐标的值为1,其余为0。
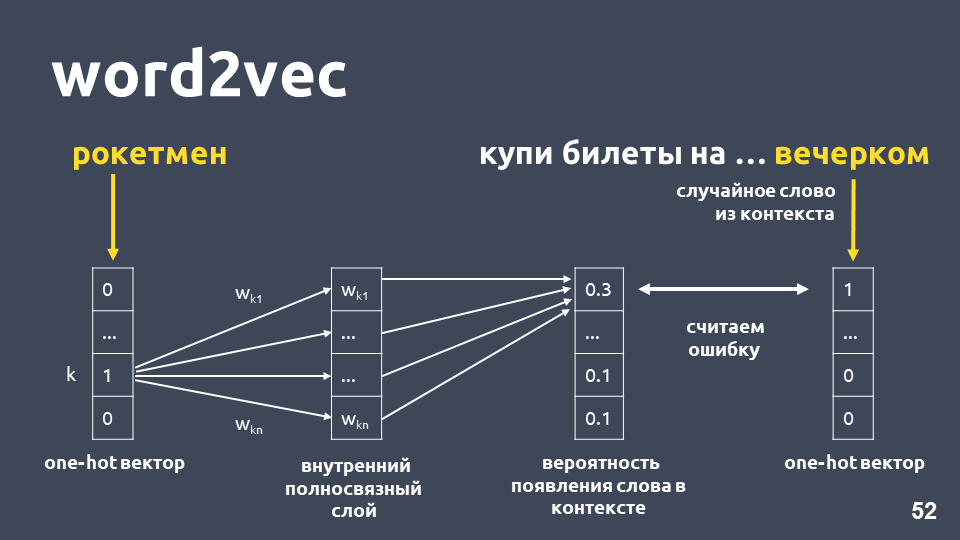
接下来,我们训练一个简单的单层神经网络,无需在内层上激活即可预测上下文中的下一个单词,即使用“ rocketman”一词来预测“傍晚”一词。 在输出中,我们从字典中获得所有单词的概率分布如下。 由于我们知道单词的真正含义,因此我们可以计算错误,更新权重等。

通过对样本进行训练获得的更新权重就是词嵌入。
首先,使用嵌入而不是数字的优势
是考虑了上下文 。 一个流行的例子:特朗普和普京在word2vec中关系密切,因为它们都是总统,并且经常在文本中一起使用。
对于在训练样本中找到的单词,您只需获取嵌入矩阵,将其向量作为单词的索引,然后进行嵌入。
看起来一切都很好,除了矩阵中的某些单词可能不是,因为模型在训练期间没有看到它们。 为了处理不熟悉的单词(词汇不足)的问题,在2014年,他们提出了对word2vec-
fasttext的修改。
Fasttext的工作原理如下:如果单词不在词典中,则将其划分为符号n-gram,因为每个n-gram嵌入均取自n-gram的嵌入矩阵(像word2vec一样训练),对嵌入进行平均,并获得向量。
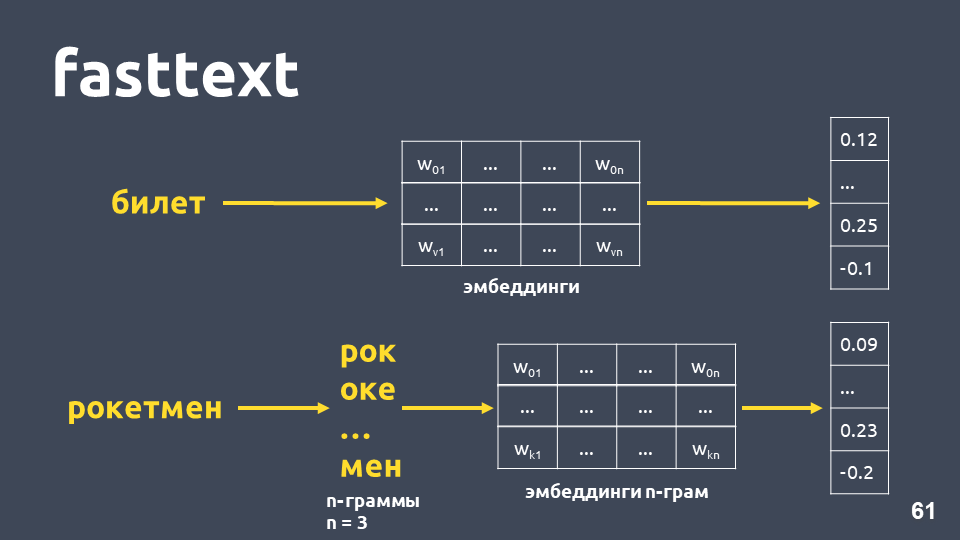
总计,我们得到不在词典中的单词的向量。 现在,
即使对于不熟悉的单词,我们也可以
计算相似度 。 而且,非常重要的是,有针对俄罗斯,英语和中文的训练有素的模型,例如Facebook和
DeepPavlov项目,因此您可以快速将其包含在您的管道中。
但是缺点仍然存在:- 该模型未用于整个文本向量。 要获得一个通用的文本向量,您需要考虑一些问题:平均值或与idf权重相乘的平均值,并且在不同的任务中这可以以不同的方式起作用。
- 无论上下文如何,一个单词的向量仍然是1。 Word2vec针对出现单词的任何上下文训练一个单词向量。 对于多值单词(例如语言),将存在一个相同的向量。
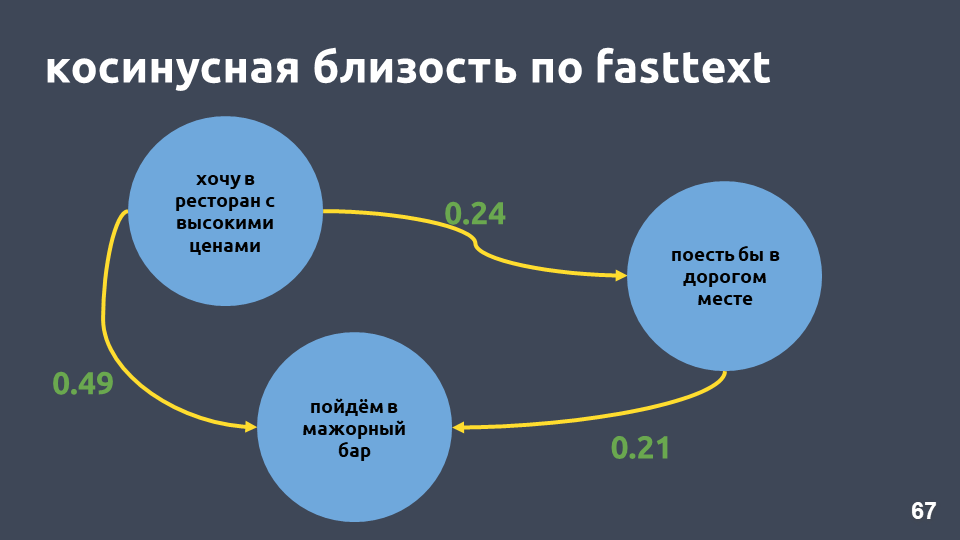
确实,在我们的示例中,快速文本中的余弦邻近度高于tf-idf中的余弦邻近度,即使这些短语只有“相同”之处。
快速文本上的t-SNE(前10个意图),F1得分:0.86但是,当可视化t-SNE分解的快速文本结果时,意向簇比tf-idf表现得差得多。 这里的F1度量是0.86而不是0.92。
我们进行了一个实验:结合了tf-idf和fasttext向量。 质量与仅使用tf-idf时完全相同。 并非对于所有任务都是如此,存在一些问题,其中tf-idf和fasttext的组合比tf-idf更好,或者fasttext的效果比tf-idf好。 您需要尝试一下。
让我们尝试增加意图的数量(回想一下,我们有170个意图)。 以下是tf-idf向量上前30个意图的聚类。
tf-idf的t-SNE(前30个意图),F1得分0、85(在10时为0.92)质量下降了7分,现在我们看不到明显的集群结构。
让我们看一下开始变得困惑的文本示例,因为添加了更多意图,这些意图在语义和语言上相交。
例如:“如果您开立存款,那有什么利息?” 和“而且我希望以7%的比例开始供款。” 非常相似的短语,但是这些是不同的意图。 在第一种情况下,一个人想知道存款的条件,在第二种情况下,要开立存款。 要将此类文本分为不同的类别,我们需要更复杂的
深度学习 。
语言模型
我们想要获得文本的向量,尤其是单词的向量,这将取决于使用的上下文。 获取这样的向量的标准方法是
使用语言模型中的嵌入 。
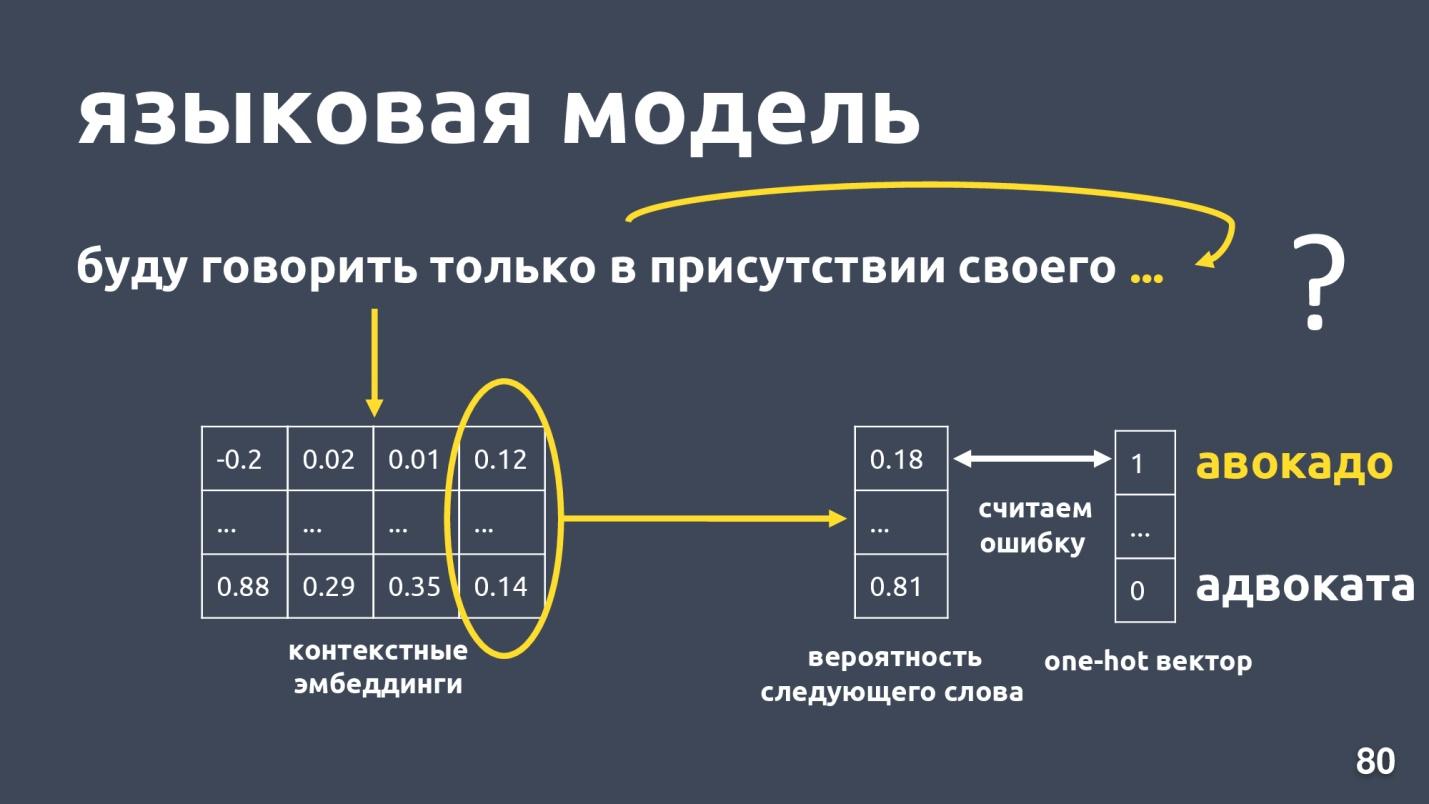
语言模型解决了语言建模的问题。 这项任务是什么? 假设有一个单词序列,例如:“我只会在自己的存在下讲话...”,然后我们尝试预测序列中的下一个单词。 语言模型提供了嵌入的上下文。 获得每个单词的上下文嵌入和向量后,就可以预测下一个单词的概率。
有一个字典维度向量,并且每个单词都被指定为下一个概率。 我们再次知道实际上是什么词,考虑一个错误并训练模型。
语言模型很多,去年是否繁荣了? 并且已经提出了许多不同的架构。
ELMo是其中之一。
艾莫
ELMo模型的思想是首先为文本中的每个单词构建一个符号词嵌入,然后为它们应用
LSTM网络 ,其方式是考虑到嵌入时要考虑到单词出现的上下文。
让我们研究一下如何获得符号嵌入:将单词分解为符号,为每个符号应用一个嵌入层,然后获得一个嵌入矩阵。 仅涉及符号时,这种矩阵的尺寸很小。 然后,将一维卷积应用于嵌入矩阵(通常在NLP中进行),最后进行最大池化,从而获得一个向量。 将两层所谓的
高速公路网络应用于此向量,该网络计算
单词的
一般向量 。
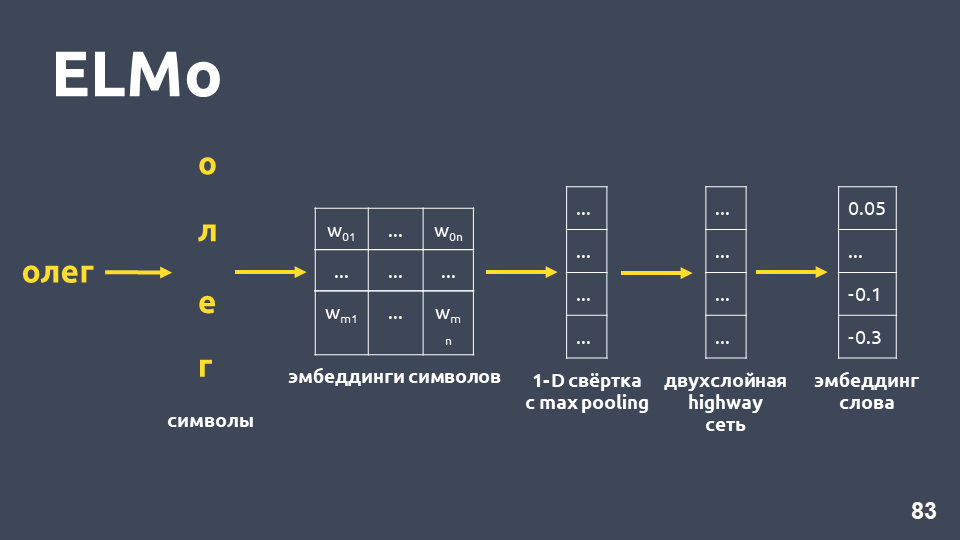
此外,该模型将建立某种嵌入假设,即使对于训练集中未找到的单词也是如此。
收到每个单词的符号嵌入后,我们对其应用两层BiLSTM网络。
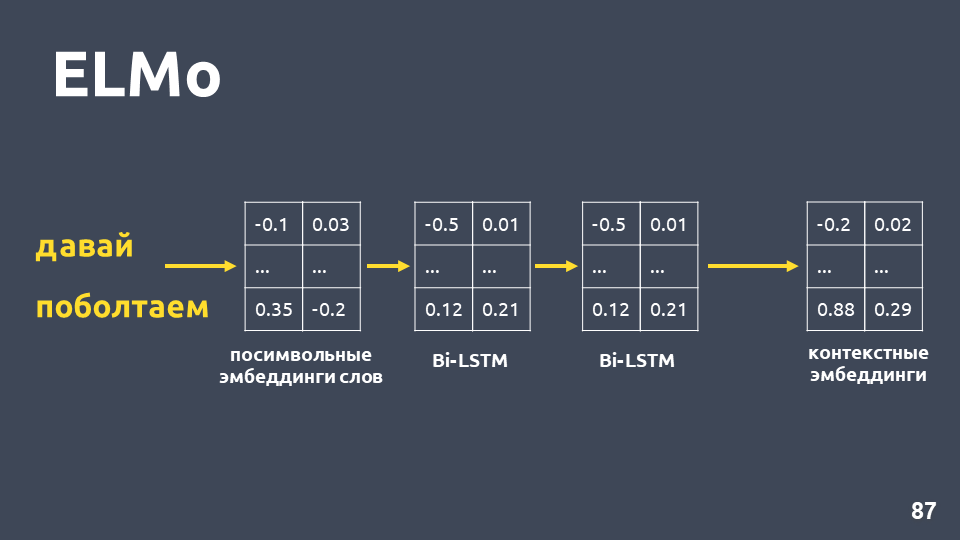
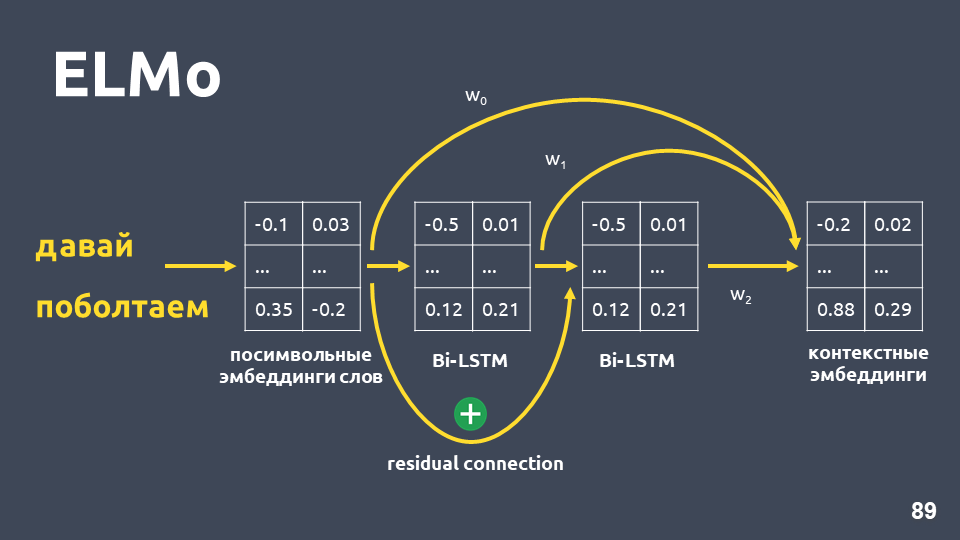
在应用两层BiLSTM网络之后,通常通常会获取最后一层的隐藏状态,并且可以认为这是上下文嵌入。 但是ELMo具有两个功能:
- 第一LSTM层的输入与其输出之间的残余连接 。 LSTM输入被添加到输出以避免渐变渐变的问题。
- ELMo的作者建议将每个单词的符号嵌入,第一LSTM层的输出和第二LSTM层的输出与为每个任务选择的权重相结合。 必须同时考虑提供LSTM第一层和第二层的低级功能和高级功能。
在我们的问题中,我们使用了这三个嵌入的简单平均值,从而获得了每个单词的上下文嵌入。
语言模型具有以下优点:
- 单词的向量取决于使用该单词的上下文。 也就是说,例如,对于身体部位和语言术语含义中的“语言”一词,我们获得了不同的向量。
- 与word2vec和fasttext一样,有许多训练有素的模型,例如,来自DeepPavlov项目。 您可以采用完成的模型,然后尝试应用到您的任务中。
- 您不再需要考虑如何平均单词向量。 ELMo模型立即产生所有文本的向量。
- 您可以为您的任务重新训练语言模型,有多种方法可以实现,例如ULMFiT。
唯一的缺点是-
语言模型不能保证属于同一类(即出于一种意图)的文本在向量空间中会接近。
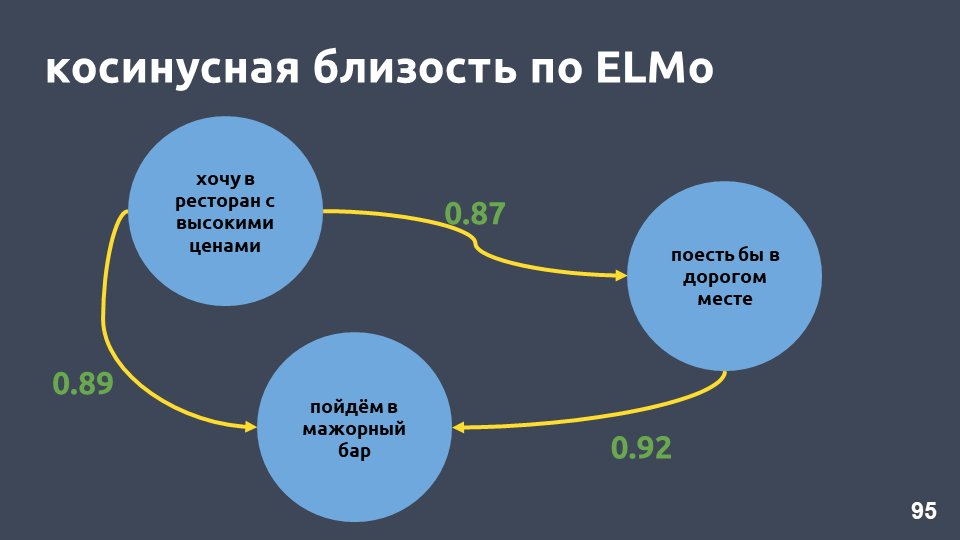
在我们的餐厅示例中,根据ELMo模型的余弦值确实变高了。
ELMo上的t-SNE(前10个意图),F1得分0.93(tf-idf为0.92)具有十大意图的集群也更加明显。 在上图中,所有10个簇都清晰可见,而精度略有提高。
ELMo上的t-SNE(前30个意图)F1得分0.86(tf-idf为0.85)对于前30个意图,集群结构仍然保留,质量也提高了一个百分点。
但是在这样的模型中,不能保证建议“如果您存入保证金,它们的利益是什么?” 尽管他们位于不同的类别,但“我希望以7%的比例缴纳会费”相距甚远。 使用ELMo,我们只需学习语言模型,并且如果语义上相似的文本将很接近。
ELMo对我们的类一无所知 ,但是您可以使用类标签将空间中具有相同意图的文本向量组合在一起。
连体网络
以您最喜欢的神经网络体系结构进行文本矢量化和两个意图示例。 对于每个示例,我们进行嵌入,然后计算它们之间的余弦距离。
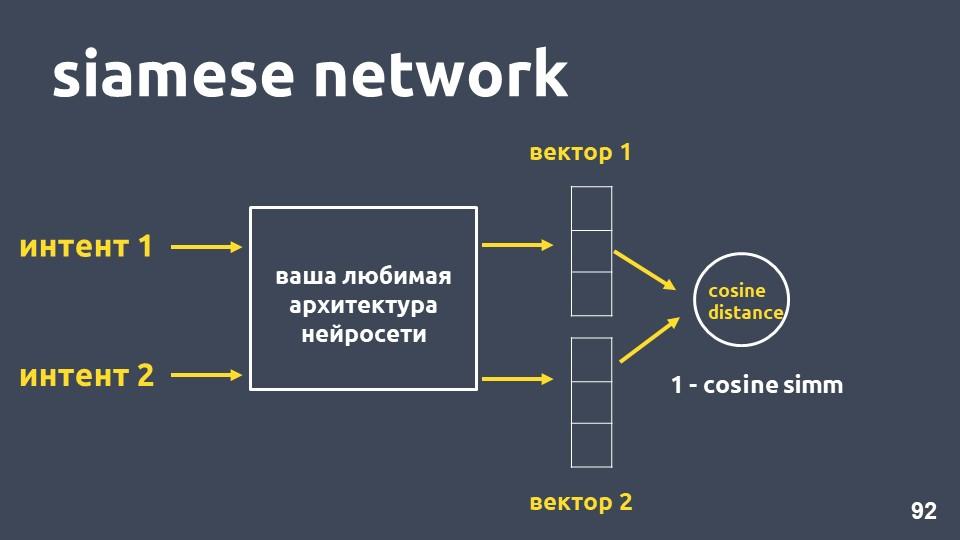
余弦距离等于一减去我们先前遇到的余弦距离。
这种方法称为
暹罗网络 。
我们希望来自同一班级的文本(例如“进行转账”和“投钱”)在空间上紧紧地排列在一起。 也就是说,它们的向量之间的余弦距离应尽可能小,理想情况下为零。 与不同意图有关的文本应尽量分开。
但实际上,这种训练方法效果不佳,因为不同类别的对象彼此之间的距离不够远。 称为
“三重态损失”的损失函数要好得多。 它使用三元组的三元组对象。
该图显示了一个三元组:蓝色圆圈中的锚对象,绿色圆圈中的正对象和红色圆圈中的负对象。 否定对象和锚点属于不同的类别,而肯定对象和锚点属于同一类。

我们要确保训练后,正物体比负物体更靠近锚点。 为此,我们考虑对象对之间的余弦距离,然后输入超参数-“ margin”-我们期望在正负对象之间的距离。

损失函数如下所示:
换句话说,在训练过程中,我们实现了正对象比负对象更接近锚点,至少是余量。 如果损失函数为零,则它起作用,然后我们完成训练,否则我们将目标函数最小化。
训练完模型后,我们仍然没有得到分类器,它只是一种获得这样的嵌入的方法,即位于一个意图中的对象最有可能具有接近的向量。
得到模型后,可以在嵌入之上使用其他分类方法。
KNN非常适合,因为我们已经实现了嵌入具有独特的簇结构。
回想一下kNN如何处理文本:获取文本的元素,对其进行嵌入,将其转换为向量空间,然后查看其邻居是谁。 在邻居中,我们考虑最频繁的类别,并得出结论,新对象属于该类别。
我们使用的嵌入尺寸为300,在训练样本中大约有500,000个对象。 在性能方面,寻找最接近的邻居的标准方法不适合我们。 我们使用了
HNSW方法-
分层可导航小世界 。
“可导航的小世界”是一个连通的图,其中相距较远的顶点之间几乎没有边,而附近的顶点之间有很多边。 在我们的情况下,边缘长度将由余弦距离确定,即 , , .
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
总结
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .