最近,FPGA制造商和第三方公司一直在积极开发与使用高级开发工具的传统方法不同的FPGA开发方法。
作为一名FPGA开发人员,我使用Verilog的硬件描述语言(
HDL )作为主要工具,但是新方法的日益普及引起了我的极大兴趣,因此在本文中,我决定弄清正在发生的事情。
本文不是使用指南或说明,这是我对各种高级开发工具可以为希望投入FPGA领域的FPGA开发人员或程序员所提供的内容的评论和结论。 为了比较我认为最有趣的开发工具,我编写了一些测试并分析了结果。 在削减-这是怎么回事。
为什么需要FPGA的高级开发工具?
- 加快项目开发
-由于重用已经用高级语言编写的代码;
-从头开始编写代码时,通过使用高级语言的所有优点;
-通过减少编译时间和代码验证。
- 能够创建适用于任何FPGA系列的通用代码。
- 降低FPGA的开发门槛,例如,避免使用“时钟速度”和其他底层实体的概念。 能够为不熟悉HDL的开发人员编写FPGA代码。
高级开发工具从哪里来?
现在,许多人都被高层开发的思想所吸引。 诸如
Quokka和
Python代码生成器之类的爱好者以及
MathWorks和FPGA制造商
Intel和
Xilinx之类的公司都参与其中。
每个人都使用他的方法和工具来实现自己的目标。 为追求完美和美丽世界而奋斗的爱好者会使用他们喜欢的开发语言,例如Python或C#。 公司试图取悦客户,提供自己的工具或改编现有的工具。 Mathworks提供了自己的HDL编码器工具,用于从m脚本和Simulink模型生成HDL代码,而Intel和Xilinx提供了用于通用C / C ++的编译器。
目前,拥有大量财务和人力资源的公司取得了更大的成功,而发烧友则有所落后。 本文将专门讨论MathWorks的产品HDL编码器和Intel的HLS Compiler。
赛灵思呢在本文中,由于英特尔和赛灵思的体系结构和CAD系统不同,因此我不考虑Xilinx的HIL,这使得无法对结果进行明确的比较。 但我想指出,赛灵思HLS与Intel HLS一样,提供了C / C ++编译器,它们在概念上是相似的。
让我们开始比较Mathworks和Intel HLS Compiler的HDL编码器,它们已经使用不同的方法解决了一些问题。
高级开发工具比较
测试一个。 “两个乘法器和一个加法器”
解决该问题没有实际价值,但非常适合作为第一个测试。 该函数采用4个参数,将第一个参数与第二个参数相乘,第三个参数与第四个参数相乘,然后将相乘的结果相加。 没什么复杂的,但让我们看看我们的主题如何应对。
Mathworks的HDL编码器
为了解决此问题,m脚本如下所示:
function [out] = TwoMultAdd(a,b,c,d) out = (a*b)+(c*d); end
让我们看看Mathworks为我们提供的将代码转换为HDL的功能。
我不会详细考虑使用HDL编码器的工作,我将只讨论将来会更改的设置,以便在FPGA中获得不同的结果,并且需要在MATLAB中运行其代码的MATLAB程序员必须考虑这些更改。
因此,首先要做的是设置输入值的类型和范围。 FPGA中没有熟悉的char,int,float,double。 数字的位深度可以是任意值,根据您打算使用的输入值的范围来选择它是合乎逻辑的。
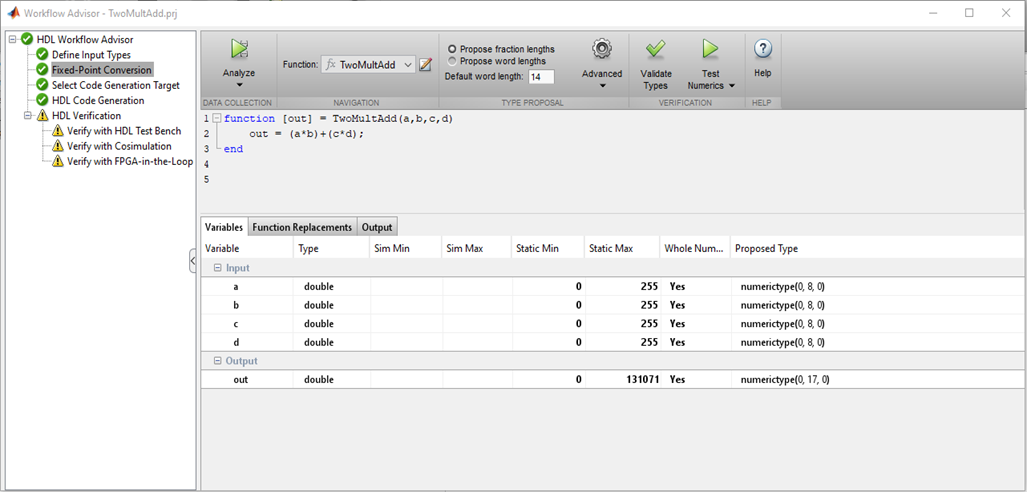 图1
图1MATLAB检查变量的类型,它们的值并为总线和寄存器选择正确的位大小,这确实很方便。 如果位深度和键入没有问题,则可以继续以下几点。
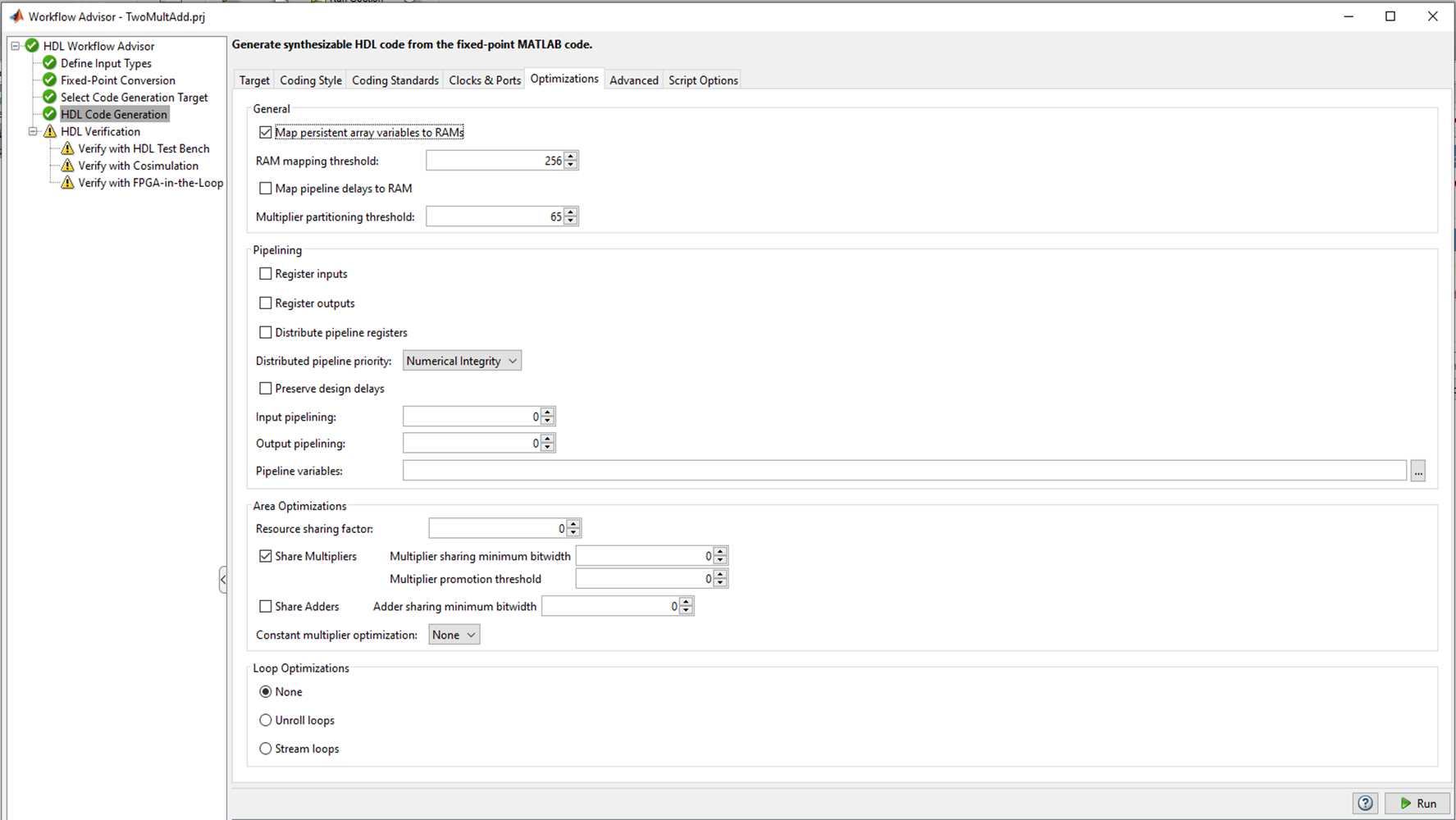 图2
图2HDL代码生成中有几个选项卡,您可以在其中选择要转换为的语言(Verilog或VHDL); 代码风格 信号名称。 在我看来,最有趣的选项卡是“优化”,我将对其进行试验,但是稍后,让我们暂时保留所有默认值,然后看看“开箱即用” HDL编码器会发生什么。
按下运行按钮并获得以下代码:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (a, b, c, d, out); input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output [16:0] out; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; endmodule // TwoMultAdd_fixpt
代码看起来不错。 MATLAB理解在Verilog的一行上编写整个表达式是不好的做法。 为乘法器和加法器创建单独的
导线 ,没有什么可抱怨的。
令人震惊的是,缺少寄存器的描述。 发生这种情况是因为我们没有询问HDL编码器此问题,而是将设置中的所有字段都保留为其默认值。
这是Quartus从此类代码中合成的内容。
 图3
图3没问题,一切都按计划进行。
在FPGA中,我们实现了同步电路,但我仍然希望看到寄存器。 HDL编码器提供了一种用于放置寄存器的机制,但是放置寄存器的位置取决于开发人员。 我们可以将寄存器放置在乘法器的输入处,乘法器的输出处,加法器前面或加法器的输出处。
为了综合示例,我选择了FPGA Cyclone V系列,其中使用带有内置加法器和乘法器的特殊DSP模块来实现算术运算。 DSP模块如下所示:
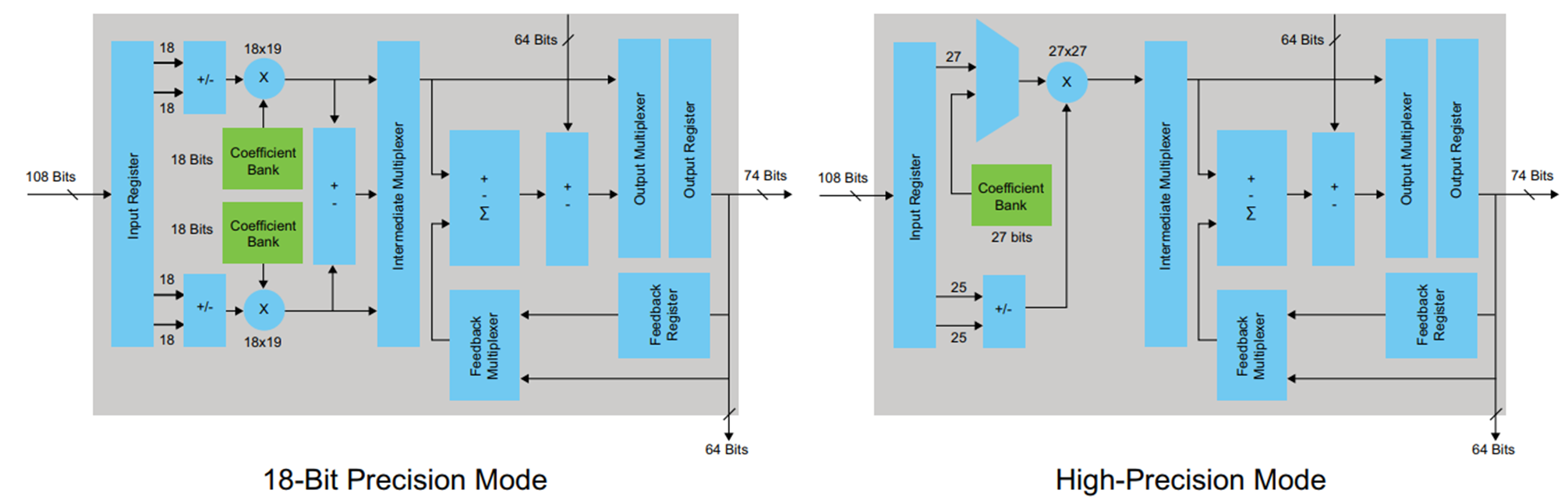 图4
图4DSP模块具有输入和输出寄存器。 无需在加法之前尝试在寄存器中捕捉乘法结果,这只会违反体系结构(在某些情况下,甚至可以使用此选项)。 开发人员可以根据等待时间要求和所需的最大频率来决定如何处理输入和输出寄存器。 我决定只使用输出寄存器。 为了在HDL编码器生成的代码中描述此寄存器,需要在HDL编码器的“选项”选项卡中选中“寄存器输出”复选框并重新开始转换。
原来的代码如下:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (clk, reset, clke_ena_i, a, b, c, d, clke_ena_o, out); input clk; input reset; input clke_ena_i; input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output clke_ena_o; output [16:0] out; // ufix17 wire enb; wire [16:0] out_1; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 reg [16:0] out_2; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; assign enb = clke_ena_i; always @(posedge clk or posedge reset) begin : out_reg_process if (reset == 1'b1) begin out_2 <= 17'b00000000000000000; end else begin if (enb) begin out_2 <= out_1; end end end assign clke_ena_o = clke_ena_i; assign out = out_2; endmodule // TwoMultAdd_fixpt
如您所见,该代码与以前的版本相比有根本的不同。 始终出现块,这是对寄存器的描述(正是我们想要的)。 对于始终块操作,也将显示clk模块的输入(时钟频率)和复位(复位)。 可以看出,加法器的输出被锁存在始终描述的触发器中。 也有几个ena许可信号,但对我们来说不是很有趣。
让我们看一下Quartus现在合成的图。
 图5
图5再次,结果是良好的和预期的。
下表显示了已用资源表-我们牢记这一点。
 图6
图6对于第一个任务,Mathworks会获得功劳。 一切都不是复杂的,可预测的且具有预期的结果。
我详细描述了一个简单的示例,提供了DSP模块的框图,并描述了在HDL编码器中使用寄存器使用设置的可能性,而不是“默认”设置。 这样做是有原因的。 由此,我想强调一点,即使在这样一个简单的示例中,当使用HDL编码器时,也需要了解FPGA架构和数字电路的基础知识,并且必须有意识地更改设置。
英特尔HLS编译器
让我们尝试使用与C ++相同的功能来编译代码,并查看最终使用HLS编译器在FPGA中合成的内容。
所以C ++代码
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d) { return (a*b)+(c*d); }
我选择了数据类型以避免变量溢出。
有许多高级方法可以设置位深度,但是我们的目标是测试在不进行任何更改的情况下在FPGA下组装以C / C ++样式编写的函数的能力,这些都是开箱即用的。
由于HLS编译器是Intel的本机工具,因此我们使用特殊的编译器收集代码,并立即在Quartus中检查结果。
让我们看一下Quartus合成的电路。
 图7
图7编译器在输入和输出处创建了寄存器,但本质隐藏在包装器模块中。 我们开始部署包装器,并...看到越来越多的嵌套模块。
该项目的结构如下所示。
 图8
图8英特尔的一个明显暗示是“不要动手!”。 但是我们会尝试的,特别是功能并不复杂。
在项目树的肠道中| quartus_compile | TwoMultAdd:TwoMultAdd_inst | TwoMultAdd_internal:twomultadd_internal_inst | TwoMultAdd_fu
nction_wrapper:TwoMultAdd_internal | TwoMultAdd_function:theTwoMultAdd_function | bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start | bb_TwoMultAdd_B1_start_stall_region:thebb_TwoMultAdd_B1_start_stall_region | i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd:thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x | i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13:thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x | Mult1是您要寻找的模块。
我们可以看一下Quartus合成的所需模块的示意图。
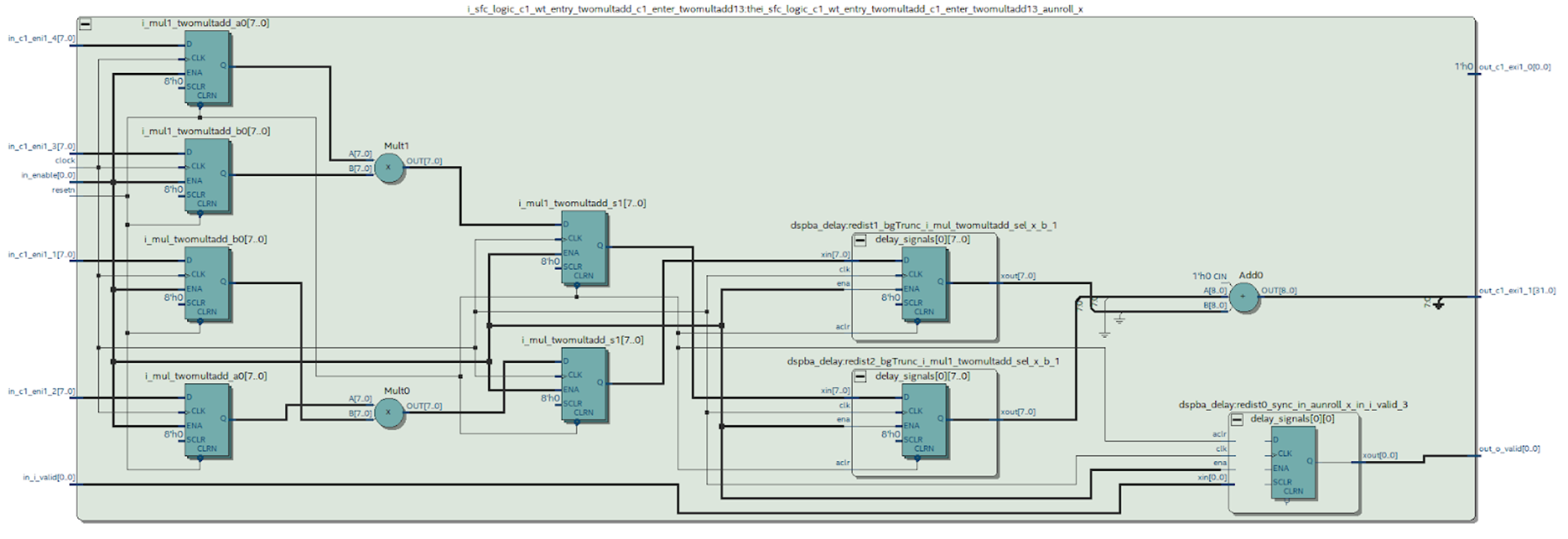 图9
图9从这个方案可以得出什么结论。
显然,在MATLAB中工作时我们试图避免发生了一些事情:乘法器输出的情况是综合的-这不是很好。 从DSP框图(图4)可以看出,其输出只有一个寄存器,这意味着每次乘法都必须在单独的模块中完成。
已用资源表显示了这将导致什么。
 图10
图10将结果与HDL编码器表进行比较(图6)。
如果使用大量的寄存器可以忍受,那么在这种简单功能上花费宝贵的DSP模块将是非常不愉快的。
但是与HDL编码器相比,Intel HLS具有巨大的优势。 使用默认设置,HLS编译器在FPGA中开发了同步设计,尽管它消耗了更多资源。 这样的架构是可能的,很明显,Intel HLS配置为实现最高性能,而不是节省资源。
让我们看看我们的主题如何处理更复杂的项目。
第二次测试。 “矩阵的元素式乘法与结果求和”
此功能广泛用于图像处理:所谓的
“矩阵滤波器” 。 我们使用高级工具出售它。
Mathwork的HDL编码器
工作立即开始受到限制。 HDL Coder不能接受二维矩阵函数作为输入。 鉴于MATLAB是用于处理矩阵的工具,这对整个继承的代码造成了沉重打击,这可能会成为一个严重的问题。 如果代码是从头开始编写的,则必须考虑这是一项令人不愉快的功能。 因此,您必须将所有矩阵部署到向量中,并考虑输入向量来实现函数。
MATLAB中该函数的代码如下
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ = sum(mult); out = summ/len; end
生成的HDL代码非常肿,包含数百行,因此在此不再赘述。 让我们看看Quartus从此代码中合成了什么方案。
 图11
图11该方案看起来不成功。 从形式上来说,它可以正常工作,但是我认为它将以非常低的频率工作,并且几乎不能在实际硬件中使用。 但是任何假设都必须得到验证。 为此,我们将寄存器放置在该电路的输入和输出处,借助Timing Analyzer,我们将评估实际情况。 要进行分析,您必须指定电路的期望工作频率,以便Quartus知道在布线时应采取的措施,并在出现故障的情况下提供违规报告。
我们将频率设置为100 MHz,让我们看看Quartus可以从建议的电路中挤出什么。
 图12
图12可以看出,结果有点:33 MHz看起来很琐碎。 乘法器和加法器链的延迟约为30 ns。 为了摆脱这个“瓶颈”,您需要使用传送带:在算术运算之后插入寄存器,从而减少了关键路径。
HDL编码器为我们提供了这个机会。 在选项选项卡中,可以设置管道变量。 由于所讨论的代码是以MATLAB风格编写的,因此无法通过管道传递变量(除mult和summ变量之外),这不适合我们。 有必要将寄存器插入隐藏在我们HDL代码中的中间电路中。
而且,优化的情况可能更糟。 例如,没有什么可以阻止我们编写代码
out = (sum(target.*kernel))/len;
它对于MATLAB来说已经足够了,但完全使我们无法优化HDL。
下一步是手动编辑代码。 这是非常重要的一点,因为我们拒绝继承并开始重写m脚本,而不是MATLAB样式。
新代码如下
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ_1 = zeros([1,(len/2)]); summ_2 = zeros([1,(len/4)]); summ_3 = zeros([1,(len/8)]); for i=0:1:(len/2)-1 summ_1(i+1) = (mult(i*2+1)+mult(i*2+2)); end for i=0:1:(len/4)-1 summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2)); end for i=0:1:(len/8)-1 summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2)); end out = summ_3/len; end
在Quartus中,我们收集HDL Coder生成的代码。 可以看出,具有基元的层数已减少,该方案看起来更好。
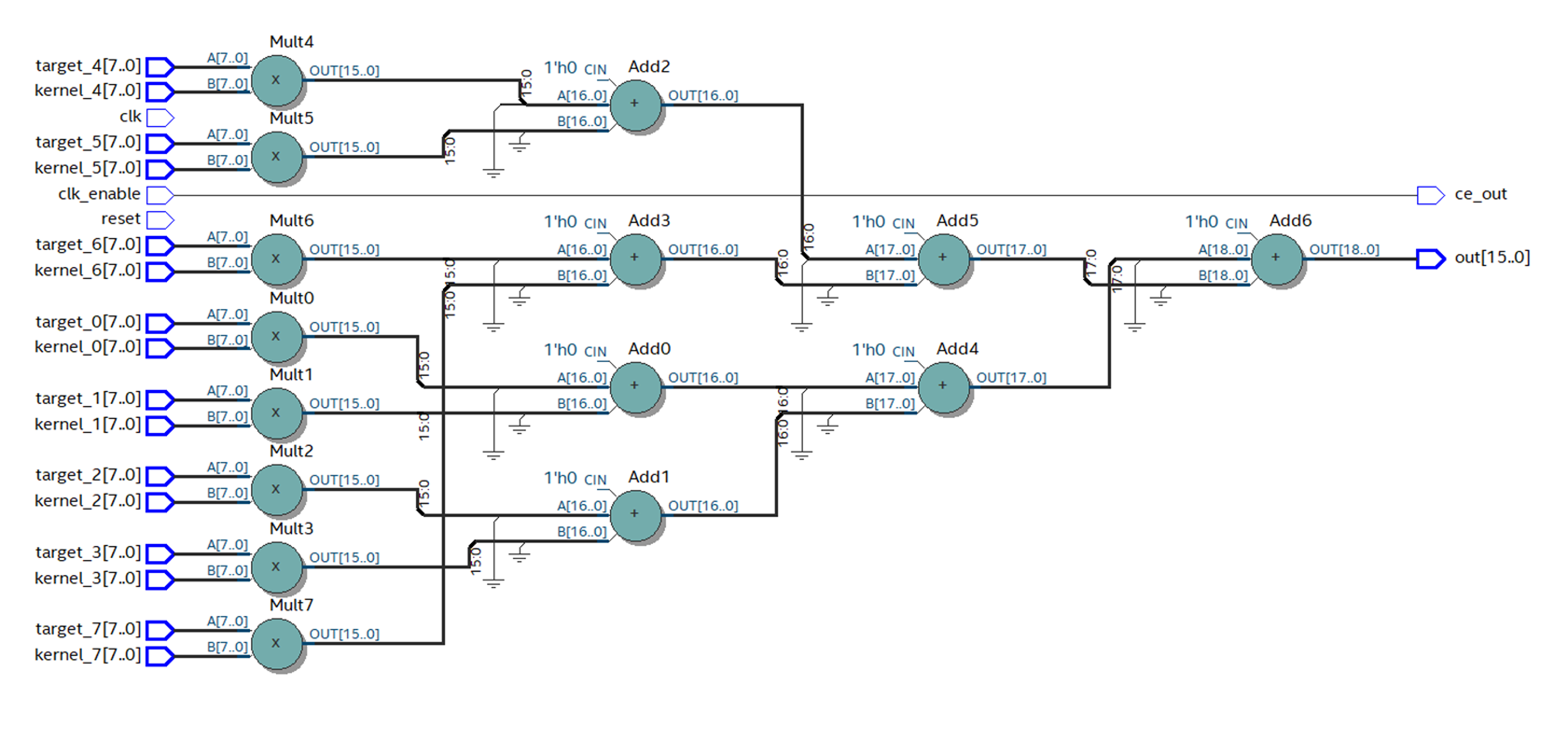 图12
图12使用正确的图元布局,频率将增长近3倍,最高可达88 MHz。
 图13
图13现在最后一点:在“优化”设置中,将summ_1,summ_2和summ_3指定为管道的元素。 我们在Quartus中收集结果代码。 方案更改如下:
 图14
图14最大频率再次增加,现在它的值约为195 MHz。
 图15
图15这种设计将在芯片上消耗多少资源? 图16显示了所描述情况的已用资源表。
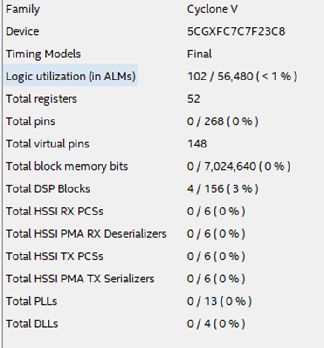 图16
图16考虑这个例子可以得出什么结论?
HDL编码器的主要缺点是不太可能使用纯格式的MATLAB代码。
不支持将矩阵作为函数输入,MATLAB风格的代码布局中等。
主要的危险是在没有附加设置的情况下生成的代码中缺少寄存器。 没有这些寄存器,即使已经接收到正式可用的HDL代码而没有语法错误,也不希望在现代现实和发展中使用这种代码。
建议立即编写经过增强的代码以转换为HDL。 在这种情况下,就速度和资源强度而言,您可以获得非常令人满意的结果。
如果您是MATLAB开发人员,请不要急于单击“运行”按钮并在FPGA下编译代码,请记住,您的代码将被合成为真实电路。 =)
英特尔HLS编译器
为了实现相同的功能,我编写了以下C / C ++代码
component unsigned int conv(unsigned char *data, unsigned char *kernel) { unsigned int mult_res[16]; unsigned int summl; summl = 0; for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; summl = summl+mult_res[i]; } return summl/16; }
引起您注意的第一件事是使用的资源量。
 图17
图17从表中可以看出,仅使用了1个DSP模块,因此出现了问题,并且乘法没有并行执行。 使用的寄存器数量也令人惊讶,甚至涉及到内存,但是我们将把它留给HLS编译器来解决。
值得注意的是,HLS编译器使用大量额外资源开发出了次优的产品,但根据Quartus报告,仍然是一个工作电路,它将以可接受的频率工作,而HDL编码器这样的故障则不会。
 图18
图18让我们尝试改善情况。 为此需要什么? 是的,闭上眼睛继承并爬入代码,但到目前为止还不多。
HLS具有用于优化FPGA代码的特殊指令。 我们插入unroll指令,它将并行扩展循环:
#pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; }
让我们看看Quartus是如何反应的
 图19
图19首先,请注意DSP块的数量-其中有16个,这意味着乘法是并行执行的。
万岁! 展开作品! 但是,已经很难忍受其他资源利用率的增长。 电路变得完全不可读。
 图20
图20我认为,这是由于没有人向编译器指出定点数的计算非常适合我们,并且他诚实地在逻辑和寄存器上实现了所有浮点数学运算。 我们需要向编译器解释它需要什么,为此,我们再次陷入代码中。
为了使用定点,实现了模板类。
 图21
图21用我们自己的话来说,我们可以使用变量深度手动设置为最大的变量。 对于那些使用HDL编写的人来说,您可能不习惯它,但是C / C ++程序员可能会抓紧时间。 在这种情况下,就像在MATLAB中一样,位深度没有人知道,开发人员自己必须计算位的数量。
让我们看看它在实际中的外观。
我们按如下方式编辑代码:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel) { ac_fixed<16,16,false>mult_res[16]; ac_fixed<32,32,false>summl; #pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; } for (int i = 0; i < 16; i++) { summl = summl+mult_res[i]; } return summl/16; }
而不是图20中令人毛骨悚然的意大利面,我们得到了这种美丽:
 图22
图22不幸的是,使用的资源仍在发生奇怪的事情。
 图23
图23但是,对报告的详细审查表明,我们直接感兴趣的模块看起来绰绰有余:
 图24
图24寄存器和块存储器的大量消耗与大量外围模块有关。 我仍然不完全了解它们存在的深层含义,这需要加以解决,但是问题已经解决。 在极端情况下,您可以从项目的总体结构中小心地切出我们感兴趣的一个模块,这将使我们免于占用大量资源的外围模块。
第三次测试。 “从RGB到HSV的过渡”
开始写这篇文章时,我没想到它会如此庞大。 但是我不能拒绝本文框架中的第三和最后一个例子。
首先,这是我实践中的一个真实示例,正是由于这个原因,我开始着眼于高级开发工具。
其次,从前两个示例中,我们可以假设设计越复杂,高级工具完成任务的能力就越差。
我想证明这种判断是错误的,实际上,任务越复杂,高级开发工具的优势就越明显。
去年,当在其中一个项目上工作时,我不喜欢在速卖通上购买的相机,即色彩不够饱和。 改变颜色饱和度的一种流行方法是从RGB颜色空间切换到HSV空间,其中参数之一是饱和度。 我记得我是如何打开转换公式并深吸一口气的。。。在FPGA中实现这种计算并不是什么特别的事,但是当然,这需要时间来编写代码。 因此,从RGB切换到HSV的公式如下:
 图25
图25在FPGA中实现这样的算法将花费数天而不是数小时,并且由于HDL的特殊性,必须非常仔细地完成所有这些工作,而我认为,在C ++或MATLAB中的实现将花费数分钟。
在C ++中,您可以直接在额头上编写代码,但仍然可以获得有效的结果。
我在C ++中编写了以下选项
struct color_space{ unsigned char rh; unsigned char gs; unsigned char bv; }; component color_space rgb2hsv(color_space rgb_0) { color_space hsv; float h,s,v,r,g,b; float max_col, min_col; r = static_cast<float>(rgb_0.rh)/255; g = static_cast<float>(rgb_0.gs)/255; b = static_cast<float>(rgb_0.bv)/255; max_col = std::max(std::max(r,g),b); min_col = std::min(std::min(r,g),b);
从已用资源表中可以看出,Quartus成功地实现了结果。
 图26
图26频率很好。
 图27
图27使用HDL编码器,事情变得有些复杂
为了不使文章膨胀,我不会为该任务提供m脚本,它不应引起任何困难。 写在额头上的m脚本很难被成功使用,但是如果您编辑代码并正确指定流水线的位置,我们将获得工作结果。 当然,这将花费数十分钟,而不是数小时。
C++ , .
, , , , — , FPGA , HDL.
结论
.
, , , .
, , . , , HDL, .
, FPGA FPGA . .
, — FPGA.
HLS compiler : , , , “best practices” .. MATLAB, , GUI , , , , , .
? — Intel HLS compiler. . HDL coder . , HDL coder , , . HLS, , , FPGA , .
Xilinx , — FPGA. , , Verilog/VHDL , . ( ), .
? , , , HDL .
, , , , .