从理论上讲,机器学习(ML)的使用有助于减少人类对流程和操作的参与,重新分配资源并降低成本。 这在特定的公司和行业中如何运作? 正如我们的经验所示,它是有效的。
在开发的某个阶段,我们VTB Capital面临着迫切需要减少处理技术支持请求所需的时间。 在分析了选项之后,决定使用ML技术对公司主要投资平台Calypso的业务用户的呼叫进行分类。 此类请求的快速处理对于IT服务的高质量至关重要。 我们请关键合作伙伴
EPAM帮助解决此问题。

因此,支持请求通过电子邮件接收,并转换为Jira中的票证。 然后,支持专家手动对它们进行分类,确定优先级,输入其他数据(例如,从哪个部门和位置接收到请求,它属于系统的哪个功能单元),并分配执行者。 总共使用了大约10类查询。 例如,这可能是分析某些数据并向请求者提供信息,添加新用户等的请求。 此外,操作可以是标准操作,也可以是非标准操作,因此立即正确确定请求类型并将执行分配给合适的专家非常重要。
重要的是要注意:VTB Capital不仅希望开发一种实用的技术解决方案,而且还希望评估市场上各种工具和技术的功能。 一项任务,两种不同的方法,两种技术平台和三个半星期的时间:结果如何?
原型1:技术和模型
原型开发的基础是EPAM团队提出的方法和历史数据-约拉(Jira)的大约10,000张票。 主要关注点集中在每个故障单所包含的3个必填字段上:发行类型(问题类型),摘要(请求书信或主题的“标题”)和描述(描述)。 在该项目的框架内,计划解决“摘要”和“描述”字段中分析文本的问题,并根据结果自动确定请求的类型。
正是这两个票据领域中的文本特征成为分析数据和开发ML模型的主要技术难题。 因此,“摘要”字段可能包含非常“干净”的文本,但包含特定的单词和术语(例如,
CWS报告未运行)。 相反,“描述”字段的特征是带有更多特殊字符,符号,反斜杠和非文本元素残差的更“肮脏”的文本:
德拉同事,
您能否向我们解释FX_Opt_delta_all和FX_Opt_delta_cash风险度量之间的区别是什么?
!01D39C59.62374C90_image001.png! )
此外,文本通常包含几种语言(主要是自然地,俄语和英语),可以找到商务术语,粗俗和程序员语。 当然,由于通常会急着写请求,因此在两种情况下都不能排除错别字和拼写错误。
EPAM团队选择的技术包括用于原型开发的Python 3.5,用于文本处理的NLTK + Gensim + Re,用于数据分析和模型开发的Pandas + Sklearn以及用于深度学习框架和后端的Keras + Tensorflow。
考虑到初始数据的可能特征,构造了三种表示形式,用于从“摘要”字段中提取字符:在符号级别,符号组合和单个单词。 每个表示形式都用作循环神经网络的入口。
反过来,选择服务字符统计信息(对于使用感叹号,斜杠等处理文本很重要)和过滤服务字符和垃圾后字符串的平均值(用于紧凑保存文本结构)作为Description字段的表示形式;以及过滤停用词后的词级表示。 每种表示形式都是神经网络的入口:在完全连接,逐行且在单词级别上的统计-在递归形式中。
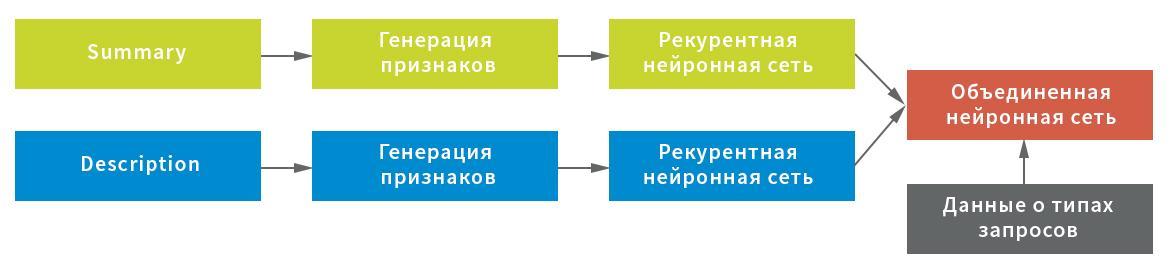
在此方案中,神经网络被用作循环网络,由具有递归和正常退出的双向GRU层,使用GlobalMaxPool1D层的循环网络的隐藏状态池以及具有退出的完全连接(密集)层组成。 对于每个输入,都建立了自己的神经网络“头”,然后通过串联将它们组合起来并锁定到目标变量。
为了获得最终结果,组合神经网络返回了属于每种类型的特定请求的概率。 数据被分为五个没有交集的块:该模型基于其中四个构建,并在第五个上进行测试。 由于每个请求只能分配一种请求,因此决策的规则很简单-通过最大概率值。
原型2:算法和工作原理
由VTB Capital团队准备的提案的第二个原型是Microsoft .NET Core上的一个应用程序,带有用于实现机器学习算法的Microsoft.ML库和用于通过REST API与Jira交互的Atlassian.Net SDK。 建立ML模型的基础也成为历史数据-50,000吉拉门票。 与第一种情况一样,机器学习涵盖了“摘要”和“描述”字段。 在使用之前,两个字段也都被“清理”了。 问候语,签名,通信历史记录和非文本元素(例如图像)已从用户的信件中删除。 此外,使用Microsoft ML中的内置功能,可以从英文文本中清除与处理和分析文本无关的停用词。
选择平均感知器(二进制分类)作为机器学习算法,并通过“一种对所有”方法进行补充以提供多类分类
结果评估
尚无ML模型可以(可能)提供100%的结果准确性。
1号算法原型提供了正确分类(准确度)的份额,等于请求总数的0.8003,即80%。 此外,在假设人们将从解决方案提供的两个答案中选择正确答案的情况下,相似度量的值达到0.901或90%。 当然,在某些情况下,开发的解决方案效果较差或无法给出正确的答案-通常,这是由于单词集太短或请求本身中信息的特殊性所致。 学习过程中使用的数据量不足,仍然发挥着作用。 根据初步估计,处理信息量的增加将使分类精度再提高0.01-0.03点成为可能。
评估准确性(Precision)和完整性(Recall)的最佳模型的结果如下:

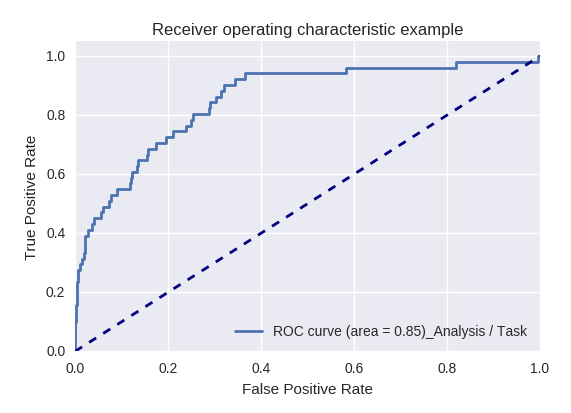
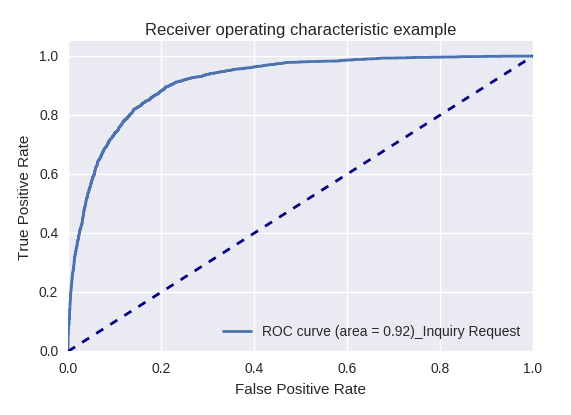
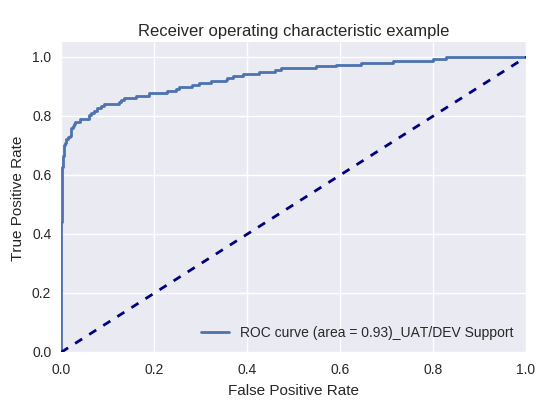
如果我们使用ROC-AUC曲线对各种类型的查询评估模型的整体质量,则结果如下。
行动请求(动作请求)和信息分析(分析/任务请求)
 业务数据更改请求(业务数据请求)和更改请求(更改请求)
业务数据更改请求(业务数据请求)和更改请求(更改请求)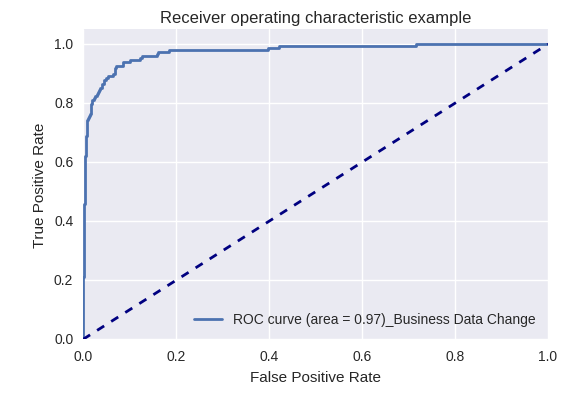
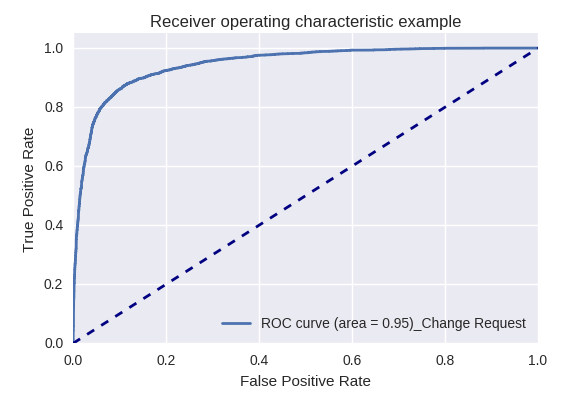 开发请求和查询请求
开发请求和查询请求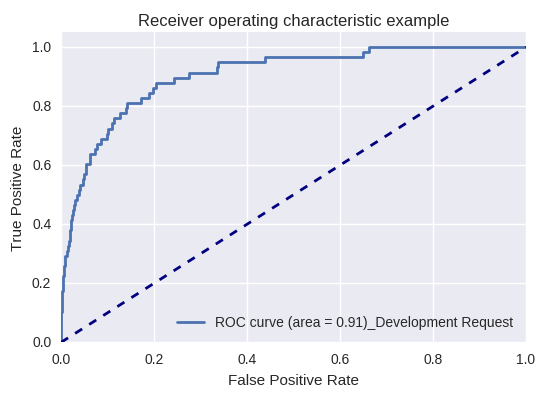
 创建新对象的请求(New Object Request)和添加新用户的请求(New User Request)
创建新对象的请求(New Object Request)和添加新用户的请求(New User Request)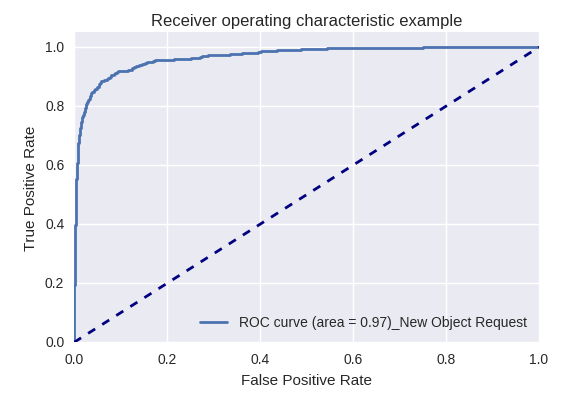
 生产请求和UAT / DEV支持请求(UAT / Dev支持请求)
生产请求和UAT / DEV支持请求(UAT / Dev支持请求)
下面给出了某些类型的查询的正确和错误分类的示例:
询价单
变更要求
正确分类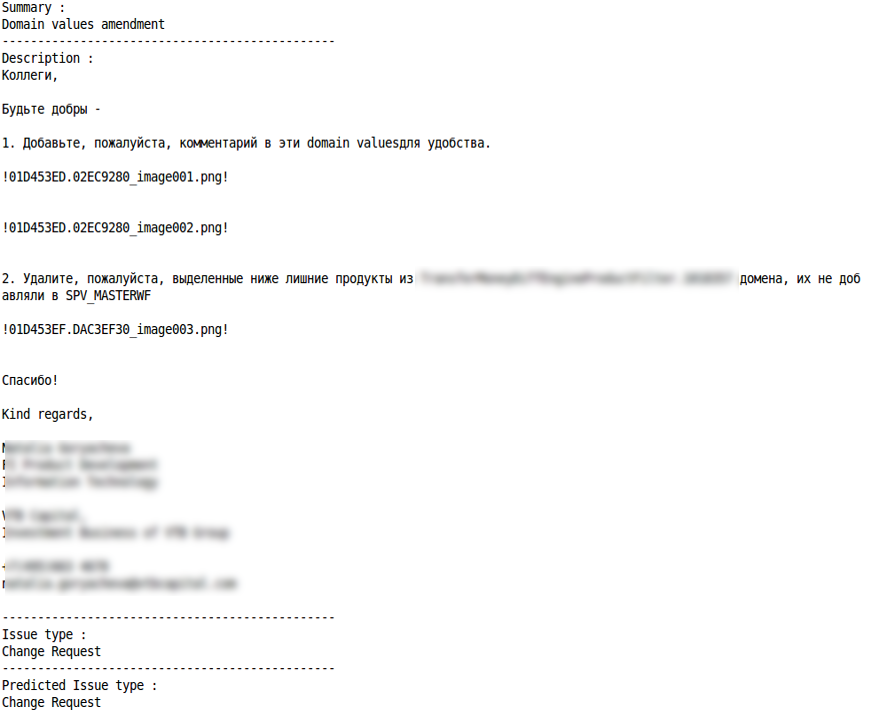 分类错误
分类错误 行动要求正确分类
行动要求正确分类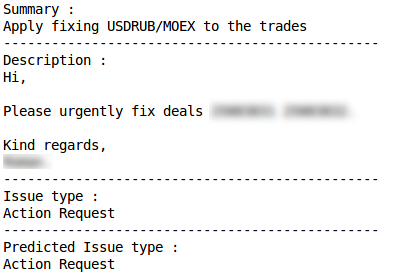 分类错误生产问题正确分类
分类错误生产问题正确分类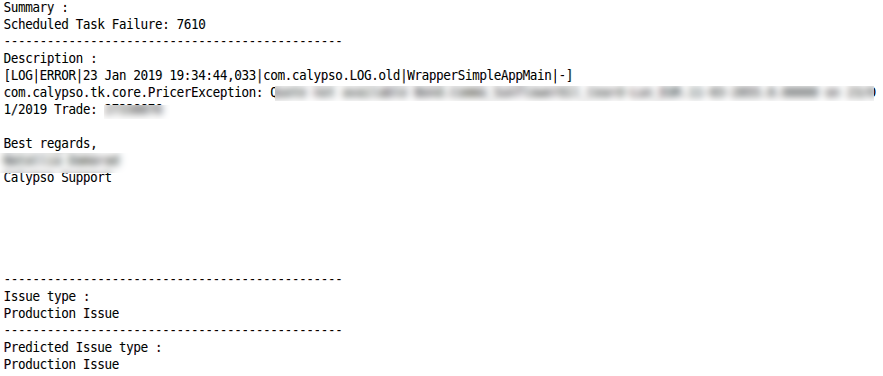 分类错误
分类错误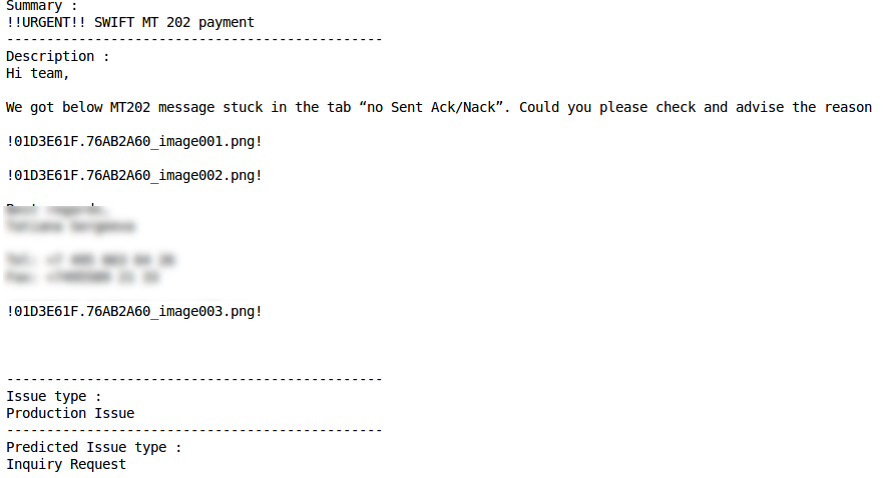
第二个原型也显示出良好的结果:在大约75%的情况下,ML正确地确定了查询的类型(准确性指标)。 改进指标的机会与提高源数据的质量有关,尤其是消除了将相同查询分配给不同类型的情况。
总结一下
每个已实现的原型都显示出了有效性,现在,两个已开发的原型的组合已在VTB Capital投入试生产。 在不到一个月的时间里以最小的成本进行了一次ML小型实验,使该公司熟悉了机器学习工具并解决了分类用户请求的重要应用问题。
EPAM和VTB Capital的开发人员所获得的经验,除了使用已实现的算法来处理用户的进一步开发请求之外,还可以用于解决与信息流处理有关的各种问题。 小迭代的过程和一个过程的覆盖使您逐渐掌握和组合各种工具和技术,选择久经考验的选项,而放弃效果不佳的选项。 这对于IT团队来说很有趣,同时有助于获得对于管理和业务很重要的结果。