众所周知,软件开发人员最喜欢的消遣方式之一就是面试雇主。 我们都是出于完全不同的原因,不时这样做。 我认为,其中最明显的是求职并不是最常见的。 参加面试是保持健康,重复被遗忘的基础知识和学习新知识的好方法。 而且,如果成功的话,还可以增强自信心。 我们感到无聊,我们在诸如
“ LinkedIn”之类的“商业”社交网络中将自己设置为“开放报价”的状态-人力资源经理大军已经在攻击我们收件箱中的传入消息。

在此过程中,尽管发生了所有麻烦,但我们面临着许多问题,正如他们在隐性折叠的窗帘的另一侧所说的那样,它们正在“摇铃”,其细节隐藏在
战争迷雾的背后。 通常只会在通过算法和数据结构进行的测试(个人而言,我根本没有此类数据)以及实际采访中才回忆起它们。
清单是任何专业程序员采访中最常见的问题之一。 例如,单链列表。 以及相关的基本算法。 例如,掉头。 通常,这种情况是这样发生的:“很好,但是您将如何扩展单链表?” 最主要的是让这个问题让申请人感到惊讶。
实际上,所有这些使我写了这篇简短的评论,以不断提醒和启发。 所以,开个玩笑,瞧!
单链表
链表是基本
数据结构之一 。 实际上,它的每个元素(或节点)都由存储的数据和到相邻元素的链接组成。 单链接列表仅存储指向结构中下一个元素的链接,而
双链接列表则保存下一个和上一个元素。 这样的数据组织允许它们位于任何存储区域中(例如,与
数组不同 ,所有
数组的元素都应该一个接一个地位于内存中)。
当然,关于列表还有很多要说的:它们可以是循环的(即最后一个元素存储到第一个元素的链接),也可以不是(即没有到最后一个元素的链接)。 可以输入列表,即 是否包含相同类型的数据。 依此类推。
最好尝试编写一些代码。 例如,以某种方式可以想象一个列表节点:
final class Node<T> { let payload: T var nextNode: Node? init(payload: T, nextNode: Node? = nil) { self.payload = payload self.nextNode = nextNode } }
“通用”是在
payload字段中能够存储任何类型的有效负载的类型。
该列表本身由其第一个节点详尽地标识:
final class SinglyLinkedList<T> { var firstNode: Node<T>? init(firstNode: Node<T>? = nil) { self.firstNode = firstNode } }
第一个节点被声明为可选节点,因为列表很可能为空。
从理论上讲,当然,在该类中,您需要实现所有必需的方法-插入,删除,访问节点等,但是我们将在其他时间实现。 同时,我们将检查使用struct ( Apple积极鼓励我们使用的示例)是否是更好的选择,也许还记得“写时复制”方法。单链列表传播
第一种方式。 循环次数
现在是时候开始做我们今天要从事的事情了! 处理它的最有效方法是两种方法。 第一个是一个简单的循环,从第一个节点到最后一个节点。
该循环使用三个变量,这些变量在开始之前被分配了上一个,当前和下一个节点的值。 (此时,前一个节点的值自然为空。)该循环从检查下一个节点不为空开始,如果是,则执行循环的主体。 循环中没有任何魔术发生:在当前节点上,指向下一个元素的字段被分配一个指向前一个元素的链接(在第一次迭代时,分别重置了链接的值,这对应于最后一个节点的事务状态)。 进一步,对应于上一个,当前和下一个节点的变量将被分配新值。 退出循环后,当前节点(即通常最后一个可迭代的节点)被分配一个新的链接值到下一个节点,因为 当列表中的最后一个节点成为当前节点时,就会退出循环。
换句话说,这听起来似乎很奇怪而且难以理解,所以最好看一下代码:
extension SinglyLinkedList { func reverse() { var previousNode: Node<T>? = nil var currentNode = firstNode var nextNode = firstNode?.nextNode while nextNode != nil { currentNode?.nextNode = previousNode previousNode = currentNode currentNode = nextNode nextNode = currentNode?.nextNode } currentNode?.nextNode = previousNode firstNode = currentNode } }
为了进行验证,我们使用有效载荷为简单
整数标识符的节点列表。 创建十个元素的列表:
let node = Node(payload: 0)
一切似乎都很好,但是我们是人,而不是计算机,这对我们很容易获得所创建列表和上述算法的正确性的直观证明。 也许简单的打印就足够了。 为了使输出可读,将
CustomStringConvertible协议的实现添加
CustomStringConvertible具有整数标识符
CustomStringConvertible节点:
extension Node: CustomStringConvertible where T == Int { var description: String { let firstPart = """ Node \(Unmanaged.passUnretained(self).toOpaque()) has id \(payload) and """ if let nextNode = nextNode { return firstPart + " next node \(nextNode.payload)." } else { return firstPart + " no next node." } } }
...并以相应的列表顺序显示所有节点:
extension SinglyLinkedList: CustomStringConvertible where T == Int { var description: String { var description = """ List \(Unmanaged.passUnretained(self).toOpaque()) """ if firstNode != nil { description += " has nodes:\n" var node = firstNode while node != nil { description += (node!.description + "\n") node = node!.nextNode } return description } else { return description + " has no nodes." } } }
我们类型的字符串表示形式将包含一个内存地址和一个整数标识符。 使用它们,我们组织了十个节点的生成列表的打印:
print(String(describing: list))
展开此列表并再次打印:
list.reverse() print(String(describing: list))
您可能会注意到列表和节点的内存中的地址未更改,并且列表的节点以相反的顺序打印。 现在,对节点的下一个元素的引用指向前一个元素(即,例如,节点“ 5”的下一个元素现在不是“ 6”,而是“ 4”)。 这意味着我们做到了!
第二种方式。 递归
进行相同掉头的第二种已知方法是基于
递归 。 为了实现它,我们将声明一个函数,该函数采用列表的第一个节点,并返回“新”的第一个节点(之前的最后一个节点)。
参数和返回值是可选的,因为在此函数内部,将在每个后续节点上一次又一次地调用它,直到它为空(即直到列表末尾)。 因此,在函数主体中,有必要检查在其上调用该函数的节点是否为空,以及该节点是否具有以下内容。 如果不是,则该函数返回传递给参数的内容。
实际上,我确实尝试用语言描述了完整的算法,但是最后我几乎擦除了所有内容,因为结果难以理解。 绘制流程图并正式描述算法的步骤-同样,在这种情况下,我认为这没有任何意义,因为这对您我来说都更方便阅读和尝试理解
Swift代码:
extension SinglyLinkedList { func reverseRecursively() { func reverse(_ node: Node<T>?) -> Node<T>? { guard let head = node else { return node } if head.nextNode == nil { return head } let reversedHead = reverse(head.nextNode) head.nextNode?.nextNode = head head.nextNode = nil return reversedHead } firstNode = reverse(firstNode) } }
为了调用方便,算法本身由实际列表类型的方法“包装”。
它看起来更短,但我认为更难理解。
我们对之前的价差结果调用此方法,并打印新的结果:
list.reverseRecursively() print(String(describing: list))
从输出中可以看到,存储器中的所有地址都没有再次更改,并且节点现在按照原始顺序进行了跟随(也就是说,它们又被“部署”了)。 这意味着我们再次正确!
结论
如果仔细研究逆向方法(或进行调用计数实验),您会注意到第一种情况下的循环和第二种情况下的内部(递归)方法调用的次数比列表中节点数少一倍(在本例中为九个)次)。 您还可以注意在第一种情况下循环发生的事情-分配顺序相同-在第二种情况下注意第一个非递归方法调用。 事实证明,在两种情况下,对于十个节点的列表,“圆”都重复了十次。 因此,我们对两种算法都具有线性
复杂度 -O(n) 。
一般而言,描述的两种算法被认为是解决此问题最有效的方法。 至于计算复杂度,不可能提出一种值较低的算法:一种或另一种方式,您需要“访问”每个节点,以便为存储在链接中的一个节点分配一个新值。
另一个值得一提的功能是“分配的内存复杂性”。 两种提出的算法都会创建固定数量的新变量(第一种情况为三个,第二种情况为一个)。 这意味着分配的内存量不取决于输入数据的定量特性,而是由常数函数O(1)来描述。
但是,实际上,在第二种情况下并非如此。 递归的危险是为
堆栈上的每个递归调用分配了额外的内存。 在我们的情况下,递归深度对应于输入数据量。
最后,我决定做更多的实验:以一种简单的原始方式,针对不同数量的输入数据,测量了两种方法的绝对执行时间。 像这样:
let startDate = Date().timeIntervalSince1970
这就是我得到的(这是来自
Playground的原始数据):
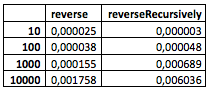
(不幸的是,我的计算机尚未掌握较大的值。)
从表中可以看到什么? 没什么特别的。 尽管已经注意到递归方法在节点数量相对较少的情况下表现较差,但在100到1000之间的某个地方,它开始表现出更好的效果。
我还在成熟的
“ Xcode”项目中尝试了相同的简单测试。 结果如下:

首先,值得一提的是,结果是在激活针对执行速度(
-Ofast )的“积极”优化模式之后获得的,这部分是数量如此之少的原因。 有趣的是,在这种情况下,递归方法表现出更好的效果,相反,仅在非常小的输入数据上并且已经在100个节点的列表上,该方法失败了。 在100,000个中,他使程序异常终止。
结论
从目前我最喜欢的编程语言的角度来看,我试图涵盖一个相当经典的话题,希望您以及我自己都对进步感到好奇。 如果您也能学到新的东西,我也感到非常高兴-然后,我肯定在本文上浪费了我的时间(而不是坐在
电视上 )。
如果有人希望跟踪我的社交活动,请访问我的“ Twitter”链接,其中首先有指向我的新帖子的链接,还有更多链接。