如果以前的文章更有可能成为种子,那么现在是时候在她的计算机上测试Julia的并行化功能了。
多核或分布式处理
Distributed模块提供了与分布式内存并行计算的实现,这是Julia随附的标准库的一部分。 大多数现代计算机都具有不止一个处理器,并且可以将多台计算机集群。 利用这些多个处理器的功能,您可以更快地执行许多计算。 性能受两个主要因素影响:处理器本身的速度和其内存访问的速度。 在群集中,很明显,此CPU将对同一台计算机(节点)上的RAM进行最快的访问。 也许更令人惊讶的是,由于主内存和缓存速度的差异,此类问题在典型的多核笔记本电脑上还是很重要的。 因此,良好的多处理器环境应允许您通过特定处理器控制部分内存的“所有权”。 Julia提供了一个基于消息的多处理器环境,该环境允许程序在不同内存域中的多个进程上同时运行。
Julia的消息传递实现与其他环境(例如MPI [1])不同 。 Julia中的通信通常是“单向”的,这意味着程序员只需在两进程操作中显式地控制一个进程即可。 另外,这些操作通常看起来不像“发送消息”和“接收消息”,而是类似于更高级别的操作,例如对用户定义函数的调用。
Julia中的分布式编程基于两个原语构建: 远程链接和远程调用 。 远程链接是一个对象,可以从任何进程使用它来引用存储在特定进程中的对象。 远程调用是一个进程根据另一个(可能是相同的)进程的某些自变量调用某个函数的请求。
远程链接有两种形式: Future和RemoteChannel 。
远程调用返回Future并立即执行; 进行呼叫的过程继续进行下一个操作,而远程呼叫发生在其他地方。 您可以使用返回的Future的wait命令来等待远程调用完成,也可以使用fetch获取结果的完整值。
另一方面,我们有重写的RemoteChannels。 例如,多个进程可以引用相同的远程通道来协调其处理。 每个进程都有一个关联的标识符。 提供Julia交互式提示的进程的标识符始终为1。默认情况下,用于并发操作的进程称为“工人”。 如果只有一个进程,则认为进程1是有效的。 否则,除过程1之外的所有其他过程均被视为工作程序。

让我们开始吧。 以julia -pn后记在本地计算机上提供了n个工作流。 通常,n等于机器上的CPU线程(逻辑核心)数量是有意义的。 请注意,-p参数隐式加载Distributed模块。
如何开始撰写附言?对于Linux用户,控制台操作应该简单明了。 此教育程序适用于没有经验的Windows用户。
终端Julia(REPL)提供了使用系统命令的功能:
julia> pwd() # "C:\\Users\\User\\AppData\\Local\\Julia-1.1.0" julia> cd("C:/Users/User/Desktop") # julia> run(`calc`) # # Windows. # Process(`calc`, ProcessExited(0))
使用这些命令,您可以从朱莉娅(Julia)开始朱莉娅(Julia),但最好不要被它带走
从julia / bin /运行cmd并在那里运行julia -p 2命令或爱好者从快捷方式启动的选项会更正确:在桌面上,创建一个包含以下内容的记事本文档C:\Users\User\AppData\Local\Julia-1.1.0\bin\julia -p 4 ( 指定进程的地址和数量 ),并将其保存为文本文件,名称为run.bat 。 在这里,现在您的桌面上有一个用于4个核心的Julia启动系统文件。
您可以使用另一种方法(特别是对于Jupyter而言 ):
using Distributed addprocs(2)
$ ./julia -p 2 julia> r = remotecall(rand, 2, 2, 2) Future(2, 1, 4, nothing) julia> s = @spawnat 2 1 .+ fetch(r) Future(2, 1, 5, nothing) julia> fetch(s) 2×2 Array{Float64,2}: 1.18526 1.50912 1.16296 1.60607
remotecall的第一个参数是被调用的函数。
Julia中的大多数并发程序都没有引用特定的进程或可用的进程数,但是远程调用被视为提供更精确控制的低级接口。
remotecall的第二个参数是将要完成工作的进程的标识符,其余参数将传递给被调用的函数。 如您所见,在第一行中,我们要求处理2建立一个随机的2 x 2矩阵,在第二行中,我们要求向其添加1。 两种计算的结果在两个期货r和s中可用。 spawnat宏对第一个参数中指定的过程的第二个参数中的表达式求值。 有时您可能需要一个远程计算的值。 当您从远程对象读取以获取下一个本地操作所需的数据时,通常会发生这种情况。 remotecall_fetch有一个remotecall_fetch函数。 这等效于fetch (remotecall (...)) ,但效率更高。
请记住, getindex(r, 1,1)等效于r[1,1] ,因此此调用将检索未来r的第一个元素。
remotecall远程调用remotecall不是特别方便。 @spawn宏使@spawn变得更容易。 它使用表达式而不是函数,并为您选择在何处执行操作:
julia> r = @spawn rand(2,2) Future(2, 1, 4, nothing) julia> s = @spawn 1 .+ fetch(r) Future(3, 1, 5, nothing) julia> fetch(s) 2×2 Array{Float64,2}: 1.38854 1.9098 1.20939 1.57158
请注意,我们使用1 .+ Fetch(r)代替1 .+ r 这是因为我们不知道代码将在何处执行,因此在一般情况下,可能有必要提取以将r移至加法过程。 在这种情况下, @spawn足够聪明,可以为拥有r的进程执行计算,因此提取将无法进行操作(不完成任何工作)。 (值得注意的是,spawn不是内置的,而是在Julia中定义为宏。您可以定义自己的此类构造。)
重要的是要记住,提取后, Future将在本地缓存其值。 进一步的获取调用并不意味着网络的飞跃。 选择所有参考期货后,将删除已删除的存储值。
@async与@spawn相似,但仅在本地进程中运行任务。 我们使用它为每个流程创建一个“提要”任务。 每个任务都会选择下一个必须计算的索引,然后等待该过程完成并重复直到我们用完索引为止。
请注意,直到主任务到达@sync块的末尾之后, 供稿器任务才开始执行,然后它通过控制并等待所有本地任务的完成,然后从函数返回。
对于v0.7及更高版本,Feeder任务可以通过nextidx共享状态,因为所有任务均在同一进程中执行。 即使任务是一起计划的,在某些情况下(例如异步I / O)也可能需要阻塞。 这意味着上下文切换仅在定义明确的点发生:在这种情况下,当remotecall_fetch时。 这是当前的实现状态,在Julia的将来版本中可能会更改,因为它被设计为能够在M个进程或M:N线程中完成多达N个任务。 然后,我们需要一个模型来获取/释放nextidx锁,因为允许多个进程同时读取和写入资源是不安全的。
您的代码必须可用于运行它的任何进程。 例如,在Julia提示符下,键入以下内容:
julia> function rand2(dims...) return 2*rand(dims...) end julia> rand2(2,2) 2×2 Array{Float64,2}: 0.153756 0.368514 1.15119 0.918912 julia> fetch(@spawn rand2(2,2)) ERROR: RemoteException(2, CapturedException(UndefVarError(Symbol("#rand2")) Stacktrace: [...]
进程1知道函数rand2,但是进程2不知道。 通常,您将从文件或包中下载代码,并且在控制加载代码的进程方面具有极大的灵活性。 考虑包含以下代码的DummyModule.jl文件:
module DummyModule export MyType, f mutable struct MyType a::Int end f(x) = x^2+1 println("loaded") end
要在所有进程中引用MyType ,必须在每个进程中加载DummyModule.jl 。 调用include ('DummyModule.jl')仅将其加载到一个进程中。 要将其加载到每个进程中,请使用@everywhere宏(使用julia -p 2运行Julia):
julia> @everywhere include("DummyModule.jl") loaded From worker 3: loaded From worker 2: loaded
与往常一样,这不会使DummyModule可访问任何需要使用或导入的进程。 此外,当DummyModule包含在一个进程的范围内时,则不包含在其他任何进程中:
julia> using .DummyModule julia> MyType(7) MyType(7) julia> fetch(@spawnat 2 MyType(7)) ERROR: On worker 2: UndefVarError: MyType not defined ⋮ julia> fetch(@spawnat 2 DummyModule.MyType(7)) MyType(7)
但是,例如,仍然可以将MyType发送到加载DummyModule的进程,即使它不在范围内:
julia> put!(RemoteChannel(2), MyType(7)) RemoteChannel{Channel{Any}}(2, 1, 13)
也可以在启动时使用-L标志将该文件预加载到多个进程中,并且驱动程序脚本可用于控制计算:
julia -p <n> -L file1.jl -L file2.jl driver.jl
上面示例中运行驱动程序脚本的Julia进程的标识符为1,就像提供交互式提示的进程一样。 最后,如果DummyModule.jl不是一个单独的文件,而是一个包,则使用DummyModule将在所有进程中加载DummyModule.jl,但只会将其传输到被调用的进程范围内。
启动和管理工作流程
基本的Julia安装具有对两种类型的群集的内置支持:
- 使用-p选项指定的本地集群,如上所示。
- 使用--machine-file选项集群计算机。 这将使用没有密码的ssh登录名在指定计算机上启动Julia工作流(与当前主机相同的路径)。

函数addprocs , rmprocs , worker和其他函数可作为软件工具使用,用于在集群中添加,删除和查询进程。
julia> using Distributed julia> addprocs(2) 2-element Array{Int64,1}: 2 3
在调用addprocs之前,必须将Distributed模块显式加载到主进程中。 它自动适用于工作流程。 请注意,工作人员不要运行启动脚本~/.julia/config/startup.jl也不~/.julia/config/startup.jl其全局状态(例如全局变量,新方法的定义和已加载模块)与任何其他正在运行的进程同步。 可以通过编写自己的ClusterManager来支持其他类型的集群,如下面在ClusterManager部分中所述。
数据动作
发送消息和移动数据构成了分布式程序中的大部分开销。 减少消息数量和发送的数据量对于实现性能和可伸缩性至关重要。 为此,了解Julia的各种分布式编程结构执行的数据移动非常重要。
fetch可以看作是显式的数据移动操作,因为它直接请求将对象移动到本地计算机。 @spawn (以及几个相关的构造)也可以移动数据,但这并不是很明显,因此可以将其称为隐式数据移动操作。 考虑以下两种构建和平方随机矩阵的方法:
行程时间:
julia> A = rand(1000,1000); julia> Bref = @spawn A^2; [...] julia> fetch(Bref);
方法二:
julia> Bref = @spawn rand(1000,1000)^2; [...] julia> fetch(Bref);
差异似乎微不足道,但实际上由于@spawn的行为, @spawn非常明显。 在第一种方法中,随机矩阵是在本地构建的,然后发送到另一个过程中进行平方。 在第二种方法中,建立一个随机矩阵并将其平方在另一个过程上。 因此,第二种方法发送的数据少于第一种。 在这个玩具示例中,这两种方法很容易区分和选择。 但是,在实际程序中,设计数据移动可能非常昂贵,并且可能需要一些度量。
例如,如果第一个过程需要矩阵A,则第一个方法可能会更好。 或者,如果计算A昂贵且仅使用当前进程,则将其转移到另一个进程可能是不可避免的。 或者,如果当前过程在spawn和fetch(Bref)之间没有太多共同点,则最好完全消除并发性。 或想象rand(1000, 1000)更昂贵的操作rand(1000, 1000)取代。 然后可能仅在此步骤中添加另一个spawn语句。
全局变量
通过spawn远程执行的表达式或使用remotecall指定用于远程执行的闭包可以引用全局变量。 Main模块中的全局绑定与其他模块中的全局绑定有些不同。 考虑以下代码片段:
A = rand(10,10) remotecall_fetch(()->sum(A), 2)
在这种情况下,必须在远程过程中定义sum 。 请注意, A是在本地工作空间中定义的全局变量。 Worker 2在“ Main部分中没有名为A的变量。 发送工作者2的关闭函数() -> sum(A)导致Main.A在2上定义。即使在remotecall_fetch调用remotecall_fetch后, Main.A仍然存在于工作者2上。

具有嵌入式全局引用(仅在主模块中)的远程调用按以下方式管理全局变量:
- 如果将新的全局绑定作为远程调用的一部分进行引用,则会在目标工作站上创建它们。
- 全局常量也被声明为远程节点上的常量。
- 仅在远程呼叫的情况下且仅当其值已更改时,才将全局变量重新提交给目标员工。 此外,群集不同步节点之间的全局绑定。 例如:
A = rand(10,10) remotecall_fetch(()->sum(A), 2)
执行上面的片段会导致一个事实, Main.A雇员2上的Main.A与雇员3上的Main.A具有不同的值,而节点1上的Main.A的值为零。
如您可能理解的那样,尽管与全局变量关联的内存可以在将它们重新分配给主设备时收集,但是由于绑定继续起作用,因此不会为工作人员执行此类操作。 清楚! 如果不再需要某些全局变量,可以使用它们手动将它们重新分配为nothing 。 作为正常垃圾回收周期的一部分,这将释放与它们关联的所有内存。 因此,在远程调用中访问全局变量时,程序应格外小心。 实际上,只要有可能,最好完全避免它们。 如果必须引用全局变量,请考虑使用let块来本地化全局变量。 例如:
julia> A = rand(10,10); julia> remotecall_fetch(()->A, 2); julia> B = rand(10,10); julia> let B = B remotecall_fetch(()->B, 2) end; julia> @fetchfrom 2 InteractiveUtils.varinfo() name size summary ––––––––– ––––––––– –––––––––––––––––––––– A 800 bytes 10×10 Array{Float64,2} Base Module Core Module Main Module
显而易见,全局变量A在工作程序2上定义的,但是B作为局部变量编写的,因此,在工作程序2上不存在B的绑定。
并行循环

幸运的是,许多有用的并发计算不需要数据移动。 一个典型的例子是蒙特卡洛模拟,其中几个过程可以同时处理独立的模拟测试。 我们可以使用@spawn将硬币翻转为两个过程。 首先在count_heads.jl编写以下函数:
function count_heads(n) c::Int = 0 for i = 1:n c += rand(Bool) end c end
count_heads函数仅将n个随机位相加。 这是我们可以在两台计算机上进行一些测试并加总结果的方法:
julia> @everywhere include_string(Main, $(read("count_heads.jl", String)), "count_heads.jl") julia> a = @spawn count_heads(100000000) Future(2, 1, 6, nothing) julia> b = @spawn count_heads(100000000) Future(3, 1, 7, nothing) julia> fetch(a)+fetch(b) 100001564
此示例演示了功能强大且经常使用的并行编程模式。 在多个过程中独立执行许多迭代,然后使用某些函数将其结果合并。 联合过程称为约简,因为它通常会降低张量等级:将数的向量缩减为一个数,或者将矩阵缩减为一行或一列,依此类推。 在代码中,通常如下所示:模式x = f(x, v [i]) ,其中x是电池, f是归约函数,而v[i]是要归约的元素。
期望f是关联的,使得操作以什么顺序执行无关紧要。 请注意,我们将此模板与count_heads一起count_heads可能是通用的。 我们使用了两个显式的spawn语句,将并发限制为两个进程。 要在任意数量的进程上运行,我们可以在分布式内存中使用并行for循环操作,可以使用distributed将其写入Julia,例如:
nheads = @distributed (+) for i = 1:200000000 Int(rand(Bool)) end
( (+) ). . .
, for , . , , , . , , . , :
a = zeros(100000) @distributed for i = 1:100000 a[i] = i end
, . , . , Shared Arrays , , :
using SharedArrays a = SharedArray{Float64}(10) @distributed for i = 1:10 a[i] = i end
«» , :
a = randn(1000) @distributed (+) for i = 1:100000 f(a[rand(1:end)]) end
f , . , , . , Future , . Future , fetch , , @sync , @sync distributed for .
, (, , ). , , Julia pmap . , :
julia> M = Matrix{Float64}[rand(1000,1000) for i = 1:10]; julia> pmap(svdvals, M);
pmap , . , distributed for , , , . pmap , distributed . distributed for .
(Shared Arrays)

Shared Arrays . DArray , SharedArray . DArray , ; , SharedArray .
SharedArray — , , . Shared Array SharedArrays , . SharedArray ( ) , , . SharedArray , . , Array , SharedArray , sdata . AbstractArray sdata , sdata Array . :
SharedArray{T,N}(dims::NTuple; init=false, pids=Int[])
N - T dims , pids . , , pids ( , ).
init initfn(S :: SharedArray) , . , init , .
:
julia> using Distributed julia> addprocs(3) 3-element Array{Int64,1}: 2 3 4 julia> @everywhere using SharedArrays julia> S = SharedArray{Int,2}((3,4), init = S -> S[localindices(S)] = myid()) 3×4 SharedArray{Int64,2}: 2 2 3 4 2 3 3 4 2 3 4 4 julia> S[3,2] = 7 7 julia> S 3×4 SharedArray{Int64,2}: 2 2 3 4 2 3 3 4 2 7 4 4
SharedArrays.localindices . , , :
julia> S = SharedArray{Int,2}((3,4), init = S -> S[indexpids(S):length(procs(S)):length(S)] = myid()) 3×4 SharedArray{Int64,2}: 2 2 2 2 3 3 3 3 4 4 4 4
, , . 例如:
@sync begin for p in procs(S) @async begin remotecall_wait(fill!, p, S, p) end end end
. pid , , ( S ), pid .
«»:
q[i,j,t+1] = q[i,j,t] + u[i,j,t]
, , , , , : q [i,j,t] , q[i,j,t+1] , , , q[i,j,t] , q[i,j,t+1] . . . , (irange, jrange) , :
julia> @everywhere function myrange(q::SharedArray) idx = indexpids(q) if idx == 0
:
julia> @everywhere function advection_chunk!(q, u, irange, jrange, trange) @show (irange, jrange, trange)
SharedArray
julia> @everywhere advection_shared_chunk!(q, u) = advection_chunk!(q, u, myrange(q)..., 1:size(q,3)-1)
, :
julia> advection_serial!(q, u) = advection_chunk!(q, u, 1:size(q,1), 1:size(q,2), 1:size(q,3)-1);
@distributed :
julia> function advection_parallel!(q, u) for t = 1:size(q,3)-1 @sync @distributed for j = 1:size(q,2) for i = 1:size(q,1) q[i,j,t+1]= q[i,j,t] + u[i,j,t] end end end q end;
, :
julia> function advection_shared!(q, u) @sync begin for p in procs(q) @async remotecall_wait(advection_shared_chunk!, p, q, u) end end q end;
SharedArray , ( julia -p 4 ):
julia> q = SharedArray{Float64,3}((500,500,500)); julia> u = SharedArray{Float64,3}((500,500,500));
JIT- @time :
julia> @time advection_serial!(q, u); (irange,jrange,trange) = (1:500,1:500,1:499) 830.220 milliseconds (216 allocations: 13820 bytes) julia> @time advection_parallel!(q, u); 2.495 seconds (3999 k allocations: 289 MB, 2.09% gc time) julia> @time advection_shared!(q,u); From worker 2: (irange,jrange,trange) = (1:500,1:125,1:499) From worker 4: (irange,jrange,trange) = (1:500,251:375,1:499) From worker 3: (irange,jrange,trange) = (1:500,126:250,1:499) From worker 5: (irange,jrange,trange) = (1:500,376:500,1:499) 238.119 milliseconds (2264 allocations: 169 KB)
advection_shared! , , .
, . , , .
, , , .
- Julia
, , , .
, , -. , 在哪里 — . - , .. , .
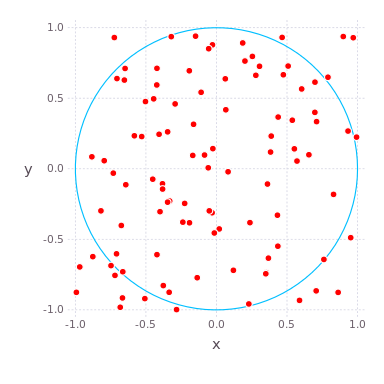
( , ) ( ) , , , . , , . compute_pi (N) , , .
function compute_pi(N::Int)
, , 。 : , , 25 .
Julia Pi.jl ( Sublime Text , ):
C:\Users\User\AppData\Local\Julia-1.1.0\bin\julia -p 4 julia> include("C:/Users/User/Desktop/Pi.jl")
using Distributed addprocs(4)
Jupyter
Pi.jl @everywhere function compute_pi(N::Int) n_landed_in_circle = 0
, :
julia> @time parallel_pi_computation(1000000000, ncores = 1) 6.818123 seconds (1.96 M allocations: 99.838 MiB, 0.42% gc time) 3.141562892 julia> @time parallel_pi_computation(1000000000, ncores = 1) 5.081638 seconds (1.12 k allocations: 62.953 KiB) 3.141657252 julia> @time parallel_pi_computation(1000000000, ncores = 2) 3.504871 seconds (1.84 k allocations: 109.382 KiB) 3.1415942599999997 julia> @time parallel_pi_computation(1000000000, ncores = 4) 3.093918 seconds (1.12 k allocations: 71.938 KiB) 3.1416889400000003 julia> pi ? = 3.1415926535897...
JIT - — . , Julia . , ( Multi-Threading, Atomic Operations, Channels Coroutines).
, , . MPI.jl MPI ,
DistributedArrays.jl .
GPU, :
- ( C) OpenCL.jl CUDAdrv.jl OpenCL CUDA.
- ( Julia) CUDAnative.jl CUDA .
- , , CuArrays.jl CLArrays.jl
- , ArrayFire.jl GPUArrays.jl
- -
- Kynseed
, , . !