有关计算机视觉,可解释性,NLP的文章-我们访问了日本的AISTATS会议,并希望分享文章的概述。 这是一次有关统计和机器学习的重要会议,今年将在台湾附近的冲绳岛举行。 在这篇文章中,Yulia Antokhina( Yulia_chan )从主要部分准备了精彩文章的描述,接下来她将与Anna Papeta一起讨论受邀讲师的报告和理论研究。 我们还将介绍会议本身的召开方式以及“非日本”日本的情况。 通过随机离散化防御白盒对抗攻击
通过随机离散化防御白盒对抗攻击张雨辰(微软); 珀西·梁(斯坦福大学)
→
文章→
代码让我们从一篇有关防止计算机视觉中的对抗性攻击的文章开始。 这些是针对模型的有针对性的攻击,当攻击的目的是使模型犯错误时,可以达到预定的结果。 即使对人的原始图片进行了很小的更改,计算机视觉算法也可能会出错。 例如,该任务与机器视觉有关,机器视觉在良好条件下比人更快地识别道路标志,但在袭击时却表现得差得多。
对抗攻击明显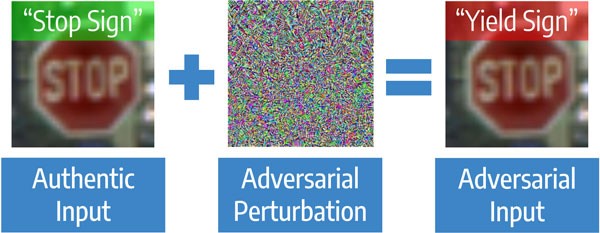
攻击是黑盒-攻击者对算法一无所知,而白盒则相反。 保护模型有两种主要方法。 第一种方法是在常规和“受攻击”的图片上训练模型-这称为对抗训练。 这种方法在像MNIST这样的小图片上效果很好,但是有文章表明,在像ImageNet这样的大图片上效果不佳。 第二种保护类型不需要重新训练模型。 在将图片提交给模型之前对其进行预处理就足够了。 转换示例:JPEG压缩,调整大小。 这些方法所需的计算量较少,但现在它们仅能抵御Blackbox攻击,因为如果已知转换,则可以采用相反的方法。
方法在本文中,作者提出了一种方法,该方法不需要对模型进行过度训练即可用于Whitebox攻击。 目的是使用随机变换来减少普通示例与“损坏”示例之间的Kullback-Leibner距离。 事实证明,添加随机噪声就足够了,然后对颜色进行随机采样。 也就是说,“受损的”图像质量被馈送到算法输入,但是仍然足以使算法起作用。 并且由于机会,有可能承受白盒攻击。
左侧是原始图片,中间是在Lab空间中对像素颜色进行聚类的示例,右侧是几种颜色的图片(例如,代替40种蓝色阴影-一个) 结果
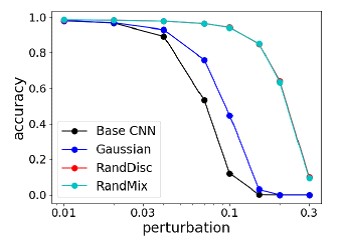
结果将该方法与NIPS 2017对抗攻击与防御比赛中最强的攻击进行了比较,它平均显示出最佳的质量,并且不会在“攻击者”下重新训练。
对抗NIPS竞赛中最强攻击的最强防御方法比较 不同图像变化下MNIST方法精度的比较
不同图像变化下MNIST方法精度的比较
 减轻字向量中的偏差
减轻字向量中的偏差Sunipa Dev(犹他大学); 杰夫·菲利普斯(犹他大学)
→
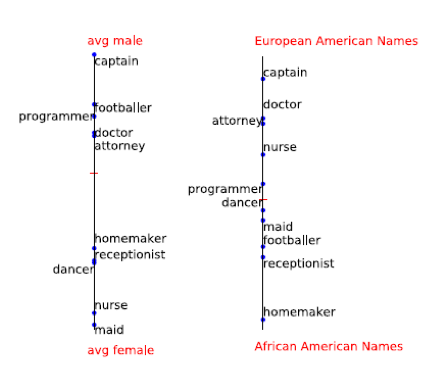
文章“时髦”的演讲是关于无偏词向量的。 在这种情况下,“偏见”表示单词表示中的性别或国籍偏见。 任何监管机构都可能反对这种“歧视”,因此,犹他大学的科学家决定研究NLP的“权利均等化”可能性。 实际上,为什么男人不能“魅力四射”,而女人不能“数据科学家”呢?
原始-现在获得的结果,其余-无偏算法的结果

本文讨论了一种发现这种偏差的方法。 他们认为性别和国籍由名字很好地表征。 因此,如果按名称找到偏移量并将其减去,那么很可能可以摆脱算法的偏差。
更多“男性”和“女性”一词的示例:
 查找性别补偿的名称:
查找性别补偿的名称:
奇怪的是,这种简单的方法有效。 作者训练了一个没有偏见的手套,并在Git中进行了布局。
是什么让你这么做的? 了解具有足够输入子集的黑盒决策布兰登·卡特(MIT CSAIL); Jonas Mueller(亚马逊网络服务); 悉达多·in那(MIT CSAIL); 大卫·吉福德(MIT CSAIL)
→
文章→
编码 两次下面的文章讨论有关充足输入子集算法。 SIS是即使生成的所有其他特征都可以在其中产生一定结果的最小特征子集。 这是以某种方式解释复杂模型结果的另一种方法。 适用于文本和图片。
SIS搜索算法的详细信息: 带有有关啤酒评论的文字上的应用示例:
带有有关啤酒评论的文字上的应用示例: MNIST上的应用示例:
MNIST上的应用示例: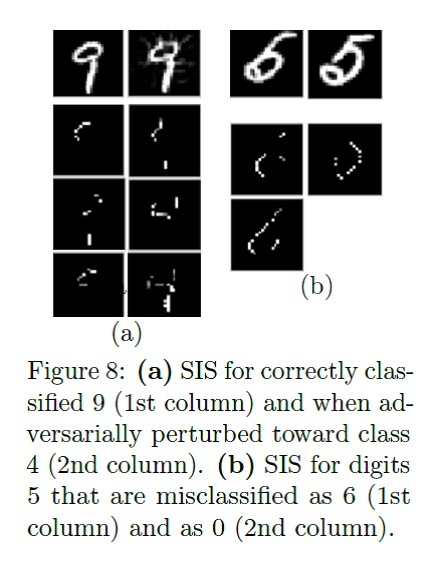 Kullback-Leibler距离相对于“理想”结果的“解释”方法的比较:
Kullback-Leibler距离相对于“理想”结果的“解释”方法的比较: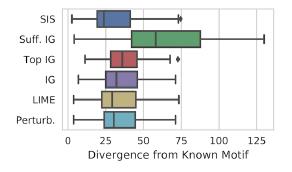
首先按对模型的影响对要素进行排名,然后从影响力最大的细分为不相交的子集。 它通过蛮力工作,并且在标记的数据集上,其结果比LIME的解释更好。 Google Research提供了SIS搜索的便捷实现。
关系数据的经验风险最小化和随机梯度下降Victor Veitch(哥伦比亚大学); Morgane Austern(哥伦比亚大学); 周文达(哥伦比亚大学); David Blei(哥伦比亚大学); 彼得·奥尔班兹(哥伦比亚大学)
→
文章→
代码在优化部分,有一份关于经验风险最小化的报告,作者探索了在图上应用随机梯度下降的方法。 例如,在社交网络数据上构建模型时,您只能使用配置文件的固定功能(订户数量),但是有关配置文件(已订阅)之间的连接的信息会丢失。 此外,整个图通常很难处理-例如,它不适合内存。 当这种情况出现在表格数据上时,可以在子样本上运行模型。 不清楚如何在图中选择子样本的类似物。 作者从理论上证实了使用随机子图作为子样本类似物的可能性,结果证明这是“不疯狂的想法”。 Github上的文章有可复制的示例,包括Wikipedia示例。
考虑到“维基百科”的图形结构,将其嵌入到类别中,所选文章最接近“法国物理学家”: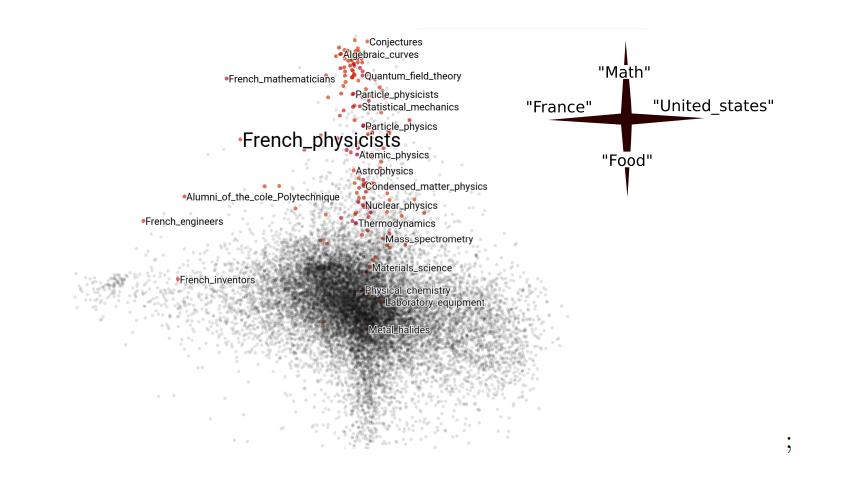
→
网络数据的数据科学离散数据图是演讲嘉宾演讲者Poling Loh(威斯康星大学麦迪逊分校)发表的另一篇关于网络数据的数据科学评论报告。 该演讲涵盖了统计推断,资源分配,局部算法等主题。 例如,在统计推断中,它是关于如何理解图表在传染病数据上的结构。 建议使用受感染节点之间连接数的统计信息-证明该定理可用于相应的统计检验。
通常,对于那些不涉及图模型但希望尝试并对如何正确测试图的假设感兴趣的人来说,最有可能观看报告。
会议进展如何AISTATS 2019是在冲绳举行的为期三天的会议。 这是日本,但是冲绳的文化更接近中国。 主要的购物街让人想起这么小的迈阿密,大街上有长途汽车,乡村音乐,而且旁边还有一点点-丛林中有蛇,红树林被台风扭曲。 当地的风味是由琉球文化创造的,琉球文化位于冲绳,但首先成为中国的附庸和贸易伙伴,然后被日本人占领。
显然,在冲绳岛,他们经常举行婚礼,因为那里有很多婚礼沙龙,会议在婚礼厅的场地举行。
超过500人聚集了科学家,文章作者,听众和演讲者。 在三天内,您几乎可以与所有人交谈。 尽管会议是在“世界尽头”举行的,但来自世界各地的代表还是来了。 尽管地域辽阔,但事实证明,我们所有人的利益都是相似的。 例如,令我们惊讶的是,来自澳大利亚的科学家解决了与我们团队相同的数据科学问题和方法。 但是,毕竟,我们生活在地球的几乎相反的两侧……该行业的参与者并不多:谷歌,亚马逊,MTS和其他几家顶级公司。
有一些日本赞助公司的代表,尽管“非日本人”在日本很难工作,但他们大多观看和倾听,而且很可能正在寻找某人。
提交会议的有关以下主题的文章:
其他所有内容都在我们的下一篇文章中。 不要错过!
公告: