研究工作也许是我们培训中最有趣的部分。 这个想法是即使在大学也要尝试选择的方向。 例如,来自软件工程和机器学习领域的学生经常去公司做研究(主要是JetBrains或Yandex,但不仅限于此)。
在这篇文章中,我将讨论我在计算机科学领域的项目。 作为工作的一部分,我研究并实践了解决最著名的NP难题之一的方法:
顶点覆盖问题 。
现在,解决NP困难问题的一种有趣方法正在迅速发展-参数化算法。 我将尝试使您快速入门,讲一些简单的参数化算法,并描述一种对我有很大帮助的强大方法。 我在PACE挑战赛上展示了我的结果:根据公开测试的结果,我的决定名列第三,最终结果将于7月1日公布。

关于我自己
我的名字叫瓦西里·阿尔费罗夫(Vasily Alferov),我现在正在完成HSE的三年级-圣彼得堡。 自学校时代起,我就一直喜欢算法,当时我在179所莫斯科学校学习并成功参加了计算机科学竞赛。
参数化算法的专家总数最终达到标准...
一个例子摘自《参数化算法》一书想象一下,您是一个小镇的酒吧保安。 每个星期五,有一半的城市到您的酒吧放松,这给您带来很多麻烦:您需要将暴力访客带出酒吧,以防止打架。 最后,它困扰您,您决定采取预防措施。
由于您的城市很小,因此您可以确定哪些游客如果一起去酒吧,很可能会产生争执。 您有
n人名单,今晚将来到酒吧。 您决定不让任何城镇居民进入酒吧,以便没有人打架。 同时,您的上级不想损失利润,并且如果您不让
k人以上的人参加律师会感到不满。
不幸的是,您面临的挑战是经典的NP艰巨任务。 您可以将其称为“
顶点覆盖 ”或“顶点覆盖问题”。 对于此类问题,通常情况下,在可接受的时间内工作的算法是未知的。 确切地说,未经证实且相当强大的假设ETH(指数时间假设)表示无法及时解决此问题
也就是说,无法想到比穷举搜索明显更好的东西。 例如,让
n = 1000人计划来您的酒吧。 然后将进行完整搜索
大概有的选择
-太疯狂了。 幸运的是,您的指南为您设置了
k = 10的限制,因此您需要迭代的组合数量要少得多:十个元素的子集数量为
。 这已经好了,但即使在功能强大的群集上,也算不上一天。
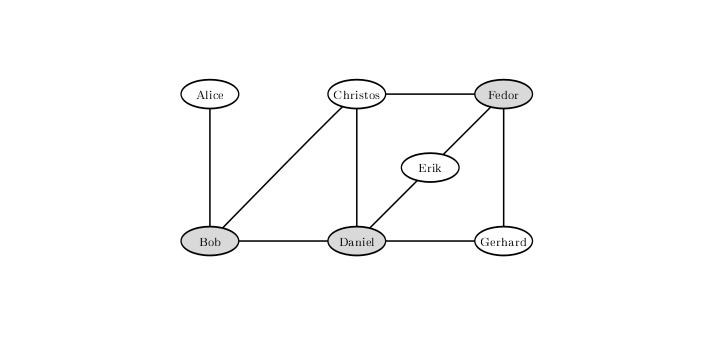
为了排除酒吧访客之间这种紧张关系造成的争斗可能性,您不得让Bob,Daniel和Fedor进入。 只有两个遗留在舷外的解决方案不存在。
这是否意味着该是该投降并让所有人加入的时候了? 让我们考虑其他选项。 好吧,例如,您不能只允许那些可能与大量人打架的人。 如果某人可以与至少
k + 1的其他人打架,那么您绝对不能让他进入,否则您将不必让所有
k + 1的镇民与他打架,这肯定会破坏领导。
愿您根据这个原则尽一切可能。 然后其他所有人最多只能与
k人作战。 将
k个人丢掉,您最多只能阻止
冲突。 所以,如果全部超过
如果一个人至少参与了一次冲突,那么您当然无法阻止所有冲突。 当然,由于您一定要放任完全没有冲突的人员,因此您需要从200人中挑选出10个大小的所有子集。 大约有
,因此集群上已经可以整理出许多操作。
如果可以安全地采用完全不冲突的人格,那么那些只参与一次冲突的人该怎么办? 实际上,也可以通过在对手面前关闭门来让他们进入。 的确,如果爱丽丝只与鲍勃发生冲突,那么如果我们让两个人,爱丽丝,我们不会输:鲍勃可能还有其他冲突,但爱丽丝肯定没有。 此外,对我们而言,不要两者兼而有之。 经过这样的操作,不再
命运未定的客人:我们所拥有的
冲突,每个参与者有两个,并且每个参与者至少涉及两个。 因此,它仅是为了解决问题
选项,很可能在笔记本电脑上计算了半天。
实际上,简单的推理可以达到更有吸引力的条件。 请注意,我们绝对需要解决所有争端,即从每个冲突的对中选择至少一个我们不让其介入的人。 考虑以下算法:采取任何冲突,从中删除一个参与者,然后从其余参与者中递归开始,然后删除另一个参与者,然后递归开始。 由于我们在每一步都抛出某人,因此这种算法的递归树是深度为
k的二叉树,因此,总而言之,该算法适用于
其中
n是顶点数,
m是边数。 在我们的示例中,这大约是一千万,一秒钟之内,不仅在笔记本电脑上,甚至在手机上都将被计算在内。
上面的示例是
参数化算法的示例。 参数化算法是在
f(k)poly(n)期间工作的算法,其中
p是多项式,
f是任意可计算的函数,并且
k是某个参数,该参数很可能会比问题的大小小得多。
该算法之前的所有讨论都给出了
内核化的示例,
内核化是创建参数化算法的常用技术之一。 内核化是将任务的大小减小到受参数函数限制的值。 产生的任务通常称为内核。 因此,通过关于顶点度的简单推理,我们得到了顶点覆盖问题的二次核,并通过答案的大小对其进行了参数化。 可以为该任务选择其他参数(例如,“ LP上的顶点覆盖”),但是我们将仅讨论这样的参数。
步伐挑战
PACE挑战赛 (参数化算法和计算实验挑战赛)于2015年开始,目的是在参数化算法与实际用于解决计算问题的方法之间建立联系。 前三场比赛的重点是查找图的树宽(
Treewidth ),查找
Steiner树 (
Steiner Tree )并查找许多顶点,剪切循环(
Feedback Vertex Set )。 今年,可以尝试发挥自己优势的一项任务是上述顶盖问题。
竞争每年都在普及。 如果您相信初步数据,那么今年只有24个团队参加了比赛,以解决顶点覆盖问题。 值得注意的是,比赛不会持续几个小时,甚至不是一周,而是几个月。 团队有机会学习文学作品,提出他们的原始想法并尝试将其付诸实践。 实际上,这场比赛是一项研究工作。 在欧洲最大的算法年会
ALGO上,将与
IPEC (参数化和精确计算国际研讨会)会议一起,提出最有效的解决方案和获奖者的想法。 有关比赛本身的更多信息可以在
网站上找到,过去几年的结果在
这里 。
解决方案
为了解决顶点覆盖问题,我尝试应用参数化算法。 它们通常由两部分组成:简化规则(理想情况下会导致内核化)和拆分规则。 简化规则是多项式时间内的预处理输入。 应用此类规则的目的是将问题减少到较小的等效问题。 简化规则是算法中最昂贵的部分,而这一特定部分的应用导致了总的工作时间
而不是简单的多项式时间。 在我们的案例中,拆分规则基于以下事实:对于每个顶点,您都需要以其邻居为响应。
通用方案是这样的:我们应用简化规则,然后选择某个顶点,然后进行两次递归调用:首先,我们将其作为响应,而在另一个过程中,我们接受其所有邻居。 这就是我们所谓的沿峰分裂(分支)的过程。
在下一段中,将对该方案进行精确的添加。
分割规则的想法
让我们讨论如何选择沿其发生分裂的顶点。
在算法意义上,主要思想是非常贪婪的:让我们取最大度数的峰值并除以它。 为什么看起来这么好? 因为在递归调用的第二个分支中,我们将以这种方式删除许多顶点。 您可以预料会有一个小图,我们会尽快对其进行处理。
通过已经讨论过的简单的内核化技术,这种方法还不错,它可以解决一些具有数千个顶点的测试。 但是,例如,它不适用于三次图(即每个顶点的度为3的图)。
还有一个基于相当简单的想法的想法:如果图形断开连接,则可以通过组合最后的答案来独立解决其连接组件上的问题。 顺便说一下,这是对方案的小的修改,这将大大加快解决方案的速度:在这种情况下,我们之前的工作是计算组件响应次数的乘积,现在我们要计算数量。 为了加快早午餐,您需要将连接的图变成断开的图。
怎么做? 如果图中有一个关节点,则有必要沿着它徘徊。 铰接点是这样的一个顶点,当该顶点被删除时,图形将失去连接性。 在图中找到关节的所有点可以是线性时间的经典算法。 这种方法大大加快了早午餐。
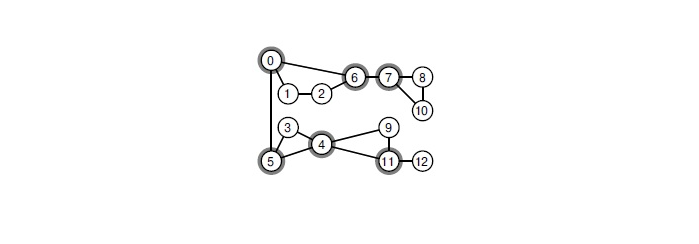
删除任何选定的顶点时,图形将分解为连接的组件。
我们会做的,但是我想要更多。 例如,在图形中查找较小的顶点部分,并沿其顶点分割。 我知道找到最小全局顶点截面的最有效方法是使用Gomori-Hu树,它是在立方时间内构建的。 在PACE挑战中,典型的图形大小为几千个顶点。 在这种情况下,需要在递归树的每个顶点执行数十亿次操作。 事实证明,根本不可能在规定的时间内解决问题。
让我们尝试优化解决方案。 可以通过构造最大流量的任何算法找到一对顶点之间的最小顶点部分。 您可以在这种网络上运行Dinitz
算法 ;在实践中,它的运行速度非常快。 我怀疑理论上有可能证明工作时间的估计
那已经可以接受了。
我尝试了几次,以寻找成对的随机顶点之间的割点,并从中选取最平衡的顶点。 不幸的是,在公开的PACE挑战测试中,结果很差。 我将其与沿着最大度数的顶点分散的算法进行了比较,并从对下降深度的限制开始。 在算法尝试以这种方式找到切点之后,剩下了更大的图。 这是由于事实证明,切割的结果非常不平衡:在除去5-10个峰之后,只有15-20个峰能够分开。
值得注意的是,理论上最快算法的文章使用了更高级的技术来选择顶点进行分割。 这样的技术实现起来非常复杂,并且时间和内存通常很差。 我无法将它们与实践完全接受。
如何应用简化规则
我们已经有了关于内核化的想法。 让我提醒您:
- 如果存在孤立的顶点,则将其删除。
- 如果存在一个度数为1的顶点,则将其删除并以其邻居作为响应。
- 如果存在一个至少为k + 1的度数顶点,则将其作为响应。
对于前两个,一切都很清楚,而对于第三个,则有一个窍门。 如果在漫画栏问题中我们从
k处受到限制,那么在PACE挑战中,您只需要找到最小尺寸的顶点覆盖即可。 这是典型的将搜索问题转换为决策问题的过程,通常在两种任务之间没有什么区别。 在实践中,如果我们编写顶点覆盖问题解决程序,则可能会有所不同。 例如,如第三段。
在实现方面,有两种方法可以执行此操作。 第一种方法称为迭代加深。 它包含以下内容:我们可以从下面对答案进行一些合理的限制,然后使用该限制作为对上面答案的限制,然后运行我们的算法,而递归不会低于此限制。 如果找到答案,则可以肯定它是最佳选择,否则您可以将该限制增加一个并重新开始。
另一种方法是存储一些当前的最佳答案,并寻找一个较小的答案,当找到该答案时,请更改此参数
k以在搜索中更多地切断多余的分支。
经过每晚的实验后,我确定了这两种方法的组合:首先,我对搜索深度进行某种限制的算法运行(选择算法以使其与主要解决方案相比花费的时间不多),并使用上面发现的最佳解决方案作为限制答案-即那个
k 。
2度顶点
用0和1度的顶点我们可以算出。 事实证明,这也可以使用2度的顶点来完成,但是为此,图形将需要更复杂的运算。
为了解释这一点,您需要以某种方式识别峰。 我们将阶数为2的顶点称为顶点
v ,将其相邻顶点称为
x和
y 。 然后我们将有两种情况。
- 当x和y是邻居时。 然后,您可以接收x和y的响应,并删除v 。 实际上,作为响应,必须从这个三角形中至少取两个顶点,并且如果我们取x和y ,我们当然不会丢失:它们可能有更多的邻居,但是v没有。
- 当x和y不是邻居时。 然后说明可以将所有三个顶点粘合在一起。 我们的想法是,在这种情况下,存在一个最佳答案,其中我们可以求出v或两个顶点x和y 。 此外,在第一种情况下,我们必须响应所有邻居x和y ,而在第二种情况下,则没有必要。 当我们不采取粘滞顶点作为响应时以及当我们采取它时,正是这种情况。 仅需注意的是,在两种情况下,此类操作的响应都会减少一。
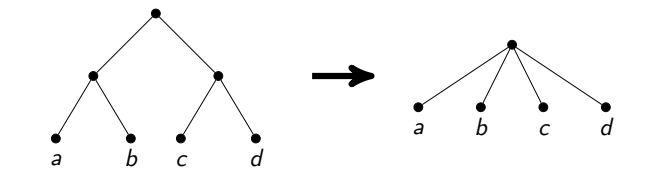
值得注意的是,这种诚实的线性时间方法很难准确实现。 粘贴顶点是一项困难的操作,您需要复制邻居列表。 如果不小心执行此操作,则可能会出现渐近的非最佳操作时间(例如,如果在每次粘合后复制很多边)。 我决定从2度的顶点搜索整个路径,并解析一堆特殊情况,例如来自这些顶点或除了一个顶点之外的所有这些顶点的循环。
另外,此操作必须是可逆的,以便在从递归返回期间,我们以原始形式恢复图形。 为了确保这一点,我没有清除合并顶点的边列表,之后我只知道应该将哪些边指向。 图形的这种实现也需要准确性,但是它提供了诚实的线性时间。 对于数以万计的边的图形,它完全适合处理器缓存,这在速度方面具有很大的优势。
线性芯
最后,是内核中最有趣的部分。
首先,回想一下在二部图中,可以寻求最小顶点覆盖率
。 为此,请使用
Hopcroft-Karp算法在此处查找最大匹配,然后使用
Koenig-Egerwari定理。
线性核的概念如下:首先,我们对图进行划分,即得到两个顶点而不是每个顶点
v 和
,而不是每个边
u-v,我们有两个边
和
。 结果图将是二分图。 我们在其中找到最小的顶点覆盖率。 原始图的某些顶点到达该顶点两次,某些仅到达一次,而某些顶点从未到达一次。 Nemhauser-Trotter定理指出,在这种情况下,可以删除未被单击一次的顶点并回答被两次单击的顶点。 而且,她说,在其余的峰中(一次击中的峰),您需要至少收回一半。
我们刚刚学会在图中保留不超过
2k个顶点。 确实,如果答案的其余部分至少是所有顶点的一半,则总顶点不超过
2k 。
在这里,我设法迈出了一步。 显然,以这种方式构造的内核取决于我们在二分图中采用的最小顶点覆盖类型。 我想使剩余顶点的数量最少。 以前,他们只知道如何及时做到。
。 我及时提出了该算法的实现
因此,可以在分支的每个阶段在成千上万个顶点的图上搜索此核心。
结果
实践表明,我的解决方案在测试数百个顶点和几千条边时效果很好。 通过这样的测试,可以期望在半小时内找到解决方案。 如果图形具有很多高度较大的顶点(例如10度及以上),则在可接受的时间段内找到答案的可能性原则上会增加。
要参加比赛,必须将决定发送到
optil.io 。 从那里展示的
盘子来看,我对开放测试的决定在二十位中排名第三,与第二位相比有很大的差距。 坦白说,目前尚不清楚在比赛本身如何评估决策:例如,我的决策通过的测试少于第四名,但是对于通过测试的决策则更快。
封闭测试的结果将于7月1日宣布。