
信任机器学习模型所做的预测的问题变得越来越重要。 基于此预测做出的决策越重要,则置信度越低。 这主要是由于以下事实:始终不清楚影响最终决定的因素是什么,训练模型的初始数据是否存在偏差,以及开发人员在计算参数时是否犯了错误。 在实践中不可能手动验证所有这些内容,因此对于管理人员而言,根本不实施AI常常会更容易。
但是,如果您使该过程自动化,该怎么办?
引入基于云的解决方案
Watson OpenScale ,它不仅使您能够控制模型的质量,而且还可以跟踪预测中偏差的存在,检测并消除其原因。
我们将告诉您它是什么以及在何处学习如何使用它。
偏见-一个隐藏的AI问题
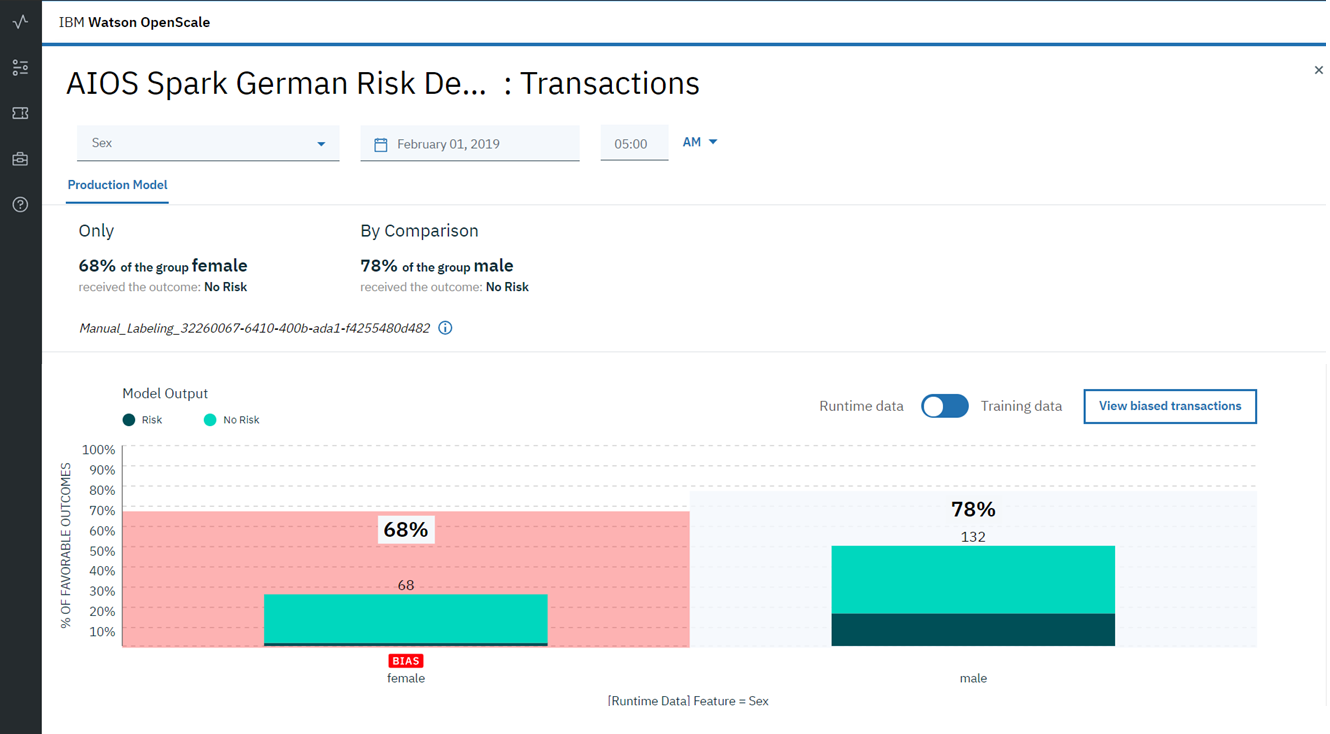
想象你正在看一场足球比赛,有人问你谁是2018年最好的球员。 你会怎么回答? 停下来思考一秒钟,然后再继续阅读...如果您是阿根廷的粉丝,则很可能会说“梅西”,如果您是葡萄牙的粉丝,您的答案将是“罗纳尔多”。 有人会说梅西是最好的,或者也许是Dziuba。 这些答案中的每一个(包括您脑海中出现的答案)都反映了每个回答此问题的人所固有的偏见。 这可能是由于玩家本人或整个团队的钦佩直接引起的,或者是由于对团队所代表的国家/地区的某种感觉。
在我们业务的几乎所有方面都可以发现有意识和无意识的偏见。 在决策(包括人工智能算法)方面,偏差可能会产生重大后果。 考虑一家使用AI识别欺诈活动的银行。 想象一下,开发此模型的人使用了一个数据集,其中所有欺诈性交易都是由某个性别,国籍或收入水平的人进行的。 然后,可以肯定地说,在这样的偏差数据下训练的模型将在其预测中考虑该偏差。 此外,由于描述此模型的指标(精度/召回率)将接近理想值(毕竟,验证是在同一数据集的子样本上进行的),因此员工很难检测到由于算法导致的偏差。 结果,即使度量标准具有出色的价值,这种模型也将非常糟糕,将其标记为欺诈行为,反之亦然,从而跳过真正危险的交易。 所有这一切都归因于训练模型的源数据中的偏差(bias)。
更大的问题可能是模型结果中存在偏差,而数据中没有任何偏差。 这可能是由于参数权重分布中的错误引起的,或者是由于模型的训练或进一步训练期间进行了非线性变换而导致的。 因此,非常重要的是,不仅要在数据预处理阶段发现偏差,而且还要在测试和产品使用过程中不断监控预测,以防止偏差出现在算法结果中。
由于这种问题,在许多公司所有者的眼中,AI
看起来都不
可靠 。
人工智能可以帮助改善人工智能吗?
IBM提供了
Watson OpenScale云解决方案,该解决方案可以连续监视模型性能和实时预测偏差。 它不仅可以检测出问题的发生,还可以找到问题发生的原因,并提供了有关如何更正初始数据的选项,以避免在预测中出现偏差。 IBM Watson OpenScale允许您连续监视模型的运行,并检查其是否存在偏差。
对于使用人工智能模型的公司来说,另一个大问题是模型的黑匣子性质。 企业主如何才能根据正确的数据来验证AI是否做出了正确的决定? 如何解释人工智能模型的“行为”? 对这些问题缺乏“简单”的答案是专家最近遇到的一个大问题。 IBM Watson OpenScale解决了该问题。 由模型做出的最终预测,IBM Watson OpenScale附带两个不同的解释,使您可以了解算法的行为。 因此,似乎有相当大的机会来提高管理人员之间的信任度,从而加速AI在业务中的实施。
那么Watson OpenScale到底是什么呢?
-IBM Cloud上可用的云服务在Lite帐户的框架内
免费使用
-监视和跟踪模型结果通过清晰便捷的图形界面,可测量模型的速度并跟踪结果以投影到业务目标中
-用于业务目的的调整模型模型的业务结果会不断工作以调整数据以改善机器学习模型的结果
 -模型的管理和解码
-模型的管理和解码通过跟踪和解释业务流程中的AI解决方案以及智能错误检测和纠正以改善结果来支持合规性。

是否要使用IBM Watson OpenScale测试偏差模型?
还是找出为什么她对特定数据做出此决定?
7月9日到莫斯科参加一个
免费的一日研习班 ,您可以:
- 熟悉神经网络训练和操作的原理和特征
- 使用提供的数据集和详细说明训练不同类型的神经网络
- 使用Watson OpenScale平台和IBM Adversarial Robustness Toolbox(IBM ART)开源库测试神经网络的操作
- 尝试AI功能以使用NeuNetS引擎快速创建神经网络模型
所有数据处理都在IBM云中进行-您只需要一台笔记本电脑和一个浏览器。 注册和详细信息-
单击此处 。