
这篇文章比关于业务的技术性更强,但是我们还将从业务的角度得出一些结论。 将最注意自动比较不同来源的商品。
在线商店的工作由相当多的组件组成。 无论计划是什么,立即赚钱,增长或寻找投资者,或者例如开发相关领域,至少您都必须解决以下问题:
- 与供应商合作。 要出售不必要的东西,您必须首先购买不必要的东西。
- 目录管理。 某人的专业领域狭窄,而某人则销售数十万种不同的商品。
- 零售价格管理。 在这里,您必须考虑供应商的价格,竞争对手的价格以及负担得起的金融工具。
- 与仓库合作。 原则上,可能没有自己的仓库,而是从合作伙伴的仓库取货,但问题是一种或另一种方式。
- 行销 在这里,网站充满了内容,网站放置,广告(在线和离线),促销等等。
- 订单的接收和处理。 呼叫中心,网站上的购物篮,通过即时Messenger进行的订单,通过平台和市场进行的订单。
- 交货。
- 会计和其他内部系统。
我们正在谈论的商店没有狭窄的专业领域,但是提供了从化妆品到迷你拖拉机的各种商品。 我将告诉您我们如何与供应商合作,监控竞争对手,目录管理和定价(批发和零售)以及与批发客户合作。 略谈仓库的话题。
为了更好地理解某些技术解决方案,知道
在某个时候,我们认为技术上的事情,如果可能的话,不是为自己而做,而是为普遍而做。 并且,也许,经过几次尝试,它会问世以发展新业务。 事实证明,这是公司内部的一家初创公司。
因此,我们正在考虑一个独立的系统,该系统或多或少是通用的,该系统与公司的其他基础架构集成在一起。
与供应商合作有什么问题?
实际上有很多。 只是给一些:
- 本身有很多供应商。 我们大约有400个。每个人都需要一些时间。
- 没有从供应商那里获取报价的唯一方法。 有人按计划发送到邮件,有人按请求发送,有人上载到文件托管,有人放在站点上。 通过Skype发送文件的方式有很多种。
- 没有单一的数据格式。 我什至在此主题上画了一幅画(它较低,表格代表不同的格式)。
- 为了继续与供应商合作,必须遵守最低零售和最低批发价格的概念。 通常,它们以自己的格式提供。
- 每个供应商的术语是不同的。 结果,同一产品的名称不同,并且没有唯一的密钥可以轻松比较它们。 因此,我们比较很难。
- 向供应商下订单的系统不是自动化的。 我们每天晚上从Skype上的某个人,您帐户中的某个人向某人下订单,并向我们发送一个包含订单列表的exel文件。

我们已经学会解决这些问题。 除后者外,有关后者的工作正在进行中。 现在将有技术细节,然后考虑以下列表。
收集资料
照原样
从各种来源手动收集并准备了供应商文件。 准备工作包括根据特定模板重命名和编辑内容。 根据文件的不同,有必要删除非标准商品,无库存商品,重命名列或转换货币,从一个页面的不同选项卡收集数据。
怎么了
首先,我们学会了检查邮件并从那里领取带有附件的信件。 然后,他们通过直接链接以及指向Yandex和Google驱动器的链接使工作自动化。 这解决了从大约75%的供应商处接收报价的问题。 我们还注意到,正是通过这些渠道,才可以更频繁地更新商品,从而使自动化的实际百分比更高。 我们仍然可以得到一些使者的价格。
其次,我们不再手动处理文件。 为此,我们输入了供应商资料,您可以在其中指定要使用的列和标签,如何确定货币和可用性,交货时间以及供应商的工作计划。
事实证明是灵活的。 自然,我们第一次并没有考虑所有因素,但是现在每个人都有不同的文件格式,因此可以灵活地配置所有400个提供程序的处理。
至于文件格式,我们了解xls,xlsx,csv,xml(yml)。 就我们而言,这就足够了。
他们还弄清楚了如何过滤记录。 我们列出了停用词,如果供应商的报价中包含停用词,则我们不会对其进行处理。 技术细节如下:在较小列表上,您甚至可以更好地“迎头赶上”;在较大列表上,您可以更快地使用Bloom过滤器。 我们对他进行了试验,并保留了所有内容,因为在列表中感觉到的增益要比我们大。
另一个重要的事情是供应商的工作时间表。 我们的供应商按照不同的时间表进行工作,此外,他们位于不同的国家/地区,周末的时间并不相同。 交货时间通常以工作日内的数字或数字范围表示。 当我们确定零售和批发价格时,我们将必须以某种方式评估将货物交付给客户的时间。 为此,我们创建了可配置的日历,在每个提供程序的设置中,您可以指定它可以处理哪个日历。
我必须根据类别和制造商来配置折扣和利润。 碰巧供应商对所有合作伙伴都有一个通用文件,但是与某些合作伙伴存在折扣协议。 因此,如有必要,仍然可以增加或减少增值税。
顺便说一下,折扣和加价规则的配置将我们引向下一个主题。 毕竟,在使用它们之前,您需要了解它是哪种产品。
映射如何工作
如何从不同的供应商处调用同一产品的一个小示例,以了解您必须使用的产品:
显示器LG LCD 22MP48D-P
21.5英寸LG 22MP48D-P黑色(16:9,1920x1080,IPS,60 Hz,DVI + D-Sub(VGA))
COMP-电脑外围设备-显示器LG 22MP48D-P
最高22“ LG Display Monitor LG 22MP48D-P(21.5”,黑色,IPS LED 5ms 16:9 DVI磨砂250cd 1920x1080 D-Sub FHD)22MP48D-P
显示器LG 22“ LG 22MP48D-P亮黑色(IPS,LED,1920x1080,5 ms,178°/ 178°,250 cd / m,100M:1,+ DVI)显示器
液晶显示器LG液晶显示器22“ IPS 22MP48D-P LG 22MP48D-P
LG Monitor 21.5“ LG 22MP48D-P gl.Black IPS,1920x1080,5ms,250 cd / m2,1000:1(Mega DCR),D-Sub,DVI-D(HDCP),vesa 22MP48D-P.ARUZ
LG Monitor LG 22MP48D-P黑色22MP48D-P.ARUZ
显示器LG 22MP48D-P 22MP48D-P
显示器LG 22MP48D-P亮黑色22MP48D-P
显示器21.5英寸LG Flatron 22MP48D-P gl.Black(IPS,1920x1080,16:9,178/178,250cd / m2,1000:1,5ms,D-Sub,DVI-D)(22MP48D-P)22MP48D-P
显示器22英寸LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21.5“ 22MP48D-P IPS LED,1920x1080,5ms,250cd / m2,5Mln:1,178°/ 178°,D-Sub,DVI,倾斜,VESA,亮黑色22MP48D-P
LG 21.5“ 22MP48D-P(16:9,IPS,VGA,DVI)22MP48D-P
显示器21.5''LG 22MP48D-P黑色
LG MONITOR 21.5“ LG 22MP48D-P亮黑色(IPS,LED,1920x1080,5 ms,178°/ 178°,250 cd / m,100M:1,+ DVI)22MP48D-P
LG LCD显示器21.5英寸[16:9] 1920x1080(FHD)IPS,非玻璃,250cd / m2,H178°/ V178°,1000:1,16.7M彩色,5ms,VGA,DVI,倾斜,2Y,黑色OK 22MP48D -P
LCD LG 21.5“ 22MP48D-P黑色{IPS LED 1920x1080 5ms 16:9 250cd 178°/ 178°DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitors LG LG 22“ LCD 22MP48D 22MP48D-P
21.5“ 16x9 LG Monitor LG 21.5” 22MP48D-P黑色IPS LED 5ms 16:9 DVI磨砂250cd 1920x1080 D-Sub FHD 2.7kg 22MP48D-P.ARUZ
显示器21.5英寸LG 22MP48D-P [黑色]; 5毫秒; 1920x1080,DVI,IPS
照原样
比较涉及1C(第三方付费模块)。 至于便利性/速度/准确性,这样的系统使得维护一个目录成为可能,该目录包含6个级别的6万种产品。 也就是说,每天,供应商的报价已经过时或消失,创造了与新货一样多的匹配货。 非常接近-目录大小的0.5%,即 300个产品。
演变方式:方法的一般说明
稍微高一点,我举了一个我们需要匹配的示例。 在探讨匹配主题时,我对ElasticSearch在匹配任务中很流行感到惊讶,我认为它具有概念上的局限性。 对于我们的技术堆栈,我们使用MS SQL Server进行数据存储,但是比较是在我们自己的基础结构上进行的,并且由于有大量数据并且我们需要快速处理它,因此我们使用针对特定任务优化的数据结构,并尝试在不需要时不访问磁盘或数据库和其他慢速系统。
显然,比较问题可以通过多种方式解决,并且显然,它们都不能提供绝对的准确性。 因此,主要思想是尝试组合这些方法,将它们按精度和速度进行排序,并在考虑速度的情况下按精度从高到低的顺序进行应用。
我们每个算法的执行计划(保留关于简并案例的计划)可以由以下一般顺序简要表示:
代币化 我们将源代码分成有意义的独立部分。 它可以完成一次,然后在所有算法中进一步使用。
令牌标准化。 以一种很好的方式,您需要将自然语言的单词带到一般的数字和尾数,并将诸如“ ABC15MX”(如果有的话,这是西里尔字母)的标识符转换为拉丁文。 并将所有内容都放入同一寄存器。
令牌分类。 试图了解每个部分的含义。 例如,您可以选择类别,制造商,颜色等。
搜索匹配的最佳人选。
原始线和最佳候选者确实指示相同乘积的可能性的估计。
对于当前可用的所有算法,前两点是通用的,然后即兴创作。
代币化 在这里,我们只是按照空格,斜杠等特殊字符将行分成几部分。 事实证明,随着时间的流逝,字符集非常重要,但是我们并未在算法本身中使用任何复杂的东西。
然后,我们需要标准化令牌。 将它们转换为小写。 我们没有将所有内容引向主格,而是简单地切断了结尾。 我们还有一本小词典,并将令牌翻译成英文。 除其他外,翻译使我们免于同义词的侵害,其含义相似,俄语单词也以相同的方式翻译成英语。 无法翻译的地方,我们将拼写形式的西里尔字母改为拉丁字母。 (事实证明,这根本不是多余的。即使您不希望有任何肮脏的花样,例如,在“ SamsungU43NU7100U”生产线中,西里尔E也可以满足要求。)

令牌分类。 我们可以突出显示类别,制造商,型号,商品,EAN,颜色。 我们有一个目录,在目录中构造了数据。 我们拥有交易平台提供给我们的竞争对手的数据。 在处理它们时,我们将尽可能地构建数据。 我们可以纠正所有来源中仅发生一次的错误或错字(例如制造商或颜色),而不必分别考虑制造商和颜色。 结果,我们有了一个可能的制造商,型号,商品,颜色和标记分类的大词典,而这仅仅是对O(1)的词典搜索。 从理论上讲,您可以有一个开放的类别列表和某种智能分类算法,但是我们的基本方法效果很好,分类不是瓶颈。
应该注意的是,有时供应商会提供已经结构化的数据,例如,商品位于表格中的单独单元格中,或者供应商在批发销售时为零售打折,并且零售价可以yml(xml)格式获得。 然后,我们保存数据结构,并启发式地将令牌仅从非结构化数据中划分为类别。
现在介绍一下我们使用什么算法和使用什么顺序。
完全匹配和几乎完全匹配
最简单的情况。 行被划分为令牌,它们将它们引导为一种形式。 然后,他们提出了一个对令牌顺序不敏感的哈希函数。 此外,通过散列匹配,我们可以将所有数据保留在内存中,我们可以为每个字典提供16兆字节的数据,并具有一百万个键。 实际上,该算法的性能优于简单的字符串比较。
至于散列,建议使用“ exclusive or”本身,并提供如下功能:
public static long GetLongHashCode(IEnumerable<string> tokens) { long hash = 0; foreach (var token in tokens.Distinct()) { hash ^= GetLongHashCode(token); } return hash; }
在这个阶段最有趣的事情是得到一行的哈希值。 实际上,事实证明32位很小,获得了很多冲突。 而且-您不仅可以从框架中获取函数的源代码并更改返回值的类型,各行的冲突更少,但是在“排他或”之后仍然发生,因此我们编写了自己的冲突。 实际上,它们只是从输入数据的非线性框架中添加到函数中。 绝对好些了,有了新功能的碰撞,我们在数百万条记录上只见过一次,记录下来并推迟到更好的时候。
因此,我们在寻找匹配项时不考虑单词顺序及其形式。 这样的搜索适用于O(1)。
不幸的是,很少见,但也发生了:“ ABC 42 Type 16”和“ ABC 16 Type 42”,这是两种不同的产品。 我们还学会了处理此类问题,但以后会更多。
匹配人类确认的产品
我们提供了手动匹配的产品(大多数情况下,这些产品是自动匹配的产品,但是已经过手动检查)。 实际上,在这种情况下,我们正在做相同的事情,只是现在我们添加了匹配哈希表的字典,对其进行搜索并没有改变算法的时间复杂度。
手动匹配的行仅位于数据库中,以防万一,以防此类原始数据使您将来可以更改哈希算法,重新计算所有内容且不丢失任何内容。
属性映射
前两种算法快速准确,但还不够。 接下来,我们应用属性匹配。
以前,我们已经以规范化令牌的形式展示了数据,甚至将它们分类。 在本章中,我称呼令牌类别属性。
最可靠的属性是EAN(https://ru.wikipedia.org/wiki/European_Article_Number)。 EAN匹配为您几乎100%保证它们是同一产品。 但是,EAN不匹配没有说明什么,因为一种产品可能具有不同的EAN。 一切都会好起来的,但在我们的数据中,EAN是很少见的,因此它在误差级别对比较的影响。
该文章不太可靠。 通常会直接从供应商的结构化数据中获得一些奇怪的东西,但是无论如何在此阶段我们都使用它。
与最后阶段一样,这里我们使用字典(搜索O(1)),并将(制造商+模型+文章)的哈希值用作键。 散列允许您执行内存中的所有操作。 在这种情况下,我们还考虑了颜色,如果颜色匹配或不存在,则我们认为商品是相符的。
搜索最匹配的
先前的步骤简单,快速且相当可靠,但不幸的是,它们仅涵盖了不到一半的比较。
在寻找最佳匹配时,有一个简单的想法:稀有标记的重合度较大,频繁标记的重合度较小。 包含数字的令牌的价值大于字母令牌。 以相同顺序匹配的令牌的价值要大于重新排列的令牌。 长比赛比短比赛更好。
现在,仍然需要提出一种快速的数据结构,该结构可以同时考虑所有这些因素,并适合数百万条记录的目录的内存。
我们想出了以字典字典的形式呈现目录的想法,在第一层,键将是制造商的哈希(目录中的数据是结构化的,我们知道制造商),值是字典。 现在是第二级。 第二级的密钥将是令牌中的哈希,值是找到该令牌的目录中id项目的列表。 在这种情况下,我们使用标记组合的出现顺序,包括它们在目录中出现的顺序。 我们根据令牌的数量,令牌的长度等来决定使用哪种组合,而不使用哪种组合,这是速度,准确性和所需内存之间的折衷。 在图中,我简化了此结构,没有哈希并且没有规范化。
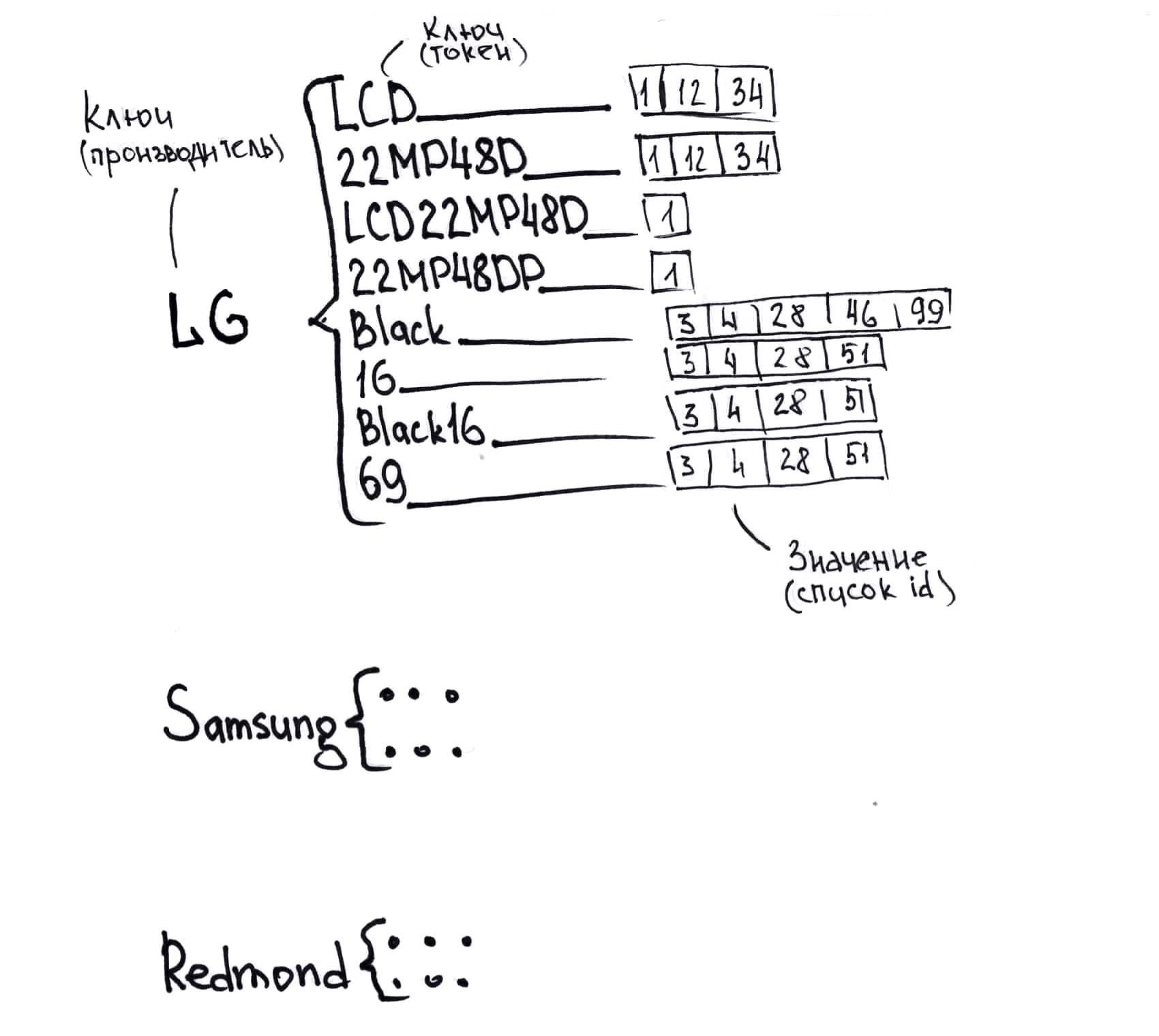
如果每个产品平均使用20个令牌,则在我们的列表中(具有附带的词典的值),平均到该产品的链接将出现20次。 代币的数量最多不超过目录中商品的20倍。 大约可以计算出一百万条记录的目录所需的内存:2000万个键,每个记录4个字节,2000万个产品ID,每个4个字节,组织字典和列表的开销(顺序是相同的,但是由于列表和字典的大小我们事先不知道,但要增加,再乘以2)。 总计-480 MB。 实际上,事实证明,商品令牌要多一些,在一百万种商品中,每个目录需要多达800兆字节。 可以接受的是,现代熨斗的功能允许您同时在内存中存储一百多个这种大小的目录。
回到算法。 有了需要匹配的字符串,我们可以确定制造商(我们有一个分类算法),然后使用与商品目录中的商品相同的算法获取令牌。 我的意思是包括令牌的组合。
然后,一切都相对简单。 对于每个令牌,我们可以快速找到找到它的所有产品,并考虑到我们之前谈到的所有内容(长度,频率,数字或特殊字符的存在),估算每次比赛的权重,并评估找到的所有候选者的“相似性”。 实际上,这里也有优化,我们没有考虑所有候选者,首先我们创建了一个权重较大的代币匹配的小列表,并且我们不将权重低的代币匹配应用于所有产品,而仅应用于此列表。
我们选择最佳匹配,查看被分类的标记的重合,并考虑比较分数。 此外,我们有两个阈值P1和P2,P1 <P2。 如果评估结果大于阈值P2-不需要人工参与,则一切都会自动进行。 如果介于两个值之间-我们提供手动查看比较的功能,在此之前,它将不参与定价。 如果小于P1(最有可能是此类产品不在目录中),我们将不退货。
返回到“ ABC 42 Type 16”和“ ABC 16 Type 42”行。 解决方案非常简单-如果多个产品具有相同的哈希值,则我们不会通过哈希将它们匹配。 最后一种算法将考虑令牌的顺序。 从理论上讲,供应商价格表中的此类行不能与任意数字匹配,其中数字16和42根本不会出现。 实际上,我们没有遇到这样的需求。
速度和准确性
现在为所有的速度。 线性准备词典所需的时间取决于目录的大小。 直接比较所需的时间线性地取决于要比较的商品数量。 创建后不会更改搜索中涉及的所有数据结构。 这使我们有机会在匹配阶段使用多线程。 一百万条记录的目录的准备工作大约需要40-80秒。 比较的速度为每秒20到4万条记录,并且与目录的大小无关。 但是,然后,您需要保存结果。 通常,选择的方法对于大容量而言是有益的,但是具有十几个记录的文件将不成比例地变长。 因此,我们使用缓存并每15分钟重新计算一次搜索结构。
的确,用于比较的数据需要在某个地方读取(大多数情况下这是一个excel文件),并且匹配的句子需要保存在某个地方,这也需要时间。 因此,总数为每秒2-4千条记录。
为了评估准确性,我们准备了一个大约20,000个不同类别的不同供应商的手动验证比较的测试套件。 每次更改后,都会对该数据进行算法测试。 结果如下:
- 商品已在目录中并进行了正确比较-84%
- 产品已在目录中,但尚未匹配,需要手动匹配-16%
- 货物在目录中并且被错误比较-0.2%
- 该产品不在目录中,并且程序正确识别出该产品-98.5%
- 该产品不在目录中,但程序将其与其中一种产品匹配-1.5%
在80%的情况下,如果匹配了产品,则无需手动确认(我们会自动确认比较结果),其中自动确认的报价中有0.1%的错误。
事实证明,0.1%的错误很多。 对于匹配的一百万条记录,这是一千个错误匹配的记录。 这是很多原因,因为买家最好找到这样的记录。 好吧,如何不从这辆拖拉机的大灯价格订购拖拉机。 但是,这上千个错误是针对一百万个提案的工作开始时,便逐渐得到纠正。 结束了这个问题的可疑价格检疫工作后来出现了,这是我们工作的头几个月。
还有另一类与比较无关的错误;这些是我们供应商的错误价格。 这就是为什么我们没有在比较中考虑价格的部分原因。 我们决定,由于我们拥有价格形式的其他信息,因此我们将使用它来尝试确定我们自己的错误,以及其他错误。
寻找错误的价格
这是我们正在积极尝试的部分。 基本版本是,并且它不允许您以外壳的价格出售手机,但是我觉得它更好。
对于每种产品,我们找到可接受的供应商价格的界限。 根据可用的数据,我们会考虑此产品的供应商价格,竞争对手的价格,此制造商的产品供应商的价格。 那些不在边界范围内的价格在我们所有的算法中均被隔离并忽略。 您可以手动将此类可疑价格标记为正常价格,然后我们会记住此产品的价格并重新计算可接受价格的范围。
现在,用于计算可接受的最大和最小价格的直接算法一直在变化,我们正在寻找误报数量与检测到的不正确价格数量之间的折衷方案。
我们在计算中使用中值(平均值给出最差的结果),并且尚未分析分布形式。 在我看来,对分布形式的分析只是可以改进算法的地方。
使用数据库
从以上所有内容,我们可以得出结论,我们经常以许多方式更新供应商和竞争对手的数据,并且使用数据库可能会成为瓶颈。 原则上,我们最初提请注意这一点,并试图实现最佳性能。 当处理大量记录时,我们将执行以下操作:
- 我们从工作表中删除索引
- 在此表上禁用全文本索引
- 删除具有特定条件的所有记录(例如,我们当前正在处理的特定供应商的所有报价)
- 使用BULK COPY插入新记录
- 重新创建索引
- 启用全文索引
批量复制以每秒10到4万条记录的速度运行,为什么还有这么大的传播量还有待观察,但它是可以接受的。
删除记录大约需要与插入相同的时间。 仍然需要一些时间来重新创建索引。
顺便说一下,对于每个目录,我们都有一个单独的数据库。 我们即时创建它们。 现在,我将告诉您为什么我们有多个目录。
编目有什么问题
而且也有很多。 现在我们将列出:
- 该目录包含约40万种完全不同类别的产品。 专业地理解每个类别是不可能的。
- 您需要遵循某种风格,遵循目录名称,命名子类别等的一般规则。 因此,我们试图实现一个连贯的逻辑目录结构。
- 您可以多次创建相同的产品,这是一个问题。 如果没有分析相似名称的工具,就会不断创建重复项。
- 将供应商库存的那些商品添加到目录中是合理的。 在这种情况下,您需要具有产品类别的优先级。
- 我们需要几个目录。 我们自己的一个,我们自己进行,另一个-聚合器目录,我们通过api更新。 第二个目录的含义是,聚合器平台仅适用于其自己的目录,因此接受其命名法中的报价。 这是另一个需要比较的地方。
我们认为将目录保存在进行比较的同一位置是合乎逻辑的,也是正确的。 因此,我们可以告诉管理目录的用户供应商拥有什么,但不在目录中。
我们如何保存目录
这将是关于没有详细特征的目录,特征是另外一个大故事。
作为基本属性,我们选择了以下内容:
首先,我们制作了api以从外部来源获取目录,然后我们致力于创建,编辑和删除记录的便利。
搜索的工作方式
首先,管理目录的便利之处在于可以在目录或供应商的报价中快速找到产品的能力,并且存在细微差别。 例如,您需要能够搜索“ LG 21.5”行22MP48D-P(16:9,IPS,VGA,DVI)22MP48D-P的“ 2MP48”。
开箱即用的全文sql服务器搜索是不合适的,因为它不知道该怎么做,并且使用LIKE'%2MP48%'进行搜索太慢。
我们的解决方案是相当标准的,我们使用N-gram。 更准确地说,然后是三字母组。 通过三字母组合,我们已经建立了全文索引并执行了全文搜索。 在这种情况下,我不确定我们是否会非常合理地使用空间,但是就速度而言,根据要求,此解决方案的工作时间为50到500毫秒,有时在300万条记录中可以达到一秒。
让我解释一下,“ LG 21.5”行22MP48D-P(16:9,IPS,VGA,DVI)22MP48D-P转换为“ lg2 g21 215 152 522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad adv dvi vi2 i22”,存储在参与全文索引的单独字段中。
顺便说一句,trigram对我们仍然有用。
创建一个新产品
在大多数情况下,目录中的产品是根据供应商的建议创建的。 也就是说,我们已经掌握了供应商提供的“ LG LCD Monitor 21.5” [16:9] 1920x1080(FHD)IPS,nonGLARE,250cd / m2,H178°/ V178°,1000:1、16.7M彩色, “ 5ms,VGA,DVI,倾斜,2Y,Black OK 22MP48D-P”的价格为120美元,他有5到10个单位的库存。
在创建产品时,首先,我们需要确保尚未在目录中创建此类产品。 我们分四个阶段解决这个问题。
首先,如果我们在目录中有产品,那么供应商的投标很有可能会自动与此产品匹配。
其次,在向用户显示用于创建新产品的表单之前,我们将通过三字母进行搜索并显示最相关的结果。 (从技术上讲,这是使用CONTAINSTABLE完成的)。
第三,当我们填写新产品的字段时,我们将展示类似的现有产品。 这解决了两个问题:有助于避免重复并保持名称中的样式,可以将类似产品用作模型。
第四,还记得吗,我们将行划分为令牌,将其归一化,算作哈希? 我们将做同样的事情,只是不会让商品具有相同的哈希值。
在这个阶段,我们尝试为用户提供帮助。 通过价格表中的行,我们将尝试确定商品的制造商,类别,商品,EAN和颜色。 首先,通过令牌(我们可以将它们划分为类别),然后,如果无法解决问题,我们将通过三字母组合找到最相似的产品。 并且,如果足够相似,请填写制造商和类别。
产品编辑的工作原理几乎相同,只是并非所有内容都适用。
我们如何设定价格
任务是这样的:实际上,要在数量和销售利润之间保持平衡,以实现最大的利润。 商店工作的所有其他方面也与此相关,但是在定价阶段发生的事情影响最大。
至少,我们将需要有关供应商和竞争对手的报价信息。 还值得考虑最低的零售和批发价格和交付成本,以及金融工具-贷款和分期付款。
我们收集竞争对手的价格
首先,我们有许多我们自己价格的资料。 有一个零售配置文件,有几个供批发客户使用。 所有这些都在我们的系统中创建和配置。
因此,每个配置文件的竞争者都不同。 在零售-其他零售商店,在批发销售-我们相同的供应商。
供应商的一切都清晰明了,但是对于零售业,我们以多种方式收集竞争对手的数据。 首先,一些聚合器提供了有关该站点上所有商品的所有价格的信息。 以我们自己的命名法,但是我们可以匹配产品,因此它可以自动运行。 到目前为止,这几乎足够。 其次,我们有竞争对手解析器。 由于它们尚未实现自动化,并且以控制台应用程序的形式存在(有时会崩溃),因此我们很少使用它们。
自定义您的个人资料
在配置文件中,我们有机会根据供应商,类别,制造商,供应商的商品价格配置不同的利润范围。
仍然可以指出我们与哪个供应商合作的类别或制造商,而不是与我们考虑的竞争对手。然后,我们建立金融工具,指出可用的分期付款以及银行将自己承担的费用。并且已经在边际利润之内,我们形成了自己的价格,首先试图保持相同的平衡,然后使我们的仓库商品卖得更好。简而言之,但实际上我不希望用简单的词来解释那里发生了什么。我可以告诉你没有发生什么。不幸的是,我们尚不知道如何预测需求并考虑将货物存储在仓库中的成本。与第三方系统集成
从业务角度来看很重要,但从技术角度来看却很有趣。简而言之,我可以说我们可以将数据发送到第三方系统(包括增量系统,也就是说,我们了解自上次交换以来发生了什么变化),并且可以进行邮件列表。时事通讯是可定制的,因此(不仅限于此)我们向批发客户提供报价。与批发客户合作的另一种方法是b2b门户。它仍处于积极的开发中,它将在一个月内立即生效。帐户,更改记录
从技术的角度来看,另一个有趣的问题。每个用户都有一个帐户。简而言之,可以说以下几点:如果使用ORM,则它具有内置的更改跟踪机制。如果您了解它(在我们的例子中是EF Core,甚至那里有一个API),那么您几乎可以登录两行。对于更改历史记录,我们创建了一个界面,现在您可以跟踪谁更改了系统设置中的内容,编辑或比较了某些产品的人员,等等。根据日志,可以考虑进行统计。我们知道谁创建或编辑了多少产品,手动确认了多少比较以及拒绝了多少,您可以看到每个更改。关于系统的一般结构
我们有一个用于帐户和与目录无关的事物的数据库,一个用于日志的数据库,以及每个目录的数据库。这使目录查询更容易,数据分析也更容易,并且代码更易于理解。顺便说一下,日志记录系统是自写的,我们确实需要对与一个请求或一项繁重任务相关的日志进行分组,此外,我们还需要用于分析它们的基本功能。使用“交钥匙”解决方案,这变得很困难,此外,这是另一个需要支持的依赖项。Web界面在ASP.NET Core和引导程序上进行,并且繁重的操作由Windows服务执行。我认为,使项目受益的另一个功能是用于读取和写入数据的不同模型。我们没有实现成熟的CQRS,但是我们从那里采用了其中一个概念。我们通过存储库写入数据库,但是用于记录的对象永远不会离开update / create / delete方法。批量更新是通过批量复制完成的。为了读取而创建了单独的模型和单独的数据访问层,因此我们仅在特定时刻读取需要的内容。事实证明,您可以使用ORM,同时避免繁重的查询,并在不确定的时间(例如延迟加载),N + 1问题访问数据库,并且我们还使用该模型作为DTO进行读取。在主要依赖项中,我们有ASP.NET Core,几个第三方nuget程序包和MS SQL Server。尽管有可能,但我们尝试不依赖许多第三方系统。为了在本地完全部署项目,只需安装SQL Server,从版本控制系统中获取源代码并构建项目。必要的数据库将自动创建,但是不需要其他任何东西。您可能必须在配置中更改一两行。没有什么
我们尚未建立项目知识系统。我们想就地制作维基和技巧。他们没有创建一个简单的直观界面,这个界面还不错,但是对于一个没有准备的人来说有点令人困惑。到目前为止,CI / CD仅在计划中。没有处理商品的详细特征。我们也计划,但没有具体的截止日期。
业务概要
从开始积极开发到投入生产,两个人在该项目上工作了7个月。开始时,我们在空闲时间制作了一个原型。对现有系统的集成最困难。在我们投入生产的三个月中,可供批发客户使用的商品数量已从7万增加到23万,现场的商品数量也从6万增加到14万。该网站总是很晚,因为它需要功能,图片和产品说明。我们在汇总器上卸载了106,000个报价,而不是三个月前的4万个。使用目录的人数没有改变。我们与425个供应商合作,这个数字在三个月内几乎翻了一番。我们跟踪一千多个竞争对手的价格。好吧,我们跟踪它-我们有一个解析系统,但是在大多数情况下,我们从定期提供数据的人员那里获取现成的数据。不幸的是,我无法告诉您销售情况,我自己没有可靠的数据。需求是季节性的,因此不可能直接将月份与上个月进行比较。一年中发生了太多事情,无法从所有因素凸显我们的系统的影响。非常非常有条件的,正负一公里的目录增长,更灵活和更具竞争力的价格以及相关的销售增长已经为开发和实施付出了代价。另一个结果-我们得到了一个与特定商店的基础设施基本无关的项目,您可以从中进行公共服务。它从一开始就构想出来,并且这个计划几乎奏效。不幸的是,盒装解决方案失败了。要提供可注册的服务项目,请选中“我同意”框,该框按“原样”运行,而无需适应客户,您需要重新设计界面,增加灵活性并创建一个Wiki。并使基础架构易于扩展并消除单点故障。现在,我们只能通过确保可靠性的方式进行定期备份。作为企业解决方案,我认为我们已经准备好解决业务问题。小型企业就是找到企业。顺便说一下,我们已经吸引了一个具有最基本功能的第三方客户端。伙计们需要一个比较商品的工具,而积极发展带来的不便并没有吓到他们。