许多使用Spark ML的人都知道,他们在那里做的某些事情“并不完全成功”。
或根本不做。 Spark开发人员的立场是 SparkML是基础平台,并且所有扩展都必须是单独的程序包。 但这并不总是很方便,因为数据科学家和分析人员希望使用熟悉的工具(Jupter,Zeppelin)进行工作,而这正是大多数需要的工具。 他们不想使用maven-assembly来收集500兆字节的JAR文件,也不希望自己下载依赖项并将其添加到Spark启动参数中。 精通JVM项目构建系统的工作可能需要习惯于Jupyter / Zeppelin的分析师和DataScientists付出更多的努力。 让DevOps和集群管理员在计算节点上放置一堆软件包显然是一个坏主意。 自己编写SparkML扩展的任何人都知道重要的类和方法(出于某种原因是私有[ml]),对存储的参数类型的限制等有多少隐藏的困难。
现在看来,有了MMLSpark库,生活会更轻松一些,并且使用SparkML和Scala进入可伸缩机器学习的门槛会略低。
引言
由于许多困难,以及SparkML中稀疏的现成方法和解决方案集,许多公司为Spark编写了扩展。 一个例子是PravdaML ,它是由Odnoklassniki开发的,通过对GitHub上内容的快速评估来判断,它看起来非常有前途。 不幸的是,这些解决方案中的大多数通常都是封闭的或开放的,但是无法通过Maven / sbt和API文档进行安装,这使得使用它们非常困难。
今天,我们来看一下MMLSpark库。
我们将像往常一样考虑对泰坦尼克号旅客进行分类的任务示例。 目标是显示MMLSpark库的尽可能多的功能,而不是 在ImageNet上删除SOTA 显示很酷的机器学习。 所以泰坦尼克号会做到的。

该库本身具有用于Scala的本机API( 文档 ),Python API( 文档 ),并且从GitHub存储库中的某些位置来看,它很快将具有R的API。
GitHub项目(PySpark + Jupyter)中有很好的示例笔记本电脑 ,但我们会走另一条路。 正如Dmitry Bugaychenko 所写的那样 ,如果您为Spark进行开发,也就是说,您有充分的理由为此使用Scala,那么Scala允许您更有效,更灵活地定义自己的Transformer和Estimator,将它们嵌入到SparkML Pipeline中,但是numpy的工作速度却很慢UDF中的/ pandas代码(从JVM调用可执行文件)已经编写了很多。
安装简介
整个笔记本电脑在这里可用。 要与泰坦尼克号一起使用,在默认设置下在笔记本电脑上本地运行的Zeppelin Docker镜像就足够了。 Docker可以在这里找到。 MMLSpark库不在Maven Central中,而是在Spark软件包中,并且要将其添加到Zeppelin中,必须在便携式计算机的开头运行以下代码块:
%spark.dep z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/") z.load("Azure:mmlspark:0.17")
值得一提的是,该库具有出色的向后兼容性:例如,与XGBoost4j-spark不同,它至少需要Spark 2.3以上版本,而Zeppelin Docker映像附带的Spark 2.2.1中存在此问题,并且存在任何困难我没有注意到。
注意:大部分MMLSpark库专用于推断群集上的网格,而该群集上存在CNTK(根据文档判断,应读取现成的cntk模型)和巨大的OpenCV块。 当我们有大量的表格数据以.csv,表格或其他格式存在于HDFS中时,我们将专注于更普通的任务,并尝试“建模”这种情况。 因此,我们需要对其进行预处理并建立模型,而这些数据无法放入一台计算机的内存中。 因此,我们将在集群上执行所有操作。
阅读与智力分析
通常,Spark + Zeppelin一点也不差,可以应付EDA任务,但我们将尝试扩展其功能。 首先,我们导入所需的类:
import com.microsoft.ml.spark.SummarizeData import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._
我们读取了文件:
val titanicSchema = StructType( StructField("Passanger", ShortType) :: StructField("Survived", ShortType) :: StructField("PClass", ShortType) :: StructField("Name", StringType) :: StructField("Sex", StringType) :: StructField("Age", ShortType) :: StructField("SibSp", ShortType) :: StructField("Parch", ShortType) :: StructField("Ticket", StringType) :: StructField("Fare", FloatType) :: StructField("Cabin", StringType) :: StructField("Embarked", StringType) :: Nil ) val train = spark .read .schema(titanicSchema) .option("header", true) .csv("/mountV/titanic/train.csv")
现在,让我们看一下数据本身及其大小:
println(s"Train shape is: ${train.count} x ${train.columns.length}") train.limit(5).createOrReplaceTempView("trainHead")
注意:当您只需编写.show(5)时,实际上并不需要使用createOrReplaceTempView。 但是show有一个问题:当数据为“宽”时,板的文本表示形式为“浮动”,而所有内容都变得不清楚。
获取我们的数据大小: Train shape is: 891 x 12
现在在sql单元格中,我们可以查看前5行:
%sql select * from trainHead
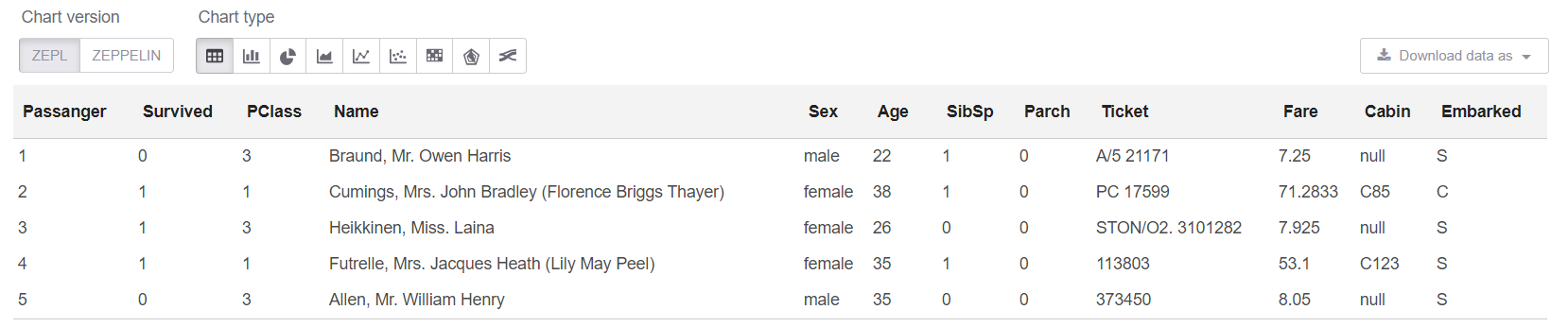
好吧,让我们在表上查看“摘要”:
new SummarizeData() .setBasic(true) .setCounts(true) .setPercentiles(false) .setSample(true) .setErrorThreshold(0.25) .transform(train) .createOrReplaceTempView("summary")
与简单的Dataset.describe相比,SummarizeData类具有多个优点,因为它使您可以计算缺失值和唯一值的数量,还可以指定计算分位数的准确性。 这对于真正的大数据可能至关重要。

一些个人想法通常,在我个人看来,PravdaML中的Odnoklassniki具有更好的SummarizeData模拟实现。 微软采用了简单的方法,并使用org.apache.spark.sql.functions ,只是将所有内容方便地包装在一个类中。 对于Odnoklassniki,这是通过其VectorStatCollector实现的,调用时需要一些更复杂的代码(必须首先将所有功能添加到向量中),并且可能需要其他操作(例如, VectorAssembler通常拒绝摘要DecimalType )。 但是基于我的Spark经验,我假设来自MMLSpark的SummarizeData可能会崩溃,并出现诸如org.apache.spark.sql.catalyst StackOverflow错误,如果确实存在很多列,并且计算图在启动时会变得不小(尽管专门针对Spark 2.4中的“极速”这类粉丝,但他们增加了缩减Catalyst图形优化器的功能。 好吧,似乎列的数量非常多,Microsoft的版本会更慢。 但这当然必须单独检查。
数据清理
在《泰坦尼克号》中,一切照常-一串字符串列缺少值。 以及数据中的某种倾斜(似乎该数据的特定版本不是很特定)-缺少值起25行。 首先,解决此问题:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))
字符串数据处理
据我所知,从“ Name和“ Cabin字段中带出的属性是泰坦尼克号中最好的属性。 您可以提供很多东西,但是为了避免给出几乎相同的代码示例,我们将自己限制为几个。
通常,将正则表达式用于此类情况很方便。
但是在这种情况下,我们想要:
- 一切都已分发,数据在原处处理;
- 一切都被设计为SpakrML Transformer或Spark ML Estimator类,以便以后可以在Pipeline中进行组装。
注意:管道首先确保我们始终对火车和测试应用相同的变换,并且还允许我们在交叉验证中捕获“展望未来”的错误。 而且,它还为我们提供了使用管道进行保存,加载和预测的简单功能。
SparkML对于此类任务有一个“几乎通用的”类-SQLTranformer ,但是用SQL编写显然比用Scala编写更糟糕,这仅是因为能够在Idea的编译和语法突出显示阶段捕获语法或典型错误。 MMLSpark在这里为我们提供了帮助,在其中实现了真正通用的UDFTransformer :
import com.microsoft.ml.spark.UDFTransformer
首先,我们将创建非常简单的转换函数,但是我们现在的目标是展示创建UDFTransformer的过程。 原则上,基于这样的简单示例,任何人都可以将逻辑添加到任何级别的复杂性。
val miss = ".*miss\\..*".r val mr = ".*mr\\..*".r val mrs = ".*mrs\\..*".r val master = ".*master.*".r def convertNames(input: String): Option[String] = { Option(input).map(x => { x.toLowerCase match { case miss() => "Miss" case mr() => "Mr" case mrs() => "Mrs" case master() => "Master" case _ => "Unknown" } }) }
(您可以立即看到Scala处理缺少的值有多么方便,顺便说一下,这些null不仅为null ,而且还为Double.NaN , 这么开玩笑 诸如BooleanType变量中的遗漏等罕见的事情)
现在声明我们的UserDefinedFunction并立即基于它创建一个Transformer :
val nameTransformUDF = udf(convertNames _) val nameTransformer = new UDFTransformer() .setUDF(nameTransformUDF) .setInputCol("Name") .setOutputCol("NameType")
注意:在Zeppelin笔记本电脑中,它们都是一样的,但是当所有这些东西都在生产代码中放到一起时,重要的是所有UDF都在extends Serializable类或对象中。 您有时可能会忘记然后再深入研究很长时间的显而易见的事情是读取Spark错误的长堆栈跟踪信息出了什么问题。
现在,我们还有“ Cabin字段。 让我们仔细看一下:

我们看到缺少许多值,有字母,数字,不同的组合等。 让我们以机舱的数量(如果多于一个)以及数量为例-它们可能具有某种逻辑,例如,如果编号是从船的一端开始的,那么船头上的机舱的机会就更少。 我们还将创建函数,然后基于它们UDFTransformer :
def getCabinsCount(input: String): Int = { Option(input) match { case Some(x) => x.split(" ").length case None => -1 } } val numPattern = "([az])([0-9]+)".r def getNumbersFromCabin(input: String): Int = { Option(input) match { case Some(x) => { x.split(" ")(0).toLowerCase match { case numPattern(sym, num) => Integer.parseInt(num) case _ => -1 } } case None => -2 } } val cabinsCountUDF = udf(getCabinsCount _) val numbersFromCabinUDF = udf(getNumbersFromCabin _) val cabinsCountTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinCount") .setUDF(cabinsCountUDF) val numbersFromCabinTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinNumber") .setUDF(numbersFromCabinUDF)
现在让我们从缺失的值开始,即年龄。 首先,让我们利用Zeppelin的可视化功能:
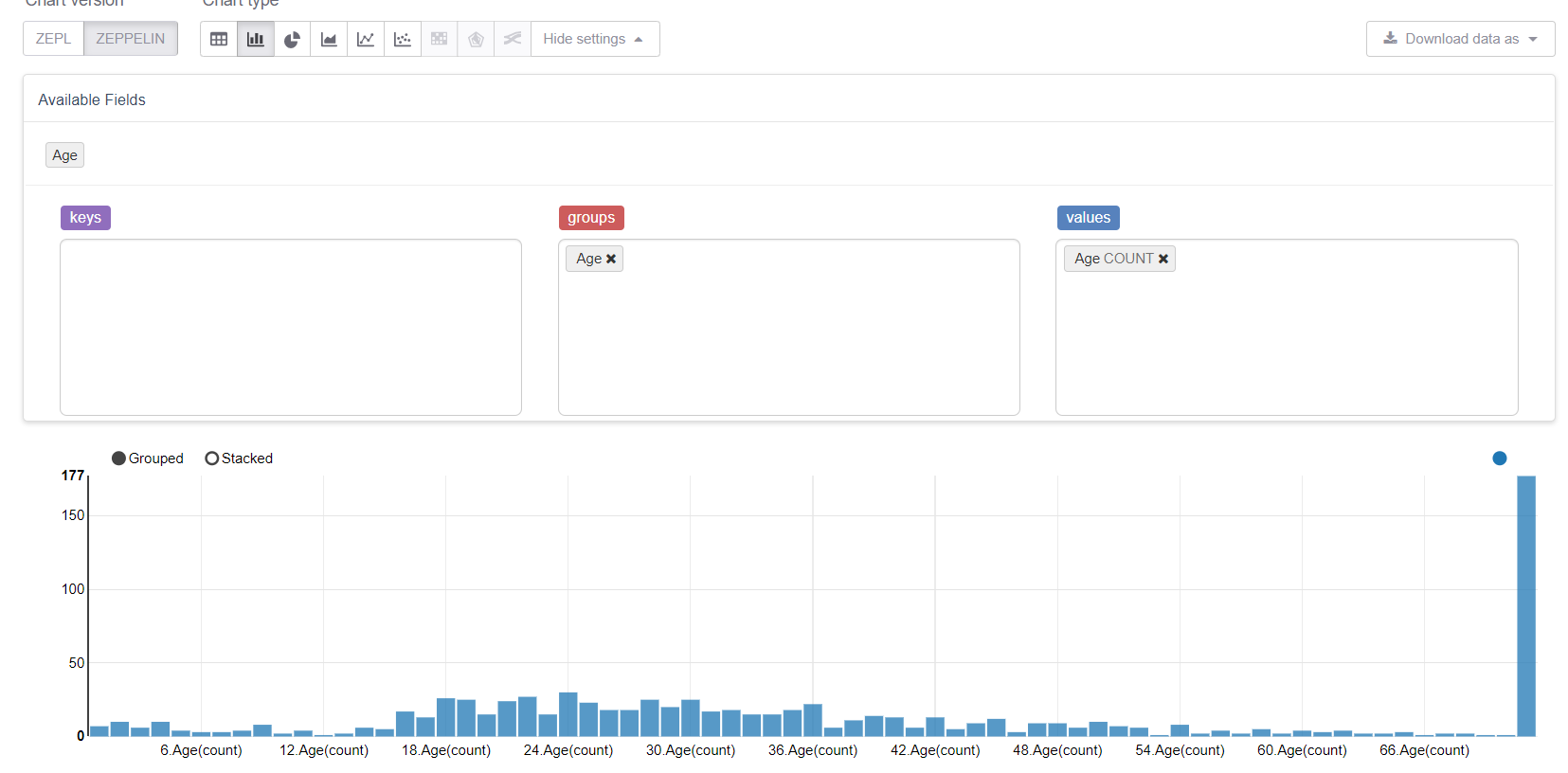
并查看缺失值如何破坏一切。 用中位数(或中位数)替换它们是合乎逻辑的,但是我们的目标是考虑MMLSpark库的所有功能。 因此,我们将编写自己的Estimator ,它将考虑训练样本上的组/平均值并将其替换为相应的差距。
我们将需要:
import org.apache.spark.sql.{Dataset, DataFrame} import org.apache.spark.ml.{Estimator, Model} import org.apache.spark.ml.param.{Param, ParamMap} import org.apache.spark.ml.util.Identifiable import org.apache.spark.ml.util.DefaultParamsWritable import com.microsoft.ml.spark.{HasInputCol, HasOutputCol} import com.microsoft.ml.spark.ConstructorWritable import com.microsoft.ml.spark.ConstructorReadable import com.microsoft.ml.spark.Wrappable
让我们注意一下ConstructorWritable ,它大大简化了生活。 如果我们的Model是fit(),方法返回的“受过训练”的模型,而该模型完全由其构造函数确定(这可能是99%的情况),那么我们根本无法用手编写序列化。 这确实大大简化并加快了开发速度,消除了错误,并降低了通常不是专业程序员的DataScientist和分析师的入门门槛。
定义我们的Estimator类。 实际上,这里最重要的是fit方法,其余是技术要点:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel] with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable { def this() = this(Identifiable.randomUID("GroupImputer")) val groupCol: Param[String] = new Param[String]( this, "groupCol", "Groupping column" ) def setGroupCol(v: String): this.type = super.set(groupCol, v) def getGroupCol: String = $(groupCol) override def fit(dataset: Dataset[_]): GroupImputerModel = { val meanDF = dataset .toDF .groupBy($(groupCol)) .agg(mean(col($(inputCol))).alias("groupMean")) .select(col($(groupCol)), col("groupMean")) new GroupImputerModel( uid, meanDF, getInputCol, getOutputCol, getGroupCol ) } override def transformSchema(schema: StructType): StructType = schema .add( StructField( $(outputCol), schema.filter(x => x.name == $(inputCol))(0).dataType ) ) override def copy(extra: ParamMap): Estimator[GroupImputerModel] = { val to = new GroupImputerEstimator(this.uid) copyValues(to, extra).asInstanceOf[GroupImputerEstimator] } }
注意:我没有使用defaultCopy,因为由于某种原因,当我调用它时,它发誓我没有构造函数\ <init>(java.lang.String),尽管这似乎不应该发生。 好吧,无论如何,实现copy容易。
现在,您需要实现Model一个描述经过训练的模型并实现transform方法的类。 我们将基于org.apache.spark.sql.functions内置的coalesce函数来构建它:
class GroupImputerModel( val uid: String, val meanDF: DataFrame, val inputCol: String, val outputCol: String, val groupCol: String ) extends Model[GroupImputerModel] with ConstructorWritable[GroupImputerModel] { val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel] def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol) override def copy(extra: ParamMap): GroupImputerModel = new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol) override def transform(dataset: Dataset[_]): DataFrame = { dataset .toDF .join(meanDF, Seq(groupCol), "left") .withColumn( outputCol, coalesce(col(inputCol), col("groupMean")) .cast(IntegerType)) .drop("groupMean") } override def transformSchema (schema: StructType): StructType = schema .add( StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType) ) }
我们需要声明的最后一个对象是Reader ,我们使用MMLSpark ConstructorReadable类实现了该对象:
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]
管道创建
在Pipeline中,我想展示常用的SparkML类和MMLSpark- MultiColumnAdapter中非常方便的东西,它使您可以将SparkML转换器一次应用于多个列(例如,作为参考,StringIndexer和OneHotEncoder会将输入仅包含一列,从而将它们变成输入广告陷入困境):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler} import org.apache.spark.ml.Pipeline import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}
首先,我们将声明我们拥有哪些列:
val catCols = Array("Sex", "Embarked", "NameType") val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")
现在创建一个字符串编码器:
val stringEncoder = new MultiColumnAdapter() .setBaseStage(new StringIndexer().setHandleInvalid("keep")) .setInputCols(catCols) .setOutputCols(catCols.map(x => x + "_freqEncoded"))
注意:与SparkML中的scikit-learn不同, StringIndexer遵循频率编码器的原理,可用于指定顺序关系(即,类别0 <类别1,这很有意义)-这种方法通常适用于决定性的树木。
Imputer我们的Imputer :
val missingImputer = new GroupImputerEstimator() .setInputCol("Age") .setOutputCol("AgeNoMissings") .setGroupCol("Sex")
还有VectorAssembler ,因为SparkML分类器更适合使用VectorType :
val assembler = new VectorAssembler() .setInputCols(stringEncoder.getOutputCols ++ numCols) .setOutputCol("features")
现在,我们将使用MMLSpark-LightGBM随附的梯度提升,它与XGBoost和CatBoost一起包含在该算法的最佳实现的“三巨头”中。 与SparkML拥有的GBM实现相比,它的工作速度更快,更好,更稳定(即使考虑到JVM端口仍处于活动开发中):
val catColIndices = Array(0, 1, 2) val lgbClf = new LightGBMClassifier() .setFeaturesCol("features") .setLabelCol("Survived") .setProbabilityCol("predictedProb") .setPredictionCol("predictedLabel") .setRawPredictionCol("rawPrediction") .setIsUnbalance(true) .setCategoricalSlotIndexes(catColIndices) .setObjective("binary")
注意: LightGBM支持使用分类变量(几乎类似于catboost),因此我们提前向其指出了类别属性在向量中的位置,他本人将弄清楚如何使用它们以及如何对其进行编码。
有关Spark的LightGBM功能的更多信息- 在运行RadHat LightGBM的节点上,除最新版本外,任何版本都会崩溃,原因是他不喜欢
glibc版本。 最近已修复此问题,但是,通过Maven安装时,MMLSpark通过Maven安装时会拉倒数第二个版本的LightGBM,因此您需要手动添加RadHat上最新版本的依赖项。 - LightGBM在其工作中在驱动程序上创建了一个套接字以与执行人员进行通信,并且它使用
new java.net.ServerSocket(0) ,因此使用了操作系统的临时端口中的随机端口。 如果临时端口的范围与防火墙打开的端口的范围不同,则 会燃烧很多 当LightGBM有时会工作(当我选择一个好的端口时),有时却无法工作,您会得到一个有趣的效果。 并且那里会出现诸如ConnectionTimeOut类的错误,例如,它也可能表明GC挂在高管身上时的选择或类似的选项。 通常,不要重复我的错误。
好吧,最后,声明我们的管道:
val pipeline = new Pipeline() .setStages( Array( missingImputer, nameTransformer, cabinsCountTransformer, numbersFromCabinTransformer, stringEncoder, assembler, lgbClf ) )
培训课程
我们将训练集分为火车和测试,并检查我们的管道。 在这里,有可能评估管道的便利性,因为它完全独立于分区,并保证我们将应用相同的转换进行训练和测试,并且所有转换参数都将在训练中“学习”:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2)) println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
为了方便计算指标,我们将使用MMLSpark- ComputeModelStatistics中的另一个类:
import com.microsoft.ml.spark.ComputeModelStatistics import com.microsoft.ml.spark.metrics.MetricConstants val modelEvaluator = new ComputeModelStatistics() .setLabelCol("Survived") .setScoresCol("predictedProb") .setScoredLabelsCol("predictedLabel") .setEvaluationMetric(MetricConstants.ClassificationMetrics)
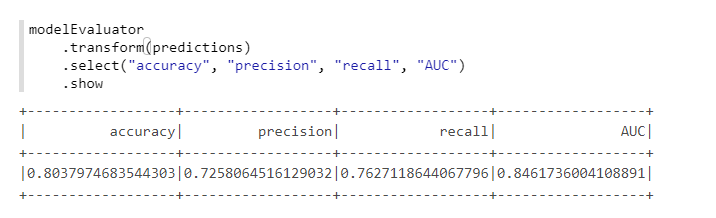
不错,因为我们没有更改默认设置。
选择超参数
要在MMLSpark中选择超参数,有一个单独的很酷的东西TuneHyperparameters ,它在网格上实现了随机搜索。 但是,不幸的是,它还不支持Pipeline ,因此我们将使用常规的SparkML CrossValidator :
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator} import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator val paramSpace = new ParamGridBuilder() .addGrid(lgbClf.maxDepth, Array(3, 5)) .addGrid(lgbClf.learningRate, Array(0.05, 0.1)) .addGrid(lgbClf.numIterations, Array(100, 300)) .build println(s"Size of ParamsGrid: ${paramSpace.size}")
不幸的是,我没有找到一种方便的方法来查看结果以及获得结果的参数。 因此,有必要使用“怪异”的设计:
crossValidator .getEstimatorParamMaps .zip(bestModel.avgMetrics) .foreach(x => { println( "\n" + x._1 .toSeq .foldLeft(new StringBuilder())( (a, b) => a .append(s"\n\t${b.param.name} : ${b.value}")) .toString + s"\n\tMetric: ${x._2}" ) })
这给了我们这样的东西:
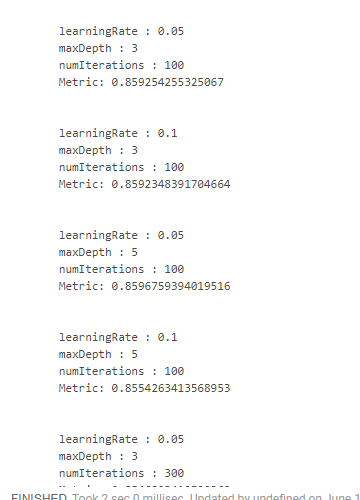
通过降低学习速度和增加树木的深度,我们获得了最佳结果。 在此基础上,有可能调整搜索空间并获得更好的结果,但是我们根本没有这样的目标。
结论
实际上,虽然MMLSpark具有0.17版,但仍包含单独的错误。 但是在我看到的所有Spark扩展中,我认为MMLSpark拥有最全面的文档以及最易于理解的安装和实施过程。 微软还没有真正推广它,只有关于Databricks的报告 ,但是更多的是关于DeepLearning的信息,而不是我写的这些常规信息。
就个人而言,在我们的任务中,该库发挥了很大作用,使我可以从Spark资源的丛林中得到一些帮助,并且不使用反射来访问私有[ml]方法,而我的一位同事几乎偶然地发现了该库。 同时,由于该库正在积极开发中,因此源文件结构 稀饭 有点混乱。 好吧,由于没有特殊的示例或其他文档(仅空的scaladoc除外),因此我一开始必须一直爬到源代码中。
因此,我真的希望这个迷你教程(尽管它非常明显和简单)对某人有用,并且可以节省很多时间和精力!