可以在此链接上找到完整的俄语课程。
此链接提供原始英语课程。

每2-3天安排一次新的讲座。
目录内容
- 塞巴斯蒂安·特伦的采访
- 引言
- 狗和猫数据集
- 各种尺寸的图像
- 彩色图像。 第一部分
- 彩色图像。 第二部分
- 对彩色图像进行卷积运算
- 在彩色图像中通过最大值进行二次采样的操作
- CoLab:猫和狗
- Softmax和S形
- 检查一下
- 图片扩展
- 例外情况
- CoLab:猫狗。 重复性
- 其他防止再培训的技术
- 练习:彩色图像分类
- 解决方案:彩色图像分类
- 总结
塞巴斯蒂安·特伦的采访
-今天,我们和塞巴斯蒂安一起再次来到这里,我们将谈论再培训。 这个话题对我们来说非常有趣,尤其是在本课程中有关使用TensorFlow的实践部分中。
-塞巴斯蒂安(Sebastian),您是否遇到过拟合问题? 如果您说您还没有遇到,那么我一定会说我不相信您!
-因此,重新训练的原因是所谓的偏差方差折衷 (偏差参数值与其分布之间的折衷)。 少数权重无法学习足够数量示例的神经网络,机器学习中的类似情况称为失真。
-是的
-具有如此多参数的神经网络可以任意选择一个您不喜欢的解决方案,因为这些参数的数量如此之多。 选择神经网络解决方案的结果取决于源数据的可变性。 因此,可以制定一个简单的规则:网络中有关数据大小(数量)的参数越多,获得随机解决方案而不是正确解决方案的可能性就越大。 例如,您问自己:“这个房间里的男人是谁,女人是谁?” 复杂的神经网络可以告诉您,例如,所有名称以T开头的人都是男人,永远不会再训练。 有两种解决方案。 其中第一个使用保留数据集(从训练集中获取少量数据以验证模型的准确性)。 您可以获取数据,将其分为两部分-90%用于训练,10%用于测试,然后进行所谓的交叉验证,在交叉验证中,一旦误差值开始,您就可以根据神经网络看不到的数据检查模型的准确性。在一定的训练周期后才能成长-是时候停止学习了。 第二种解决方案是将限制引入神经网络。 例如,要限制位移和权重参数的值,使它们越来越接近零。 权重越受限制,模型的再训练就越少。
-我正确理解,我们可以拥有用于培训,测试和验证的数据集,对吗?
-是的 如果您有用于验证的数据集,那么您必须具有从未接触过或未显示给神经网络的数据集。 如果您多次向模型显示某个数据集,那么当然,重新训练过程将开始,这对我们来说是非常不利的。
-也许您会记得重新训练模型时最有趣的情况?
-啊,是的...在我年轻的时候,当我开发一个用于下棋的神经网络时就发生了这样的事件。 那是在1993年。有趣的是,从训练了神经网络的国际象棋数据中,该网络迅速确定,如果专家将女王/王后移动到国际象棋棋盘的中心,那么就有60%的获胜机会。 她开始做的是用棋子打开“通道”,然后将女王移到棋盘的中央。 对于任何国际象棋棋手来说,这都是一个愚蠢的决定,这显然证明了该模型的再训练。
-太好了! 因此,我们讨论了有关如何改进模型的几种技术。 您认为深度学习最被低估的方面是什么?
-90%的工作被低估了,因为90%的工作将包括数据清理。
-我完全同意你的看法!
-如实践所示,任何数据集都包含某种垃圾。 很难将数据归为正确的类型,以使其保持一致,这是一个非常耗时的过程。
-是的,即使您使用图像或视频之类的数据集,似乎所有信息都已经存在,在内部,仍然需要对图像进行预处理。
-唯一适合他们的数据的人是教授,因为他们有机会假装在PowerPoint中的演示文稿中说一切都应该正确,一切都完美! 实际上,数据清理将占用您90%的时间。
太好了 因此,让我们找到更多有关再培训和技术的知识,这些知识和技术将使我们能够改善深度学习模型。
引言
-嗨! 再次欢迎您参加本课程!
-在上一课中,我们开发了一个小型卷积神经网络,用于根据FASHION MNIST数据集以灰色阴影对服装元素的图像进行分类。 在实践中我们已经看到,我们的小型神经网络可以相当准确地对传入图像进行分类。 但是,在现实世界中,我们必须处理高分辨率图像和各种尺寸。 SNA的一大优点是,它们可以与彩色图像一样好地工作。 因此,我们将通过探讨SNA如何与彩色图像配合使用来开始本课程。
-之后,您将以相同的频率构建一个卷积神经网络,该网络可以对猫和狗的图像进行分类。 在实现能够对猫和狗的图像进行分类的卷积神经网络的方法上,我们还将学习如何使用各种技术来解决神经网络最常见的问题之一-再训练。 在本课程的最后,在实践部分中,您将开发自己的卷积神经网络来对彩色图像进行分类。 让我们开始吧!
猫狗数据集
在那一刻之前,我们仅处理来自FASHION MNIST数据集的灰度图像和尺寸为28x28的灰度图像。

在实际应用中,我们不得不遇到各种尺寸的图像,例如,如下所示:

正如我们在本课开始时提到的那样,在本课中,我们将开发一个卷积神经网络,该网络可以对狗和猫的彩色图像进行分类。
为了实施我们的计划,我们将使用Microsoft Asirra数据集中的猫和狗的图像。 如果图像中分别有狗或猫,则此数据集中的每个图像分别标记为1或0。

尽管Microsoft Asirra数据集包含超过300万个带有标签的猫和狗的图像,但只有25,000个是公开可用的。 在这25,000张图像上训练我们的卷积神经网络将花费大量时间。 这就是为什么我们将使用少量图像从可用的25,000个训练我们的卷积神经网络的原因。
我们的训练图像子集包括2,000张和1,000张图像,用于模型验证。 在训练数据集中,1,000张图像包含猫,其他1,000张图像包含狗。 在本节的稍后部分,我们将讨论用于验证的数据集。
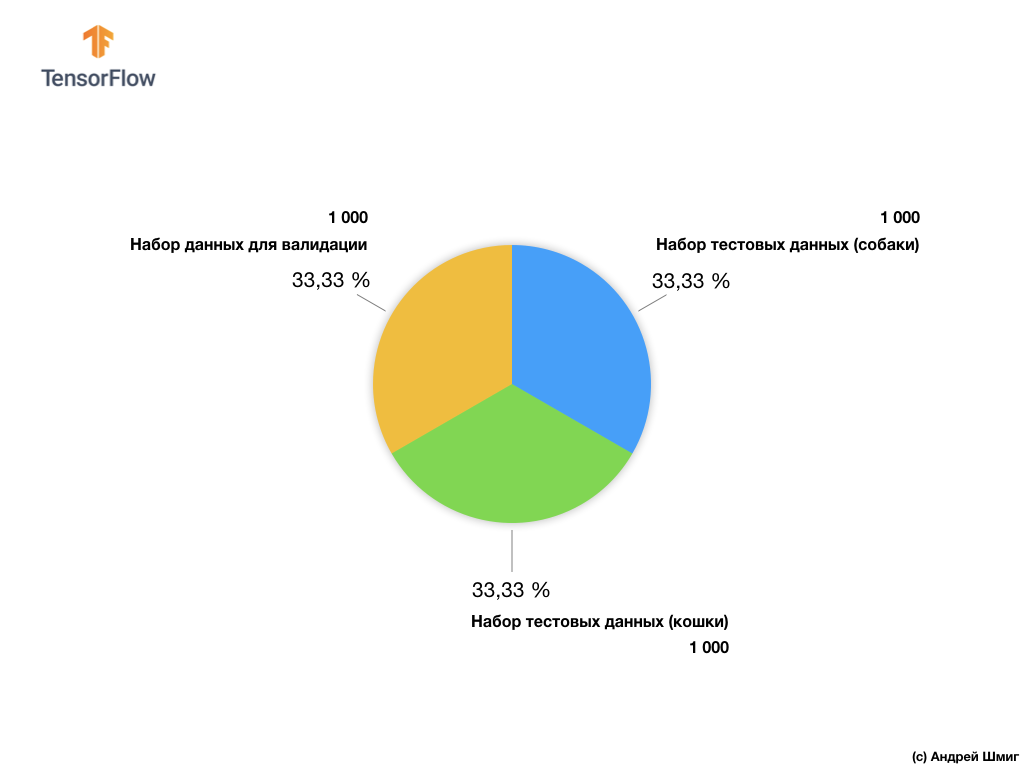
使用此数据集,我们将遇到两个主要困难-使用不同大小的图像和使用彩色图像。
让我们开始探索如何处理各种尺寸的图像。
各种尺寸的图像
我们的第一个测试将是解决处理各种尺寸图像的问题。 这是因为输入处的神经网络需要固定大小的数据。
例如,创建Flatten层时,您可以使用input_shape参数回顾以前的部分:

在将服装元素的图像传输到神经网络之前,我们将其转换为固定大小的一维数组-28x28 = 784个元素(像素)。 由于Fashion MNIST数据集中的图像大小相同,因此生成的一维数组的大小相同,并且由784个元素组成。
但是,通过处理各种大小(高度和宽度)的图像并将其转换为一维数组,我们得到了不同大小的数组。
由于输入端的神经网络需要相同大小的数据,因此仅仅摆脱转换为像素值的一维数组是不够的。
为了解决图像分类问题,我们始终采用统一输入数据的选项之一-将图像的大小减小到通用值(调整大小)。
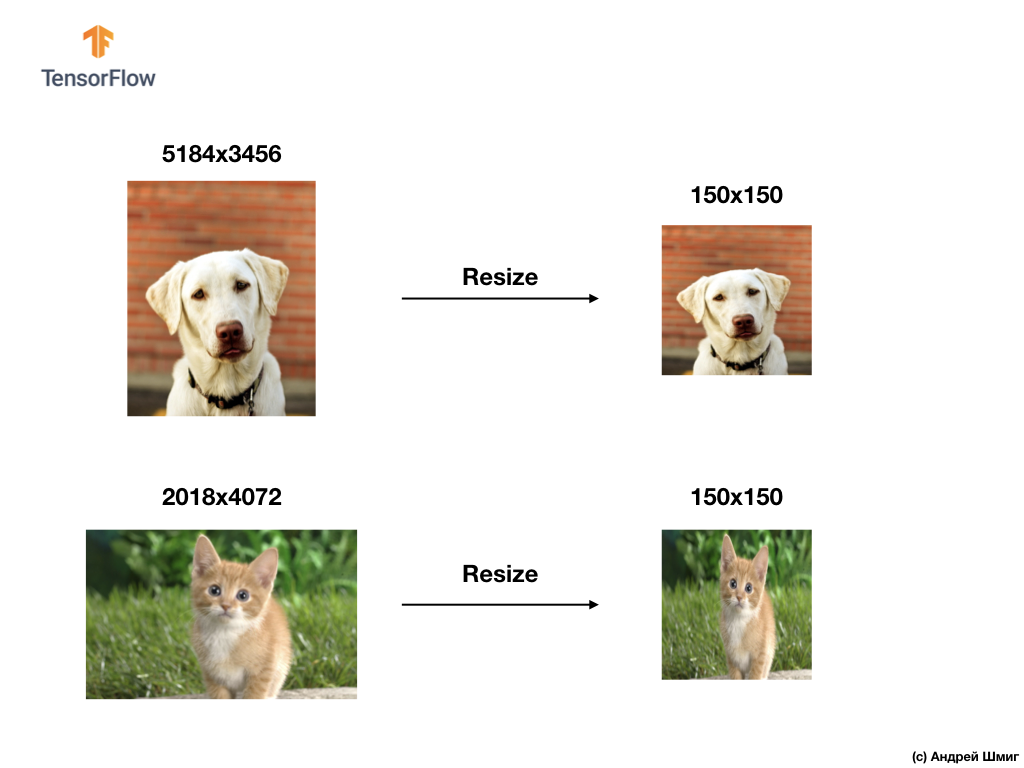
在本教程中,我们将诉诸于将所有图像的大小调整为高度150像素和宽度150像素。 将图像转换为单一大小,由此可以保证正确大小的图像将到达神经网络的输入,并且当转移到flatten层时,我们将获得相同大小的一维数组。
tf.keras.layers.Flatten(input_shape(150,150,1))
结果,我们得到了由150x150 = 22,500个值(像素)组成的一维数组。
我们将面临的下一个问题将是彩色问题-彩色图像。 我们将在下一部分中讨论它们。
彩色图像。 第一部分
为了理解和理解卷积神经网络如何与彩色图像一起使用,我们应该深入研究SNA的总体工作原理。 让我们刷新我们已经知道的内容。
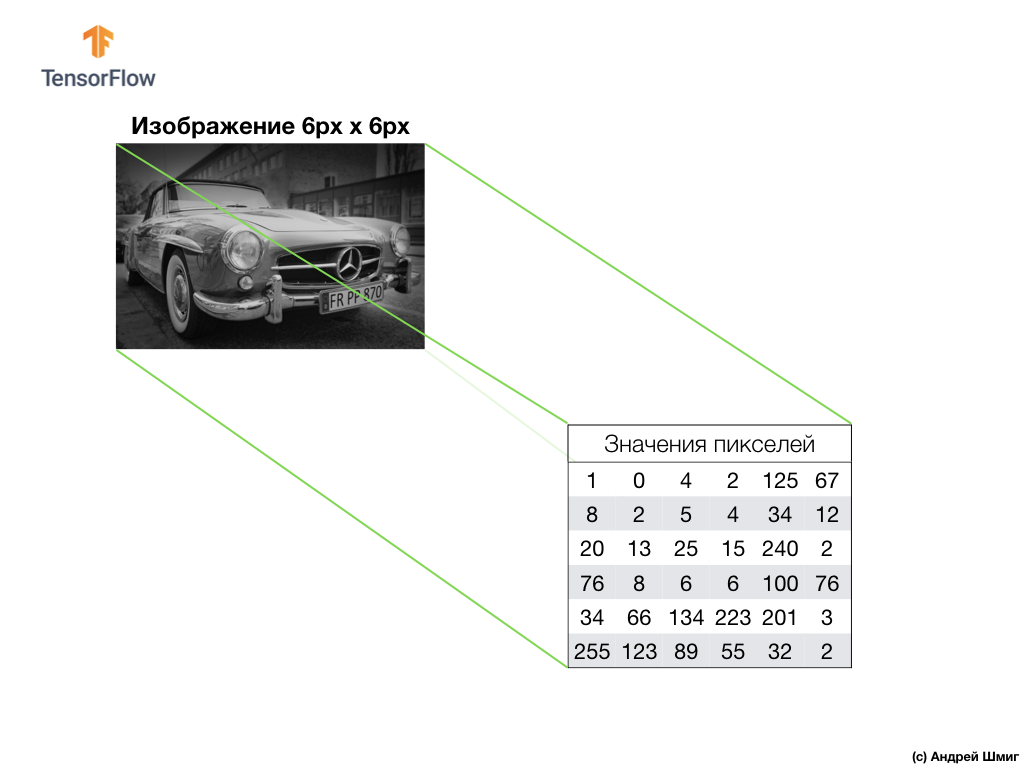
上面的示例是灰度图像,以及计算机如何将其解释为像素值的二维数组。
下面的示例是图像,这次是颜色,以及计算机如何将其解释为像素值的三维数组。
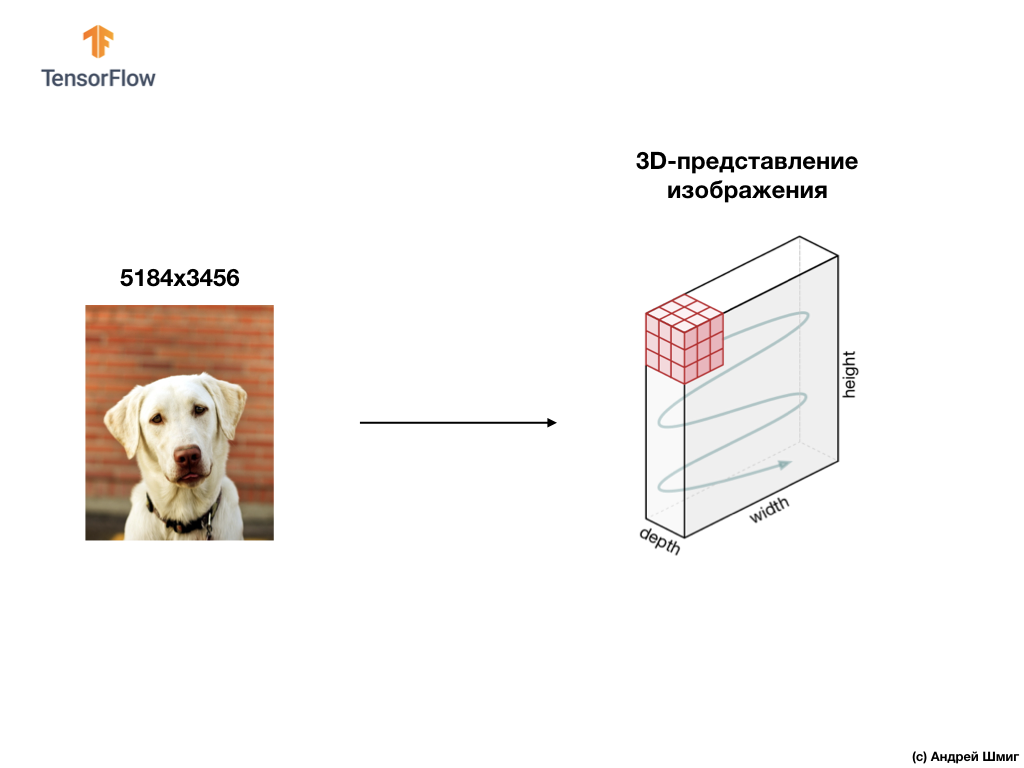
3D阵列的高度和宽度将由图像的高度和宽度决定,深度决定图像的颜色通道数。
大多数彩色图像可以由三个颜色通道表示-红色(红色),绿色(绿色)和蓝色(蓝色)。

由红色,绿色和蓝色通道组成的图像称为RGB图像。 这三个通道的组合产生彩色图像。 在每个RGB图像中,每个通道均由单独的二维像素阵列表示。
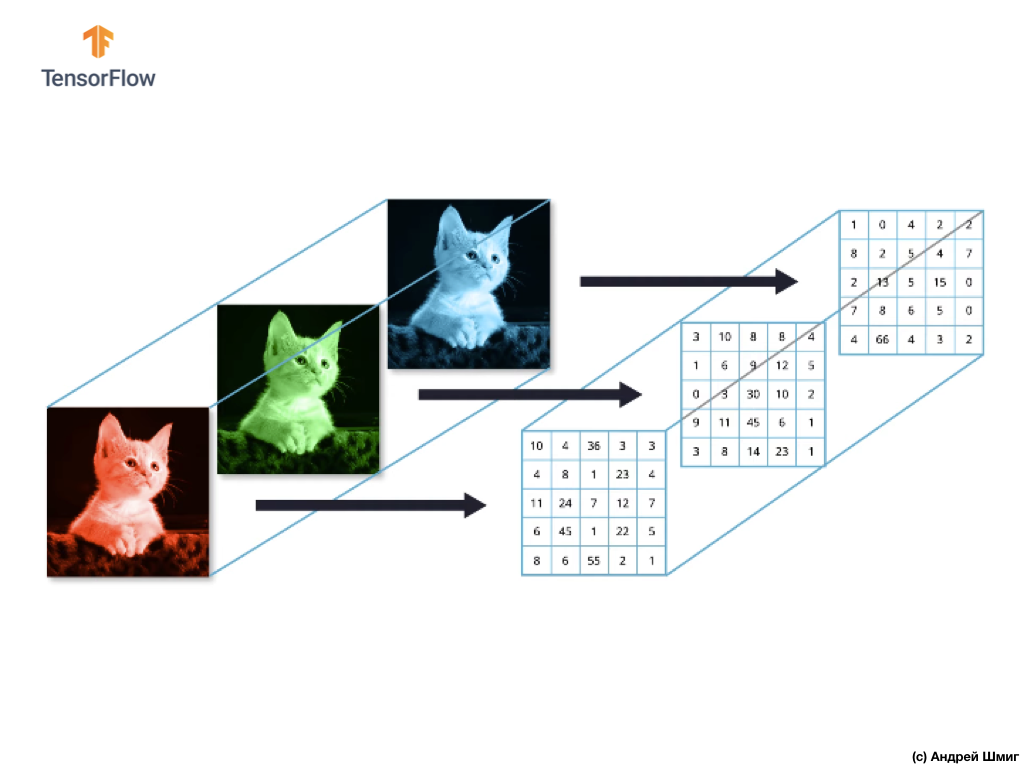
由于我们拥有的通道数量为三个,因此,我们将拥有三个二维数组。 因此,由3个颜色通道组成的彩色图像将具有以下表示形式:

彩色图像。 第二部分
因此,由于我们的图像现在将由3种颜色组成,这意味着它将是一个像素值的三维数组,因此我们的代码将需要进行相应的更改。
如果您查看上一课中解决图像中服装元素分类问题时使用的代码,可以看到我们指出了输入数据的维数:
model = Sequential() model.add(Conv2D(32, 3, padding='same', activation='relu', input_shape=(28,28,1)))
元组(28,28,1)的前两个参数是图像的高度和宽度的值。 Fashion MNIST数据集中的图像大小为28x28像素。 元组(28,28,1)的最后一个参数表示颜色通道的数量。 在Fashion MNIST数据集中,图像仅处于灰色阴影-1个颜色通道中。
既然任务变得更加复杂了,我们的猫和狗的图像大小也有所不同(但转换为单个图像-150x150像素)并包含3个颜色通道,那么值的元组也应该有所不同:
model = Sequential() model.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(150,150,3)))
在下一部分中,我们将看到在图像中存在三个颜色通道的情况下如何计算卷积。
对彩色图像进行卷积运算
在过去的课程中,我们学习了如何在灰度图像上执行卷积运算。 但是如何在彩色图像上执行卷积运算呢? 让我们从重复如何在灰度图像上执行卷积操作开始。
这一切都始于一定大小的过滤器(核心)。
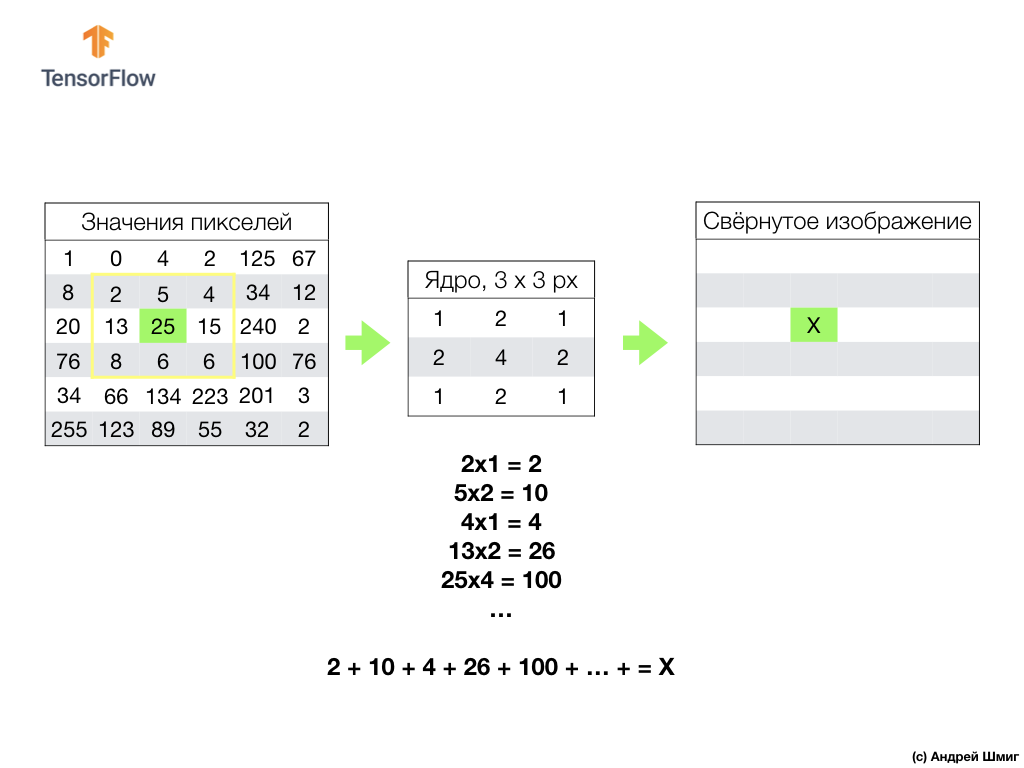
滤波器位于要转换的特定图像像素上,然后将每个滤波器值乘以图像中相应的像素值,然后将所有这些值相加。 在转换后的原始像素所在的位置的新图像中设置最终像素值。 对原始图像的每个像素重复该操作。
还值得记住的是,在卷积操作期间,为了不丢失图像边缘的信息,我们可以应用对齐方式,并使用零填充图像边缘:

现在让我们弄清楚如何对彩色图像执行卷积运算。
正如将图像转换为灰色阴影一样,我们从选择特定大小的滤镜(核心)的大小开始。

现在唯一的区别是滤镜本身将是三维的,并且depth参数的值将等于图像中颜色通道数的值-3(在我们的示例中为RGB)。 对于颜色通道的每个“层”,我们还将对选定大小的滤镜应用卷积运算。 让我们看看它是一个例子。
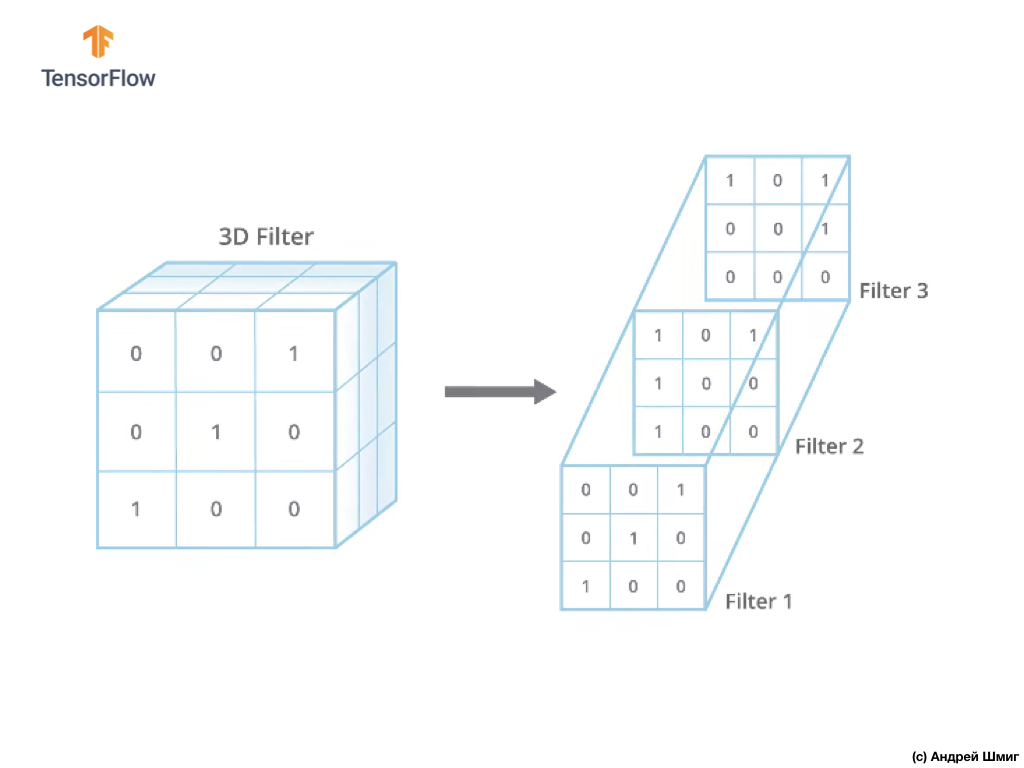
假设我们有一个RGB图像,并且想对下一个3D滤镜应用卷积运算。 值得一提的是,我们的滤波器包含3个二维滤波器。 为简单起见,让我们假设我们的RGB图像大小为5x5像素。

还记得每个颜色通道是像素颜色值的二维数组。
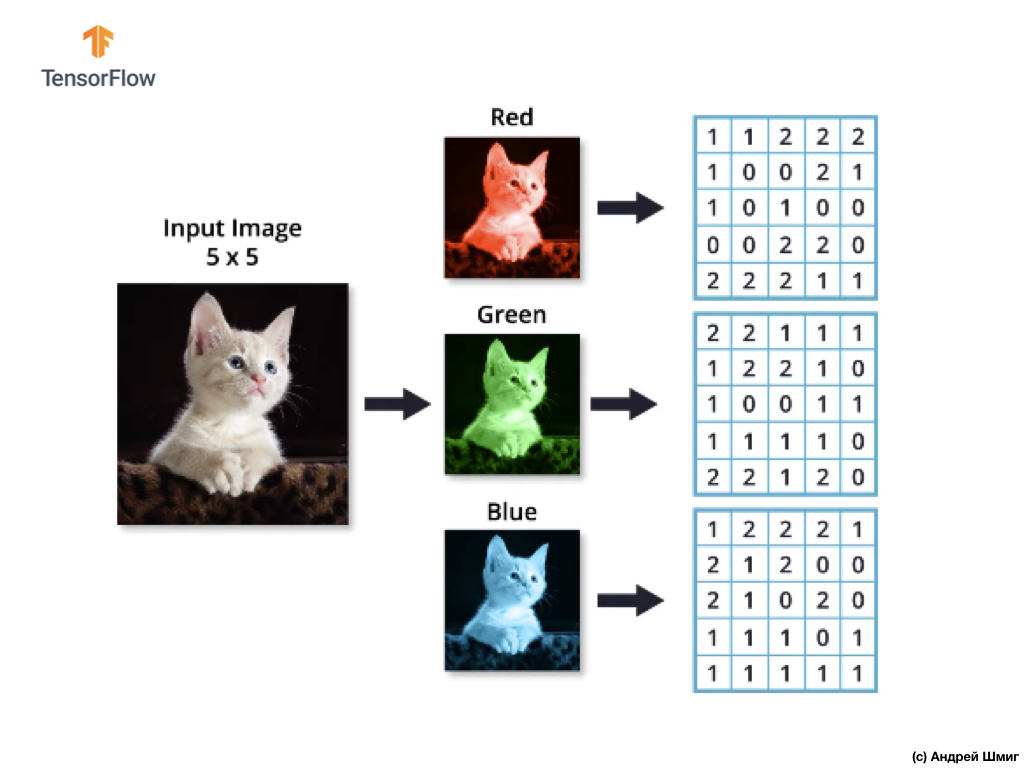
与对具有灰色阴影的图像进行卷积操作以及对彩色图像进行卷积操作一样,我们将进行对齐并在边缘的图像上添加零,以防止边界信息丢失。
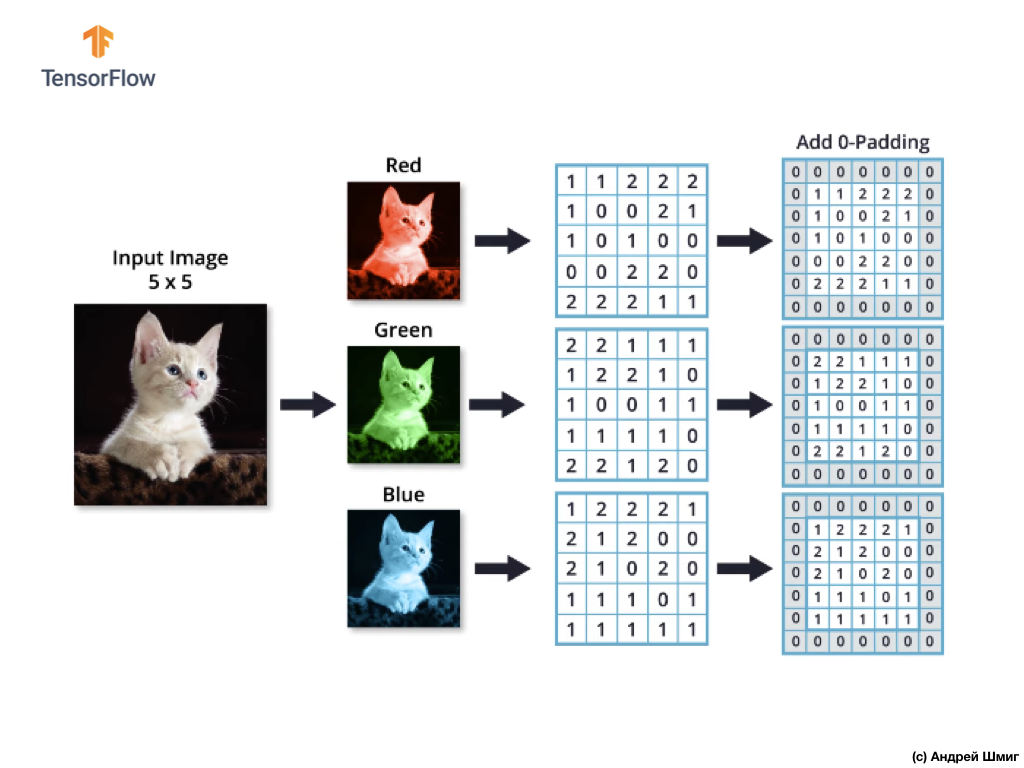
现在我们准备进行卷积运算!
彩色图像的卷积机制将类似于我们对灰度图像执行的过程。 在灰度和彩色图像上执行的操作之间的唯一区别是,现在需要对每个彩色通道执行3次卷积操作。
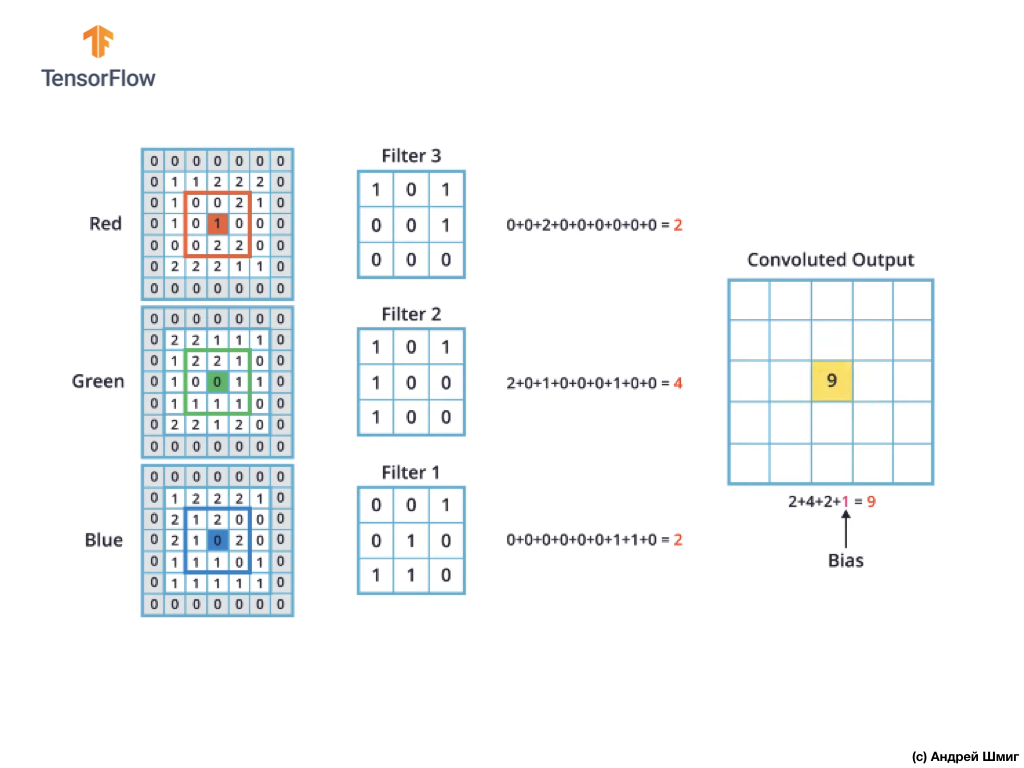
然后,在对每个颜色通道执行卷积运算之后,将三个获得的值相加并对其加1(执行此类操作时使用的标准值)。 所得的新值固定在新图像中的相同位置,即当前转换像素所在的位置。
我们对原始图像中的每个像素和每个颜色通道执行类似的转换操作(卷积操作)。
在此特定示例中,所得图像的高度和宽度与我们的原始RGB图像相同。
如您所见,将卷积运算与单个3D滤镜一起应用将产生单个输出值。
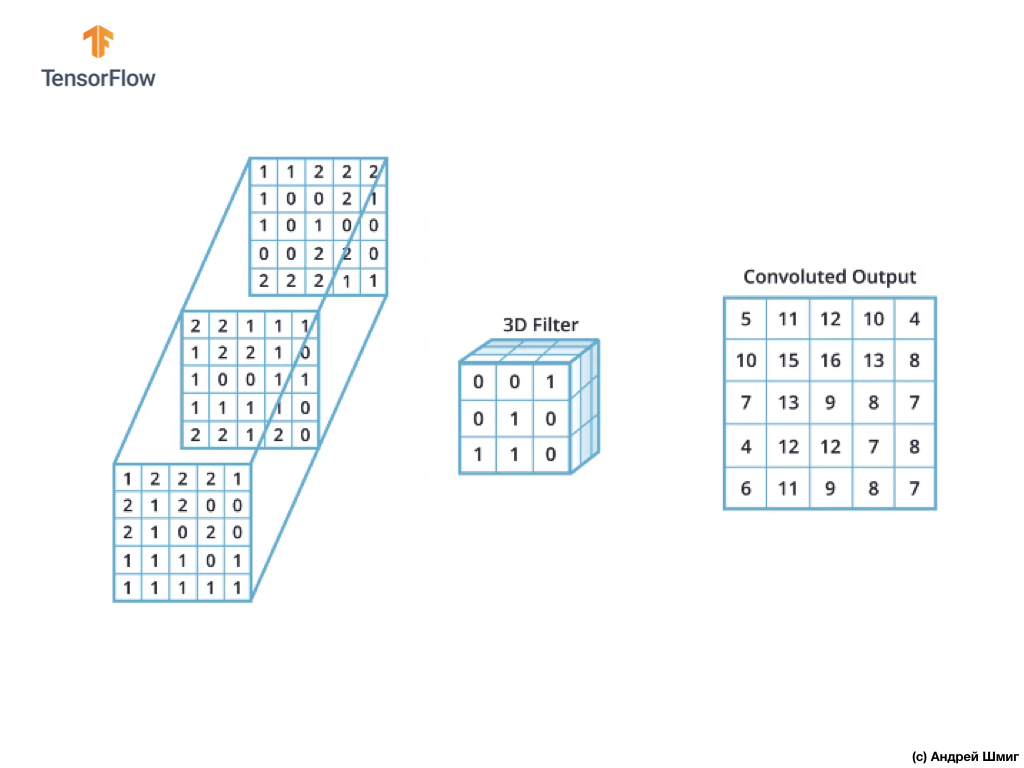
但是,在使用卷积神经网络时,通常的做法是使用多个3D滤波器。 如果我们使用多个3D滤镜,则结果将是多个输出值-每个值都是一个滤镜的结果。
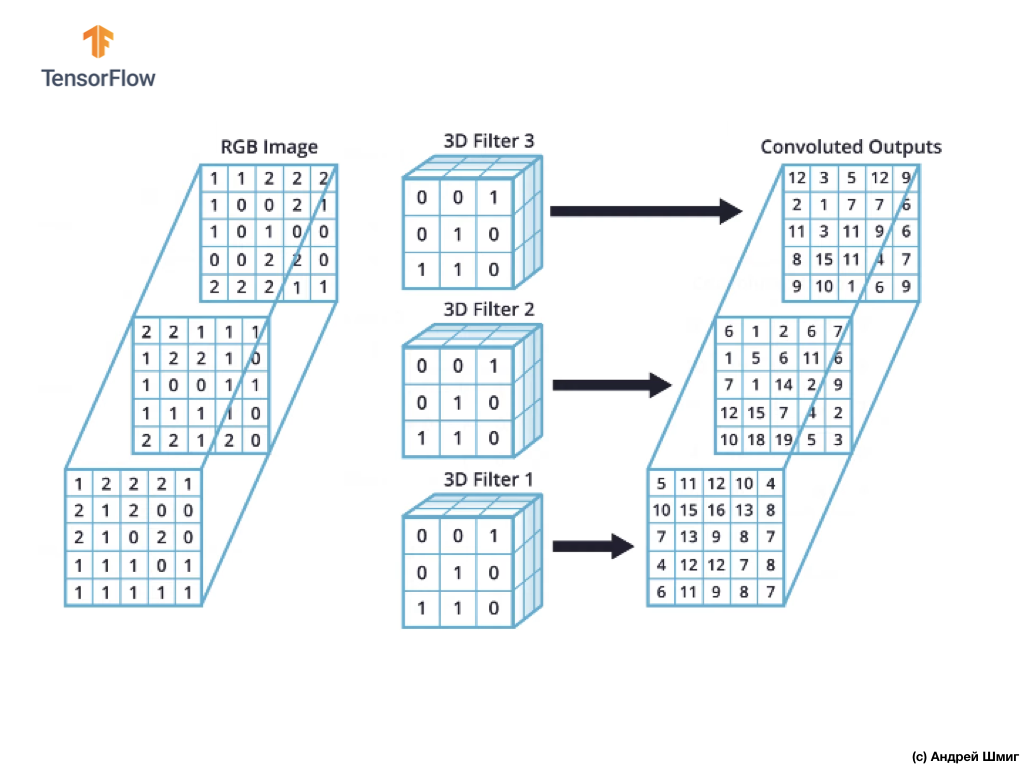
在上面的示例中,由于我们使用3个滤镜,因此生成的3D表示的深度将为3-每层将对应于一个滤镜在其所有颜色通道上方的图像上方的转换的输出值。
例如,如果我们决定使用16个而不是3个滤镜,则输出3D表示将包含16个深度层。
在代码中,我们可以通过为filters参数传递适当的值来控制创建的过滤器的数量:
tf.keras.layers.Conv2D(filters, kernel_size, ...)
我们还可以通过kernel_size参数指定过滤器的大小。 例如,要创建3个大小为3x3的过滤器,就像上面的示例一样,我们可以编写如下代码:
tf.keras.layers.Conv2D(3, (3,3), ...)
请记住,在训练卷积神经网络的过程中,将更新3D滤波器中的值以最小化损失函数的值。
现在,我们知道了如何对彩色图像执行卷积运算,是时候该弄清楚如何对最大值进行二次采样操作了(相同的最大池化)。
在彩色图像中通过最大值进行二次采样的操作
现在让我们学习如何在彩色图像中以最大值执行子采样操作。 实际上,以最大值进行二次采样的操作与处理具有灰色差异的灰色阴影的图像的方式相同-现在,由于应用了过滤器,因此需要将二次采样的操作应用于我们收到的每个输出表示。 让我们来看一个例子。
为了简单起见,让我们假设我们的输出视图如下所示:
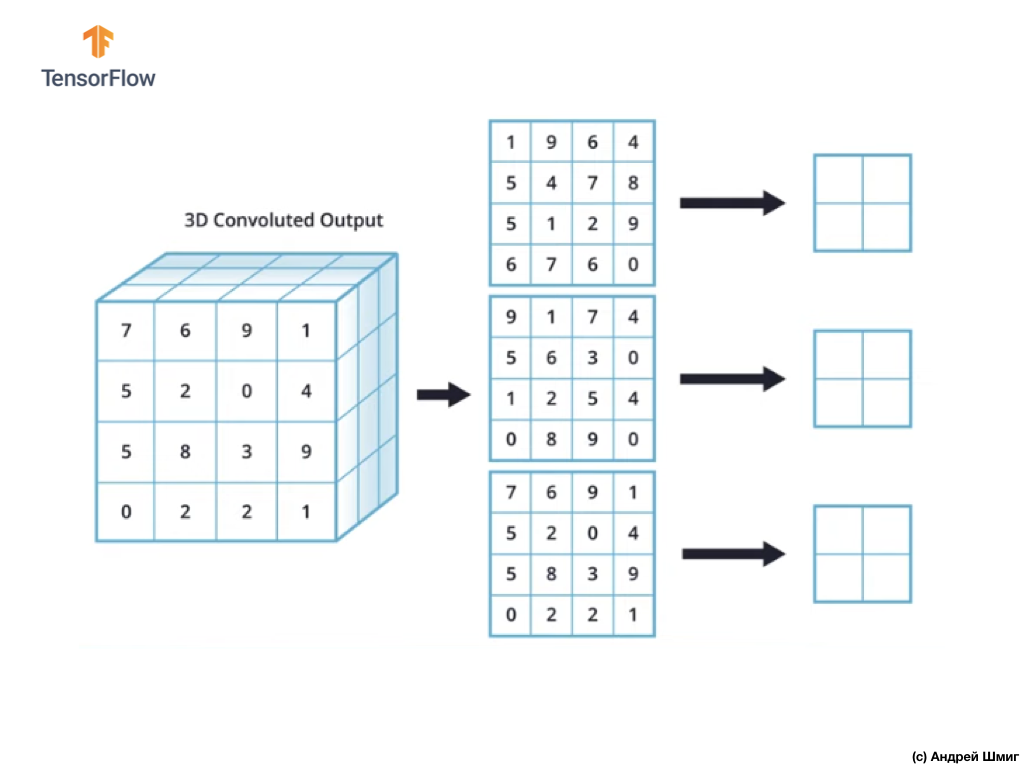
和以前一样,我们将使用2x2内核和第2步以最大值执行子采样操作。 以最大值进行二次采样的操作始于在每个输出表示形式(应用卷积运算后获得的表示形式)的左上角“安装” 2x2内核。

现在我们可以以最大值开始子采样操作。 例如,在我们的第一个输出表示形式中,以下值落入2x2内核中:1、9、5、4。由于此内核中的最大值为9,因此它将被发送到新的输出表示形式。 对每个输入表示重复类似的操作。
结果,我们应该得到以下结果:

以最大值执行二次采样操作后,结果是3个二维数组,每个二维数组的大小都比原始输入表示小2倍。
因此,在这种特定情况下,当在三维输入表示中执行最大值的二次采样操作时,我们获得了深度相同,但高度和宽度值为初始值的一半的三维输出表示。
因此,这是我们进一步工作所需要的整个理论。 现在,让我们看看它在代码中是如何工作的!
CoLab:猫和狗
可通过此链接获得英文版的CoLab原始文档。
此链接提供俄语版CoLab。
在本教程中,我们将讨论如何对猫和狗的图像进行分类。 我们将使用tf.keras.Sequential模型开发图像分类器,并使用tf.keras.Sequential加载数据。
本部分要涵盖的想法:
我们将在开发分类器时获得实践经验,并对以下概念有直观的了解:
- 使用
tf.keras.preprocessing.image.ImageDataGenerator -class建立数据流( 数据输入管道 ) tf.keras.preprocessing.image.ImageDataGenerator (如何有效地处理磁盘上与模型交互的数据?) - 再培训-这是什么以及如何确定?
在我们开始之前...
在编辑器中启动代码之前,建议您在顶部菜单中的“ 运行时->全部重置”中重置所有设置。 如果您是并行工作或与多个编辑器一起工作,则此操作将有助于避免内存不足的问题。
导入包
让我们从导入所需的包开始:
os读取文件和目录结构;numpy对于TensorFlow之外的某些矩阵运算;matplotlib.pyplot从测试和验证数据集中绘制和显示图像。
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
导入TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
资料载入
我们通过加载数据集开始开发分类器。 我们使用的数据集是Kaggle服务中“ 狗与猫”数据集的过滤版本(最后,该数据集由Microsoft Research提供)。
过去,CoLab和我使用过TensorFlow Dataset模块本身的数据集 ,这对于工作和测试非常方便。 但是,在此CoLab中,我们将使用tf.keras.preprocessing.image.ImageDataGenerator类从磁盘读取数据。 因此,首先,我们需要下载Dog VS Cats数据集并解压缩。
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
我们下载的数据集具有以下结构:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
要获取目录的完整列表,可以使用以下命令:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
结果,我们得到类似的结果:
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
现在将正确的路径分配给具有数据集的目录,以对变量进行训练和验证:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
了解数据及其结构
让我们看看测试和验证数据集(目录)中有多少只猫和狗的图像。
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
最后一块的输出如下:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
设置模型参数
为方便起见,我们将在进一步的发布中单独放置进一步数据处理和模型训练所需的变量:
BATCH_SIZE = 100
资料准备
在将图像用作我们的网络的输入之前,必须将它们转换为具有浮点值的张量。 要执行此操作的步骤列表:
- 从磁盘读取图像
- 解码图像内容并考虑RGB配置文件转换为所需格式
- 转换为具有浮点值的张量
- 要对从0到255的区间到0到1的区间的张量值进行归一化,因为神经网络在输入值较小时效果更好。
幸运的是,所有这些操作都可以使用tf.keras.preprocessing.image.ImageDataGenerator类执行。
我们可以使用几行代码来完成所有这些工作:
train_image_generator = ImageDataGenerator(rescale=1./255) validation_image_generator = ImageDataGenerator(rescale=1./255)
在为一组测试和验证数据定义了生成器之后, flow_from_directory方法将仅通过一行代码从磁盘加载图像,规范化数据并调整图像大小:
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
结论:
Found 2000 images belonging to 2 classes.
验证数据生成器:
val_data_gen = validation_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, shuffle=False, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
结论:
Found 1000 images belonging to 2 classes.
可视化训练集中的图像。
我们可以使用matplotlib可视化来自训练数据集的图像:
sample_training_images, _ = next(train_data_gen)
next函数从数据集中返回一个图像块。 一个块是(许多图像,许多标签)的元组。 目前,我们将删除标签,因为我们不需要它们了-我们对图像本身很感兴趣。
plotImages(sample_training_images[:5])
输出示例(2张图片,而不是全部5张图片):

模型制作
我们描述模型
该模型由4个卷积块组成,每个块后面都有一个带子样本层的块。 接下来,我们有一个具有512个神经元和relu激活relu的全连接层。 该模型将使用softmax给出两个类别(狗和猫)的概率分布。
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
模型编译
和以前一样,我们将使用adam优化器。 我们使用sparse_categorical_crossentropy作为损失函数。 我们还希望在每次训练迭代时监视模型的准确性,因此我们将accuracy值传递给metrics参数:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
模型视图
让我们使用summary方法按级别查看模型的结构:
model.summary()
结论:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
结论:
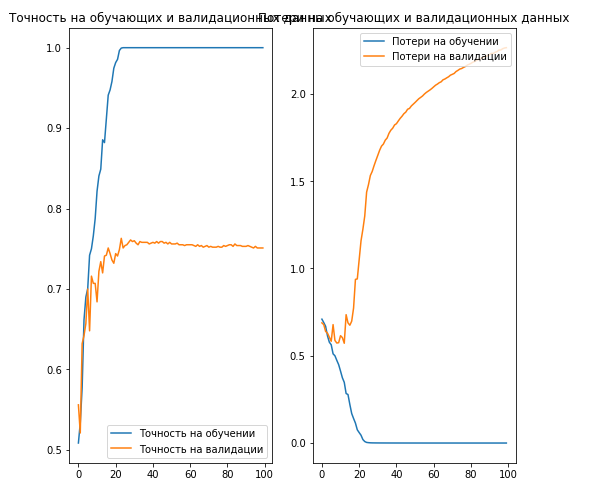
, 70% ( ).
. , .
… .
… call-to-action — , share :)
YouTube的
电报
VKontakte