选择新分支的地点是负责任的决定。 错误可能代价高昂,尤其是在资本密集型行业中。 通常,此类决策是由管理专家做出的:基于对城市,行业和以前的经验的了解。
在本文中,我将讨论分析如何帮助做出这样的决定。 如何收集有关人口,房地产价格的信息并进行交互式可视化。 客户数量是否取决于与分支机构的距离,房屋的建造年份以及物业的价值。
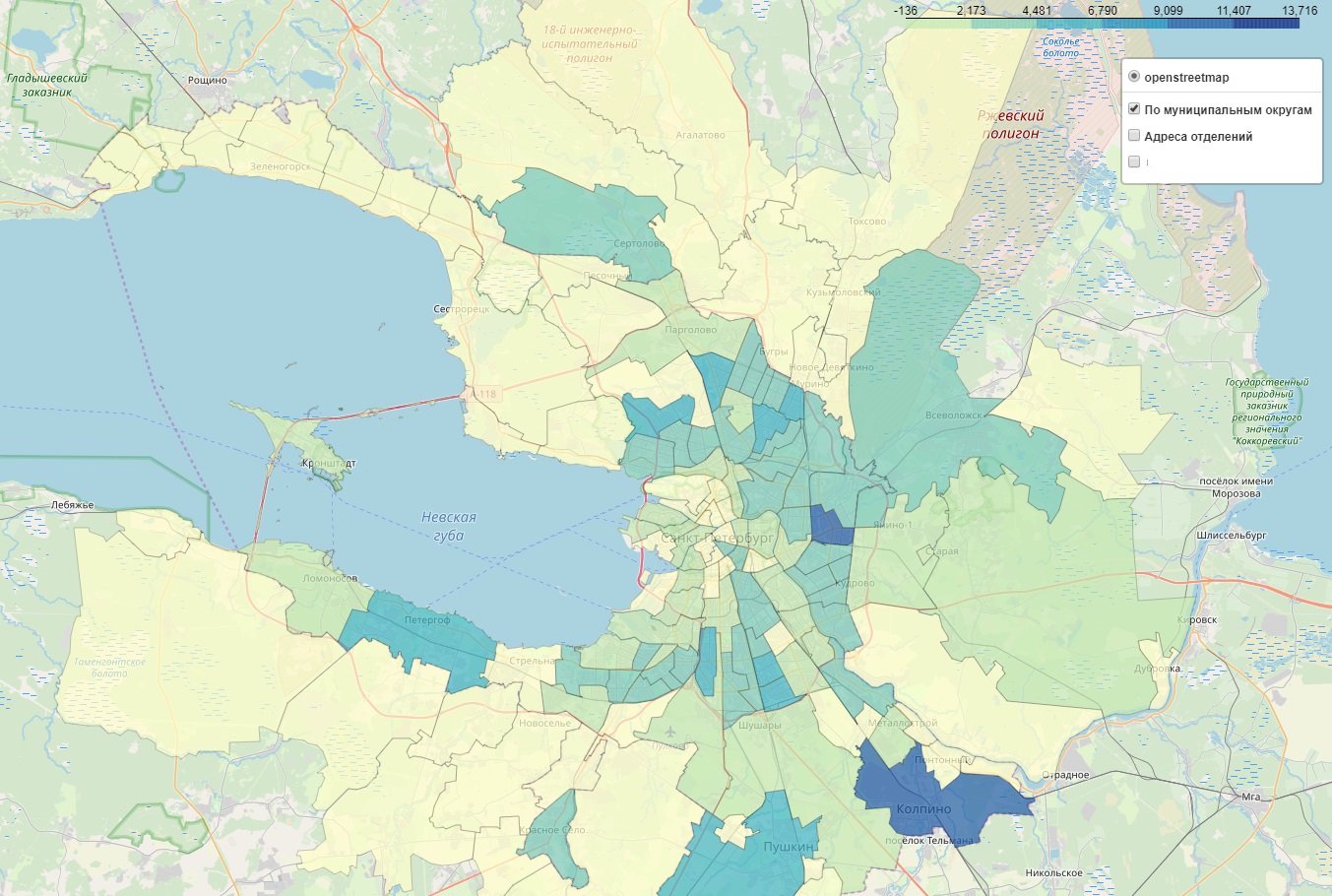
城市人口准确到家

为了评估房屋的人口,我们使用了
住房和公共服务改革的数据。 在此门户网站上,您可以获取有关每栋房屋的信息:建造年份,居住面积,房屋数量。 每所房屋的人口估算基于公寓的数量和总居住面积:平均每间公寓约3人,某些房屋和市政区略有差异。
上面是圣彼得堡人口密度的热点地图。 我们的内部使用卡还包含一个单独的层,可以满足客户的需求。 查找白点(覆盖率低的地方)更方便。
客户地址
由于业务的特定性,我们在数据库中几乎为所有客户提供了地址。 仅需要找到每个地址的地理坐标:地理编码或地理编码。 为了获得坐标,我使用了适用于python的geocoder软件包。 地理编码期间发生以下问题:
- 一些地址不正确,例如,大小写或字母混乱。 在这种情况下,地理编码可以将客户“放置”在幼儿园或办公楼中。 对于这种情况,我必须编写一个过程,将坐标更改为200 m以内的最近住宅建筑。
- 客户数量异常高的点:市中心,大街道中间,地区中间。 此类坐标是使用错误填写的地址获得的,并且可能使整体图片变形,因此,在建模之前,应将其删除
结果,我们为93%的客户获得了房屋的确切坐标。 现在您可以构建这样的地图:
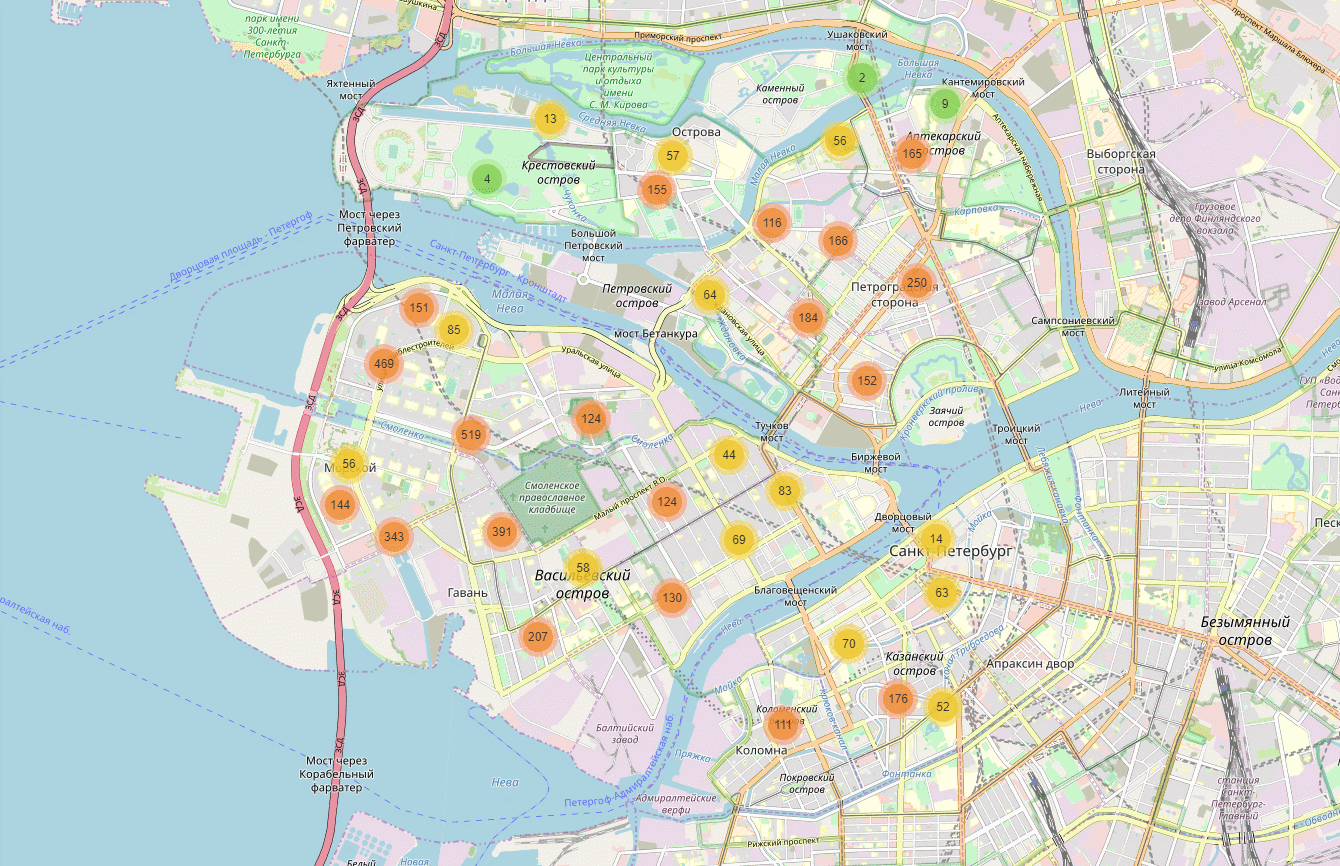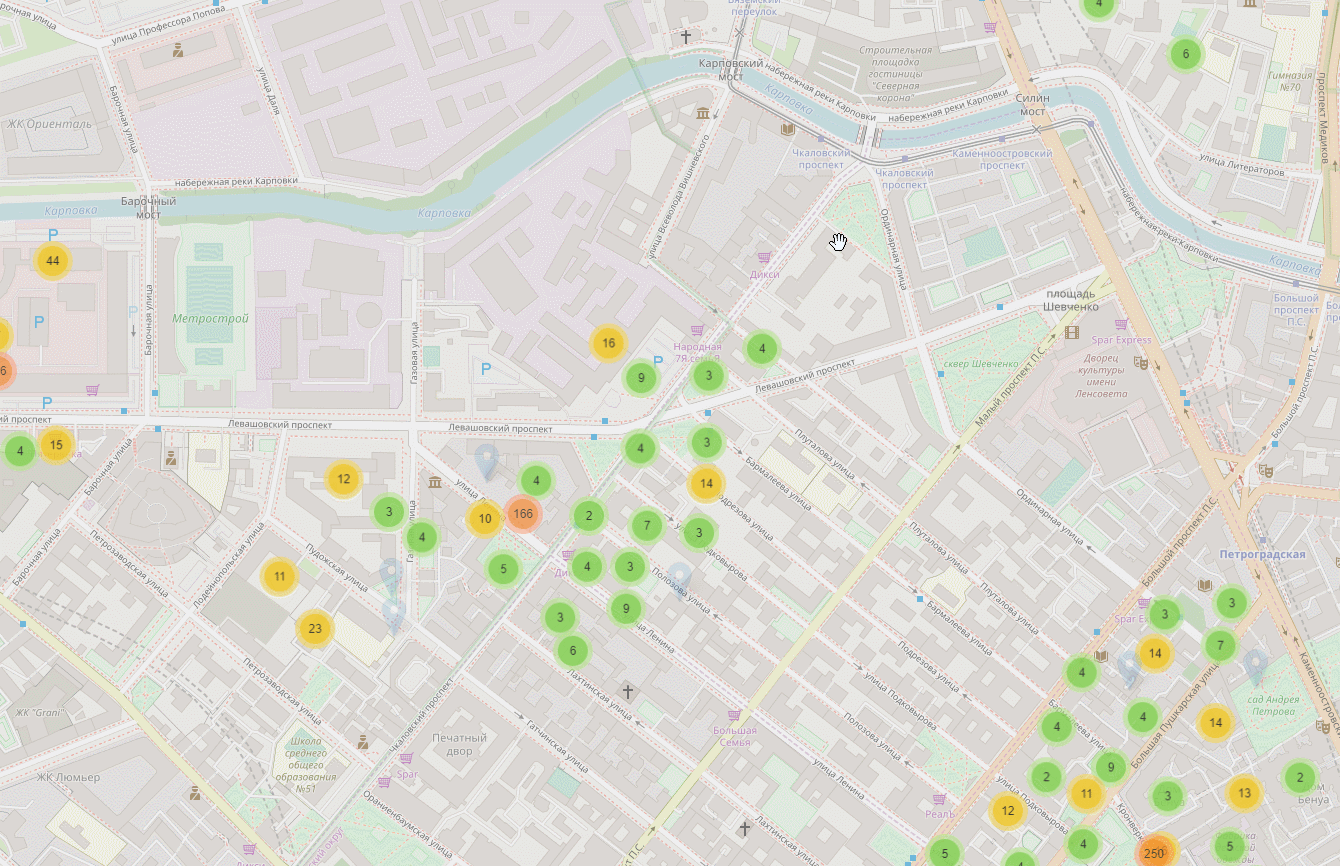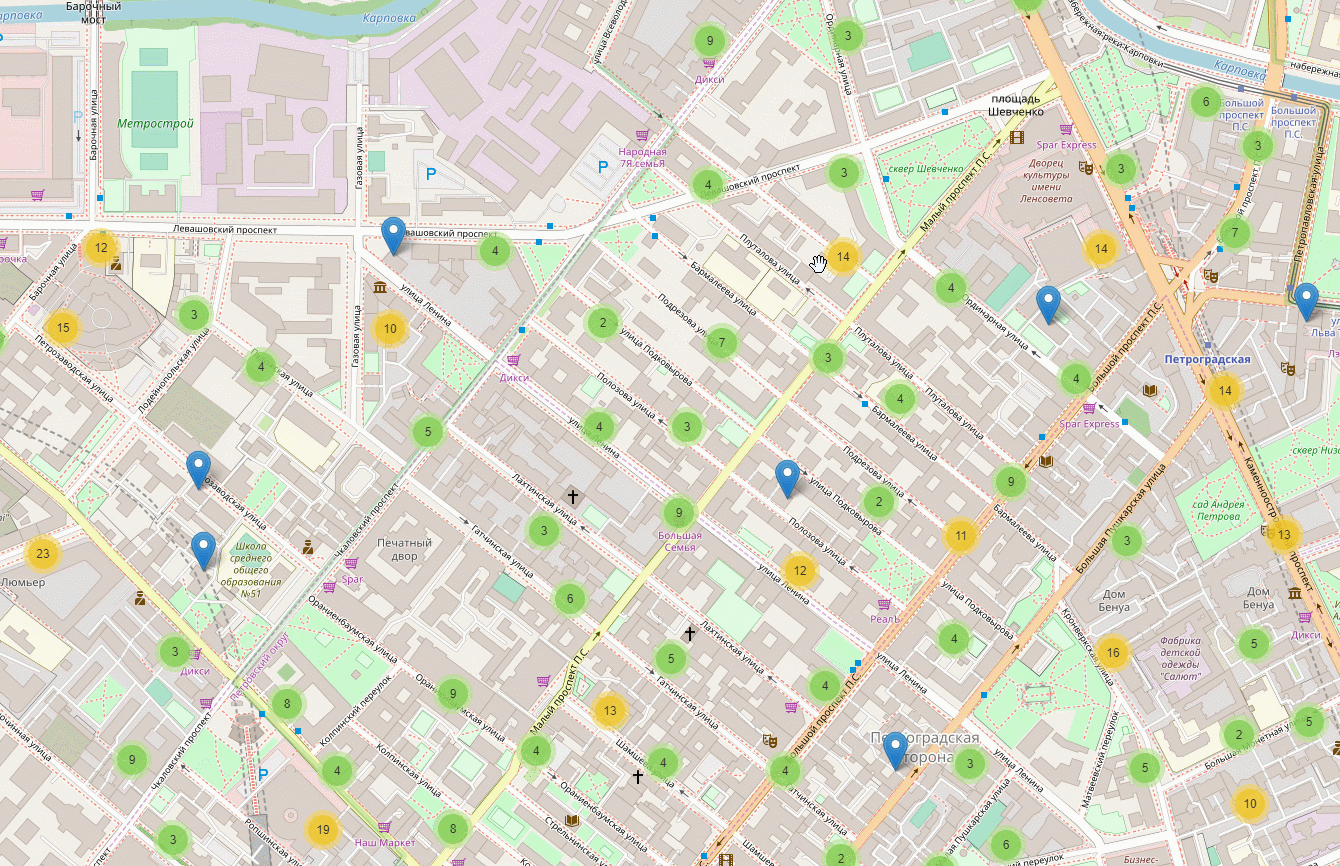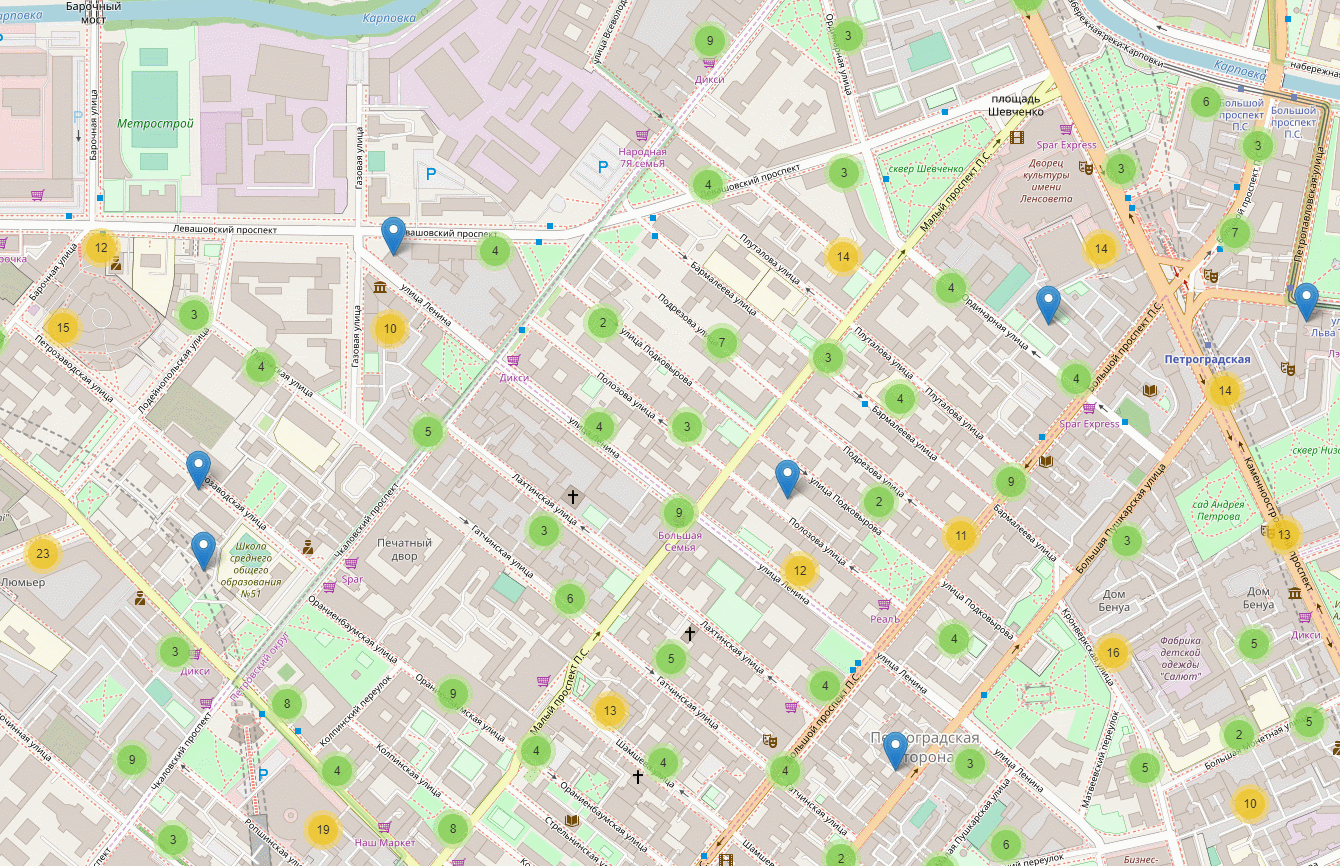 圣彼得堡部分地区的地图上绘制了随机数据。
圣彼得堡部分地区的地图上绘制了随机数据。创建地图的代码 import pandas as pd import folium from folium.plugins import MarkerCluster
事实证明,这样的地图是检验假设的便捷工具。 例如,企业有一个假设,即在某些类型的房屋(苏联大型建筑:船舶,504系列,赫鲁晓夫等)中,将没有我们的客户。 事实证明,这并非完全正确。 是的,在这类房屋中,来自人口的客户比例很低。 但是,由于城市中有很多此类房屋,因此需要考虑到它们,因此它们最多可提供20%的客户流量。
市政区的边界
您可以按市政区重新排列上一部分中的人口和客户数据,并进行映射。 如果添加信息窗口和自定义的颜色,结果将非常有用。 集线器上已有一篇出色的
文章 ,其中的步骤说明了如何构建此类卡。

物业价值
确定房地产价格已被证明是一项艰巨的任务。 在第一阶段,我们设法从2018年初开始获得所有用于房地产销售的广告-这大约是70万条记录。
对于每座房屋,每平方米的成本均以广告的中位数计算。 对于20%没有广告的房屋,我们估算了平方英尺的成本。 m。使用模型。 主要因素是每平方米的价格。 m 15最近的房子。 同时,具有类似特征的房屋的权重也更高:建造年份,居民数量,项目类型。 测试集上模型的平均误差为9.5%,这对于我们的研究是可以接受的。 尤其是当您考虑到即使在一所房子中的成本也达到平方米时。 m。差异很大:地板,维修,面积和其他因素。
到家的距离
4个部门的图表显示了房屋中客户比例与部门距离的依赖关系。 在某些分支机构中,存在很大的飞跃,这表明了其他因素(房屋的年龄,房地产价格)的影响。

在家年龄
有趣的是房屋建造年份与客户比例之间的关系。

为了进一步建模,房屋的年龄分为5个有意义的类别:
每平方米价格 米
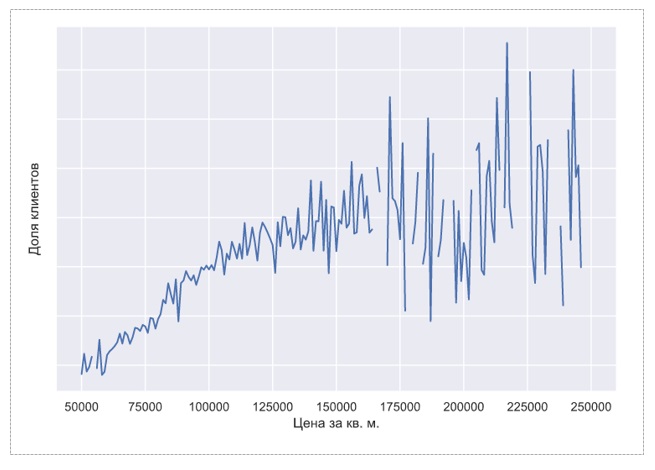
价格与客户份额相关。 但是这种关系比顾客的比例和房屋的年龄之间的关系弱。 也许原因是房屋的年龄与居民的年龄有关。 一个人的年龄极大地影响了医疗服务的请求频率。
型号说明
随后,此分析发展成为一个完整的模型,在输入中提供坐标,在输出中获得新客户的访问次数。 文章篇幅如此之多,因此我将简要讨论该模型。
为了便于解释结果,选择了线性回归作为模型。 目标变量是房屋中的客户比例,这些因素包括:到最近办公室的距离的对数,房屋成本,房屋建造年份。 这三个因素都非常重要,并进入了模型。
将新坐标替换为这样的模型(即,将距离因子更改为最近的分支),在输出中,我们得到整个网络的新客户端数量。 如果我们从这个数字中减去之前的客户数量,我们将获得净效果。
通过考虑当前分支的位置来选择新位置,可以方便地说明问题。 也就是说,没有必要另外考虑不同部门之间的“蚕食”因素。
通过每500 m进行一次简单的坐标枚举来搜索整个城市的最佳点,为计算开设多个分支机构的效果,依次设置了点。
结果
我们设法替换了墙上的地图,在上面我们手动绘制了区域的边界并在方便的交互式地图上阅读了一些东西。 避免员工手动更正和匹配数千个地址与市政区。 丰富数据,从市政区到每个房屋。
事实证明,可以找到几个非常有希望且不太明显的放置位置。 建立自动公正地比较不同点的模型。
将业务线分为“地域依赖性”和“地域无关”时,获得了有趣的结果。 前者应该是新分支的一部分,后者可以在当前位置的框架内发展。
(本文未介绍) 。