大家好,我想与公众分享一定数量的信息,在我看来,这在互联网上很难找到。
什么是树,请参阅
Wikipedia 。
 图1树的示例。
图1树的示例。那么,为什么还要在多个线程中遍历树呢? 就我而言,这是需要在磁盘上搜索文件。 显然,磁盘实际上是在一个流中工作的,但是,如果单个流在多级层次结构中搜索文件,并且所需文件位于一个级别的相邻文件夹中,则多线程文件搜索可以提供加速。 使用多线程搜索的相关性也证明了它在许多成功的商业产品中的实现。 我不排除该算法应用程序的其他变体是可能的,请在评论中写下。
首先,我建议考虑动画:
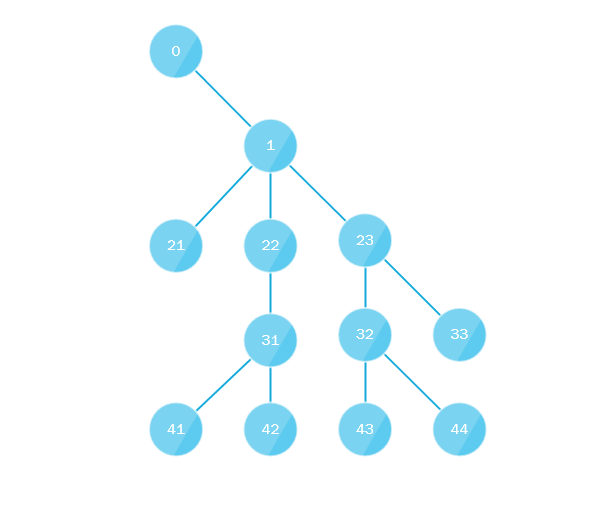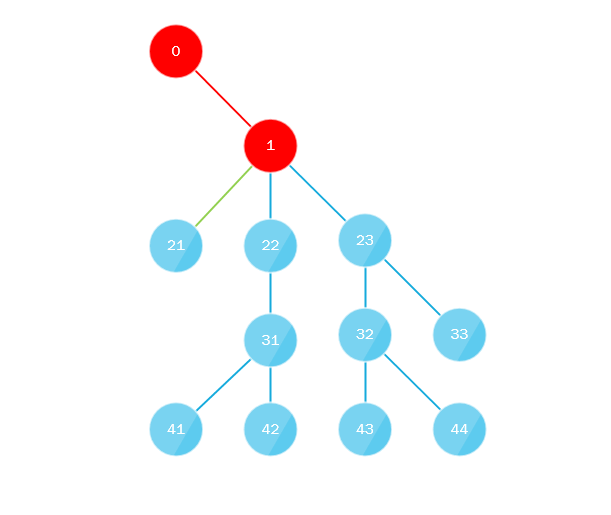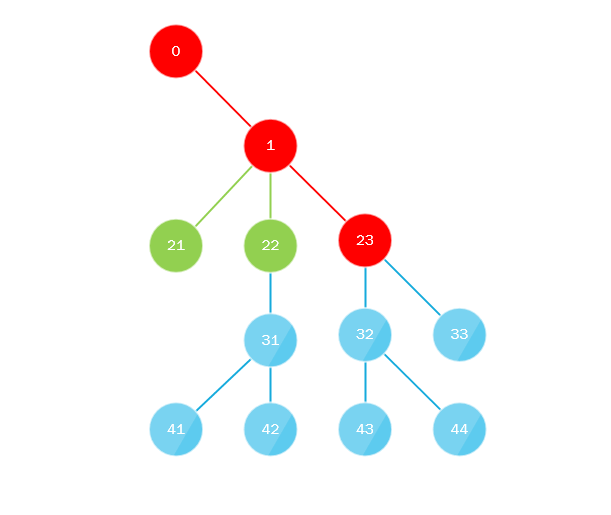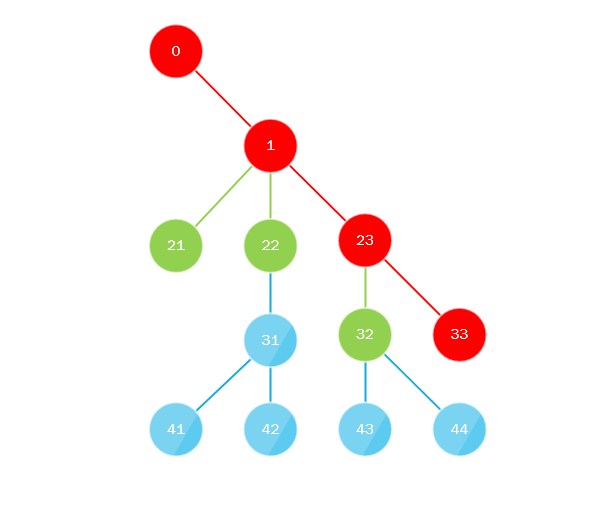
这是怎么回事 该算法的全部实质是:
- 第一条流沿着“极左”路径从树根到整个深度绕过树,即 向内移动时,总是向左移动,换句话说,总是选择最后一个子节点。
- 并行地,第一个线程收集所有丢失的子节点,然后将它们发送到队列(或堆栈),另一个线程将其接收,该队列或堆栈必须实现多线程方法,然后算法重复执行,用刚取的节点代替根节点。
实际上,通常,该算法如下所示(一种颜色-一种线程):
实际上,通常,该算法如下所示(一种颜色-一种线程):

Java软件实施
我举了一个可能对某人有用的代码示例,我搜索了很长时间,但没有找到它:
import java.io.File; import java.util.concurrent.BlockingQueue; import java.util.concurrent.Executor; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingDeque; public class MultiThreadTreeWalker extends Thread { private static BlockingQueue<File> nodesToReview = new LinkedBlockingDeque<>(); private File f; public MultiThreadTreeWalker(File f) { this.f = f; } public MultiThreadTreeWalker() { } public static void main(String[] args) { Executor ex = Executors.newFixedThreadPool(2); MultiThreadTreeWalker mw = new MultiThreadTreeWalker(new File("C:\\")); mw.run(); for (int i = 0;i<2;i++) { ex.execute(new MultiThreadTreeWalker()); } } @Override public void run() { if (f != null) {
结论
如您所见,Java中的多线程可以非常简单地通过BlockingQueue来实现,BlockingQueue是一种数据结构,提供对存储数据的多个线程的访问。
简而言之,总而言之,就是就存在其他哪些方法或树遍历方法发表评论,我想听听上师对这个问题的看法。 写问题,祝愿。
链接到GitHub 。 附近还有一个JavaFX搜索引擎,如果有人要测试,我将非常高兴。