对于刚刚开始构建机器学习系统的开发团队来说,重要的是什么? 利用集成和单元测试的体系结构,组件,测试功能,可以制作原型并获得第一批结果。 并进一步评估劳动力投入,规划制定和实施。
本文将重点介绍原型。 与产品经理交谈后的某个时间创建了哪个:我们为什么不“接触”机器学习? 特别是NLP和情绪分析?
“为什么不呢?” 我回答了。 不过,我从事后端开发已经超过15年,我喜欢处理数据并解决性能问题。 但是我仍然不得不找出“兔子洞有多深”。
选择组件
为了以某种方式概述实现ML核心逻辑的组件集,让我们看一个简单的情感分析实现示例,它是GitHub上可用的众多示例之一。
Python中情感分析的一个示例import collections import nltk import os from sklearn import ( datasets, model_selection, feature_extraction, linear_model ) def extract_features(corpus): '''Extract TF-IDF features from corpus'''
解析这样的示例对于开发人员是一个单独的挑战。
一次只有45行代码,并且一次有4个(四个,Karl!)逻辑块:
- 下载数据以进行模型训练(第25-26行)
- 准备上传的数据-特征提取(第31-34行)
- 创建和训练模型(第36-39行)
- 测试训练好的模型并输出结果(第41-45行)
这些要点中的每一个都应单独撰写。 当然,它需要在单独的模块中注册。 至少出于单元测试的需要。
另外,值得重点介绍数据准备和模型训练的组成部分。
在使模型更精确的每种方式中,投入了数百小时的科学和工程工作。
幸运的是,为了快速开始使用NLP,有一个现成的解决方案
-NLTK和
TextBlob库 。 第二个是NLTK的包装程序,它很繁琐-从训练集中提取特征,然后根据第一个分类请求训练模型。
但是在训练模型之前,您需要为其准备数据。
准备资料
下载资料
如果我们谈论原型,那么从CSV / TSV文件加载数据是基本的。 您只需从pandas库调用
read_csv函数:
import pandas as pd data = pd.read_csv(data_path, delimiter)
但是,该数据将无法在模型中使用。
首先,如果我们稍微忽略csv格式,那么很容易期望每个源都将提供具有其自身特征的数据,因此我们需要进行一些与源相关的数据准备工作。 即使是最简单的CSV文件,要解析它,我们也需要知道定界符。
此外,您应该确定哪些条目为正,哪些条目为负。 当然,此信息在我们要使用的数据集的批注中指示。 但是事实是,在一种情况下pos / neg的符号是0或1,在另一种情况下它是逻辑上的True / False,在第三种情况下只是pos / neg字符串,在某些情况下是从0到5的整数元组后者与多类分类的情况有关,但是谁说这样的数据集不能用于二进制分类呢? 您只需要适当地标识正值和负值的边界即可。
我想在不同的数据集上尝试该模型,并且要求训练后,该模型以一种单一格式返回结果。 为此,应将其异构数据统一化。
因此,在数据加载阶段我们需要三个功能:
- 与数据源的连接是针对CSV的,在我们的示例中,它是在read_csv函数内部实现的;
- 支持格式功能;
- 初步数据准备。
这就是它在代码中的外观。
import numpy as np
制作了类
CsvSentimentDataLoader ,该类在构造函数中传递给csv的路径,分隔符,文本名称和分类属性以及建议文本为正值的值列表。
加载本身发生在
load_data方法中。
我们将数据分为测试集和训练集
好的,我们上传了数据,但是我们仍然需要将其划分为训练集和测试集。
这是通过
sklearn库中的
train_test_split函数完成的。 此函数可以采用很多参数作为输入,从而确定将此数据集准确分为训练和测试的程度。 这些参数会极大地影响最终的训练和测试集,对于我们来说,创建一个类(将其称为SimpleDataSplitter)来管理这些参数并将该函数的调用汇总起来可能会很方便。
from sklearn.model_selection import train_test_split
现在,此类包括最简单的实现,将其划分时将仅考虑一个参数-应将其视为测试集的记录百分比。
数据集
为了训练模型,我使用了CSV格式的免费可用数据集:
为了更加方便,我为每个数据集创建了一个类,该类从相应的CSV文件加载数据并将其分为训练集和测试集。
import os import collections import logging from web.data.loaders import CsvSentimentDataLoader from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter log = logging.getLogger() class AmazonAlexaDataset(): def __init__(self): self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv')) self.delim = '\t' self.text_attr = 'verified_reviews' self.rate_attr = 'feedback' self.pos_rates = [1] self.data = None self.train = None self.test = None def load_data(self): loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates) splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3) self.data = loader.load_data() x_train, x_test, y_train, y_test = splitter.split_data(self.data) self.train = [x for x in zip(x_train, y_train)] self.test = [x for x in zip(x_test, y_test)]
是的,对于数据加载,原始示例中的代码多于5行。
但是现在,可以通过处理数据源和训练集准备算法来创建新的数据集。
另外,单个组件对于单元测试更加方便。
我们训练模型
该模型已经学习了一段时间。 并且必须在应用程序启动时执行一次。
为此,我们制作了一个小型包装程序,使您可以下载和准备数据,以及在应用程序初始化时训练模型。
class TextBlobWrapper(): def __init__(self): self.log = logging.getLogger() self.is_model_trained = False self.classifier = None def init_app(self): self.log.info('>>>>> TextBlob initialization started') self.ensure_model_is_trained() self.log.info('>>>>> TextBlob initialization completed') def ensure_model_is_trained(self): if not self.is_model_trained: ds = SentimentLabelledDataset() ds.load_data()
首先获得训练和测试数据,然后进行特征提取,最后训练分类器并检查测试集的准确性。
测试中
初始化后,我们将获得一个日志,以判断是否已下载数据并成功训练了模型。 并以非常高的精度(对于初学者)进行了培训-0.8878。
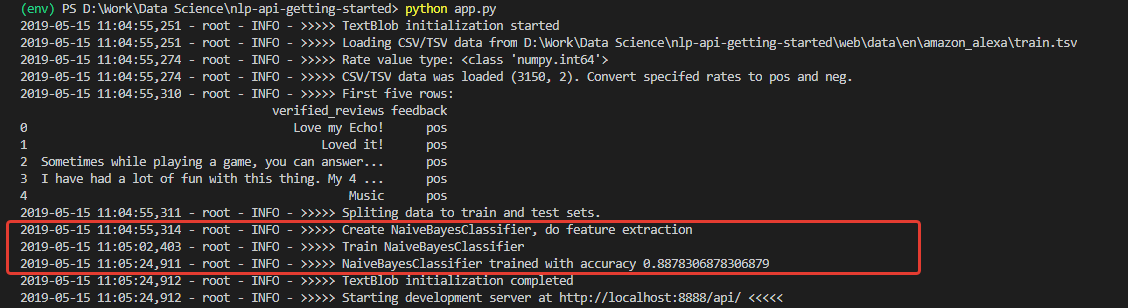
收到了这样的数字后,我非常热心。 但是不幸的是,我的喜悦并不长。 在这组模型上训练的模型是坚不可摧的乐观主义者,原则上不能识别负面评论。
原因是在训练集数据中。 该集中的正面评论数量超过90%。 因此,模型的准确性约为88%,否定性评论只会落入预期错误分类的12%。
换句话说,使用这样的训练集,根本不可能训练模型来识别负面评论。
为了真正确保这一点,我进行了单元测试,该测试分别针对另一个数据集的100个肯定短语和100个否定短语运行分类-为进行测试,我从加利福尼亚大学获得了
Sentiment Labeled Sentences Data Set 。
@loggingtestcase.capturelogs(None, level='INFO') def test_classifier_on_separate_set(self, logs): tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset ds = SentimentLabelledDataset() # Test dataset ds.load_data() # Check poisitives true_pos = 0 data = ds.data.to_numpy() seach_mask = np.isin(data[:, 1], ['pos']) data = data[seach_mask][:100] for e in data[:]: # Model train will be performed on first classification call r = tb.do_sentiment_classification(e[0]) if r == e[1]: true_pos += 1 self.assertLessEqual(true_pos, 100) print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
测试正值分类的算法如下:
- 下载测试数据;
- 接受100个标记为“ pos”的帖子
- 我们通过模型运行它们中的每一个并计算正确结果的数量
- 在控制台中显示最终结果。
类似地,对否定评论进行计数。
不出所料,所有负面评论均被确认为正面。
而且,如果您在用于测试的数据集上训练模型-
感叹标签 ? 在那里,负面和正面评论的分布恰好是50到50。
已经有东西了 来自第三方集的200个条目的实际准确性为76%,而否定评论的分类准确性为79%。
当然,有76%的人会为原型做准备,但不足以进行生产。 这意味着将需要采取其他措施来提高算法的准确性。 但这是另一个报告的主题。
总结
首先,我们得到了一个具有十几个类和200余行代码的应用程序,比原始示例多了30行。 您应该诚实-这些只是结构的暗示,是对未来应用程序边界的首次阐明。 原型。
从机器学习专家和传统应用程序开发人员的角度来看,该原型使实现代码方法之间的距离成为可能。 我认为,这是决定尝试机器学习的开发人员的主要困难。
接下来可能会使初学者陷入僵局的事情-数据的重要性不亚于所选模型。 这已经清楚地表明了。
此外,在某些数据上训练的模型总是有可能在其他数据上显示不充分,或者在某些时候其准确性将开始下降。
因此,需要指标来监控模型的状态,使用数据时的灵活性以及调整动态学习的技术能力。 依此类推。
对于我来说,在设计体系结构和构建开发过程时应考虑所有这些因素。
通常,“兔子洞”不仅很深,而且还非常巧妙地铺设了。 但是对于我(作为开发人员)来说,将来研究此主题更加有趣。