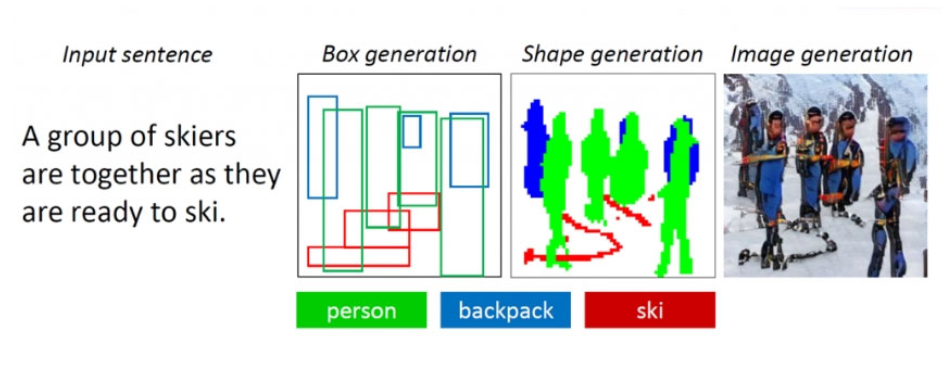
研究小组Microsoft Research 引入了一种生成竞争性神经网络,该网络能够基于文本描述生成具有多个对象的图像。 与早期的类似的只能生成基本对象的图像的文本到图像算法不同,该神经网络可以更有效地处理复杂的描述。
创建这种算法的复杂性在于,首先,在机器人无法根据其描述高质量地重新创建所有基本对象之前,其次,它无法分析多个对象之间如何相互关联。在一个组成内。 例如,要根据描述“戴头盔的女人坐在马上”创建图像,神经网络必须在语义上“理解”每个对象之间的关系。 我们设法通过训练基于COCO开放数据集的神经网络来解决这些问题,该数据集包含150万个对象的标记和分段数据。

该算法基于面向对象的生成竞争性神经网络ObjGAN(对象驱动的注意力生成对抗性Newtorks)。 她分析文本,从中提取需要放置在图像上的单词对象。 与传统的生成对抗网络不同,传统的生成对抗网络由一个生成图像的生成器和一个评估生成图像质量的鉴别器组成,而ObjGAN包含两个不同的鉴别器。 有人分析了每个复制对象的真实性以及与现有描述的匹配程度。 第二个因素确定整个构图与文本之间的关联性。
ObjGAN算法的前身是AttnGAN,它也是由Microsoft研究人员开发的。 它能够根据更简单的文字描述生成对象的图像。 将文本转换为图像的技术可用于帮助设计师和艺术家创建草图。
ObjGAN算法可在GitHub上公开获得。
更多技术细节。