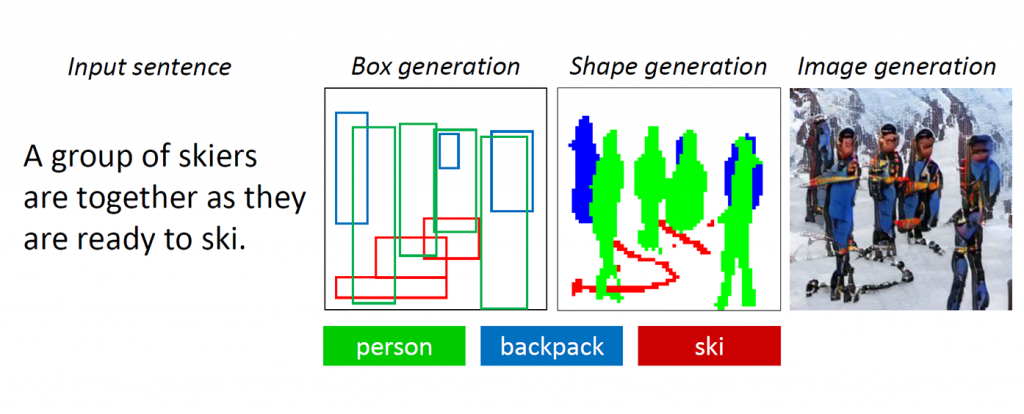
如果您被要求在雪地上画几个滑雪者的照片,那么您可能会先从三四个人的轮廓开始,然后将它们合理地定位在画布的中心,然后在滑雪者的下方素描脚。 尽管未指定,但您可能会决定向每个滑雪者添加一个背包,以期对滑雪者的运动有所期待。 最后,您将仔细地填写细节,也许将他们的衣服涂成蓝色,围巾变成粉红色,并且都以白色为背景,使这些人更真实,并确保其周围环境与描述相符。 最后,为了使场景更加生动,您甚至可以草绘一些穿过雪地的棕色石头,以表明这些滑雪者在山上。
现在有一个机器人可以做到所有这些。
Microsoft Research AI正在开发的新AI技术可以理解自然的语言描述,绘制图像的布局,合成图像,然后根据布局和所提供的各个单词来细化细节。 换句话说,该机器人可以从类似于字幕的日常场景文字描述中生成图像。 根据“ 对象驱动的文字广告”中报告的行业标准测试结果,与较早的用于复杂日常场景的文字到图片生成的最新技术相比,这种故意的机制大大提高了生成的图片质量。 通过对抗训练进行图像合成 ”,本月在加利福尼亚州长滩举行的2019年IEEE计算机视觉和模式识别会议 (CVPR 2019)上发表。 这是Microsoft Research AI的 张鹏川 , 黄秋元和高建峰 , Microsoft的 Zhang Lei ,JD AI Research的何晓东以及纽约州立大学奥尔巴尼分校的李文博和吕思玮(李文博担任Microsoft Research AI的实习生)。
基于描述的绘图机器人问题固有两个主要挑战。 首先是许多物体可以出现在日常场景中,并且机器人应该能够理解并绘制所有物体。 以前的文本到图像生成方法使用图像标题对,它们仅提供非常粗糙的监督信号来生成单个对象,从而限制了它们的对象生成质量。 在这项新技术中,研究人员利用了COCO数据集,该数据集包含跨80个常见对象类的150万个对象实例的标签和分段图,从而使该机器人可以学习这些对象的概念和外观。 用于对象生成的细粒度监督信号显着提高了这些常见对象类的生成质量。
第二个挑战在于理解和生成一个场景中多个对象之间的关系。 在生成仅包含多个特定领域的一个主要对象的图像(例如人脸,鸟类和常见对象)方面已取得了巨大的成功。 但是,在文本到图像生成技术中,生成包含多个对象并在语义上具有有意义意义的关系的复杂场景仍然是一大挑战。 这个新的绘图机器人学会了从COCO数据集中的共现模式生成对象的布局,然后生成以预生成的布局为条件的图像。
对象驱动的注意力图像生成
Microsoft Research AI的绘图机器人的核心是一项称为“生成对抗网络”(GAN)的技术。 GAN由两个机器学习模型组成-一个从文本描述生成图像的生成器,以及一个使用文本描述来判断生成图像的真实性的鉴别器。 生成器试图使伪造的图片经过鉴别器; 另一方面,歧视者从不希望被愚弄。 鉴别器共同作用,将发生器推向完美。
该绘图机器人在100,000个图像的数据集上进行了训练,每个图像上都带有显着的对象标签和分割图以及五个不同的标题,从而使模型可以构思单个对象以及对象之间的语义关系。 例如,GAN可以在比较带有和不带有狗描述的图像时,了解狗的外观。

图1:具有多个对象和关系的复杂场景。
当生成仅包含一个重要物体(例如人脸,鸟或狗)的图像时,GAN可以很好地工作,但是高质量的图像会停滞在更复杂的日常场景中,这种场景被描述为“戴头盔的女人骑着马”(见图) 1.)这是因为这样的场景包含多个对象(女人,头盔,马)和它们之间的丰富语义关系(女人戴头盔,女人骑马)。 机器人首先必须理解这些概念,并以有意义的布局将它们放置在图像中。 此后,需要一种能够指导对象生成和布局生成的更加监督的信号,以完成此语言理解和图像生成任务。
当人们绘制这些复杂的场景时,我们首先通过在画布上放置这些对象的边界框来确定要绘制的主要对象并进行布局。 然后,我们通过反复检查描述该对象的相应单词来关注每个对象。 为了捕捉这种人类特质,研究人员创建了他们所谓的“对象驱动的专注GAN”或“ ObjGAN”,以数学方式模拟了以对象为中心的注意力的人类行为。 ObjGAN通过将输入文本分解为单个单词并将这些单词与图像中的特定对象进行匹配来实现。
人们通常会检查两个方面来完善绘图:单个对象的真实感和图像斑块的质量。 ObjGAN还通过引入两个鉴别器来模仿此行为:一个是面向对象的鉴别器,一个是基于补丁的鉴别器。 逐个对象的鉴别器试图确定所生成的对象是否现实,以及该对象是否与句子描述一致。 逐个补丁的鉴别器试图确定此补丁是否现实,以及该补丁是否与句子描述一致。
相关工作:故事可视化
最新的文本到图像生成模型可以基于单句描述生成逼真的鸟图像。 但是,文本到图像的生成远远超出了基于一个句子合成单个图像的范围。 在“ StoryGAN:用于故事可视化的顺序条件GAN ”中,Microsoft Research的高建峰 ,Microsoft Dynamics 365 AI Research的甘哲,刘晶晶和Yu Cheng,杜克大学的Yiyi Li,David Carlson和Lawrence Carin,沉业龙腾讯AI Research的研究人员和卡耐基梅隆大学的Wu Yuexin Wu进一步提出了一项新的任务,称为“故事可视化”。 给定一个多句子段落,可以将整个故事可视化,生成一系列图像,每个句子一个。 这是一项艰巨的任务,因为绘图机器人不仅需要想象一个适合故事的场景,为故事中出现的不同角色之间的交互建模,而且还必须能够在动态场景和角色之间保持全局一致性。 任何单一的图像或视频生成方法都没有解决这一挑战。
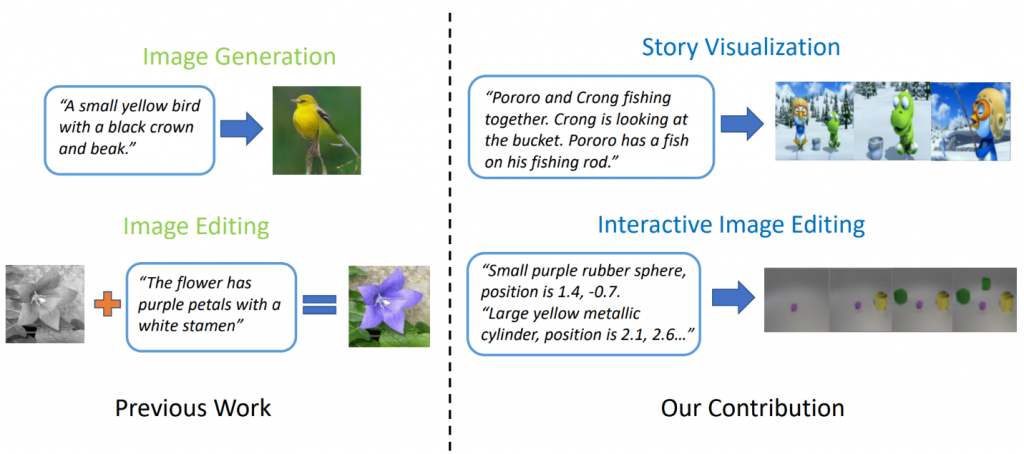
图2:故事可视化与 简单的图像生成。
研究人员基于顺序条件GAN框架提出了一个新的故事到图像序列生成模型StoryGAN。 该模型的独特之处在于它包括一个动态跟踪故事流程的深层上下文编码器,以及故事和图像级别的两个鉴别器,以增强图像质量和所生成序列的一致性。 StoryGAN还可以自然扩展为交互式图像编辑,其中可以根据文本指令顺序编辑输入图像。 在这种情况下,一系列的用户指令将用作“故事”输入。 因此,研究人员修改了现有数据集以创建CLEVR-SV和Pororo-SV数据集,如图2所示。
实际应用-一个真实的故事
文本到图像的生成技术可以找到实际的应用程序,充当画家和室内设计师的素描助手,或者用作声控照片编辑的工具。 研究人员可以想象,凭借更高的计算能力,该技术可以根据电影剧本生成动画电影,从而消除了一些人工劳动,从而使动画电影制片人的工作更加丰富。
目前,生成的图像距离照片逼真还很远。 单个物体几乎总会显示出瑕疵,例如模糊的面孔和/或形状失真的公共汽车。 这些缺陷清楚地表明,不是计算机,而是由计算机创建图像。 尽管如此,ObjGAN图像的质量明显优于以前的同类最佳GAN图像,并且是通向增强人类能力的类人通用智能道路上的里程碑。
为了使AI和人类共享同一个世界,彼此之间必须有一种相互交流的方式。 语言和视觉是人机交互的两个最重要的方式。 文本到图像的生成是推进语言视觉多模式智能研究的一项重要任务。
创造了这项激动人心的工作的研究人员期待与长滩CVPR的与会者分享这些发现,并听听您的想法。 同时,请随时在GitHub上查看其针对ObjGAN和StoryGAN的开源代码