大家身体健康!
在大学里教学生开发用于微控制器的嵌入式软件时,我使用C ++,有时我会给对各种任务特别感兴趣的学生找出有特殊头痛的天才学生。
再一次,此类学生的任务是使用C ++ 17语言和标准C ++库使4个LED闪烁,而无需连接其他库,例如CMSIS及其带有寄存器结构描述的头文件,等等。 ROM中的内存将是最小的大小和最少的RAM。 编译器优化不应高于中级。 IAR编译器8.40.1。
获胜者
前往Canary,获得5分考试。
我自己之前也没有解决过这个问题,因此,我将告诉您学生如何解决该问题以及发生了什么事。 我立即警告您,此类代码不太可能在实际应用中使用,这就是为什么我将出版物发布在“异常编程”部分中的原因,尽管谁知道。
任务条件
端口GPIOA.5,GPIOC.5,GPIOC.8,GPIOC.9上有4个LED。 他们需要眨眼。 为了比较,我们使用了用C编写的代码:
void delay() { for (int i = 0; i < 1000000; ++i){ } } int main() { for(;;) { GPIOA->ODR ^= (1 << 5); GPIOC->ODR ^= (1 << 5); GPIOC->ODR ^= (1 << 8); GPIOC->ODR ^= (1 << 9); delay(); } return 0 ; }
这里的
delay()函数纯粹是形式上的,有规律的循环,无法对其进行优化。
假定端口已经配置为输出,并且已对其应用时钟。
我还要立即说,bitbanging并不是用来使代码可移植的。
中等优化时,此代码在堆栈上占用8个字节,在ROM中占用256个字节
255个字节的只读代码存储器
1字节的只读数据存储器
8字节的读写数据存储器
由于部分内存位于中断向量表之下,调用IAR函数以初始化浮点块,各种调试函数和__low_level_init函数(端口本身已在其中配置)的事实,因此为255个字节。
因此,完整的要求是:
- main()函数应包含尽可能少的代码
- 您不能使用宏
- IAR 8.40.1编译器支持C ++ 17
- CMSIS头文件,例如“ #include” stm32f411xe.h“
- 您可以将__forceinline指令用于内联函数
- 中等编译器优化
学生决定
总的来说,有几种解决方案,我只会展示一种……这不是最佳方案,但我很喜欢。
由于无法使用标题,因此学生要做的第一件事是
Gpio类,该类应在其地址处存储指向端口寄存器的链接。 为此,他们使用结构叠加层,很可能是从这里得到的想法:
结构叠加层 :
class Gpio { public: __forceinline inline void Toggle(const std::uint8_t bitNum) volatile { Odr ^= bitNum ; } private: volatile std::uint32_t Moder; volatile std::uint32_t Otyper; volatile std::uint32_t Ospeedr; volatile std::uint32_t Pupdr; volatile std::uint32_t Idr; volatile std::uint32_t Odr;
如您所见,他们立即识别了
Gpio类,该类具有应位于相应寄存器的地址处的属性,以及一种通过分支数来切换状态的方法:
然后,我们确定了
GpioPin的结构,
GpioPin包含指向
Gpio的指针和支脚的编号:
struct GpioPin { volatile Gpio* port ; std::uint32_t pinNum ; } ;
然后,他们在端口的特定分支上制作了一个LED阵列,并通过调用每个LED的
Toggle()方法来检查该LED:
const GpioPin leds[] = {{reinterpret_cast<volatile Gpio*>(GpioaBaseAddr), 5}, {reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 5}, {reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 9}, {reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 9} } ; struct LedsDriver { __forceinline static inline void ToggelAll() { for (auto& it: leds) { it.port->Toggle(it.pinNum); } } } ;
好吧,实际上是整个代码: constexpr std::uint32_t GpioaBaseAddr = 0x4002'0000 ; constexpr std::uint32_t GpiocBaseAddr = 0x4002'0800 ; class Gpio { public: __forceinline inline void Toggle(const std::uint8_t bitNum) volatile { Odr ^= bitNum ; } private: volatile std::uint32_t Moder; volatile std::uint32_t Otyper; volatile std::uint32_t Ospeedr; volatile std::uint32_t Pupdr; volatile std::uint32_t Idr; volatile std::uint32_t Odr; } ;
有关媒介优化的代码统计信息:
275个字节的只读代码存储器
1字节的只读数据存储器
8字节的读写数据存储器
一个很好的解决方案,但是需要很多内存:)
我的决定
当然,我决定不寻找简单的方法,而是严肃地采取行动:)。
LED位于不同的端口和不同的支脚上。 您需要做的第一件事是制作
Port类,但是要摆脱占用RAM的指针和变量,您需要使用静态方法。 端口类可能如下所示:
template <std::uint32_t addr> struct Port {
作为模板参数,它将具有端口地址。 例如,在
"#include "stm32f411xe.h" ,对于端口A,它定义为GPIOA_BASE。但是我们不允许使用这些头文件,因此我们只需要设置自己的常量即可。因此,可以像这样使用该类:
constexpr std::uint32_t GpioaBaseAddr = 0x4002'0000 ; constexpr std::uint32_t GpiocBaseAddr = 0x4002'0800 ; using PortA = Port<GpioaBaseAddr> ; using PortC = Port<GpiocBaseAddr> ;
要闪烁,您需要Toggle方法(const std :: uint8_t位),该方法将使用异或运算来切换所需的位。 该方法必须是静态的,将其添加到类中:
template <std::uint32_t addr> struct Port {
优秀的
Port<>是,它可以切换腿的状态。 LED位于特定的腿上,因此逻辑上要创建一个
Pin类,该类将以
Port<>和分支编号作为模板参数。 由于
Port<>类型是模板,即 对于不同的端口,我们只能传输通用类型T。
template <typename T, std::uint8_t pinNum> struct Pin { __forceinline inline static void Toggle() { T::Toggle(pinNum) ; } } ;
尽管假定我们只应传递
Port<>类型,但是我们不能传递任何具有
Toggle()方法的
T类型废话,这将是无效的。 为了防止这种情况的发生,我们将使
Port<>继承自
PortBase基类,并在模板中将验证传递的类型确实基于
PortBase 。 我们得到以下内容:
constexpr std::uint32_t OdrAddrShift = 20U; struct PortBase { }; template <std::uint32_t addr> struct Port: PortBase { __forceinline inline static void Toggle(const std::uint8_t bit) { *reinterpret_cast<std::uint32_t*>(addr ) ^= (1 << bit) ; } }; template <typename T, std::uint8_t pinNum, class = typename std::enable_if_t<std::is_base_of<PortBase, T>::value>>
现在,仅当我们的类具有基类
PortBase实例化模板。
从理论上讲,您已经可以使用这些类,让我们看看没有优化会发生什么:
using PortA = Port<GpioaBaseAddr> ; using PortC = Port<GpiocBaseAddr> ; using Led1 = Pin<PortA, 5> ; using Led2 = Pin<PortC, 5> ; using Led3 = Pin<PortC, 8> ; using Led4 = Pin<PortC, 9> ; int main() { for(;;) { Led1::Toggle(); Led2::Toggle(); Led3::Toggle(); Led4::Toggle(); delay(); } return 0 ; }
271个字节的只读代码存储器
1字节的只读数据存储器
24字节的读写数据存储器
RAM中额外的16个字节和ROM中16个字节从何而来。 它们来自以下事实:我们将bit参数传递给Port类的Toggle函数(const std :: uint8_t位),并且编译器在输入main函数时会在该参数通过的堆栈上保存4个其他寄存器,然后使用它们寄存器中存储了每个引脚的脚编号的值,并在离开主电源时从堆栈中恢复了这些寄存器。 而且,尽管从本质上讲这是某种完全没用的工作,但是由于这些函数是内置的,所以编译器的行为完全符合该标准。
您可以通过以下方法消除此问题:通常删除端口类,将端口地址作为
Pin类的模板参数传递,并在
Toggle()方法内部,计算ODR寄存器的地址:
constexpr std::uint32_t OdrAddrShift = 20U; template <std::uint32_t addr, std::uint8_t pinNum, struct Pin { __forceinline inline static void Toggle() { *reinterpret_cast<std::uint32_t*>(addr + OdrAddrShift ) ^= (1 << bit) ; } } ; using Led1 = Pin<GpioaBaseAddr, 5> ;
但是,这看起来不是很好,并且用户友好。 因此,我们希望编译器通过一些优化来消除这种不必要的寄存器保存。
我们对Medium进行优化,然后看到结果:
251个字节的只读代码存储器
1字节的只读数据存储器
8字节的读写数据存储器
哇哇...少了4个字节
代号255个字节的只读代码存储器
1字节的只读数据存储器
8字节的读写数据存储器
怎么会这样 让我们看一下调试器中的C ++代码(左)和C代码(右)的汇编器:
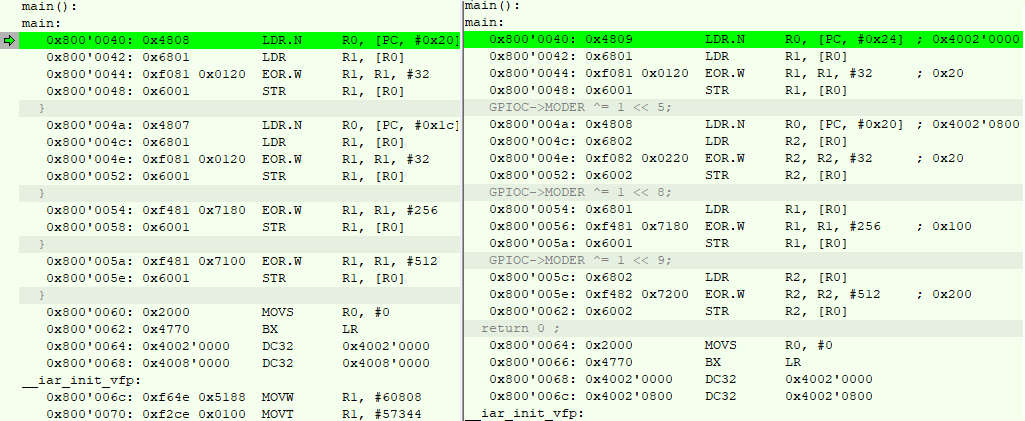
可以看出,首先,编译器内置了所有功能,现在根本没有调用,其次,它优化了寄存器的使用。 可以看出,在使用C代码的情况下,编译器使用R1或R2寄存器存储端口地址,并在每次切换该位时执行其他操作(将地址保存在R1或R2中的寄存器中)。 在第二种情况下,它仅使用R1寄存器,并且由于最后3个调用总是从端口C进行的,因此不再需要在寄存器中保存相同的端口C地址。 结果,节省了2个团队和4个字节。
这是现代编译器的奇迹:)好吧,好吧。 原则上,可以停在那里,但让我们继续前进。 我认为不可能优化其他任何东西,尽管可能不正确,如果您有想法,请在评论中写下。 但是有了main()中的大量代码,您就可以工作。
现在,我希望所有的LED都位于容器中的某个位置,您可以调用该方法,切换所有内容...像这样:
int main() { for(;;) { LedsContainer::ToggleAll() ; delay(); } return 0 ; }
我们不会愚蠢地将4个LED的开关插入到LedsContainer :: ToggleAll函数中,因为这并不有趣:)。 我们希望将LED放入容器中,然后对它们进行遍历并在每个LED上调用Toggle()方法。
学生使用数组存储指向LED的指针。 但是我有不同的类型,例如:
Pin<PortA, 5> ,
Pin<PortC, 5> ,并且我无法在数组中存储指向不同类型的指针。 您可以为所有Pin做一个虚拟的基础班,但是随后会出现一个虚拟功能表,我不会成功赢得学生。
因此,我们将使用元组。 它允许您存储不同类型的对象。 这种情况将如下所示:
class LedsContainer { private: constexpr static auto records = std::make_tuple ( Pin<PortA, 5>{}, Pin<PortC, 5>{}, Pin<PortC, 8>{}, Pin<PortC, 9>{} ) ; using tRecordsTuple = decltype(records) ; }
有一个很棒的容器,它存储所有LED。 现在向其中添加
ToggleAll()方法:
class LedsContainer { public: __forceinline static inline void ToggleAll() {
您不能只遍历元组的元素,因为元组元素只能在编译阶段接收。 要访问元组的元素,有一个模板get方法。 好吧 如果我们这样编写
std::get<0>(records).Toggle() ,则如果
std::get<1>(records).Toggle() ,则对类
Pin<PortA, 5>的对象调用
Toggle()方法。然后为类
Pin<Port, 5>的对象调用
Toggle()方法,依此类推...
您可以
擦拭学生的鼻子 ,只需写下:
__forceinline static inline void ToggleAll() { std::get<0>(records).Toggle(); std::get<1>(records).Toggle(); std::get<2>(records).Toggle(); std::get<3>(records).Toggle(); }
但是我们不想让支持该代码并允许他做更多工作的程序员费劲,例如在出现另一个LED的情况下,花掉他公司的资源。 您将不得不在元组和此方法的两个位置添加代码-这样做不好,并且公司所有者不会非常满意。 因此,我们使用辅助方法绕过元组:
class class LedsContainer { friend int main() ; public: __forceinline static inline void ToggleAll() {
它看起来很吓人,但我在文章开头警告说
shizany方法不是很普通...
在编译阶段,以上所有这些魔术实际上执行以下操作:
继续编译并检查代码大小,无需优化:
编译的代码 #include <cstddef> #include <tuple> #include <utility> #include <cstdint> #include <type_traits> //#include "stm32f411xe.h" #define __forceinline _Pragma("inline=forced") constexpr std::uint32_t GpioaBaseAddr = 0x4002'0000 ; constexpr std::uint32_t GpiocBaseAddr = 0x4002'0800 ; constexpr std::uint32_t OdrAddrShift = 20U; struct PortBase { }; template <std::uint32_t addr> struct Port: PortBase { __forceinline inline static void Toggle(const std::uint8_t bit) { *reinterpret_cast<std::uint32_t*>(addr + OdrAddrShift) ^= (1 << bit) ; } }; template <typename T, std::uint8_t pinNum, class = typename std::enable_if_t<std::is_base_of<PortBase, T>::value>> struct Pin { __forceinline inline static void Toggle() { T::Toggle(pinNum) ; } } ; using PortA = Port<GpioaBaseAddr> ; using PortC = Port<GpiocBaseAddr> ; //using Led1 = Pin<PortA, 5> ; //using Led2 = Pin<PortC, 5> ; //using Led3 = Pin<PortC, 8> ; //using Led4 = Pin<PortC, 9> ; class LedsContainer { friend int main() ; public: __forceinline static inline void ToggleAll() { // 3,2,1,0 , visit(std::make_index_sequence<std::tuple_size<tRecordsTuple>::value>()); } private: __forceinline template<std::size_t... index> static inline void visit(std::index_sequence<index...>) { Pass((std::get<index>(records).Toggle(), true)...); } __forceinline template<typename... Args> static void inline Pass(Args... ) { } constexpr static auto records = std::make_tuple ( Pin<PortA, 5>{}, Pin<PortC, 5>{}, Pin<PortC, 8>{}, Pin<PortC, 9>{} ) ; using tRecordsTuple = decltype(records) ; } ; void delay() { for (int i = 0; i < 1000000; ++i){ } } int main() { for(;;) { LedsContainer::ToggleAll() ; //GPIOA->ODR ^= 1 << 5; //GPIOC->ODR ^= 1 << 5; //GPIOC->ODR ^= 1 << 8; //GPIOC->ODR ^= 1 << 9; delay(); } return 0 ; }
我们看到内存过大,多了18个字节。 问题是相同的,再加上12个字节。 我不知道它们的来源...也许有人会解释。
283字节的只读代码存储器
1字节的只读数据存储器
24字节的读写数据存储器
现在,在“媒介优化”和“瞧瞧”上也有同样的事情……我们在额头上获得的代码与C ++实现完全相同,而在C代码方面则更为优化。
251个字节的只读代码存储器
1字节的只读数据存储器
8字节的读写数据存储器
如您所见,我赢了,
去了加那利群岛 ,很高兴在车里雅宾斯克休息:),但是学生们也很棒,他们顺利通过了考试!
谁在乎,代码在这里好的,我在哪里可以使用它,例如,我们在EEPROM存储器中有参数,并描述了这些参数的类(读取,写入,初始化为初始值)。 该类是模板,例如
Param<float<>>和
Param<int<>> ,例如,您需要将所有参数重置为默认值。 由于类型不同,在这里可以将它们全部放入一个元组中,并在每个参数上调用
SetToDefault()方法。 的确,如果有100个这样的参数,则ROM将吃很多,但RAM不会受到影响。
PS我必须承认,在最大程度地优化之后,此代码的大小与C和我的解决方案中的代码相同。 程序员改善代码的所有努力都归结为同一汇编代码。
P.S1谢谢
0xd34df00d的
良好建议。 您可以使用
std::apply()简化对元组的拆包。
ToggleAll()的功能代码然后简化为:
__forceinline static inline void ToggleAll() { std::apply([](auto... args) { (args.Toggle(), ...); }, records); }
不幸的是,在IAR中,当前版本尚未实现std :: apply,但它也可以正常工作,请参阅
std :: apply的实现