哈Ha! 我叫Sasha,我是后端开发人员。 在业余时间,我学习ML,并喜欢hh.ru数据。
本文是关于我们如何使用机器学习为测试人员自动化常规任务分配过程的。
Hh.ru提供内部服务,如果有人不工作或工作不正常,则在Jira(在公司内部称为HHS)中创建任务。 此外,这些任务由质量检查小组负责人阿列克谢(Alexey)手动处理,并分配给其职责范围包括故障的团队。 Lesha知道无聊的任务必须由机器人执行。 因此,他向我寻求有关ML的帮助。

下图显示了每月的HHS量。 我们正在增长,任务数量也在增长。 任务主要是在每天的工作时间内创建的,并且必须经常分心。
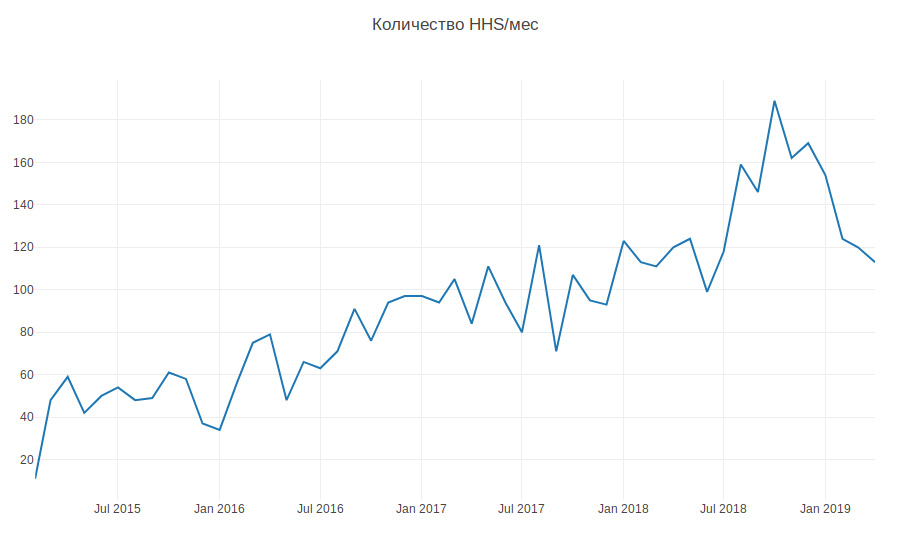
因此,根据历史数据,有必要学习如何确定HHS所属的开发团队。 这是一个多类分类任务。
资料
在机器学习任务中,最重要的是质量数据。 解决问题的结果取决于它们。 因此,任何机器学习任务都需要从研究数据开始。 自2015年初以来,我们已经累计了大约7000个任务,其中包含以下有用信息:
- 摘要-标题,简短说明
- 描述-问题的完整描述
- 标签-与问题相关的标签列表
- 记者是HHS创建者的名字。 此功能非常有用,因为人们只能使用有限的功能集。
- 已创建-创建日期
- 受让人是任务分配给的人。 目标变量将从该属性生成。
让我们从目标变量开始。 首先,每个团队都有责任范围。 有时它们相交,有时一个团队可能在开发中相交。 该决定将基于以下假设,即在完成任务时仍留在任务中的受让人负责其解决方案。 但是我们需要预测的不是一个特定的人,而是一个团队。 幸运的是,吉拉(Jira)的所有团队都得到了保存,可以进行地图绘制。 但是根据一个人来定义团队时,存在许多问题:
- 并非所有的HHS都与技术问题有关,我们只对可以分配给开发团队的那些任务感兴趣。 因此,您需要处理非技术部门受让人的任务
- 有时团队不复存在。 它们也将从训练集中删除。
- 不幸的是,人们并没有在公司中永远工作,有时他们会从一个团队转移到另一个团队。 幸运的是,我们获得了所有团队组成变化的历史。 确定了HHS和受让人的创建日期后,您可以找到在特定时间参与任务的团队。
过滤掉无关数据后,训练样本减少到4900个任务。
让我们看一下团队之间的任务分配:
任务需要在22个团队之间分配。
标志:
摘要和描述是文本字段。
首先,应清除多余的字符。 对于某些任务,在行中保留带有信息的字符(例如+和#)以区分c ++和c#是有意义的,但是在这种情况下,我决定仅保留字母和数字,因为 找不到其他字符可能有用的地方。
单词需要进行词素化。 词法化是将单词还原为引理(其正常(词汇)形式)的过程。 例如,猫→猫。 我也尝试过阻止,但是经过复词处理后质量提高了一点。 词干是寻找单词基础的过程。 此基础是由于算法(在不同的实现方式中它们是不同的),例如通过cats→cats。 第一个和第二个的含义是将相同的单词以不同的形式并置。 我为
Yandex Mystem使用了python包装器。
此外,应清除文本中不包含有效载荷的停用词。 例如,“是”,“我”,“还”。 我通常从
NLTK中取一些停用词。
我在处理文本的任务中尝试的另一种方法是基于字符的单词碎片。 例如,有一个“搜索”。 如果将其分成3个字符的组成部分,则会得到单词“ poi”,“ ois”,“诉讼”。 这有助于获得其他连接。 假设有“搜索”一词。 合法化不会导致一般形式的“搜索”和“搜索”,但是由3个字符组成的分区将突出显示公共部分-“声明”。
我做了两个令牌。 令牌生成器是一种在输入处接收文本的方法,而输出包含令牌列表-文本的组成部分。 第一个突出显示了用词修饰的单词和数字。 第二个仅突出显示去词素的单词,该单词分为3个字符,即 在输出中,他有一个由三个字符组成的令牌列表。
TfidfVectorizer中使用了分
词器 ,该工具用于将文本数据(不仅是数据)转换为基于
tf-idf的矢量表示形式。 行列表在输入处馈入,在输出处,我们得到矩阵M×N,其中M是行数,N是符号数。 每个功能都是文档中单词的频率响应,如果单词在所有文档中多次出现,则会对频率进行罚款。 感谢ngram_range TfidfVectorizer参数,我添加了
双字母
组和三字母
组作为属性。
我还尝试使用通过Word2vec获得的单词嵌入作为附加功能。 嵌入是单词的向量表示。 对于每一个文本,我将他所有单词的嵌入平均。 但这并没有增加,所以我拒绝了这些迹象。
对于标签,使用了
CountVectorizer 。 带标签的行被馈送到输入,在输出处,我们有一个矩阵,其中行对应于任务,列对应于标签。 每个单元格包含任务中标签出现的次数。 就我而言,它是1或0。
LabelBinarizer出现在Reporter中。 它对一对一属性进行二值化。 每个任务只能有一个创建者。 在LabelBinarizer的入口处,提交了任务创建者的列表,输出是一个矩阵,其中的行是任务,而各列对应于任务创建者的名称。 事实证明,在每一行中,与创建者相对应的列中均存在“ 1”,而其余部分中则为“ 0”。
对于“创建时间”,考虑了任务创建日期与当前日期之间的天数差异。
结果,获得以下迹象:
- tf-idf用于以单词和数字表示摘要(4855,4593)
- tf-idf用于三个字符分区上的摘要(4855、15518)
- tf-idf用于以文字和数字描述(4855,33297)
- tf-idf用于在三个字符的分区上进行描述(4855,75359)
- 标签的条目数(4855、505)
- Reporter的二进制符号(4855、205)
- 任务寿命(4855,1)
所有这些标志都组合成一个大矩阵(4855,129478),将在该矩阵上进行训练。
另外,值得注意的是标志的名称。 因为 一些机器学习模型可以识别对班级识别影响最大的功能,您需要使用此功能。 TfidfVectorizer,CountVectorizer和LabelBinarizer具有get_feature_names方法,这些方法显示功能列表,这些功能的顺序与数据矩阵的列相对应。
预测模型选择
XGBoost通常
会给出良好的结果。 然后他开始了。 但是我生成了大量功能,其中许多功能大大超过了训练样本的大小。 在这种情况下,重新训练XGBoost的可能性很高。 结果不是很好。 高维被很好地消化了
LogisticRegression 。 她表现出更高的素质。
我还尝试使用
此出色的教程作为练习在Tensorflow的神经网络上建立模型,但结果却比逻辑回归差。
选择超参数
我还使用了XGBoost和Tensorflow超参数,但是我将其保留在后期,因为 没有超过逻辑回归的结果。 最后,我扭曲了所有可能的笔。 结果,除以下两个参数外,所有参数均保持默认值:solver ='liblinear'和C = 3.0
可能影响结果的另一个参数是训练样本的大小。 因为 我正在处理历史数据,并且在过去的几年中,历史可能会发生重大变化,例如,对某事的责任可能会落到另一个团队身上,那么最新的数据可能会更有用,而旧数据甚至会降低质量。 在这方面,我想到了启发式方法-数据越旧,对模型训练的贡献就越小。 根据年龄,数据会乘以某个系数,该系数取自函数。 我生成了几个函数来衰减数据,并使用了在测试中增加最大的函数。
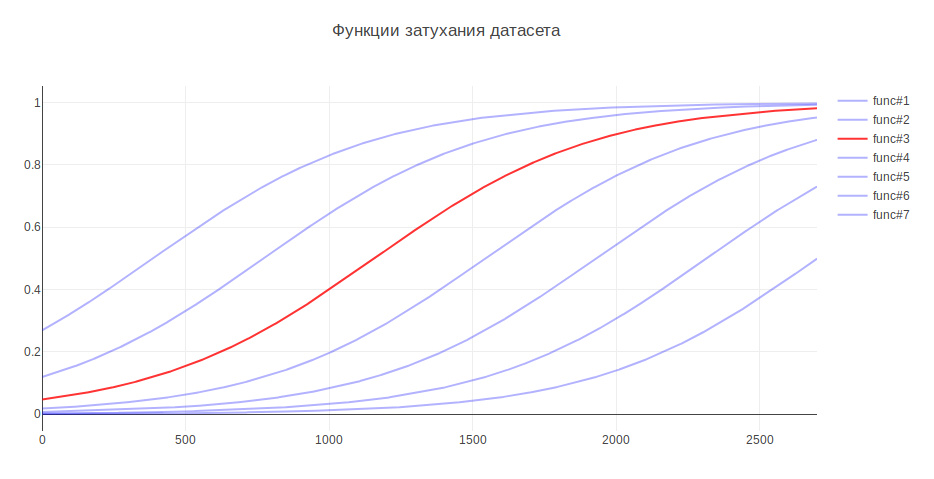
因此,分类质量提高了3%
质量评估
在分类问题中,我们需要考虑对我们来说更重要的是-
准确性或完整性 ? 在我的情况下,如果算法错误,则无需担心,我们在团队之间拥有非常好的知识,任务将转移给负责人员或质量保证中的主要人员。 另外,该算法不会随机出错,而是会找到与问题接近的命令。 因此,决定采用100%的完整性。 为了测量质量,选择了精度指标-正确答案的比例,对于最终模型,该比例为76%。
作为一种验证机制,我首先使用交叉验证-将样本分为N个部分,然后对一个部分进行质量检查,然后对其余部分进行训练,如此反复进行N次,直到每个部分都处于测试角色。 然后将结果平均。 但就我而言,这种方法不合适,因为 数据的顺序不断变化,并且众所周知,质量取决于数据的新鲜度。 因此,我一直在研究旧的东西,并在新鲜的东西上进行了验证。
让我们看看该算法最容易混淆的命令:

首先是Marketing和Pandora。 这并不奇怪,因为 第二支队伍从第一支队伍中脱颖而出,并取消了许多功能的职责。 如果考虑团队的其他成员,您还可以查看与公司内部厨房相关的原因。
为了进行比较,我想看看随机模型。 如果您随机分配负责人,则质量约为5%,如果是最普通的班级,则质量为-29%
最重要的迹象
每个类的LogisticRegression返回属性系数。 值越大,此属性对此类的贡献越大。
在扰流板下方,显示标志的顶部。 前缀指示标志的来源:
- sum-tf-idf用于以文字和数字表示摘要
- sum2-tf-idf,用于三字符拆分的摘要
- desc-tf-idf,用于以文字和数字描述
- desc2-tf-idf,用于描述三个字符的分区
- 实验室-标签字段
- 代表-现场记者
迹象A团队:sum_site(1.28),lab_responses_and_vitations(1.37),lab_failure_to雇主(1.07),lab_makeup(1.03),sum_work(1.54),lab_hhs(1.19),lab_feedback(1.06),rep_name (1.16),sum_窗口(1.13),sum_ break(1.04),rep_name_1(1.22),lab_responses_seeker(1.0),lab_site(0.92)
API:lab_delete_account(1.12),sum_comment_resume(0.94),rep_name_2(0.9),rep_name_3(0.83),rep_name_4(0.89),rep_name_5(0.91),lab_measurements_managers(0.87),lab_comments_to_result(1.66),帐户),sum_view(0.91),desc_comment(1.02),rep_name_6(0.85),desc_resume(0.86),sum_api(1.01)
Android:sum_android(1.77),lab_ios(1.66),sum_application(2.9),sum_hr_mobile(1.4),lab_android(3.55),sum_hr(1.36),lab_mobile_application(3.33),sum_mobile(1.4),rep_name_2(1.34),sum2_ril(1.27) ),sum_android_application(1.28),sum2_pril_rilo(1.19),sum2_pril_ril(1.27),sum2_ril_log(1.19),sum2_ril_log_(1.19)
帐单:rep_name_7(3.88),desc_account(3.23),rep_name_8(3.15),lab_billing_wtf(2.46),rep_name_9(4.51),rep_name_10(2.88),sum_account(3.16),lab_billing(2.41),rep_name_11b(2.27) ),sum_service(2.33),lab_payment_services(1.92),sum_act(2.26),rep_name_12(1.92),rep_name_13(2.4)
白兰地:lab_talent评估(2.17),rep_name_14(1.87),rep_name_15(3.36),lab_clickme(1.72),rep_name_16(1.44),rep_name_17(1.63),rep_name_18(1.29),sum_page(1.24),sum_brand(1.39) ),sum_constructor(1.59),页面的lab_brand(1.33),sum_description(1.23),公司的sum_description_(1.17),lab_article(1.15)
Clickme:desc_act(0.73),sum_adv_hh(0.65),sum_adv_hh_ru(0.65),sum_hh(0.77),lab_hhs(1.27),lab_bs(1.91),rep_name_19(1.17),rep_name_20(1.29),rep_name_21(1.9) ),sum_advertising(0.67),sum_placing(0.65),sum_adv(0.65),sum_hh_ua(0.64),sum_click_31(0.64)
市场营销:lab_region(0.9),lab_site_site(1.23),sum_mail(1.32),lab_managers_职位空缺(0.93),sum_calender(0.93),rep_name_22(1.33),lab_queries(1.25),rep_name_6(1.53),lab_product_1.55(repa1_5) ),sum_yandex(1.26),sum_distribution_vacancy(0.85),sum_distribution(0.85),sum_category(0.85),sum_error_function(0.83)
汞:lab_services(1.76),sum_captcha(2.02),lab_search_services(1.89),lab_lawyers(2.1),lab_authorization_worker(1.68),lab_proforientation(2.53),lab_ready_summary(2.21),rep_name_24(1.7725_mail) ),sum_user(1.57),rep_name_26(1.43),lab_moderation_of空缺(1.58),desc_password(1.39),rep_name_27(1.36)
Mobile_site:sum_mobile_version(1.32),sum_version_site(1.26),lab_application(1.51),lab_statistics(1.32),sum_mobile_version_site(1.25),lab_mobile_version(5.1),sum_version(1.41),rep_name_28(1.24),lab_string(1.04.05,1_stat_1_status ),lab_jtb(1.07),rep_name_16(1.12),rep_name_29(1.05),sum_site(0.95),rep_name_30(0.92)
TMS:rep_name_31(1.39),lab_talantix(4.28),rep_name_32(1.55),rep_name_33(2.59),sum_valuation_talantix(0.74),lab_search(0.57),lab_search(0.63),rep_name_34(0.64),lab_port(0.56) ),lab_tms(0.74),sum_hh响应(0.57),lab_mailing(0.64),sum_talantix(0.6),sum2_po(0.56)
Talantix:sum_system(0.86),rep_name_16(1.37),sum_talantix(1.16),lab_mail(0.94),lab_xor(0.8),lab_talantix(3.19),rep_name_35(1.07),rep_name_18(1.33),lab_personal_data(0.79) ),sum_talantics(0.89),sum_proceed(0.78),lab_mail(0.77),sum_response_stop_view(0.73),rep_name_6(0.72)
Web服务:sum_vacancy(1.36),desc_pattern(1.32),sum_archive(1.3),lab_patterns(1.39),sum_number_phone(1.44),rep_name_36(1.28),lab_lawyers(2.1),lab_invitation(1.27),lab_invitation(2) ),lab_selected_summages(1.2),lab_key_keys(1.22),sum_find(1.18),sum_phone(1.16),sum_folder(1.17)
iOS:sum_application(1.41),desc_application(1.13),lab_andriod(1.73),rep_name_37(1.05),lab_mobile_application(1.88),lab_ios(4.55),rep_name_6(1.41),rep_name_38(1.35),sum_mobile_application ),sum_mobile(0.98),rep_name_39(0.74),sum_resum_hide(0.88),rep_name_40(0.81),lab_重复空缺(0.76)
体系结构:sum_statistics_response(1.1),rep_name_41(1.4),lab_graphics_views_and_responses_空缺(1.04),lab_creation_of空缺(1.16),lab_quotas(1.0),sum_special offer(1.02),rep_name_42_(1.31)1.01_01 ),rep_name_43(1.09),sum_dependent(0.83),sum_statistics(0.83),lab_responses_worker(0.76),sum_500ka(0.74)
薪资银行:lab_500(1.18),lab_authorization(0.79),sum_500(1.04),rep_name_44(0.85),sum_500_site(1.03),lab_site(1.54),lab_visibility_resume(1.54),lab_price列表(1.26),lab_setting_visibility_7_resume(恢复sum_error(0.79),lab_delivered_orders(1.33),rep_name_43(0.74),sum_ie_11(0.69),sum_500_error(0.66),sum2_site_ite(0.65)
移动产品:lab_mobile_application(1.69),lab_backs(1.65),sum_hr_mobile(0.81),lab_applicant(0.88),lab_employer(0.84),sum_mobile(0.81),rep_name_45(1.2),desc_d0(0.87),rep_name_46(1.rr),sum_h 0.79),sum_incorrect_search_work(0.61),desc_application(0.71),rep_name_47(0.69),rep_name_28(0.61),sum_work_search(0.59)
潘朵拉:sum_receive(2.68),desc_receive(1.72),lab_sms(1.59),sum_ letter(2.75),sum_notification_response(1.38),sum_password(1.52),lab_recover_password(1.52),lab_mail_mail(1.31,邮件,邮箱(1.91)) ),lab_mail(1.72),lab_mail(3.37),desc_mail(1.69),desc_mail(1.47),rep_name_6(1.32)
Peppers:lab_saving_summary(1.43),sum_summing(2.02),sum_collar(1.57),sum_collar_vacancy(1.66),desc_resum(1.19),lab_summing(1.39),sum_code(1.2),lab_applicant(1.34),sum_index(1.47),sum_index ),lab_creation_summary(1.28),rep_name_45(1.82),sum_civilness(1.47),sum_save_summum(1.18),lab_invital_index(1.13)
搜索-1:sum2_poi_is_search(1.86),sum_loop(3.59),lab_questions_o_search(3.86),sum2_poi(1.86),desc_overs(2.49),lab_observing_summary(2.2),lab_observer(2.32),lab_loop(4.3oopropo_1) (1.62),sum_synonym(1.71),sum_sample(1.62),sum2_isk(1.58),sum2_is_isk(1.57),lab_auto-update_sum(1.57)
搜索2:rep_name_48(1.13),desc_d1(1.1),lab_premium_in_search(1.02),空缺(1.4),sum_search(1.4),desc_d0(1.2),lab_show_contacts(1.17),rep_name_49(1.12950,lab13 (1.05),职位空缺搜索(1.62),实验室响应和邀请(1.61),总和响应(1.09),实验室选择结果(1.37),实验室过滤器响应(1.08)
超级产品:lab_contact_information(1.78),desc_address(1.46),rep_name_46(1.84),sum_address(1.74),lab_selected_resumes(1.45),lab_reviews_worker(1.29),sum_right_shot(1.29),sum_right_range(1.29) ),sum_error_position(1.33),rep_name_42(1.32),sum_quota(1.14),desc_address_office(1.14),rep_name_51(1.09)
迹象大致反映了团队在做什么。
模型用法
至此,模型的构建完成,并且可以在其基础上构建程序。
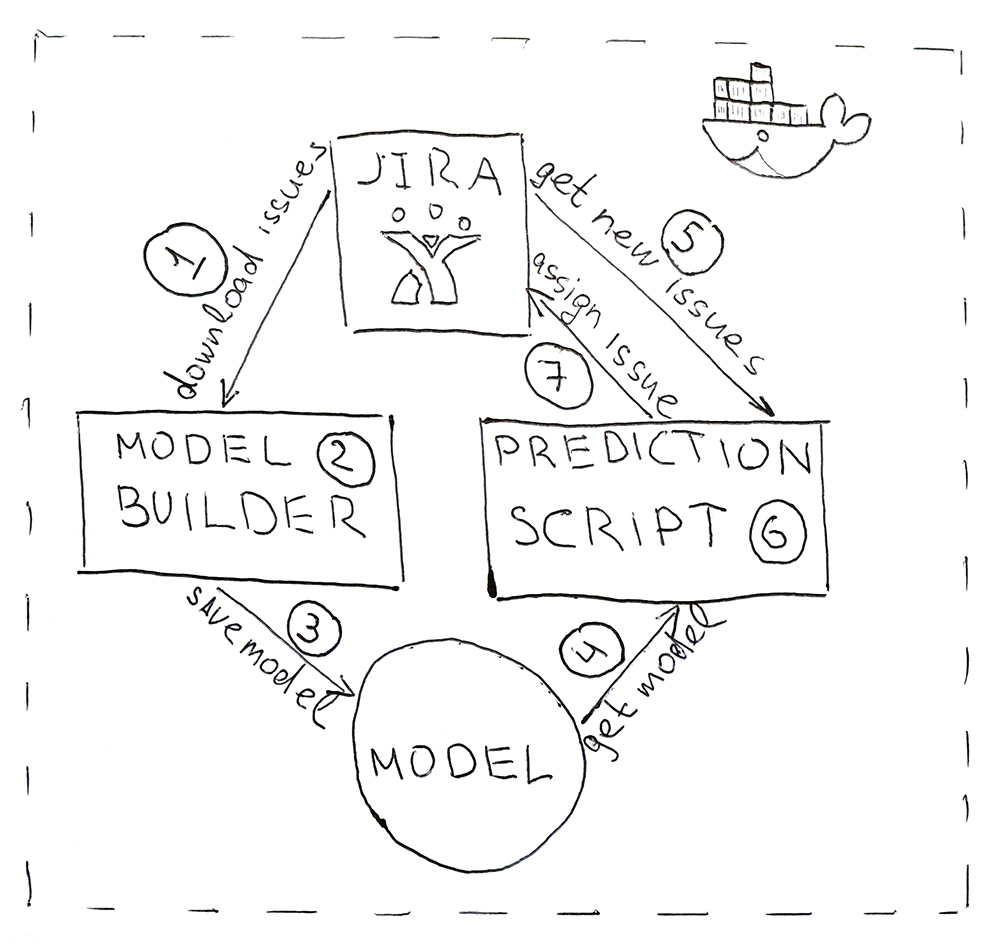
该程序包含两个Python脚本。 第一个建立模型,第二个进行预测。
- Jira提供了一个API,您可以通过该API下载已经完成的任务(HHS)。 每天一次,脚本将启动并下载。
- 下载的数据将转换为标签。 首先,对数据进行训练和测试,然后将其提交给ML模型进行验证,以确保从开始到开始质量都不会开始下降。 然后第二次在所有数据上训练模型。 整个过程大约需要10分钟。
- 经过训练的模型将保存到硬盘中。 我使用了莳萝工具来序列化对象。 除了模型本身之外,还必须保存用于获取特征的所有对象。 这是为了在新HHS的相同空间中获得标志。
- dill , 5 .
- Jira HHS.
- , HHS — .
- Jira API. , , — .
, , Docker .
. 76% — , . , , , . ! 万岁!