测试“ 1C会计”的目标和要求
测试的主要目的是比较1C系统在其他相同条件下在两个不同DBMS上的行为。 即 每次测试期间1C数据库的配置和初始数据填充应相同。
测试期间应获取的主要参数:
- 每个测试的执行时间(由开发部门1C删除)
- 测试期间,DBMS管理员将删除测试期间DBMS和服务器环境上的负载,系统管理员也将删除服务器环境上的负载
1C系统的测试应在考虑客户端-服务器体系结构的情况下进行,因此,有必要在系统中模拟一个或多个用户,并在接口中计算出信息输入并将该信息存储在数据库中。 同时,有必要在很长的一段时间内发布大量的周期性信息,以在累加寄存器中创建总计。
为了执行测试,针对1C Accounting 3.0的配置,以脚本形式开发了一种用于脚本测试的算法,其中将测试数据串行输入到1C系统中。 该脚本允许您为执行的操作和测试数据量指定各种设置。 详细说明如下。
描述测试环境的设置和特征
富通集团决定对结果进行仔细检查,包括使用著名的
吉列夫(Gilev)测试 。
还鼓励我们进行测试,包括一些有关从MS SQL Server过渡到PostgreSQL期间性能变化结果的出版物。 例如:
1C之战:PostgreSQL 9.10 vs MS SQL 2016 。
因此,这是测试的基础架构:
用于MS SQL和PostgreSQL的服务器是虚拟的,可以交替运行以进行所需的测试。 1C站在单独的服务器上。
详细资料系统管理程序规范:型号:Supermicro SYS-6028R-TRT
CPU:英特尔®至强®CPU E5-2630 v3 @ 2.40GHz(2座* 16 CPU HT = 32CPU)
内存:212 GB
操作系统:VMWare ESXi 6.5
PowerProfile:性能
系统管理程序磁盘子系统:控制器:Adaptec 6805,缓存大小:512MB
容量:RAID 10,5.7 TB
条带大小:1024 KB
写缓存:开启
读取缓存:关闭
车轮:6个。 HGST HUS726T6TAL,
扇区大小:512字节
写缓存:打开
PostgreSQL的配置如下:- postgresql.conf:
基本设置是使用计算器-pgconfigurator.cybertec.at进行的 ,根据从出版物结尾处提到的来源收到的信息,更改了参数huge_pages,checkpoint_timeout,max_wal_size,min_wal_size,random_page_cost。 根据1C主动使用临时表的建议,temp_buffers参数的值增加了:
listen_addresses = '*' max_connections = 1000
- 内核,操作系统参数:
设置以已调整守护程序的配置文件格式设置:
[sysctl]
- 文件系统:
postgresql.conf文件的所有内容:
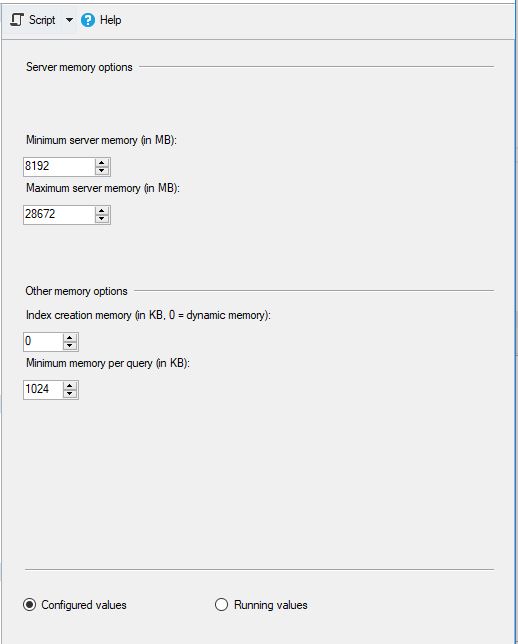
MS SQL的配置如下: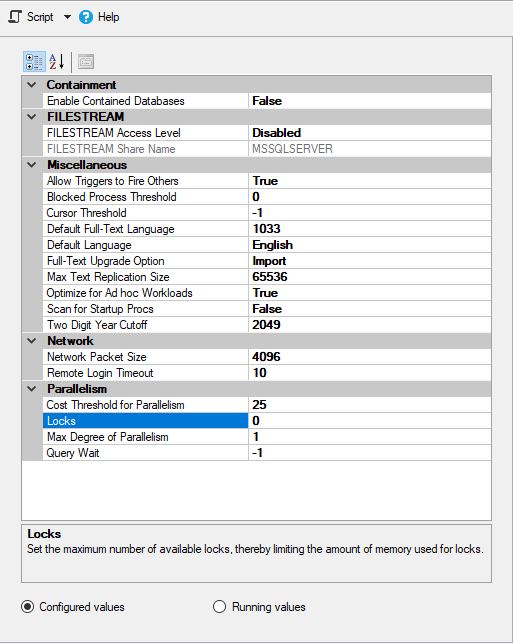
和
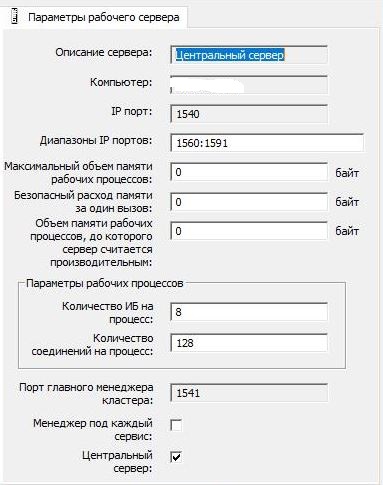
1C集群的设置为标准设置:

和
服务器上没有防病毒程序,并且未安装任何第三方。
对于MS SQL,tempdb已移至单独的逻辑驱动器。 但是,数据库的数据文件和事务日志文件位于同一逻辑驱动器上(也就是说,数据文件和事务日志未拆分为单独的逻辑驱动器)。
在所有逻辑驱动器上都禁用了MS SQL Server所在的Windows中的索引驱动器(这在prodovskih环境中通常是大多数情况下的惯例)。
自动测试脚本的主要算法的描述主要的估计测试周期为1年,在此期间,将根据指定的参数每天创建文档和参考信息。
在执行的每一天,都会启动信息输入和输出块:
- 第1块“_”-“收到商品和服务”
- 对方目录打开
- 使用“供应商”视图创建目录“承包商”的新元素
- 使用“与供应商”视图为新的对等方创建“合同”目录中的新元素
- 目录“命名”打开
- 创建目录“ Nomenclature”的一组元素,类型为“ Product”
- 目录“命名”的一组元素,格式为“服务”
- 文件清单“货物和服务的收据”
- 创建一个新文档“商品和服务收据”,其中表格部分“商品”和“服务”中填充了创建的数据集
- 当月生成报告“ Account Card 41”(如果指示了额外的结账间隔)
- 第2块“_”-“商品和服务的销售”
- 对方目录打开
- 使用“买方”视图创建“ Counterparties”目录中的新元素
- 使用新交易对手的“与买方”视图创建“合同”目录中的新元素
- 将打开“商品和服务的销售”文件清单。
- 创建一个新文档“商品和服务销售”,其中根据先前创建的数据中指定的参数填写表格部分“商品”和“服务”
- 当月生成报告“ Account Card 41”(如果指示了额外的结账间隔)
- 生成当月的报告“ Account Card 41”
在每个月的创建文档的月底,执行输入和输出信息的块:
- 从年初到月末生成报告“ Account Card 41”
- 从年初到月末生成“营业额资产负债表”报告
- 正在执行“每月结算”监管程序。
执行结果以小时,分钟,秒和毫秒为单位提供有关测试时间的信息。
测试脚本的主要功能:- 禁用/启用单个单元的能力
- 能够指定每个块的文档总数
- 能够指定每天每个块的文档数
- 能够在文件中指示商品和服务的数量
- 能够设置定量和价格指标列表以进行记录。 用于在文档中创建不同的值集
每个数据库的基本测试计划:- “第一次测试。” 在单个用户下,将创建少量具有简单表的文档,并形成“月关闭”
- 预计交货时间为20分钟。填充1个月。数据:“职业学校”有50个文件,“ RTU”有50个文件,“供应商”有100个要素,“供应商” +“协议”有50个要素,“买家” +“协议”有50个要素,“月末结算”有2个业务。文件中有1个产品和1个服务
- “第二次测试。” 在一个用户下创建大量文档并填写表格,形成月结
- — 50-60 . 3 . : 90 «», 90 «», 540 «», 90 «» + «», 90 «» + «», 3 « ». 3 3
- « ». . .
- — 40-60 . 2 . : 50 «», 50 «», 300 «», 50 «» + «», 50 «» + «». 3 3
:- , :
- « » « »
- 1 "*.dt"
- « »
结果
现在,在MS SQL Server DBMS上最有趣的结果是:详细资料:
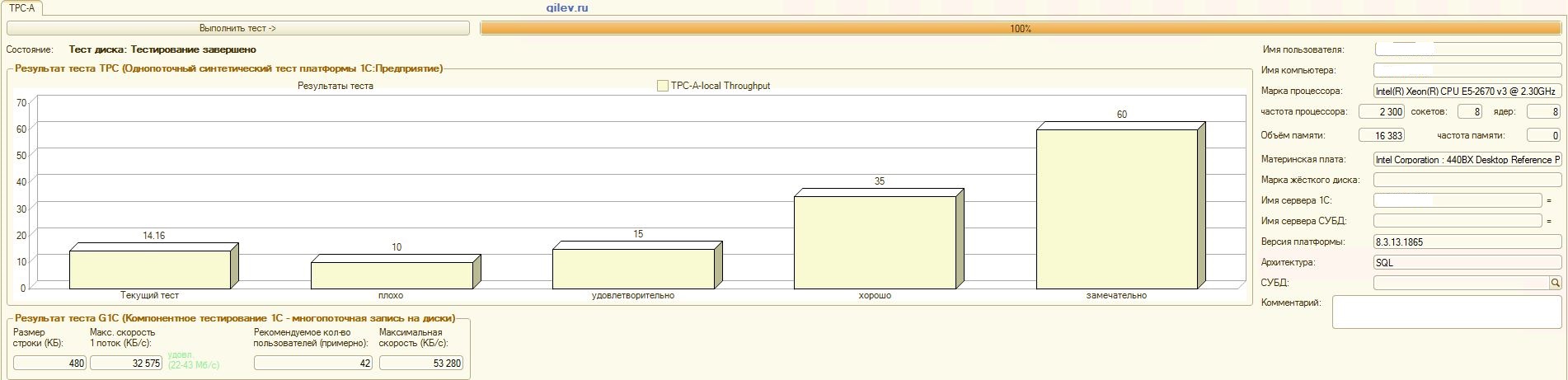
:
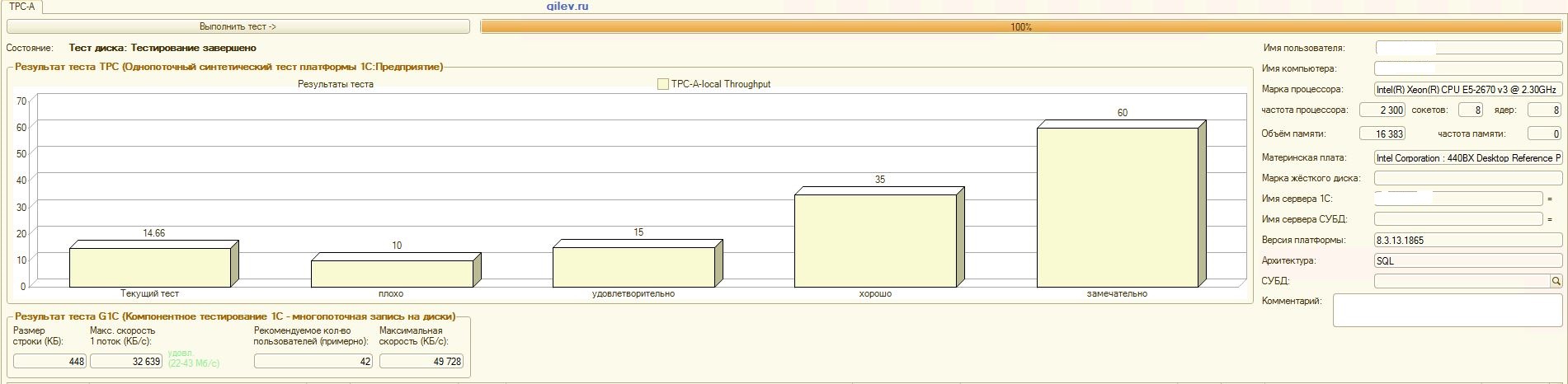
:

PostgreSQL,
, , , :
:
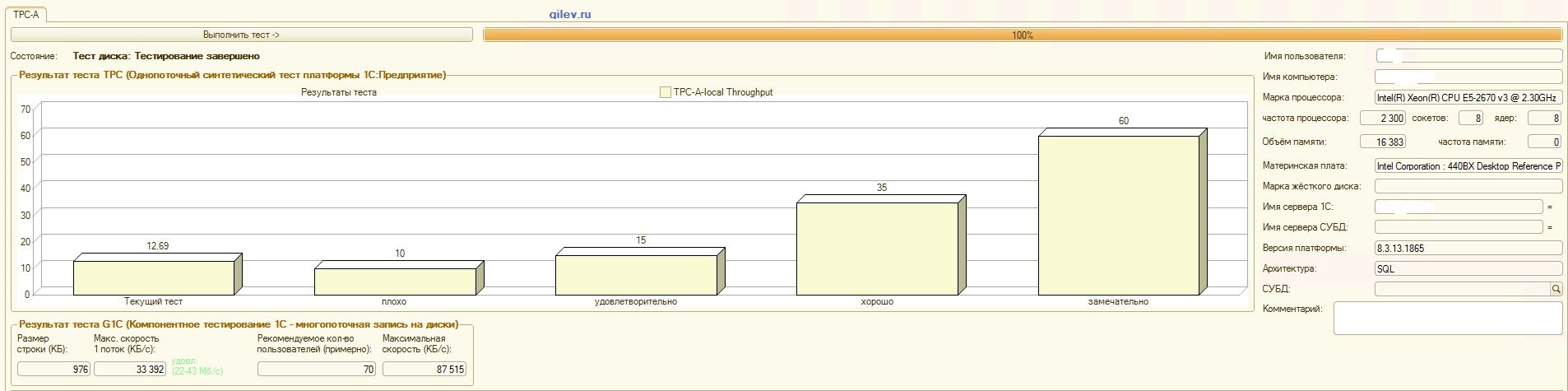
:
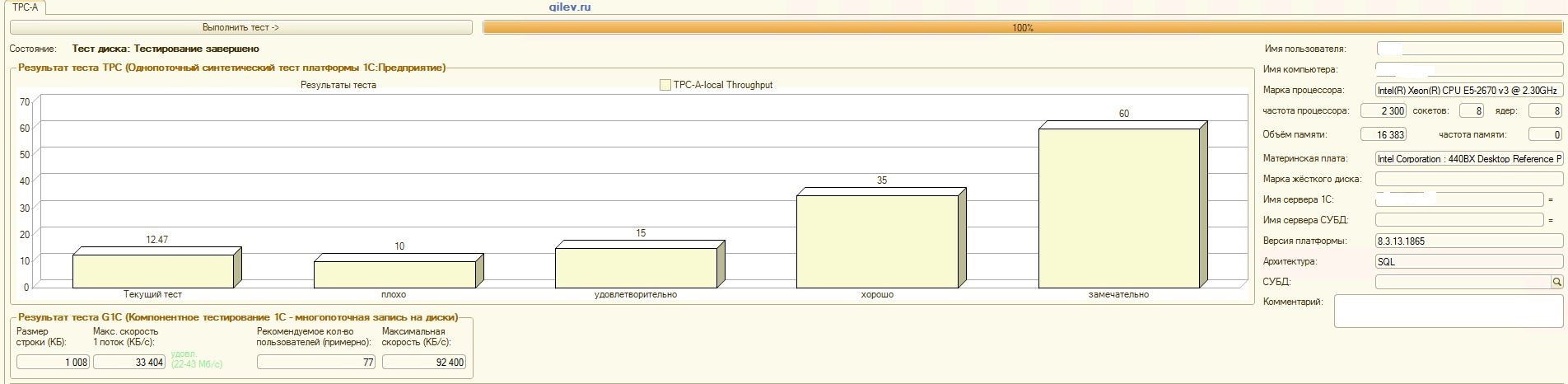
:

吉列夫测试:从结果可以看出,在一般的综合测试DBMS中,PostgreSQL平均损失了MS SQL DBMS的性能14.82%。但是,根据最后两个指标,PostgreSQL的结果要比MS SQL好得多。1C会计的专业测试:从结果可以看出,使用上述设置,1C会计在MS SQL和PostgreSQL上的工作原理大致相同。在这两种情况下,DBMS都能稳定运行。当然,您可能需要从DBMS以及从OS和文件系统进行更细微的调整。一切都随着出版物的播出而完成,这表示从MS SQL切换到PostgreSQL时,生产率将显着提高或几乎相同。此外,在此测试中,采取了多种措施来优化CentOS本身的OS和文件系统,如上所述。值得注意的是,Gilev测试针对PostgreSQL运行了很多次-给出了最佳结果。Gilev测试在MS SQL上运行了3次,因此他们没有在MS SQL上进行优化。随后的所有尝试都是使大象达到MS SQL指标。在MS SQL和PostgreSQL之间的Gilev综合测试中达到最佳差异之后,如上所述,针对1C记帐进行了专门的测试。总的结论是,尽管在PostgreSQL DBMS的Gilev综合测试中相对于MS SQL的性能显着下降,但通过上面给出的适当设置,仍可以在MS SQL DBMS和PostgreSQL DBMS上安装1C Accounting。备注
应当立即指出,进行此分析只是为了比较不同DBMS中的1C性能。该分析和结论仅对在上述条件和软件版本下的1C会计正确。根据获得的分析,不可能确切地推断出其他设置和软件版本以及不同的1C配置会发生什么。但是,Gilev测试结果表明,在1C版本8.3及更高版本的所有配置上,如果设置正确,相对于MS SQL DBMS,PostgreSQL DBMS的最大性能下降可能不会超过15%。还值得考虑的是,任何用于精确比较的详细测试都将花费大量时间和资源。基于此,我们可以做出一个更可能的假设:1C版本8.3和更高版本可以从MS SQL迁移到PostgreSQL,最大性能损失高达15%。过渡没有任何客观障碍,可能不会出现这15%的情况,而且如果出现这些障碍,仅在必要时购买功能更强大的设备就足够了。还需要注意的是,被测数据库很小,也就是说,数据大小明显小于100 GB,同时运行的最大线程数为4。这意味着对于大型数据库,其大小明显大于100 GB(例如,大约1 TB) ,以及具有密集访问权限的数据库(数十个同时存在数百个活动流),这些结果可能不正确。为了进行更客观的分析,将来比较在同一CentOS操作系统上安装的已发布MS SQL Server 2019 Developer和PostgreSQL 12以及在最新版本的Windows Server操作系统上安装MS SQL时将很有用。现在没有人将PostgreSQL放到Windows上,因此PostgreSQL DBMS的性能下降将非常重要。当然,吉列夫(Gilev)测试通常只涉及性能,而不仅仅是1C。但是,现在说MS SQL DBMS总是比PostgreSQL DBMS好得多,这还为时过早,因为事实不多。要确认或反驳此声明,您需要进行许多其他测试。例如,对于.NET,您需要编写原子操作和复杂测试,在不同的条件下重复运行它们,确定执行时间并取平均值。然后比较这些值。这将是一项客观分析。目前,我们还不准备进行这种分析,但是将来很有可能进行分析。然后,我们将在PostgreSQL比MS SQL更好的操作以及百分比方面的优势,以及在MS SQL比PostgreSQL更好的方面以及百分比方面的优势下,进行详细介绍。此外,我们的测试未将MS SQL的优化方法应用于此处,此处进行了介绍。也许本文只是忘记了关闭Windows磁盘索引。在比较两个DBMS时,应牢记一个重要的观点:PostgreSQL DBMS是免费和开放的,而MS SQL DBMS是付费的并且具有封闭的源代码。现在以牺牲Gilev测试本身为代价。在测试之外,将删除综合测试(第一个测试)和所有其他测试的迹线。第一个测试主要查询原子操作(插入,更新,删除和读取)和复杂操作(参考多个表,以及在数据库中创建,更改和删除表),并使用不同数量的处理数据。因此,对于比较两个环境(包括DBMS)相对于彼此的平均统一性能,可以认为Gilev综合测试相当客观。绝对值本身什么也没说,但是它们在两种不同媒体中的比率是很客观的。以其他Gilev测试为代价。跟踪显示最大线程数为7,但有关用户数的结论超过50。此外,根据要求,还不清楚如何计算其他指标。因此,其余测试不是客观的,并且变化很大且近似。只有专门的测试不仅考虑系统本身的特点,而且还要考虑用户本身的工作,才能给出更准确的值。致谢
- 执行1C设置并启动了Gilev测试,还为创建此出版物做出了重大贡献:
- Roman Buts-团队主管1C
- Alexander Gryaznov-1C程序员
- 富通公司的同事们为CentOS,PostgreSQL等的优化优化做出了重要贡献,但希望保持隐身状态
特别感谢uaggster和BP1988,他们对MS SQL和Windows提供了一些建议。后记
这篇文章也做了一个奇怪的分析。您得到了什么结果以及如何测试?资料来源