关于文章
对于那些想了解有关GPU如何处理分支的更多信息的程序员来说,这篇文章是简短的说明。 您可以将其视为本主题的介绍。 我建议以[
1 ],[
2 ]和[
8 ]开头,以大致了解GPU执行模型的外观,因为我们将仅考虑一个单独的细节。 对于好奇的读者,文章末尾有所有链接。 如果发现错误,请与我联系。
目录内容
- 关于文章
- 目录内容
- 词汇量
- GPU核心与CPU核心有何不同?
- 什么是一致性/差异?
- 执行蒙版处理示例
- 如何处理差异?
- 参考文献
词汇量
- GPU-图形处理单元,GPU
- 弗林的分类
- SIMD-单指令多数据,单指令流,多数据流
- SIMT-单指令多线程,单指令流,多线程
- Wave(SIM)-以SIMD模式执行的流
- 行(车道)-SIMD模型中的单独数据流
- SMT-同步多线程,同时多线程(英特尔超线程)[ 2 ]
- IMT-交错多线程,交替多线程[ 2 ]
- BB-基本块,基本块-线性指令序列,最后单跳
- ILP-指令级并行性,指令级的并行性[ 3 ]
- ISA-指令集架构,指令集架构
在我的帖子中,我将坚持这种发明的分类。 它大致类似于现代GPU的组织方式。
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1
其他名称:
- 核心可能称为CU,SM,EU
- 波形可以称为波前,硬件线程(硬件线程),扭曲,上下文
- 一行可以称为程序线程(SW线程)
GPU核心与CPU核心有何不同?
当前任何一代的GPU内核都没有中央处理器强大:简单的ILP /多问题[
6 ]和预取[
5 ],没有对过渡/返回的预测或预测。 所有这些以及微小的缓存释放了芯片上相当大的区域,其中充满了许多内核。 内存加载/存储机制能够处理通道宽度比常规CPU大一个数量级(这不适用于集成/移动GPU),但是您必须为此付出高昂的等待时间。 为了隐藏延迟,GPU使用了SMT [
2 ]-一波空闲时,另一波则使用内核的免费计算资源。 通常,一个内核处理的波数取决于所使用的寄存器,并通过分配固定的寄存器文件来动态确定[
8 ]。 计划执行指令是混合的-动态静态[
6 ] [
11 4.4]。 在SIMD模式下执行的SMT内核实现了较高的FLOPS值(每秒浮点操作数,触发器,每秒浮点操作数)。
 图例图。 黑色-不活动,白色-活动,灰色-关,蓝色-空闲,红色-待处理图1. 4:2执行历史
图例图。 黑色-不活动,白色-活动,灰色-关,蓝色-空闲,红色-待处理图1. 4:2执行历史该图显示了执行掩码的历史记录,其中x轴表示从左到右的时间,y轴表示从上到下的行的标识符。 如果您仍然不明白这一点,请在阅读以下各节后返回到图纸。
这说明了虚拟配置中GPU内核执行历史的样子:四个波形共享一个采样器和两个ALU。 每个周期中的波形计划器都会从两个波形中发出两个指令。 当一个波在执行对存储器的访问或长时间的ALU操作时处于空闲状态时,调度程序将切换到另一对波,因此ALU几乎始终被100%占用。
图2. 4:1执行历史一个具有相同负载的示例,但是这次在指令的每个周期中只有一个波动发出。 请注意,第二个ALU挨饿了。
图3.执行历史4:4这次,每个周期发出四个指令。 请注意,对ALU的请求太多,因此几乎总是有两个波浪在等待(实际上,这是规划算法的错误)。
更新有关计划执行指令难度的更多信息,请参见[
12 ]。
在现实世界中,GPU具有不同的内核配置:有些GPU的每个内核最多可以包含40个波形和4个ALU,而另一些则具有7个固定波形和2个ALU。 所有这一切都取决于许多因素,并且要归功于架构仿真的艰苦过程。
另外,实际的SIMD ALU的宽度可能比它们所服务的波窄,因此处理一个发出的指令要花费几个周期。 该因素称为长度“钟声” [
3 ]。
什么是一致性/差异?
让我们看一下以下代码片段:
例子1
uint lane_id = get_lane_id(); if (lane_id & 1) {
在这里,我们看到了一条指令流,其中的执行路径取决于正在执行的行的标识符。 显然,不同的行具有不同的含义。 会发生什么? 解决这个问题有不同的方法[
4 ],但最终它们都做同一件事。 一种方法是执行掩码,我将介绍它。 在Volta之前的Nvidia GPU和AMD GCN GPU中都使用了这种方法。 执行掩码的要点是我们为wave中的每一行存储一个位。 如果相应的行执行位为0,则下一条指令的发布将不影响任何寄存器。 实际上,该行不应感觉到整个已执行指令的影响,因为其执行位为0。其工作方式如下:该波按深度搜索顺序在控制流程图中传播,保存选定转换的历史,直到设置了这些位为止。 我认为最好以身作则。
假设我们有一个宽度为8的波。这是代码片段的执行掩码:
示例1.执行掩码的历史记录
现在考虑更复杂的示例:
例子2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) {
例子3
uint lane_id = get_lane_id(); if (lane_id < 16) {
您可能会注意到历史记录是必要的。 当使用执行屏蔽方法时,设备通常使用某种堆栈。 天真的方法是存储一个元组堆栈(exec_mask,地址),并添加收敛指令,这些指令从堆栈中检索掩码并更改wave的指令指针。 在这种情况下,电波将具有足够的信息来绕过每条线的整个CFG。
在性能方面,由于所有这些数据存储,只需要几个循环即可处理控制流指令。 并且不要忘记堆栈的深度有限。
更新。 感谢
@craigkolb,我读了一篇文章[
13 ],该文章指出AMD GCN fork / join指令首先从更少的线程中选择路径[
11 4.6],这保证了掩码堆栈的深度等于log2。
更新。 显然,几乎总是可以将所有内容嵌入到着色器中的着色器/结构CFG中,并因此将执行掩码的整个历史记录存储在寄存器中,并计划静态旁路/会聚CFG [
15 ]。 在查看了AMDGPU的LLVM后端后,我没有发现编译器不断发出的栈处理证据。
运行时掩码硬件支持
现在看一下Wikipedia中的这些控制流程图:
图4.一些类型的控制流程图我们需要处理所有情况的最少掩码控制指令集是什么? 这是在具有隐式并行化,显式掩码控制和数据冲突的完全动态同步的人工ISA中的外观:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE
让我们看一下情况d)。
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret
我不是控制流分析或ISA设计方面的专家,因此我确信在某些情况下我的人工ISA无法应对,但这并不重要,因为结构化CFG对每个人都足够。
更新。 在此处[
11 ] ch.4阅读有关GCN支持控制流指令的更多信息,并在此处[
15 ]阅读有关LLVM实现的更多信息。
结论:
- 发散-同一波的不同线选择的路径中的结果差异
- 一致性-无差异。
执行蒙版处理示例
虚构ISA
我在人工ISA中编译了先前的代码段,并在SIMD32中的模拟器上运行了它们。 查看它如何处理执行掩码。
更新。 请注意,人工模拟器始终会选择真实的路径,但这不是最佳方法。
例子1
 图5.示例1的历史
图5.示例1的历史您注意到黑色区域了吗? 这次浪费了。 有些行等待其他人完成迭代。
例子2
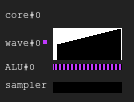 图6.示例2的历史
图6.示例2的历史例子3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16)
 图7.示例3的历史记录
图7.示例3的历史记录AMD GCN ISA
更新。 GCN还使用显式掩码处理,有关更多信息,请参见:[
11 4.x]。 我决定通过ISA显示一些示例,这要归功于
shader-playground,这很容易做到。 也许有一天我会找到一个模拟器并设法获得图表。
请记住,编译器很聪明,因此您可以获得其他结果。 我试图欺骗编译器,以免通过放置指针循环然后清理汇编代码来优化我的分支; 我不是GCN专家,因此可能会忽略一些重要的知识。
还要注意,在这些片段中未使用S_CBRANCH_I / G_FORK和S_CBRANCH_JOIN指令,因为它们很简单并且编译器不支持它们。 因此,不幸的是,不可能考虑掩模的堆叠。 如果您知道如何使编译器对堆栈进行处理,请告诉我。
更新。 查看
@ SiNGUL4RiTY的有关在AMD使用的LLVM后端中实现矢量化控制流的讨论。
例子1
例子2
例子3
AVX512
更新。 @tom_forsyth向我指出,AVX512扩展也具有显式的掩码处理,因此这里有一些示例。 可以在[
14 ],15.x和15.6.1中找到关于此的更多详细信息。 它不完全是GPU,但仍然具有32位的真实SIMD16。 代码片段是使用ISPC(–target = avx512knl-i32x16)
Godbolt创建的 ,经过大量重新设计,因此可能并非100%正确。
例子1
例子2
例子3
如何处理差异?
我试图创建一个简单而完整的说明,说明合并分歧线会导致效率低下。
想象一下一段简单的代码:
uint thread_id = get_thread_id()
让我们创建256个线程并测量它们的执行时间:
图8.不同线程的持续时间x轴是节目流的标识符,y轴是时钟周期。 与单线程执行相比,不同的列显示了在对具有不同波长的流进行分组时浪费了多少时间。
波形运行时间等于其中包含的行中的最大运行时间。 您会发现SIMD8的性能已经大大下降,进一步扩展只会使性能稍差一些。
图9.一致线程的运行时该图中显示了相同的列,但是这次迭代次数是通过流标识符排序的,即,具有类似迭代次数的流被发送到单个wave。
对于此示例,执行速度可能会提高约一半。
当然,该示例太简单了,但我希望您理解这一点:执行中的差异源于数据的差异,因此CFG必须简单且数据一致。
例如,如果您正在编写光线跟踪器,则可以从具有相同方向和位置的光线分组中受益,因为它们很可能会穿过BVH中的相同节点。 有关更多详细信息,请参见[
10 ]和其他相关文章。
还值得一提的是,有一些技术可以在硬件级别处理差异,例如,动态翘曲形成[
7 ]和小分支的预测执行。
参考文献
[1]
图形管道之旅[2]
Kayvon Fatahalian:并行计算[3]
计算机体系结构定量方法[4]
低成本的无堆栈SIMT融合[5]
通过微基准测试剖析GPU内存层次[6]
通过Microbenchmarking剖析NVIDIA Volta GPU架构[7]
动态扭曲变形和调度,以实现高效的GPU控制流程[8]
Maurizio Cerrato:GPU架构[9]
玩具GPU模拟器[10]
减少GPU程序中的分支分歧[11]
“ Vega”指令集架构[12]
Joshua Barczak:模拟GCN的着色器执行[13]
切向量:关于散度的离题[14]
英特尔64和IA-32架构软件开发人员手册[15]
针对SIMD应用矢量化发散控制流