敬礼,哈布里沃派! 以下文章的翻译是专门为
基于Kubernetes的基础设施平台课程的学生准备的,该课程将于明天开始。 让我们开始吧。

Kubernetes中的自动缩放
自动扩展允许您根据资源的使用来自动增加和减少工作量。
Kubernetes自动缩放具有两个维度:
- 集群自动缩放器,负责缩放节点;
- Horizontal Pod Autoscaler(HPA),可自动缩放部署或副本集中的炉床数量。
群集自动缩放可与水平炉床自动缩放结合使用,以动态控制计算资源和遵守服务水平协议(SLA)所需的系统并发程度。
集群自动扩展在很大程度上取决于托管集群的云基础架构提供商的功能,并且HPA可以独立于IaaS / PaaS提供商运行。
HPA开发
自从引入Kubernetes v1.1以来,水平炉床自动缩放已发生了重大变化。 HPA的第一个版本根据测量的CPU消耗量来缩放炉床,然后根据内存使用量来缩放炉床。 Kubernetes 1.6引入了一个称为自定义指标的新API,该API使HPA可以访问自定义指标。 Kubernetes 1.7添加了一个聚合级别,该级别允许第三方应用程序通过注册为API附加组件来扩展Kubernetes API。
多亏了Custom Metrics API和聚合级别,Prometheus之类的监控系统可以为HPA控制器提供特定于应用程序的指标。
水平炉床自动缩放功能是作为控制循环实现的,它会定期向Resource Metrics API(资源指标API)查询关键指标(例如CPU和内存使用情况),并向Custom Metrics API(自定义指标API)查询特定的应用程序指标。
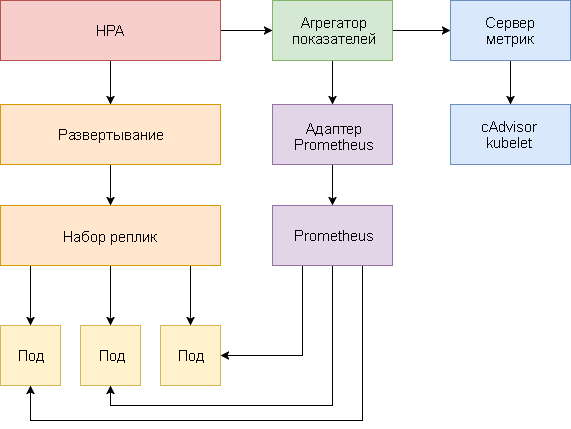
以下是为Kubernetes 1.9和更高版本配置HPA v2的分步指南。
- 安装提供关键指标的Metrics Server加载项。
- 启动演示应用程序,以查看基于CPU和内存使用情况的炉膛自动缩放工作方式。
- 部署Prometheus和自定义API服务器。 在聚合级别注册自定义API服务器。
- 使用演示应用程序提供的自定义指标配置HPA。
在开始之前,您必须安装Go版本1.8(或更高版本)并在
GOPATH中克隆
k8s-prom-hpa存储库 :
cd $GOPATH git clone https:
1.设置指标服务器
Kubernetes
Metric Server是取代
Heapster的集群内资源利用数据聚合
器 。 指标服务器从
kubernetes.summary_api收集节点和炉膛的CPU和内存使用情况信息。 Summary API是一种内存高效的API,用于将Kubelet / cAdvisor数据指标传输到服务器。
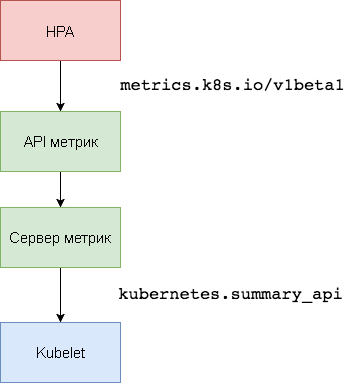
在HPA的第一个版本中,需要一个Heapster聚合器来获取CPU和内存。 在HPA v2和Kubernetes 1.8中,仅启用Metric的服务器是必需的,并且启用了Horizontal
horizontal-pod-autoscaler-use-rest-clients 。 Kubernetes 1.9默认启用此选项。 GKE 1.9附带了一个预安装的指标服务器。
在
kube-system命名空间中展开指标服务器:
kubectl create -f ./metrics-server
1分钟后,
metric-server将开始传输有关节点和Pod使用CPU和内存的数据。
查看节点指标:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
查看心律指标:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2.根据CPU和内存使用量自动缩放
要测试炉膛水平自动缩放(HPA),可以使用基于Golang的小型Web应用程序。
在
default名称空间中展开
podinfo :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
使用NodePort服务通过以下
http://<K8S_PUBLIC_IP>:31198联系
podinfo :
http://<K8S_PUBLIC_IP>:31198 。
如果平均CPU利用率超过80%或内存消耗超过200 MiB,则指定一个将至少服务两个副本的HPA,并扩展到十个副本:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
创建HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml
几秒钟后,HPA控制器将联系度量服务器并接收有关CPU和内存使用情况的信息:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
要增加CPU使用率,请使用rakyll / hey进行负载测试:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
您可以按以下方式监视HPA事件:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
暂时删除podinfo(您必须在本指南的后续步骤之一中重新部署它)。
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3.自定义指标服务器设置
要基于自定义指标进行扩展,需要两个组件。 第一个数据库
-Prometheus时间序列数据库-收集应用程序指标并保存。 第二个组件
k8s-prometheus-adapter用构建器提供的度量标准对Custom Metrics API Kubernetes进行补充。
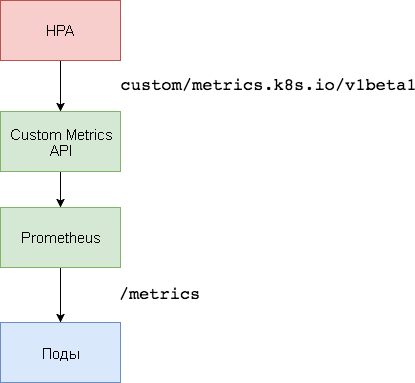
专用名称空间用于部署Prometheus和适配器。
创建一个
monitoring名称空间:
kubectl create -f ./namespaces.yaml
在
monitoring名称空间中展开Prometheus v2:
kubectl create -f ./prometheus
生成Prometheus适配器所需的TLS证书:
make certs
部署用于自定义指标API的Prometheus适配器:
kubectl create -f ./custom-metrics-api
获取Prometheus提供的特殊指标列表:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
然后提取
monitoring名称空间中所有pod的文件系统使用情况数据:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4.基于自定义指标的自动缩放
创建NodePort
podinfo服务并部署到
default名称空间:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
podinfo应用程序将传递特殊指标
http_requests_total 。 Prometheus适配器将删除
_total后缀并将此度量标准标记为计数器。
从Custom Metrics API获取每秒的查询总数:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
字母
m表示
milli-units ,因此,例如
901m是901毫秒。
创建一个HPA,如果请求数量超过每秒10个请求,它将扩展podinfo部署:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
在
default名称空间中展开HPA
podinfo :
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
几秒钟后,HPA将从度量标准API获取
http_requests值:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
以每秒25个请求的速度为podinfo服务施加负载:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
几分钟后,HPA将开始扩展部署:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
使用当前的每秒请求数,部署将永远不会达到最多10个Pod。 三个副本足以确保每个Pod每秒的请求数量少于10。
在完成负载测试之后,HPA会将部署规模减小到初始副本数:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
您可能已经注意到,自动缩放器不会立即响应指标更改。 默认情况下,它们每30秒同步一次。 此外,仅在最近3-5分钟内工作负载没有增加或减少的情况下,才会进行扩展。 这有助于防止决策冲突,并留出时间来连接集群自动扩展程序。
结论
并非所有系统都可以仅基于CPU或内存利用率(或两者)来强制执行SLA合规性。 大多数处理流量高峰的Web服务器和移动服务器都需要根据每秒的请求数进行自动缩放。
对于ETL应用程序(来自工程提取转换负载-“提取,转换,加载”),例如,当超过作业队列的指定阈值长度时,可以触发自动缩放。
在所有情况下,使用Prometheus来对应用程序进行检测并突出显示用于自动扩展的必要指示器,使您可以微调应用程序以改善流量峰值的处理并确保基础结构的高可用性。
想法,问题,意见? 加入
Slack的讨论!
这是这种材料。 我们正在等待您的评论,并在
课程中与您见面!