TensorFlow生态系统包含许多在软件和硬件堆栈的各个级别上工作的编译器和优化器。 对于那些每天使用Tensorflow的人来说,这种多层堆栈可能会产生难以理解的错误,包括编译时间和运行时,以及与使用各种硬件(GPU,TPU,移动平台等)相关的错误。
从Tensorflow图开始的这些组件可以以如下图的形式表示:
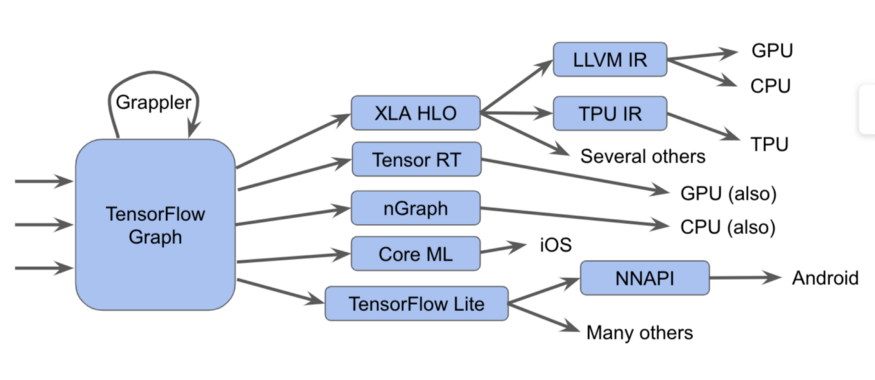 实际上更难
实际上更难在此图中,我们可以看到Tensorflow图可以以几种不同的方式运行。
一个笔记在TensorFlow 2.0中,图可以是隐式的;贪婪的执行可以单独,成组或在完整图上运行操作。 这些图或图的片段必须优化并执行。
例如:
还有更复杂的方法,例如在Grappler框架中,每个层包括许多优化遍历,可优化TensorFlow中的操作。
尽管编译器和中间表示形式的这些各种实现方式可以提高性能,但是它们的多样性给最终用户带来了问题,例如在将这些子系统配对时会混淆错误消息。 而且,新软件和硬件堆栈的创建者必须针对每种新情况调整优化和转换通道。
有了这些,我们很高兴宣布MLIR,这是一个多级中间表示。 这是一种中间视图格式和编译库,用于模型视图和生成依赖于硬件的代码的低级编译器之间。 在MLIR的介绍中,我们希望让位于基于工业质量组件的优化编译器和编译器实现的开发方面的新研究。
我们希望MLIR将引起许多团体的关注,其中包括:
- 编译器研究人员以及想要优化机器学习模型的性能和内存消耗的从业人员;
- 硬件制造商正在寻找一种将其硬件与Tensorflow结合的方法,例如TPU,智能手机中的移动神经处理器以及其他定制ASIC;
- 希望给编程语言带来好处的人们可以通过优化编译器和硬件加速器来获得好处;
什么是MLIR?
MLIR本质上是用于现代优化编译器的灵活基础结构。 这意味着它由一个中间表示(IR)规范和一组用于转换此表示的工具组成。 当我们谈论编译器时,从较高级别的视图移至较低级别的视图称为降低,并且将来我们将使用此术语。
MLIR是在LLVM的影响下构建的,从中无耻地借鉴了许多好的想法。 它具有灵活的类型系统,旨在表示,分析和转换图形,将多个抽象级别组合到一个编译级别中。 这些抽象包括Tensorflow操作,嵌套的多面循环区域,LLVM指令以及定点操作和类型。
MLIR的方言
为了区分各种软件和硬件目标,MLIR提供了“方言”,其中包括:
- TensorFlow IR,其中包括可以在TensorFlow图中完成的所有操作
- XLA HLO IR,旨在获得XLA编译器提供的所有好处,我们的输出不仅可以获取TPU的代码。
- 专为多面体表示和优化设计的实验性亲和方言
- LLVM IR(1:1)与本地LLVM视图匹配,从而允许MLIR使用LLVM为GPU和CPU生成代码。
- TensorFlow Lite设计用于为移动平台生成代码
每个方言包含一组使用不变式的特定操作,例如:“它是一个二进制运算符,其输入和输出具有相同的类型。”
扩展MLIR
MLIR没有固定的内置内置全局内部操作列表。 方言可以定义完全自定义的类型,并且MLIR可以对LLVM IR类型系统(具有一流的聚合),领域语言抽象(例如量化类型)进行建模,这对于ML优化的加速器很重要,并且在将来,甚至是Swift或Clang类型的系统。
如果要将新的低级编译器附加到此系统,则可以创建新的方言,然后从TensorFlow图的方言降到您的方言。 这为硬件开发人员和编译器开发人员简化了路径。 您可以将方言定位到同一模型的不同级别,高级优化器将负责IR的特定部分。
对于编译器研究人员和框架开发人员,MLIR允许您在每个级别创建转换,您可以在IR中定义自己的操作和抽象,从而可以更好地为应用程序任务建模。 因此,MLIR不仅仅是LLVM的纯编译器基础结构。
尽管MLIR可用作ML的编译器,但它也允许使用机器学习技术! 这对于开发数值库的工程师非常重要,并且无法为各种ML模型和硬件提供支持。 MLIR的灵活性使在抽象级别之间移动时更容易探索代码下降策略。
接下来是什么
我们已经打开了
GitHub存储库,并邀请所有感兴趣的人(查看我们的指南!)。 在接下来的几个月中,我们将发布比该工具箱更多的功能-TensorFlow和TF Lite方言规范。 为了找到更多信息,我们可以告诉您更多信息,请参阅
Chris Luttner的
演示文稿和我们
在Github上的
自述文件 。
如果您想了解与MLIR相关的所有信息,请加入我们的
新邮件列表 ,该
邮件列表将很快专注于我们项目未来版本的公告。 和我们在一起!