引言
现在该购买存储了。 选哪一个,听谁? 供应商A谈论供应商B,还有一个集成商C告诉对方情况并为供应商D提供建议。在这种情况下,经验丰富的存储架构师也将四处走动,尤其是对于所有新供应商以及当今的SDS和超融合。
那么,您如何解决这个问题却又不傻呢? 我们(
AntonVirtual Anton Zhbankov和
korp Evgeny Elizarov)将尝试用白色用俄语讲述这一点。
本文有很多共通之处,并且实际上是“
虚拟化数据中心设计 ”在数据存储系统选择和存储技术概述方面的扩展。 我们简要地考虑了一般理论,但建议您熟悉本文。
为何
当一个新人进入论坛或在专门的聊天室(例如“存储讨论”)中并询问以下问题时,通常可以观察到这种情况:“在这里,我为存储提供了两种选择-ABC SuperStorage S600和XYZ HyperOcean 666v4,您有什么建议?”
有人开始衡量实施吓人和难以理解的筹码有什么特点,而对于一个没有准备的人来说,这些筹码根本就是中文。
因此,在比较商业报价中的规格之前,您需要长时间问自己的关键也是第一个问题是为什么? 为什么需要此存储空间?

答案将是出乎意料的,非常类似于Tony Robbins的风格-存储数据。 谢谢队长! 但是,有时我们对细节进行了如此深入的比较,以至于我们忘记了为什么要做所有这些事情。
因此,数据存储系统的任务是以给定的性能存储并提供对DATA的访问。 我们将从数据开始。
资料
资料类型
我们计划存储哪种数据? 一个非常重要的问题,甚至可以从考虑中删除许多存储系统。 例如,计划存储视频和照片。 您可以立即删除为小块随机访问而设计的系统,或具有压缩/重复数据删除专有芯片的系统。 它可能只是优秀的系统,我们不想说坏话。 但是在这种情况下,它们的优势相反会变弱(视频和照片未压缩),或者只会大大增加系统成本。
相反,如果预期用途是负载的事务型DBMS,那么出色的能够每秒传输千兆字节的多媒体流系统将是一个糟糕的选择。
数据量
我们计划存储多少数据? 数量始终增长为质量;这永远都不应忘记,尤其是在我们数据量呈指数增长的时代。 PB级系统不再常见,但是,PB级的卷越多,系统变得越具体,对中小型卷进行随机访问的系统的功能就越不熟悉。 之所以要这样做,是因为仅按块进行的访问统计表会变得大于控制器上的可用RAM。 更不用说压缩/撕裂。 假设我们想将压缩算法切换为一种更强大的算法,并压缩出20 PB的数据。 需要多长时间:半年,一年?
另一方面,如果您需要存储和处理500 GB的数据,为什么还要打扰花园呢? 这种大小的家用固态硬盘(低DWPD)仅为500。 为什么要建立光纤通道工厂并以铸铁桥的价格购买高端外部存储系统?
占总热门数据的百分比? 数据负载有多不均匀? 如果热数据量相对于总数据量很少,那么分层存储技术或闪存就可以在这里提供真正的帮助。 反之亦然,在流系统(视频监视,某些分析系统)中通常会在整个卷上负载均匀的情况下,此类技术不会产生任何效果,只会增加系统的成本/复杂性。
知识产权
数据的背面是使用此数据的信息系统。 IP具有一组继承数据的要求。 有关IP的更多信息,请参阅“设计虚拟数据中心”。
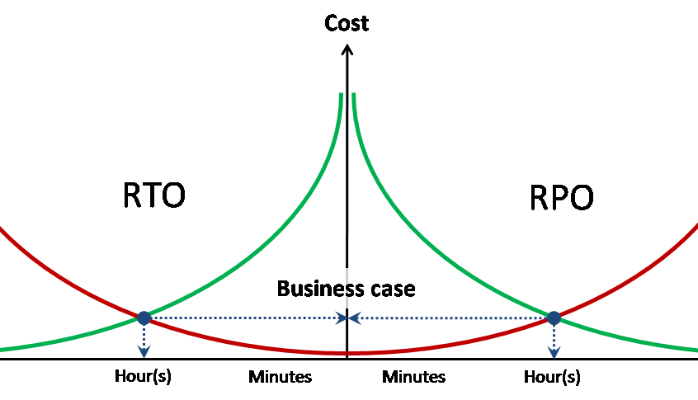
故障转移/可用性要求
容错/数据可用性的要求从使用它们的IS继承而来,并以三个数字表示
-RPO ,
RTO ,
可用性 。
可用性 -在给定的时间段内可用于与之一起使用的数据的份额。 通常用9表示。例如,每年两个九表示可用性为99%,否则每年允许95小时的不可访问性。 三个九-每年9.5个小时。
RPO / RTO-这些不是摘要指标,而是针对每个事件(事故),而不是可用性。
RPO-事故期间丢失的数据量(以小时为单位)。 例如,如果您每天备份一次,则RPO = 24小时。 即 如果发生事故并完全丢失存储,则可能会丢失多达24小时的数据(从备份开始算起)。 例如,基于为IS指定的RPO,编写备份计划。 此外,基于RPO,您可以了解需要多少同步/异步数据复制。
RTO-发生事故后的服务恢复时间(数据访问)。 根据设置的RTO值,我们可以了解是否需要城域群集或单向复制就足够了。 我是否还需要多控制器高端存储类?
性能要求
尽管这是一个非常明显的问题,但大多数困难都随之而来。 根据您是否已经拥有某种基础架构,将构建收集必要统计信息的方法。
您已经有一个存储系统,并且正在寻找一个替代品,或者想购买另一个用于扩展。 这里的一切都很简单。 您了解已经拥有了哪些服务,以及计划在不久的将来实施哪些服务。 根据当前服务,您将有机会收集性能统计信息。 确定当前的IOPS数量和当前的延迟-这些指标是什么?这些指标足以满足您的任务吗? 既可以在数据存储系统本身上也可以在与之连接的主机部分上完成此操作。
此外,您不仅需要监视当前负载,还需要监视一段时间(一个月比较好)。 查看白天最大的高峰是什么,备份会产生什么样的负载等。 如果您的存储设备或软件没有为您提供这些数据的完整集合,则可以使用免费的RRDtool,该工具可以与大多数最受欢迎的存储设备和交换机一起使用,并可以为您提供详细的性能统计信息。 还需要查看与此存储系统一起使用的主机,特定虚拟机上的负载,或在此主机上最适合您的负载。
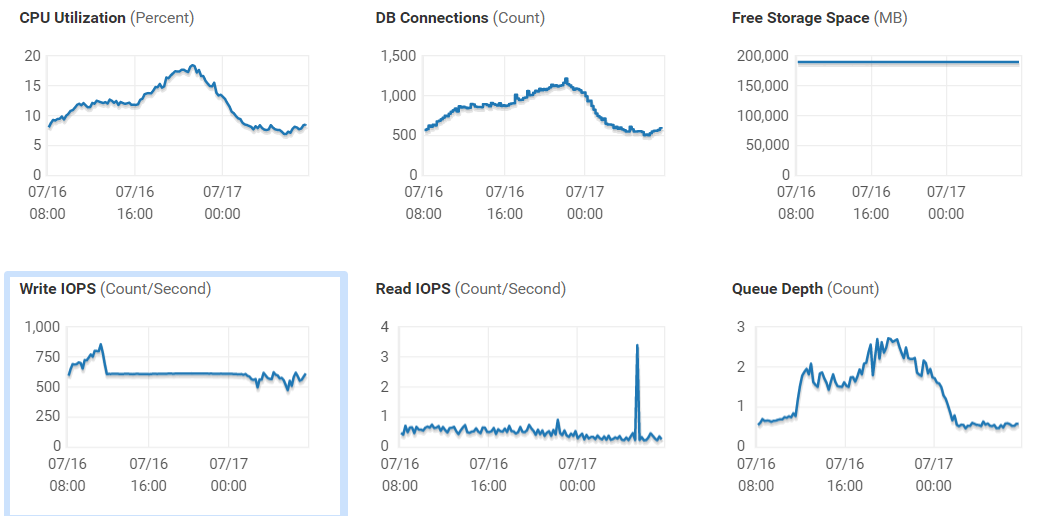
应当单独注意的是,如果卷和位于该卷上的数据存储之间的延迟差异很大-值得关注您的SAN网络,则它可能存在问题,在购买新系统之前,您应该处理此问题,因为提高当前系统性能的可能性非常高。
您可以从头开始构建基础结构,或者购买系统以使用某种新服务,而您却不知道其负载。 有以下几种选择:与专业资源的同事进行交流,以尝试找出并预测负载,与经验丰富的集成商联系,并可以为您计算负载。 第三种选择(通常是最困难的选择,特别是在涉及自写或稀有应用程序时)是试图找出系统开发人员的性能要求。
而且,注意,从实际应用的角度来看,最正确的选择是对当前设备进行试点,或者由供应商/集成商提供用于测试的设备。
特殊要求
特殊要求-所有这些都不属于直接处理和提供数据的性能,容错性和功能性要求。
数据存储系统最简单的特殊要求之一就是“异化存储介质”。 马上就很清楚,该数据存储系统应包括一个磁带库或仅一个磁带驱动器,在该磁带库上重置备份。 然后,受过专门培训的人员在磁带上签名,并自豪地将其放在特殊的保险箱中。
特殊要求的另一个示例是受保护的防震性能。
哪里
选择一个或另一个存储系统的第二个主要组成部分是有关此存储系统将位于何处的信息。 从地理或气候条件开始,以员工为结束。
顾客
此存储是为谁计划的? 该问题具有以下原因:
政府客户/商业。商业客户没有任何限制,甚至没有义务进行投标,除非根据其内部规定。
国家客户是另一回事。 44联邦法律和其他带有招标和传统知识的条款可能会受到挑战。
客户认可好吧,这里的问题很简单-选择仅受此客户可用报价的限制。
内部法规/批准的供应商/型号这个问题也非常简单,但是我们必须记住它。
身体上
在这一部分中,我们考虑了地理,通讯渠道和室内气候的所有问题。
员工
谁将使用此存储空间? 这与SHD可以直接进行的操作一样重要。
无论供应商A的存储系统多么有希望,多么酷和多么出色,如果员工只能与供应商B一起工作,那么放置它的意义就没有多大了,并且没有计划进一步购买并与A进行持续合作。
当然,问题的另一面是,受过培训的人员如何在公司中以及潜在地在此地理位置的劳动力市场中直接访问。 对于区域而言,选择具有简单接口的存储系统或进行远程集中管理的可能性非常重要。 否则,在某些时候它可能会非常痛苦。 互联网上充斥着许多故事,新员工(昨天的学生)提出了一个配置,因此整个办公室都被杀了。

环境
好吧,当然,一个重要的问题是此存储将在什么环境中工作。
- 功率/散热又如何呢?
- 什么连接
- 它将安装在哪里
- 依此类推。
这些问题通常是理所当然的,没有得到特别解决,但是有时它们可以使所有事情完全相反。
什么
供应商
今天(2019年中),俄罗斯存储市场可以分为有条件的5类:
- 顶级部门-从最简单的磁盘架到高端(HPE,DellEMC,日立,NetApp,IBM / Lenovo),应有尽有的公司
- 第二部门-阵容有限的公司,利基市场,认真的SDS供应商或新兴的公司(富士通,Datacore,Infinidat,华为,Pure等)
- 第三部门-低端,廉价SDS,在ceph和其他开放项目(Infortrend,Starwind等)上的良好实践的中小型企业解决方案
- SOHO细分-家用/小型办公室级别的小型和超小型存储系统(Synology,QNAP等)
- 导入替换的存储系统-既包括带有粘胶标签的第一个部门的硬件,也包括第二个部门的罕见代表(RAIDIX,让我们在第二个方面有所作为),但是主要是第三部分(航空磁盘,Baum,Depo等)。
该划分相当随意,并不意味着第三或SOHO段很差并且无法使用。 在具有明确定义的数据集和负载配置文件的特定项目中,它们可以很好地工作,在价格/质量比方面远远超过了第一部门。 首先要确定任务,增长前景,所需的功能,这一点很重要-然后Synology将忠实地为您服务,并且头发会变得柔软如丝。
选择供应商的重要因素之一是当前环境。 您已经拥有多少个存储系统以及哪些存储系统,工程师可以使用哪些存储系统。 您是否需要另一个供应商,另一个联系点,您是否会逐渐将整个负载从供应商A迁移到供应商B?
没有必要生产超出必要范围的实体。
iSCSI / FC /文件
在访问协议的问题上,工程师之间没有共识,争端比神学讨论更像是工程学讨论。 但通常,需要注意以下几点:
FCoE更可能死了而不是活着。
FC与iSCSI 。 通过专用IP网络来实现2019年FC超过IP存储的主要优势之一,IP存储是用于数据访问的专用工厂。 FC在IP网络方面没有全球优势,并且IP可用于构建任何负载级别的存储系统,甚至可以用于大型银行ABS的重型DBMS的系统。 另一方面,FC的死亡不是第一年的预言,而是不断干扰这一情况的。 例如,今天,存储市场中的一些参与者正在积极开发NVMEoF标准。 他是否也享有FCoE的命运-时间会证明一切。
文件访问也不值得关注。 NFS / CIFS在生产环境中表现良好,并且经过适当设计,没有比块协议更多的抱怨。
混合/全闪存阵列
经典存储系统有两种类型:
- AFA(全闪存阵列)-针对使用SSD进行了优化的系统。
- 混合-允许您同时使用HDD和SSD,或同时使用两者。
它们的主要区别是受支持的存储效率技术和最高性能水平(高IOPS和低延迟)。 这些系统和其他系统(在它们的大多数模型中,不包括低端段)都可以操作块设备和文件设备。 支持的功能和较年轻的模型还取决于系统级别;通常将其削减到最低级别。 在研究特定模型的特征时,您应该注意这一点,而不仅仅是整个生产线的能力。 而且,当然,其技术特征取决于系统级别,例如处理器,内存量,高速缓存,端口的数量和类型等。 从管理的角度来看,混合(磁盘)系统中的AFA仅在使用SSD驱动器的机制实现上有所不同,即使您在混合系统中使用SSD,也并不意味着您可以在系统的AFA级别上获得一定的性能。 。 同样,在大多数情况下,在混合系统上有效存储的内联机制将被禁用,并且将其包含在内会导致性能下降。
特殊储存
除了主要专注于操作数据处理的通用存储外,还有一些特殊的存储系统,其关键原理与通常的原理有所不同(低延迟,很多IOPS):
媒体类这些系统设计用于存储和处理大尺寸的媒体文件。 累积 延迟实际上变得无关紧要,并且在许多并行流中以宽带发送和接收数据的能力已成为重要问题。
对备份进行重复数据删除存储。由于备份的友好性不同,这在通常情况下很少见(平均备份与昨天的差异为1-2%),因此此类系统可以非常有效地将记录在其上的数据打包到数量很少的物理介质中。 例如,在某些情况下,数据压缩率可以达到200:1。
对象存储这些存储系统没有通常的带有块访问和文件管理功能的卷,并且它们大多数都类似于一个巨大的数据库。 通过唯一标识符或元数据(例如,所有JPEG格式的对象,创建日期在XX-XX-XXXX和YY-YY-YYYY之间)可以访问存储在此类系统中的对象。
遵守制度 。
今天在俄罗斯并不常见,但是值得一提。 这些存储系统的目的是确保数据存储符合安全策略或法规要求。 在某些系统(例如,EMC Centera)中,实现了禁止删除数据的功能-转动钥匙并进入此模式后,管理员和其他任何人都无法物理删除已记录的数据。
专有技术
闪存缓存
Flash Cache是使用闪存作为第二级缓存的所有专有技术的通用名称。 使用闪存缓存时,通常会计算存储量以提供磁盘的稳定负载,而峰值缓存则负责峰值负载。
有必要了解负载配置文件和对存储卷块的调用的本地化程度。 闪存缓存是一种用于请求具有高度本地化的负载的技术,实际上不适用于均匀负载的卷(例如,分析系统)。
市场上有两种闪存缓存实现:
- 只读。 在这种情况下,仅缓存读取的数据,而写入直接进入磁盘。 一些制造商(例如NetApp)认为写入其存储系统是最佳选择,而缓存则无济于事。
- 读/写。 不仅可以读取还可以缓存写入,因此可以缓存流并减少RAID Penalty的影响,因此,在没有这种最佳写入机制的情况下,可以提高存储的整体性能。
分层
多级存储(撕裂)是一种将级别组合到具有不同性能的单个磁盘池中的技术,例如SSD和HDD。在访问数据块明显不均匀的情况下,系统将能够通过将已加载的数据块移至高性能级别,而将冷的数据块移至较慢的级别,从而自动平衡数据块。中下阶层的混合系统使用分层存储,并按计划在各个级别之间移动数据。同时,最佳模型的分层存储块大小为256 MB。这些功能不允许我们将多级存储技术视为提高生产率的技术,因为许多人错误地认为这是一种技术。中低端系统中的多层存储是一种用于优化负载不均的系统的存储成本的技术。快照
无论我们如何谈论存储的可靠性,丢失数据的机会都与硬件问题无关。就像病毒,黑客或其他任何不经意地删除/破坏数据一样。因此,备份生产数据是工程师工作不可或缺的一部分。快照是某个时间点上卷的快照。与大多数系统一起使用时,例如虚拟化,数据库等。我们需要拍摄快照,从中将数据复制到备份副本,而我们的IP可以安全地继续使用此卷。但这是值得记住的-并非所有快照都同样有用。不同的供应商使用不同的方法来创建与其架构相关的快照。CoW(写时复制)。当您尝试写入数据块时,其原始内容将被复制到一个特殊的区域,然后正常记录。这样可以防止快照中的数据损坏。自然,所有这些“寄生”数据操作都会给存储系统造成额外的负载,因此,具有类似实现的供应商建议不要使用十几个快照,也不要在高负载的卷上完全使用它们。RoW(写重定向)。在这种情况下,原始卷自然会冻结,并且当您尝试写入数据块时,存储系统会将数据写入可用空间中的特殊区域,从而更改该块在元数据表中的位置。这使您可以减少重写操作的数量,从而最终消除性能下降并消除对快照及其数量的限制。关于应用程序,也有两种类型的快照:应用程序有效。在创建快照时,存储系统会在使用者的操作系统中提取一个代理,该代理会从内存到磁盘强制刷新磁盘缓存,并强制创建该应用程序。在这种情况下,从快照还原时,数据将保持一致。崩溃一致。在这种情况下,不会发生这种情况,快照将按原样创建。从这样的快照中恢复时,图片就像是突然关闭电源一样,并且可能有一些丢失的数据挂在缓存中并且没有到达磁盘。这样的快照更易于实现,不会导致应用程序性能下降,但可靠性较低。为什么在存储系统上需要快照?- 直接从存储进行无代理备份
- 根据真实数据创建测试环境
- 对于文件存储,可以通过使用存储快照而不是系统管理程序来将其用于创建VDI环境。
- 通过以远高于备份频率的频率创建计划的快照来确保低RPO
克隆化
克隆卷-的工作原理与快照类似,但不仅可以读取数据,还可以完全使用快照。我们能够获得包含所有数据的精确副本,而无需进行物理副本,从而节省了空间。通常,在测试与开发中或者如果您要检查IS上某些更新的功能,则使用卷克隆。克隆将使您就磁盘资源而言,能够尽可能快速,经济地执行此操作,仅修改的数据块将被写入。复制/日记
复制是一种在另一个物理存储系统上创建数据副本的机制。通常,每个供应商都有一项专有技术,只能在自己的生产线内工作。但是,还有第三方解决方案,包括在虚拟机监控程序级别上运行的解决方案,例如VMware vSphere Replication。专有技术的功能及其可用性通常通常比通用技术要优越得多,但是不适用于例如需要从NetApp到HP MSA的副本的情况。复制分为两个亚种:Synchronous。在同步复制的情况下,写入操作将立即发送到第二个存储系统,并且直到远程存储系统确认后才确认执行。因此,访问延迟在增加,但是我们拥有数据的精确镜像副本。即
对于丢失主存储的情况,RPO = 0。异步的。写操作仅在主存储系统上执行,并立即得到确认,同时在缓冲区中累积以将数据包传输到远程存储系统。这种复制类型适用于价值较低的数据,无论是带宽较低的通道还是延迟较大的通道(对于超过100 km的距离而言,通常如此)。 RPO =数据包发送频率。通常存在带有复制的日志记录机制磁盘操作。在这种情况下,将分配一个特殊的日志记录区域,并存储一定时间深度或受日志量限制的记录操作。对于某些专有技术,例如EMC RecoverPoint,它与系统软件集成在一起,可让您将特定的书签绑定到特定的日记帐分录。因此,不仅可以在4月23日11小时59秒13毫秒,而且可以在“ DROP ALL TABLES; 提交。”都市圈
Metro群集是一项技术,可让您在两个存储系统之间创建双向同步复制,从侧面看,该对看起来像一个存储系统。它用于创建在地铁距离(小于100公里)处具有地理间隔的肩部的群集。使用虚拟化环境中的示例,城域集群可让您创建具有虚拟机的数据存储,该虚拟机可直接从两个数据中心记录。在这种情况下,将在虚拟机管理程序级别创建一个群集,该群集由连接到该数据存储区的不同物理数据中心中的主机组成。您可以执行以下操作:- . , , . RTO = (15 VMware) + .
- Disaster avoidance , -, . 1, , , 2 .
从技术上讲,存储虚拟化是将另一个存储系统中的卷用作磁盘。虚拟化存储系统可以简单地将外部卷作为自己的卷推送到使用者,同时将其镜像到另一个存储系统,甚至可以从外部卷创建RAID。存储虚拟化类别中的经典代表是EMC VPLEX和IBM SVC。好吧,当然是具有虚拟化功能的存储-NetApp,Hitachi,IBM / Lenovo Storwize。您为什么需要它?- 存储级别的冗余。在卷之间创建一个镜像,其中一半在HP 3Par上,另一半在NetApp上。EMC的虚拟器。
- . , 3Par, , Dell. 3Par, VPLEX . , . Dell, 3Par .
- .
/
压缩和重复数据删除是那些可以节省磁盘空间的技术。值得一提的是,原则上并非所有数据都经过压缩和/或重复数据删除,而对某些类型的数据则进行了更好的压缩和重复数据删除,反之亦然。压缩和重复数据删除有两种类型:内联 -数据块在将数据写入磁盘之前先进行压缩和重复数据删除。因此,系统仅计算块的哈希值,并根据表将其与现有哈希值进行比较。首先,这比仅写入磁盘要快,其次,我们不消耗额外的磁盘空间。发布-当已经对磁盘上的记录数据执行了这些操作时。因此,首先将数据写入磁盘,然后才计算哈希值,并删除多余的块,并释放磁盘资源。值得一提的是,大多数供应商都使用这两种类型,这使您可以优化这些流程,从而提高其效率。大多数存储供应商都有可用的实用程序,可让您分析数据集。这些实用程序根据存储系统中实现的相同逻辑工作;因此,估计的效率水平将重合。同样,不要忘记,许多供应商都提供了效率保证程序,这些程序所承诺的水平不低于某些(或全部)数据类型的声明水平。并且不要忽略该程序,因为通过为您的任务计算系统,并考虑到特定系统的效率系数,您可以节省体积。还值得考虑的是,这些程序是为AFA系统设计的,但是由于购买了较小数量的SSD,与传统系统中的HDD相比,这将降低它们的成本,并且如果不与磁盘系统的成本进行比较,那么它将非常接近它。型号
在这里,我们提出了正确的问题。“这里为我提供了两个存储选项-ABC SuperStorage S600和XYZ HyperOcean 666v4,您推荐什么?转为“在这里,我为我们提供了两个存储选项-ABC SuperStorage S600和XYZ HyperOcean 666v4,您有何建议?具有生产/测试/开发循环的目标负载混合VMware虚拟机。测试=富有成效。每个150 TB,最高性能为80,000 IOPS 8kb块50%随机访问80/20读写。300 TB用于开发,足够50,000 IOPS,80个随机,80个条目。在一个站点上进行测试,预期在都市集群RPO = 15分钟RTO = 1小时,异步复制RPO = 3小时中可以生产。将会有50TB的DBMS,这对他们来说很不错。我们到处都有戴尔服务器,旧的日立存储系统几乎无法应付,我们计划在容量和性能方面增加50%的负载。”正如他们所说,正确制定的问题包含了80%的答案。附加信息
根据作者的说法,您还应该熟悉什么书本
- Olifer和Olifer“计算机网络”。这本书将有助于系统化并可能更好地理解IP /以太网存储系统的数据传输介质的工作方式。
- “ EMC信息存储和管理”。一本关于存储基础知识,为什么,如何以及为什么的好书。
论坛和聊天
一般建议
价钱
现在,关于价格-通常,如果遇到存储价格,通常是标价,每个客户都将从中获得单独的折扣。折扣大小包含大量参数,因此,在没有向分销商请求的情况下,根本无法预测贵公司将收到的最终价格。但是同时,最近低端型号开始出现在普通的计算机商店中,例如nix.ru或xcom-shop.ru。在其中,您可以立即以固定价格购买感兴趣的系统,例如任何计算机组件。但是我想马上指出,对TB / $的直接比较是不正确的。如果从这种角度来看,最简单的JBOD +服务器将是最便宜的解决方案,它将无法提供成熟的双控制器存储系统所提供的灵活性或可靠性。这根本不意味着JBOD令人讨厌和肮脏,只需要再次非常清楚地了解您将如何以及出于何种目的使用此解决方案。您经常可以听到,JBOD没有任何问题,只有一个背板。但是,后平原也可能失败。一切迟早都会崩溃。合计
相互比较系统不仅需要价格,或者不仅是生产率,还需要所有指标的总和。
仅在确定需要硬盘时才购买硬盘。 相反,对于低负载和不可压缩的数据类型,值得关注大多数供应商现在拥有的SSD存储效率保证程序(即使在俄罗斯,它们也确实有效),但这完全取决于将要使用的应用程序和数据。位于此存储上。
不要追求便宜。 有时,许多不愉快的时刻隐藏在这些时刻之下,叶夫根尼·伊利扎洛夫(Yevgeny Elizarov)在他有关
Infortrend的文章中对此进行了描述。 最终,这种便宜可以降临到您身边。 不要忘记-“僵硬付出两次”。