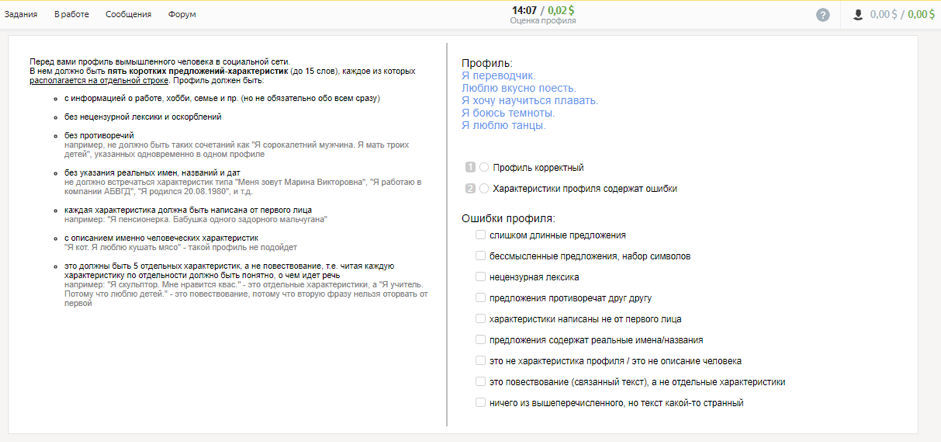
Toloka是用于机器学习任务的最大的机器标记数据源。 每天,在Tolok,成千上万的艺术家产生超过500万个收视率。 对于与机器学习有关的任何研究和实验,都需要大量的质量数据。 因此,我们开始发布开放的数据集,用于各个学科领域的学术研究。
今天,我们将分享到第一个公共数据集的链接,并讨论它们的组装方式。 我们还将向您展示在平台名称中要强调的地方。
一个有趣的事实:人工智能技术越复杂,就越需要人工帮助。 人们对图像进行分类以训练计算机视觉; 人们评价页面与搜索查询的相关性。 人们将语音转换为文本,以便语音助手学习理解和说话。 机器需要人工评估,以便在没有人的情况下工作得更好,并且比人更好。
以前,许多公司专门在经过特殊培训的员工(评估员)的帮助下收集此类评估。 但是随着时间的流逝,机器学习领域的任务太多了,并且大多数情况下,任务本身不再需要特殊的知识和经验。 因此,需要“人群”(crowd)的帮助。 但是靠他们自己,并不是每个人都能找到大量随机的表演者并与他们一起工作。 众包平台解决了这个问题。
Yandex.Toloka(正确的发音方式,重点是最后一个音节)是世界上最大的众包平台之一。 我们拥有超过400万注册用户。 每天有500多个项目在我们的帮助下收集评估。 令人高兴的事实:今年在Data Fest会议的Data Labeling部分中,来自不同公司的所有六位发言人都提到Toloka是其项目的标记来源。
关于在商业中使用Toloka的说法已经很多。 今天,我们将讨论我们认为同样有用的其他领域。
托洛克研究
众包以及一般来说,大规模收集人类标记的任务与机器学习的工业应用大致相同。 这是所有技术公司都花很多钱的领域。 但与此同时,由于某种原因,在研究方面投资不足的是她:与ML的其他领域相比,在与人群合作方面,很少进行认真的研究和发表文章。
我们想改变这一点。 我们的团队不仅将Toloka视为解决应用问题的工具,而且还将其视为各个领域的科学研究的平台。
Toloka公共数据集
我们希望支持科学界并吸引研究人员加入Toloka,因此我们开始为非商业学术目的发布数据集。 研究人员可能会对不同方向的研究感兴趣:这里是聊天机器人,以及用于测试收费判决汇总模型,语言研究和计算机视觉问题的数据。 让我们谈谈它们:
Toloka Persona Chat Rus一万个对话的数据集将帮助对话系统的研究人员制定出训练聊天机器人的方法。 我们与
MIPT神经系统和深度学习实验室的项目
iPavlov一起进行了
准备 ,该项目在对话式人工智能领域进行研究,并开发了
DeepPavlov ,这是一个用于创建交互式助手的开放库。 Persona Chat Rus数据集包含描述某个人的性格的配置文件以及研究参与者之间的对话。
如何收集数据在第一阶段,在Toloka用户的帮助下,我们收集了个人资料,其中包含有关一个人,他的爱好,职业,家庭和生活事件的信息,并选择了适合对话的信息。
在第二阶段,我们邀请参与者扮演这些个人资料之一所描述的人的角色,并在Messenger中相互交流。 对话的目的是更多地了解对话者并自我介绍。 产生的对话框已由其他表演者检查。

Toloka聚合相关性2数据集使您可以探索众包中的质量控制方法。 它包含2016年对“相关性(两个等级)”项目收集的表演者的将近500万个匿名评估。 您会在这里找到匿名的通行者评估和参考评估,这将有助于评估答案的质量。 对这些数据的研究将使我们能够追踪表演者的意见如何影响最终评估的质量,哪种结果汇总方法更好地使用以及需要收集多少意见才能获得可靠的答案。
如何收集数据向承包商提供了一个请求以及设置该请求的用户所在地区,该文件的屏幕截图和链接,使用搜索引擎和答案选项的能力:“相关”,“不相关”,“未显示”。
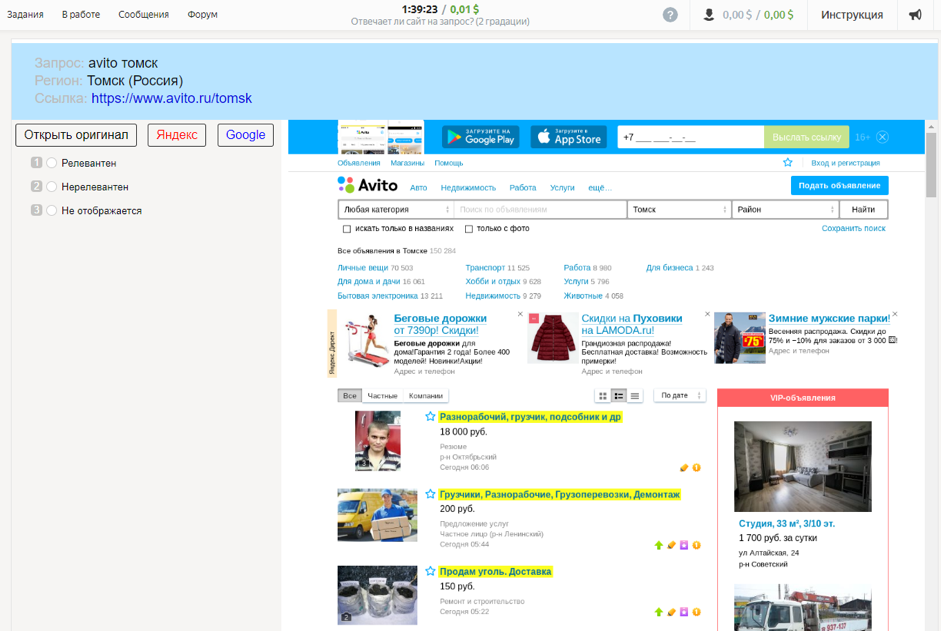
Toloka聚合相关性5该数据集与上一个数据集相同,只是此处的估计不是在二进制中收集的,而是在项目“相关性(5个等级)”中以五点规模收集的。 数据集包含超过一百万个评分。
如何收集数据对五个等级的文件进行评估更为复杂,并且需要更多的资格。 向承包商提供了请求和设置请求的用户所在的区域,文档的屏幕快照及其链接,使用搜索引擎的按钮以及五个答案选项:“重要”,“有用”,“相关+”,“相关-”,“不讲究”。

质量的主要指标是根据控制任务(黄金集)估算的汇总答案的准确性。 数据集中的某些任务没有一个,但是有几个正确答案。 这些答案中的任何一个都被认为是正确的。 主要汇总方法的准确性:
●多数意见是89.92%。
●戴维德·斯基(Dawid-Skene)-90.72%。
●GLAD-90.16%。
来自人群智慧的词法关系(LRWC)数据集包含俄语母语人士对单词之间的属种关系的看法:一般(超名)与私有(简称)之间的联系。 由研究员Dmitry Ustalov于2017年收集。
如何收集数据为了进行研究,采用了300个最常用的现代俄语名词。 使用叙词表(RuTez,RuWordNet)和自动方法来形成同义词(Watset,Hyperstar),获得了10,600个属对(例如“小猫”-“哺乳动物”)。 该研究的参与者需要回答以下问题:“小猫真的是哺乳动物的一种吗?” 为了正确地表达这个问题,使用形态分析仪和pymorphy2生成器将同义字放入属格中。
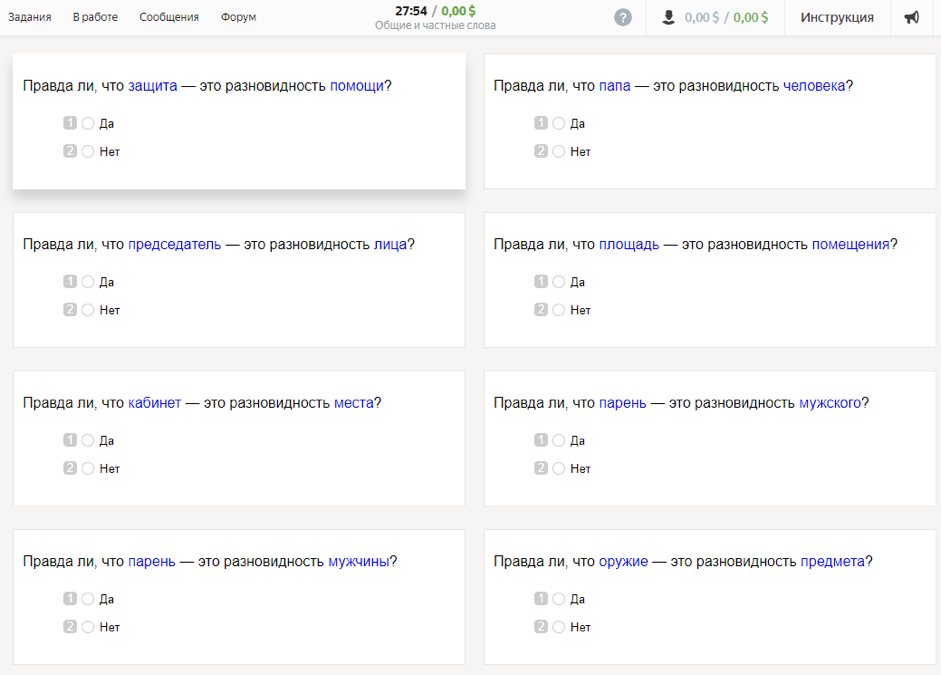
每对都由7位年龄超过20岁的俄语俄语表演者来区分。 根据所有估算值汇总后的结果,有4576对单词收到肯定答案,而6024对单词则为否定。 有趣的是,研究参与者在选择否定答案而不是肯定答案上更加一致。
俄语的人类注释意义歧义词语境数据集包含20562个单词的2562个上下文含义,代表最大范围的语义含义。 该研究由德米特里·乌斯塔洛夫(Dmitry Ustalov)于2017年进行。
如何收集数据向研究参与者展示了该单词及其在语音中的用法示例。 有必要在话语上下文中确定单词的含义,并选择答案之一。

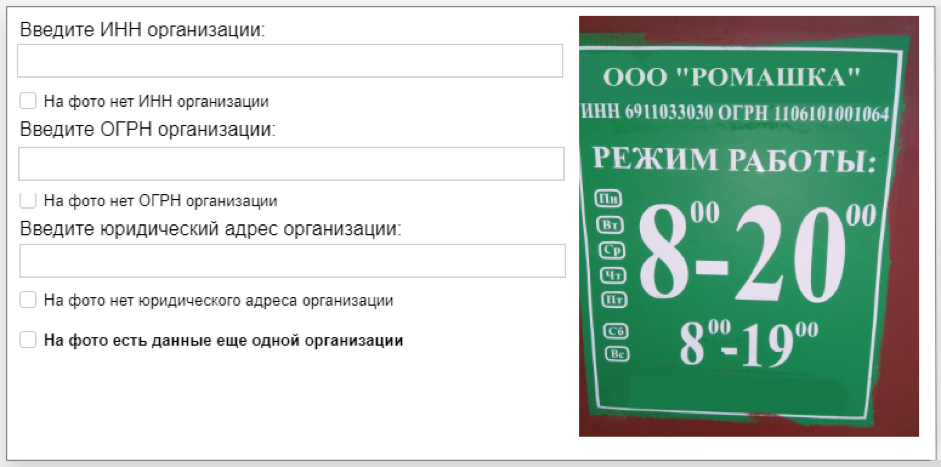
Toloka业务ID识别对于此数据集,我们准备了上万张组织信息板的照片和一个带有数字(TIN和PSRN)的文本文件,这些文件已在板上标明。 从这些数据中获悉,计算机视觉模型将能够识别图像中的数字序列。 该数据集由Yandex.Directory服务提供。
如何收集数据首先,我们在Toloka移动应用程序中启动了该任务:邀请表演者到地图上标记的地址,找到组织并为其信息板拍照。 此任务和其他现场任务有助于维护Yandex.Directory中的最新信息。
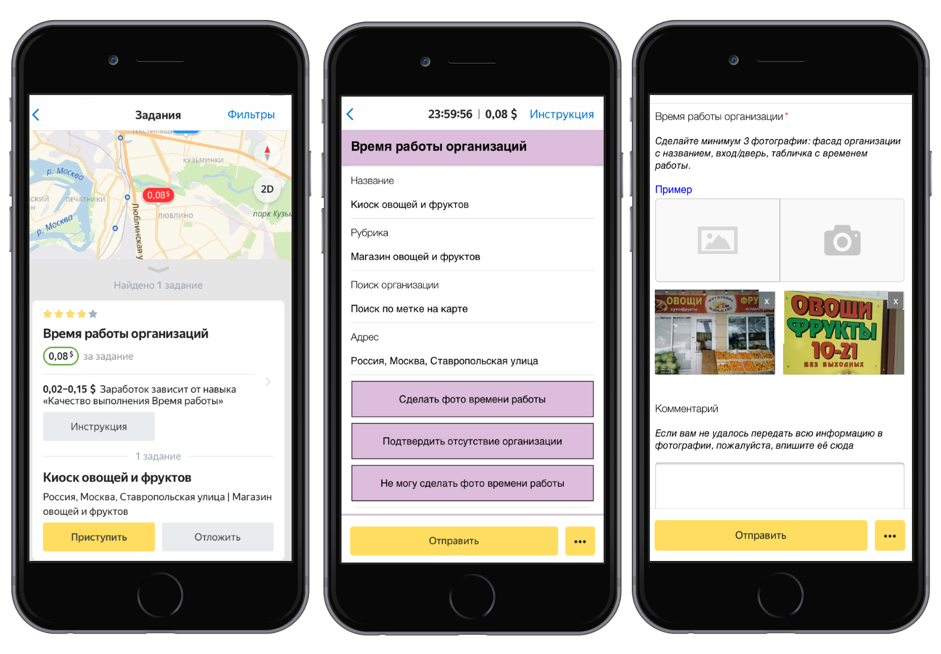
然后由其他执行者检查已完成任务的质量。 我们发送了带有TIN和PSRN的照片以供解密。 骗子从照片中重新打印这些数字,然后我们处理了结果并形成了数据集。
Toloka聚合功能数据集包含1000项任务中的约6万个评分,以及几乎所有任务的正确答案。 艺术家根据成人内容的可用性将网站分为五类。 除了每个任务,还附加了52个可用于预测类别的实值指标。
您可以从以下链接选择和下载数据集:
https :
//toloka.yandex.ru/datasets/ 。 我们不打算对此进行详细说明,并敦促研究人员注意众包并谈论其项目。