(第一部分在这里: https : //habr.com/en/post/456446/ )
头孢
引言
由于网络是Ceph的关键要素之一,并且在我们公司中有些特定,因此我们将首先向您介绍一下。
对Ceph本身(主要是网络基础结构)的描述将少得多。 仅介绍Ceph服务器和Proxmox虚拟化服务器的某些功能。
因此:网络拓扑本身是作为Leaf-Spine构建的。 经典的三层体系结构是一个网络,其中包含核心 (核心路由器), 聚合 (聚合路由器)并直接与Access客户端(访问路由器)连接:
三级方案
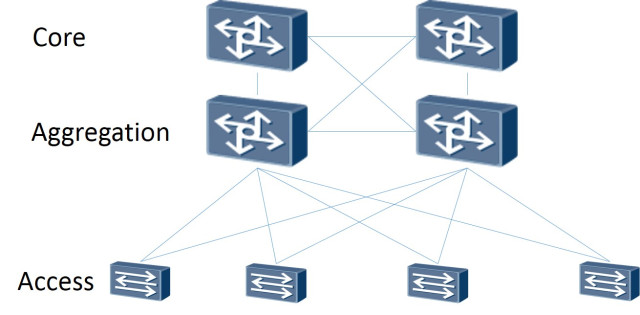
Leaf-Spine拓扑包含两个级别: Spine (大致来说是主路由器)和Leaf (分支)。
两级方案

所有内部和外部路由都基于BGP。 XCloud是处理访问控制,公告和更多内容的主要系统。
用于通道预留(以及用于扩展)的服务器连接到两个L3交换机(大多数服务器连接到Leaf交换机,但是某些网络负载增加的服务器直接连接到该交换机的Spine),并通过BGP宣布其单播地址,以及服务的任意播地址(如果有几台服务器为服务流量提供服务,并且ECMP平衡足以满足他们的需求)。 该方案的一个单独功能是使用基于RFC 5549的BGP未编号标准,这不仅使我们可以节省地址,还需要工程师熟悉IPv6世界。宴会和连通性出现问题。 但是,在切换到FRRouting之后(那些积极的贡献者是我们的网络设备供应商:Cumulus和XCloudNetworks),我们还没有看到更多的此类问题。
为了方便起见,我们将整个总体方案称为“工厂”。
寻找方法
群集网络配置选项:
1)BGP上的第二个网络
2)使用LACP的两个单独的堆叠式交换机上的第二个网络
3)在两个单独的隔离式交换机上使用OSPF的第二个网络
测验
测试分为两种类型:
a)使用iperf,qperf,nuttcp实用程序的网络
b)内部测试Ceph ceph-gobench,rados实验台,创建了rbd,并在一个或多个线程中使用dd使用fio在其上进行了测试
所有测试均在带有SAS磁盘的测试机上进行。 rbd性能的数据并没有太多关注,它们仅用于比较。 有兴趣根据连接类型进行更改。
第一选择
网卡已连接到出厂的已配置BGP。
对于内部网络使用此方案不是最佳选择:
首先,交换形式的中间元素数量过多,这会带来额外的延迟(这是主要原因)。
其次,最初,为了通过s3传递静态数据,他们使用了在带有radosgateway的几台机器上提出的任意播地址。 这导致以下事实:从前端计算机到RGW的流量分配不均,而是沿着最短的路径传递-也就是说,前端Nginx始终转向与RGW相同的节点,该节点连接到与其共享的叶子(当然,这是不是主要参数-我们只是随后拒绝了任播地址返回静态值)。 但是出于实验的纯正性,他们决定对这种方案进行测试,以获取比较数据。
我们害怕对整个带宽进行测试,因为产品服务器使用了工厂,并且如果我们阻塞了叶子和主干之间的链接,这将损害部分销售。
实际上,这是拒绝这种计划的另一个原因。
使用带宽为3Gbps,带宽为1、10和100的Iperf测试与其他方案进行比较。
测试显示以下结果:
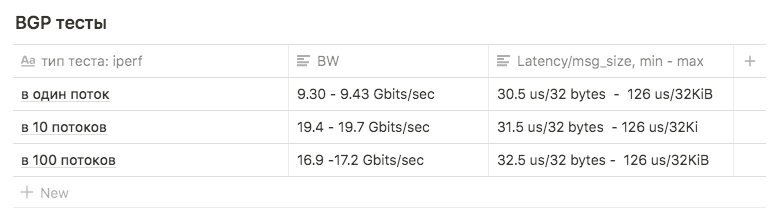
在1个流中,大约为9.30-9.43 Gbits / sec (在这种情况下,重新传输的数量猛增到39148 )。 该图证明接近一个接口的最大值,表明使用了两个接口之一。 重传次数约为500-600。
每个接口有10个9.63 Gbit / s的流,而重传的数量平均增加到17045。
在100个线程中,结果比在10 个线程中差,而重传的次数则更少:平均值为3354
第二选择
拉普
有两个Juniper EX4500交换机。 他们将它们收集在堆栈中,并通过第一个链接将服务器连接到一个交换机,将第二个链接到第二个交换机。
初始绑定设置如下:
root@ceph01-test:~# cat /etc/network/interfaces auto ens3f0 iface ens3f0 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f0 rx 8192 post-up /sbin/ethtool -G ens3f0 tx 8192 post-up /sbin/ethtool -L ens3f0 combined 32 post-up /sbin/ip link set ens3f0 txqueuelen 10000 mtu 9000 auto ens3f1 iface ens3f1 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f1 rx 8192 post-up /sbin/ethtool -G ens3f1 tx 8192 post-up /sbin/ethtool -L ens3f1 combined 32 post-up /sbin/ip link set ens3f1 txqueuelen 10000 mtu 9000 auto bond0 iface bond0 inet static address 10.10.10.1 netmask 255.255.255.0 slaves none bond_mode 802.3ad bond_miimon 100 bond_downdelay 200 bond_xmit_hash_policy 3 #(layer3+4 ) mtu 9000
iperf和qperf测试显示Bw高达16Gbits / sec。 我们决定比较不同类型的mod:
rr,balance-xor和802.3ad。 我们还比较了不同类型的散列layer2 + 3和layer3 + 4 (希望在散列计算上获得优势)。
我们还比较了变量net.ipv4.fib_multipath_hash_policy的不同sysctl值的结果(嗯,尽管它与绑定无关,但我们对net.ipv4.tcp_congestion_control发挥了一些作用。此变量上有一篇不错的ValdikSS文章 )。
但是在所有测试中,它都无法克服18Gbits / sec的阈值(此数字是使用balance-xor和802.3ad获得的 ,测试结果之间的差异不大),并且该值是通过突发“跳跃”获得的。
第三选择
OSPF协议
为了配置此选项,从交换机中删除了LACP(保留了堆栈,但仅用于管理)。 在每个交换机上,他们为一组端口收集了一个单独的VLAN(以期将来QA和PROD服务器都将卡在同一交换机中)。
为每个VLAN配置两个扁平专用网络(每个交换机一个接口)。 在这些地址之上是来自第三个专用网络(CEPH的群集网络)的另一个地址的公告。
由于公共网络 (使用SSH的公共网络 )在BGP上工作,因此我们使用frr来配置OSPF(已在系统上)。
10.10.10.0/24和20.20.20.0/24-交换机上的两个扁平网络
172.16.1.0/24-公告网络
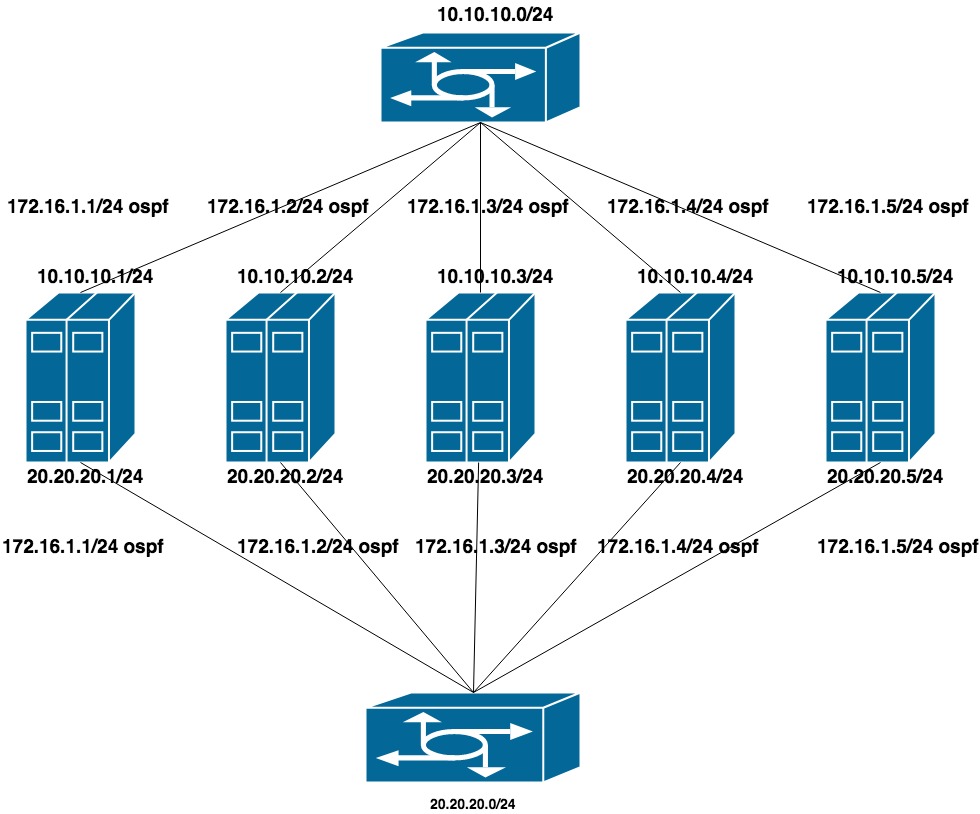
机器设置:
接口ens1f0 ens1f1查看专用网络
接口ens4f0 ens4f1看公网
机器上的网络配置如下所示:
oot@ceph01-test:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto ens1f0 iface ens1f0 inet static post-up /sbin/ethtool -G ens1f0 rx 8192 post-up /sbin/ethtool -G ens1f0 tx 8192 post-up /sbin/ethtool -L ens1f0 combined 32 post-up /sbin/ip link set ens1f0 txqueuelen 10000 mtu 9000 address 10.10.10.1/24 auto ens1f1 iface ens1f1 inet static post-up /sbin/ethtool -G ens1f1 rx 8192 post-up /sbin/ethtool -G ens1f1 tx 8192 post-up /sbin/ethtool -L ens1f1 combined 32 post-up /sbin/ip link set ens1f1 txqueuelen 10000 mtu 9000 address 20.20.20.1/24 auto ens4f0 iface ens4f0 inet manual post-up /sbin/ethtool -G ens4f0 rx 8192 post-up /sbin/ethtool -G ens4f0 tx 8192 post-up /sbin/ethtool -L ens4f0 combined 32 post-up /sbin/ip link set ens4f0 txqueuelen 10000 mtu 9000 auto ens4f1 iface ens4f1 inet manual post-up /sbin/ethtool -G ens4f1 rx 8192 post-up /sbin/ethtool -G ens4f1 tx 8192 post-up /sbin/ethtool -L ens4f1 combined 32 post-up /sbin/ip link set ens4f1 txqueuelen 10000 mtu 9000 # loopback-: auto lo:0 iface lo:0 inet static address 55.66.77.88/32 dns-nameservers 55.66.77.88 auto lo:1 iface lo:1 inet static address 172.16.1.1/32
Frr配置如下所示:
root@ceph01-test:~# cat /etc/frr/frr.conf frr version 6.0 frr defaults traditional hostname ceph01-prod log file /var/log/frr/bgpd.log log timestamp precision 6 no ipv6 forwarding service integrated-vtysh-config username cumulus nopassword ! interface ens4f0 ipv6 nd ra-interval 10 ! interface ens4f1 ipv6 nd ra-interval 10 ! router bgp 65500 bgp router-id 55.66.77.88 # , timers bgp 10 30 neighbor ens4f0 interface remote-as 65001 neighbor ens4f0 bfd neighbor ens4f1 interface remote-as 65001 neighbor ens4f1 bfd ! address-family ipv4 unicast redistribute connected route-map redis-default exit-address-family ! router ospf ospf router-id 172.16.0.1 redistribute connected route-map ceph-loopbacks network 10.10.10.0/24 area 0.0.0.0 network 20.20.20.0/24 area 0.0.0.0 ! ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32 ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 ! route-map ceph-loopbacks permit 10 match ip address prefix-list ceph-loopbacks ! route-map redis-default permit 10 match ip address prefix-list default-out ! line vty !
在这些设置上,网络测试iperf,qperf等。 显示两个通道的最大利用率为19.8 Gbit /秒,而延迟降至20us
Bgp router-id字段:用于在处理路由信息和构建路由时标识节点。 如果未在配置中指定,则选择主机IP地址之一。 不同的硬件和软件制造商可能具有不同的算法,在我们的案例中,FRR使用了最大的环回IP地址。 这导致了两个问题:
1)如果我们尝试挂断一个比当前地址更多的地址(例如,来自网络172.16.0.0的私有地址),则这将导致router-id发生更改,并因此重新安装当前会话。 这意味着短暂的中断和网络连接的丢失。
2)如果我们尝试挂断由多台计算机共享的任播地址,并将其选为路由器ID ,则网络上会出现两个具有相同路由器ID的节点。
第二部分
经过质量检查测试后,我们开始升级战斗Ceph。
网路
从一个网络迁移到两个网络
群集网络参数是无法通过ceph tell osd指定OSD即时更改的参数之一。 在配置中更改它并重新启动整个集群是一个可以容忍的解决方案,但是我真的不希望停机时间很小。 用新的网络参数重新启动一个OSD也是不可能的-有时我们会有两个半集群-旧网络上的旧OSD,新网络上的新OSD。 幸运的是,群集网络参数(顺便说一下,还有public_network)是一个列表,也就是说,您可以指定多个值。 我们决定逐步采取行动-首先在配置中添加一个新网络,然后删除旧的网络。 Ceph按顺序浏览网络列表-OSD首先开始使用首先列出的网络。
困难之处在于,第一个网络通过bgp工作并连接到一个交换机,第二个网络连接到ospf并连接到其他未物理连接到第一个交换机的网络。 在过渡时,有必要在两个网络之间临时进行网络访问。 设置工厂的特殊之处在于,如果不在发布列表中,则无法在网络上配置ACL(在这种情况下,它是“外部”,并且只能在外部创建ACL。它是在西班牙创建的,但是没有到达)在叶子上)。
解决方案是一个拐杖,很复杂,但是有效:通过bgp与ospf同时发布内部网络。
过渡顺序如下:
1)在两个网络上为ceph配置群集网络:通过bgp和ospf
在frr config中,无需更改任何内容,只需一行
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
它不会限制我们在已通告的地址中使用,内部网络本身的地址会在环回接口上引发,这足以在路由器上配置此地址的通告的接收。
2)将新网络添加到ceph.conf配置
cluster network = 172.16.1.0/24, 55.66.77.88/27
并开始一次重新启动OSD,直到每个人都切换到172.16.1.0/24网络。
root@ceph01-prod:~#ceph osd set noout # - OSD # . , # , OSD 30 . root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \ root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done
3)然后我们从配置中删除多余的网络
cluster network = 172.16.1.0/24
并重复该过程。
就是这样,我们顺利地迁移到了新的网络。
参考文献:
https://shalaginov.com/2016/03/26/network-topology-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench