使用nginx平衡L7级别的HTTP流量,如果目标没有返回肯定的响应,则可以将客户端请求发送到下一个应用程序服务器。 对应用程序服务器的运行状况进行被动验证的机制的测试表明,文档的含糊之处以及将服务器从生产服务器池中排除的算法的特殊性。
平衡HTTP流量的摘要
有多种平衡HTTP流量的方法。 在OSI模型的级别上,网络,传输和应用程序级别之间
存在平衡技术 。
可以根据应用程序的大小
使用组合 。
流量均衡技术在应用及其维护中产生了积极的影响。 这里有一些。 应用程序的水平缩放,其中
负载分布在多个节点之间 。 通过从中移除客户端请求流来计划停用应用服务器。 为更改的应用程序功能实施A / B测试策略。 通过
向功能良好的应用服务器发送请求来提高应用程序的容错能力。
最后一个功能以两种模式实现。 在被动模式下,客户端流量中的平衡器评估目标应用程序服务器的响应,并在某些条件下将其从生产服务器池中排除。 在活动模式下,平衡器会定期以给定URI独立地将请求发送到应用程序服务器,并且对于某些响应迹象,决定将其从生产服务器池中排除。 随后,在某些条件下,平衡器将应用程序服务器返回到生产服务器池中。
被动验证应用程序服务器并将其从生产服务器池中排除
让我们仔细看看免费软件版本nginx / 1.17.0中的被动应用程序服务器检查。 应用服务器通过Round Robin算法依次选择,它们的权重是相同的。
此三步图显示了一个时间段,该时间段从向2号应用程序服务器发送客户端请求开始。 明亮的指示器表示客户端和平衡器之间的请求/响应。 黑暗指示器-Nginx和应用程序服务器之间的请求/响应。
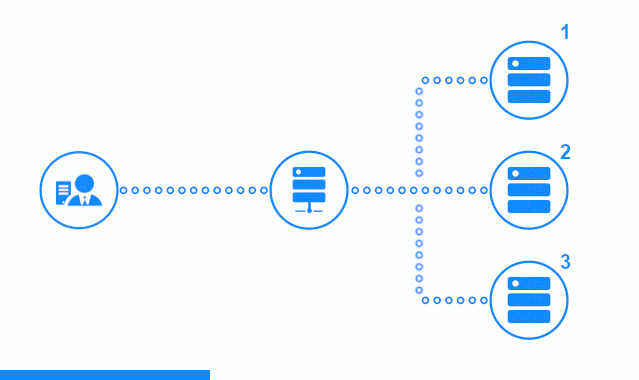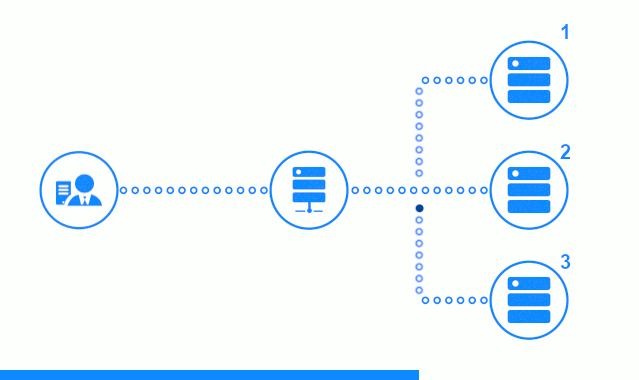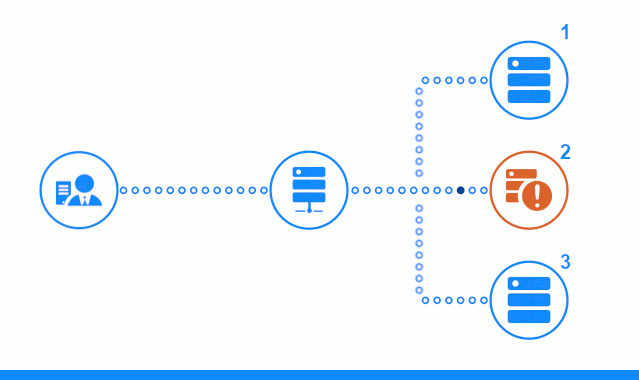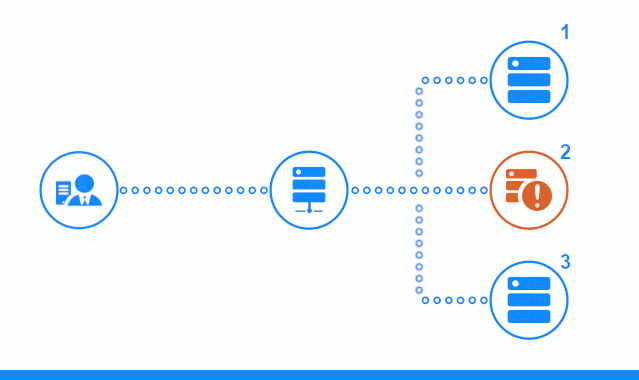
该图的第三步显示了平衡器如何将客户端的请求重定向到下一个应用程序服务器,以防目标服务器给出错误响应或根本没有响应。
proxy_next_upstream指令中指定了服务器使用以下服务器的HTTP和TCP错误列表。
默认情况下,nginx仅
将具有幂等HTTP方法的请求重定向到下一个应用程序服务器。
客户得到什么? 一方面,将请求重定向到下一个应用程序服务器的能力增加了在目标服务器出现故障时向客户端提供令人满意的响应的机会。 另一方面,很明显,先是顺序调用目标服务器,然后再进行顺序调用,这增加了对客户端的总响应时间。
最后,
应用程序服务器响应返回到客户端
, proxy_next_upstream_tries 允许的尝试计数器 结束 。
使用重定向功能到下一个工作服务器时,您需要另外协调平衡器和应用程序服务器上的超时。 在应用程序服务器和平衡器之间进行“旅行”请求的时间上限是客户端超时,即企业指定的等待时间。 在计算超时时,还必须考虑网络事件的余量(数据包传递期间的延迟/丢失)。 如果客户端每次都通过超时结束会话,而平衡器获得了有保证的答案,那么使应用程序可靠的良好意图将是徒劳的。

应用程序服务器的被动运行状况检查由指令控制,例如,其值具有以下选项:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... }
从
2019年 7月2日开始,文档
确定 max_fails参数设置了在
fail_timeout参数指定的时间内应进行的服务器尝试失败的次数。
fail_timeout参数设置在一定时间内必须进行指定次数的不成功尝试使用服务器才能使服务器不可用的时间。 以及服务器将被视为不可用的时间。
在给定示例(配置文件的一部分)中,平衡器配置为在100秒内捕获5个失败的呼叫。
将应用程序服务器返回到生产服务器池
从文档中可以
看出,fail_timeout之后的平衡器不能认为服务器无法运行。 但是,不幸的是,该文档未明确确定如何评估服务器性能。
没有实验,只能假设检查状态的机制与前面描述的类似。
期望与现实
在提出的配置中,预期平衡器具有以下行为:
- 在平衡器从生产服务器池中排除2号应用程序服务器之前,将向其发送客户端请求。
- 从2号应用程序服务器返回500错误的请求将被转发到下一个应用程序服务器,并且客户端将收到肯定的响应。
- 一旦平衡器在100秒内收到5个代码为500的响应,它将从生产服务器池中排除2号应用服务器。 100秒窗口之后的所有请求将立即发送到其余工作的应用程序服务器,而无需花费额外的时间。
- 在100秒后,平衡器必须以某种方式评估应用程序服务器的性能,并将其返回到生产服务器池中。
根据平衡器的杂志,进行了实物测试后,确定第3条陈述无效。 一旦
满足max_fails参数的条件,平衡器就会排除空闲服务器。 因此,发生故障的服务器将从服务中排除,而无需等待100秒的时间。
fail_timeout参数仅充当错误累积时间的上限。
作为第4个断言的一部分,事实证明,nginx仅通过一个请求即可检查以前从服务器维护中排除的应用程序的功能。 并且,如果服务器仍然响应错误,则在
fail_timeout之后,下一个检查将
失败 。
缺少什么?
- 在nginx / 1.17.0中实现的算法可能不是将服务器返回到生产服务器池之前检查服务器性能的最公平方法。 至少,根据当前文档,不是期望1个请求,而是max_fails中指定的数量 。
- 状态检查算法未考虑查询速度。 数值越大,尝试失败的频谱向左移的趋势就越强,并且应用服务器从工作服务器池中退出的速度太快。 我认为这会对应用程序产生不利影响,这些应用程序自身会产生“短时血块”错误。 例如,收集垃圾时。

我想问一下您,服务器运行状况检查算法是否有实际好处,该算法可以衡量失败尝试的速度?