大家好! 下周一,课程将在
Python开发人员课程的新班级开始,这意味着我们有时间发布另一篇有趣的材料,我们现在将做。 好好阅读。

早在2003年,英特尔就发布了新的奔腾4“ HT”处理器。 该处理器超频至3GHz,并支持超线程技术。

在接下来的几年中,英特尔和AMD一直在努力通过提高总线速度,二级缓存大小和减小矩阵大小以最大程度地减少延迟来实现最佳台式机性能。 2004年,频率为3 GHz的HT模型被超频至4 GHz的580 Prescott模型所取代。
向前看,似乎只是有必要增加时钟频率,但是,新处理器遭受了高功耗和散热的困扰。
您的台式机处理器今天能提供4 GHz吗? 这不太可能,因为提高性能的途径最终取决于总线速度的提高和内核数量的增加。 2006年,英特尔酷睿2取代了奔腾4,并且时钟速度低得多。
除了为广大用户提供多核处理器外,2006年还发生了其他事情。 Python 2.5终于亮了! 它已经带有with关键字的beta版本,大家都知道并喜欢它。
当使用Intel Core 2或AMD Athlon X2时,Python 2.5有一个主要限制。
这是一个GIL。
什么是GIL?
GIL(全局解释器锁定)是Python解释器中受互斥量保护的布尔值。 在主CPython字节码计算循环中使用该锁来确定当前正在执行指令的线程。
CPython支持在单个解释器中使用多个线程,但是线程必须请求访问GIL才能执行低级操作。 反过来,这意味着Python开发人员可以使用异步代码,多线程,而不必担心死锁期间在处理器级别阻塞任何变量或崩溃。
GIL简化了多线程Python编程。

GIL还告诉我们,尽管CPython可以是多线程的,但一次只能执行一个线程。 这意味着您的四核处理器会执行类似的操作(希望蓝屏除外)。
当前版本的GIL
于2009年编写,支持异步功能,即使在原则上尝试删除它或更改其要求之后,仍保持不变。
任何建议删除GIL的理由都是解释器的全局锁定不应降低单线程代码的性能。 任何在2003年尝试启用超线程的人都会理解
我在说什么 。
在CPython中放弃了Gil
如果要真正并行化CPython中的代码,则必须使用多个过程。
在CPython 2.6中,
多处理模块已添加到标准库中。 多重处理掩盖了CPython中进程的生成(每个进程都有自己的GIL)。
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
创建流程,使用编译后的模块和Python函数将命令发送给它们,然后将它们重新加入主流程。
多重处理还支持通过队列或通道使用变量。 她有一个锁定对象,该对象用于锁定主进程中的对象并从其他进程写入。
多处理有一个主要缺点。 它承载着巨大的计算负荷,这会影响处理时间和内存使用率。 即使没有无站点,CPython的启动时间也是100-200毫秒(有关更多信息,请查看
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b )。
结果,您可能在CPython中拥有并行代码,但是您仍然需要仔细计划共享多个对象的长时间运行的进程的工作。
另一种选择是使用第三方程序包,例如Twisted。
PEP554和GIL的死亡?
因此,让我提醒您,CPython中的多线程很简单,但实际上不是并行化,而是多处理是并行的,但会带来大量开销。
如果有更好的方法怎么办?绕过GIL的关键在于名称,解释器的全局锁定是解释器全局状态的一部分。 CPython进程可以具有多个解释器,因此可以具有多个锁,但是很少使用此函数,因为只能通过C-API对其进行访问。
CPython 3.8的功能之一是PEP554,它是在标准库中带有新
interpreters模块的子解释器和API的实现。
这使您可以在单个过程中从Python创建多个解释器。 Python 3.8的另一项创新是,所有解释器都将拥有自己的GIL。
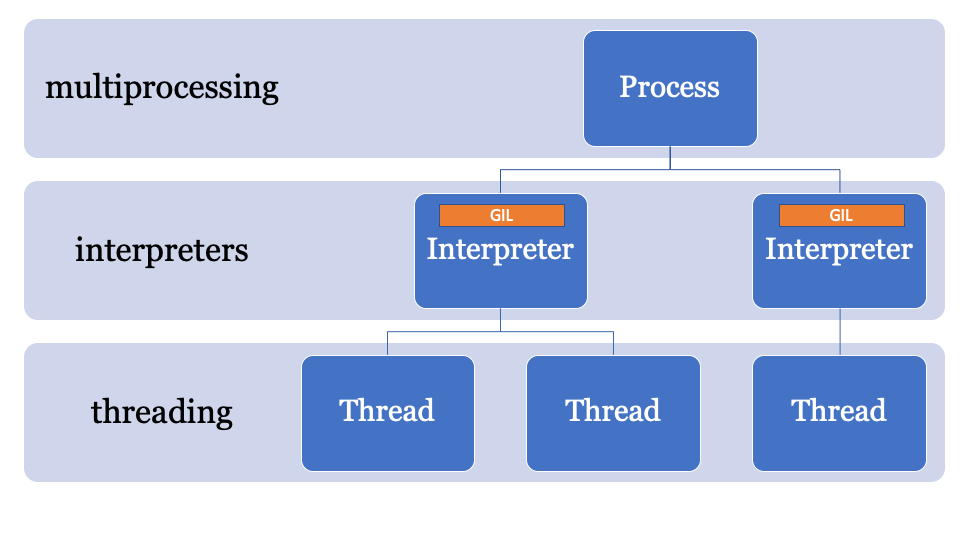
由于解释器的状态包含在内存中分配的区域,所有指向Python对象的指针(本地和全局)的集合,因此PEP554中的子解释器无法访问其他解释器的全局变量。
像多处理一样,解释器共享对象包括序列化它们并使用IPC形式(网络,磁盘或共享内存)。 有许多方法可以在Python中序列化对象,例如,
marshal模块,
pickle模块或更标准化的方法(如
json或
simplexml 。 它们每个都有其优点和缺点,并且都给计算带来了负担。
最好具有一个公共的内存空间,该内存空间可以通过特定的过程进行更改和控制。 因此,对象可以由主解释器发送并由另一个解释器接收。 这将是用于搜索PyObject指针的托管内存空间,每个解释器都可以访问该内存空间,而主进程将管理锁。
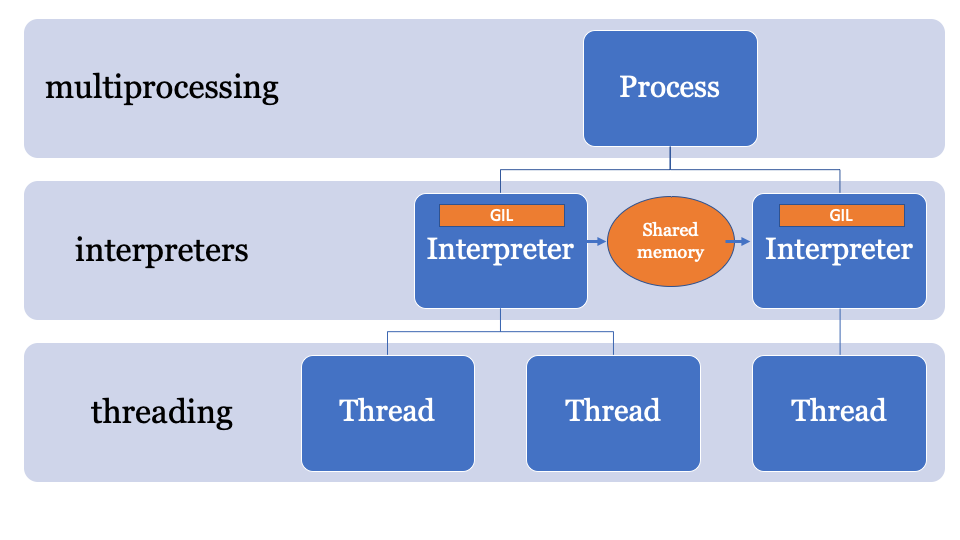
与此相关的API仍在开发中,但可能看起来像这样:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import marshal
本示例使用NumPy。 numpy数组通过通道发送,使用
marshal模块进行序列化,然后子解释器处理数据(在单独的GIL上),因此可能存在与CPU相关的并行化问题,这是子解释器的理想选择。
效率低下
marshal模块的工作速度非常快,但不如直接从内存中共享对象那样快。
PEP574引入了新的
pickle协议
(v5) ,该协议支持与其余pickle流分开处理内存缓冲区的功能。 对于大型数据对象,一次性将它们全部序列化并从子解释器反序列化将增加很多开销。
新的API可以如下(纯粹假设)实现:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import pickle
看起来有图案
本质上,该示例基于使用低级子解释器的API构建。 如果您尚未使用
multiprocessing库,则您可能会遇到一些问题。 它不像流处理那样简单,您不能说在单独的解释器中使用这样的输入数据列表运行此功能。
该PEP与其他PEP合并后,我认为我们会在PyPi中看到几个新的API。
子解释器有多少开销?
简短的答案:不仅仅是一个流,少于一个过程。
长答案:解释器具有其自己的状态,因此尽管PEP554简化了子解释器的创建,但它仍需要克隆并初始化以下内容:
__main__和importlib中的__main__ ;sys字典的内容;- 内置函数(
print() , assert等); - 溪流;
- 内核配置。
可以很容易地从内存中克隆内核配置,但是导入模块并不是那么简单。 在Python中导入模块的速度很慢,因此,如果创建子解释器意味着每次都将模块导入不同的名称空间,则会降低收益。
那异步呢?
标准库中
asyncio事件
asyncio的现有实现创建用于评估的堆栈框架,并在主解释器中
asyncio状态(因此共享GIL)。
合并PEP554(可能已经在python 3.9中使用)之后,可以使用事件循环的另一种实现方式(尽管还没有人这样做),它可以在子解释器中并行运行异步方法。
听起来很酷,也把我包起来!
好吧,不是真的。
由于CPython在同一个解释器上运行了很长时间,因此代码库的许多部分使用“运行时状态”而不是“解释器状态”,因此,如果现在引入PEP554,仍然会有很多问题。
例如,垃圾收集器的状态(在版本3.7 <中)属于运行时。
在PyCon冲刺期间的更改中,垃圾收集器的状态
开始移至解释器,以便每个子解释器将拥有自己的垃圾收集器(应如此)。
另一个问题是CPython代码库中存在一些“全局”变量以及C语言中的许多扩展。因此,当人们突然开始正确地并行化其代码时,我们看到了一些问题。
另一个问题是文件描述符属于该进程,因此,如果打开了要在一个解释器中写入的文件,则子解释器将无法访问该文件(无需对CPython进行进一步更改)。
简而言之,仍然有许多问题需要解决。
结论:GIL是否正确?
GIL将继续用于单线程应用程序。 因此,即使遵循PEP554,单线程代码也将突然变得不并行。
如果要用Python 3.8编写并行代码,将遇到与处理器相关的并行化问题,但这也是未来的趋势!
什么时候
Pickle v5和用于多处理的内存共享很可能会在Python 3.8(2019年10月)中使用,并且子解释器将出现在3.8和3.9版本之间。
如果您希望尝试使用所提供的示例,那么我创建了一个包含所有必需代码的单独分支:
https :
//github.com/tonybaloney/cpython/tree/subinterpreters。您如何看待? 写您的评论并在课程中见。