我叫Stas Kirillov,我是Yandex ML平台组的领先开发人员。 我们正在开发机器学习工具,为其提供支持和开发基础架构。 以下是我最近关于CatBoost库如何工作的演讲。 在报告中,我为那些想了解它或成为我们的贡献者的人介绍了代码的切入点和功能。
-CatBoost在Apache 2.0许可下生活在GitHub上,也就是说,它对所有人都是免费的。 该项目正在积极开发中,现在我们的存储库已超过四千颗星。 CatBoost用C ++编写,它是用于在决策树上进行梯度增强的库。 它支持多种类型的树,包括默认情况下在库中使用的所谓的“对称”树。
我们遗忘的树木有什么好处? 他们可以快速学习,快速应用和帮助学习,以根据模型的最终质量的变化对更改的参数产生更大的抵抗力,从而大大减少了对参数选择的需求。 我们的图书馆旨在使它在生产中易于使用,快速学习并立即获得良好的质量。

梯度提升是一种算法,其中我们建立了简单的预测变量来改善目标函数。 也就是说,我们没有立即构建复杂的模型,而是依次构建了许多小模型。

CatBoost的学习过程如何? 我会告诉您代码的工作原理。 首先,我们解析用户传递的训练参数,对其进行验证,然后查看是否需要加载数据。 因为数据已经可以加载(例如,在Python或R中)。接下来,我们加载数据并从边界构建网格以量化数值特征。 这对于快速学习很有必要。
分类功能我们处理的方式有所不同。 我们从一开始就对要素进行分类,然后将哈希值从零重新编号为分类要素的唯一值的数量,以便快速读取分类要素的组合。
然后,我们直接启动训练循环-机器学习的主要周期,在那里我们迭代构建树。 在此循环之后,将导出模型。
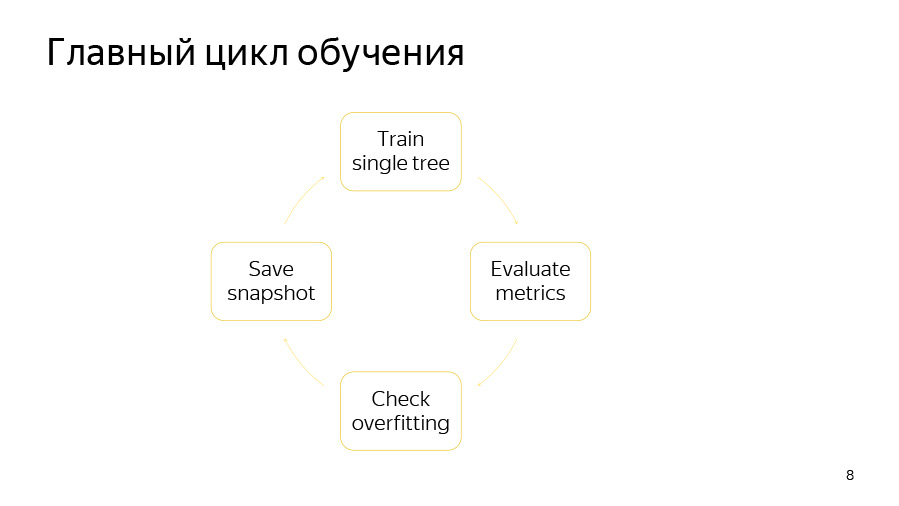
培训周期本身包括四个要点。 首先,我们正在尝试构建一棵树。 然后,我们看一下质量提高或降低的程度。 然后,我们检查再训练检测器是否起作用。 然后,如果时间合适,请保存快照。

学习一棵树是一个遍历树的循环。 在开始时,如果我们使用有序增强或具有分类功能,则我们随机选择数据排列。 然后,我们根据此排列计数计数器。 然后,我们尝试贪婪地选择这棵树中的良好分割。 通过拆分,我们仅表示一些二进制条件:某某数值特征大于该某某值,或者某某特征按某类特征反某某物大于某某特定值。
贪婪树级别循环如何安排? 在一开始,便完成了引导程序-我们对对象进行称重或采样,然后仅使用选定的对象来构建树。 如果启用了每个级别的采样选项,也可以在选择每个拆分之前重新计算引导程序。
然后,我们将导数汇总为直方图,就像对每个拆分的候选对象所做的那样。 使用直方图,我们尝试评估如果选择此拆分候选对象将发生的目标函数变化。
我们选择速度最快的候选者并将其添加到树中。 然后,我们使用选定的树对剩余的排列计算统计信息,在这些排列处更新叶中的值,为模型计算叶中的值,然后进行循环的下一个迭代。

很难在一个地方进行培训,因此在此幻灯片上-您可以将其用作某个切入点-列出了我们用于培训的主要文件。 这是greedy_tensor_search,我们在其中生活着贪婪选择分割的过程。 这是train.cpp,我们在这里有主要的CPU培训工厂。 这是aprox_calcer,其中包含更新叶子中的值的功能。 还有score_calcer-一种评估某些候选者的函数。
同样重要的部分是catboost.pyx和core.py。 这是python包装器代码,很可能你们中的许多人都会在python包装器中嵌入某种东西。 我们的python包装器是用Cython编写的,Cython是用C ++翻译的,因此此代码应该很快。
我们的R-wrapper位于R-package文件夹中。 也许有人将不得不添加或修复某些选项,对于选项,我们有一个单独的库-catboost / libs / options。
我们是从Arcadia到GitHub的,所以您会遇到许多有趣的工件。


让我们从存储库的结构开始。 我们有一个util文件夹,其中的基本原语是:向量,地图,文件系统,使用字符串和流。
我们有一个Yandex使用的共享库所在的库-很多,而不仅仅是CatBoost。
CatBoost和contrib文件夹是我们链接到的第三方库的代码。
现在让我们谈谈您将遇到的C ++原语。 首先是智能指针。 在Yandex中,自std :: unique_ptr起我们就使用THolder,并且使用MakeHolder代替std :: make_unique。

我们有自己的SharedPtr。 此外,它以两种形式存在,即SimpleSharedPtr和AtomicSharedPtr,它们的计数器类型不同。 在一种情况下,它是原子的,这意味着好几个流可以拥有一个对象。 因此,从流之间的转移角度来看,这将是安全的。
一个单独的类IntrusivePtr允许您拥有从TRefCounted类继承的对象,即,该类具有内置的引用计数器。 这是一次分配此类对象,而无需另外分配带有计数器的控制块。
我们也有自己的输入和输出系统。 IInputStream和IOutputStream是用于输入和输出的接口。 它们具有有用的方法,例如ReadTo,ReadLine,ReadAll,这些通常是InputStreams可以期望的一切。 我们有这些流的实现与控制台一起使用:Cin,Cout,Cerr和单独的Endl,这与std :: endl相似,也就是说,它将刷新流。

我们也有我们自己的文件接口实现:TInputFile,TOutputFile。 这是一个缓冲读取。 它们实现了对文件的缓冲读取和缓冲写入,因此您可以使用它们。
Util / system / fs.h具有NFs :: Exists和NFs :: Copy方法,如果您突然需要复制某些内容或检查某个文件是否确实存在。

我们有自己的容器。 他们很久以前就开始使用std :: vector,也就是说,它们只是从std :: vector,std :: set和std :: map继承而来,但我们也有自己的THashMap和THashSet,它们的一部分与unordered_map和无序设置。 但是对于某些任务来说,它们却变得更快,因此我们仍然使用它们。

数组引用类似于C ++中的std :: span。 没错,他不是在二十年出现,而是在更早的时候出现。 我们积极地使用它来将对数组的引用转移给数组,就像在大型缓冲区上分配一样,以免每次都不分配临时缓冲区。 假设,对于计数导数或某些近似值,我们可以在一些预分配的大缓冲区上分配内存,并且仅将TArrayRef传递给计数函数。 这非常方便,并且我们经常使用它。

Arcadia使用自己的一组类来处理字符串。 首先,这是TStingBuf-C ++ 17中str :: string_view的类似物。
TString根本不是std :: sting,它是一个CopyOnWrite字符串,因此您需要非常小心地使用它。 另外,TUtf16String是相同的TString,只是其基本类型不是char,而是16位wchar。
我们提供了从字符串转换为字符串的工具。 这是ToString,它是std :: to_string和FromString与TryFromString配对的类似物,它允许您将字符串转换为所需的类型。

我们有自己的异常结构,街机库中的基本异常是yexception,它继承自std :: exception。 我们有一个ythrow宏,用于添加有关在yexception处引发异常的位置的信息,它只是一个方便的包装器。
有一个std :: current_exception-CurrentExceptionMessage的类似物,此函数将当前异常作为字符串抛出。
有用于声明和验证的宏-它们是Y_ASSERT和Y_VERIFY。

而且我们有自己的内置序列化,它是二进制的,并不打算在不同版本之间传输数据。 相反,例如在分布式学习中,为了在同一修订版的两个二进制文件之间传输数据,需要此序列化。
碰巧我们在CatBoost中有两个版本的序列化。 第一个选项通过接口方法“保存”和“加载”工作,该方法序列化到流。 我们的分布式培训中使用了另一个选项,它使用了一个相当老的内部BinSaver库,可用于序列化必须在特殊工厂中注册的多态对象。 这是分布式培训所必需的,我们不太可能在这里讨论。

我们也有自己的模拟boost_optional或std :: optional-TMaybe。 类比标准品::变体-TVariant。 您需要使用它们。

有一定的约定,在CatBoost代码中,我们抛出TCatBoostException而不是yexception。 这是相同的yexception,仅在抛出异常时才添加堆栈跟踪。
而且,我们还使用CB_ENSURE宏方便地检查了一些内容,如果未执行,则抛出异常。 例如,我们经常使用它来解析选项或解析用户传递的参数。

幻灯片中的链接: 第一 , 第二
开始工作之前,请务必先检查一下代码样式,它由两部分组成。 第一种是通用代码风格,直接位于CPP_STYLE_GUIDE.md文件中存储库的根目录。 另外,在信息库的根部还为我们的团队提供了单独的指南:catboost_command_style_guide_extension.md。
我们正在尝试使用PEP8格式化Python代码。 它并不总是有效,因为对于Cython代码而言,棉短绒不适用于我们,有时PEP8也会出问题。

我们组装的特点是什么? Arcadia组件最初旨在收集最不透气的应用程序,也就是说,由于静态链接的缘故,对外部的依赖性将降至最低。 这使您可以在不同版本的Linux上使用相同的二进制文件而无需重新编译,这非常方便。 组装目标在ya.make文件中描述。 在下一张幻灯片中可以看到ya.make的示例。

如果您突然想要添加某种库,程序或其他内容,则可以首先查看相邻的ya.make文件,其次使用此示例。 在这里,我们列出了ya.make的最重要元素。 在文件的开头,我们说要声明一个库,然后列出要放入该库中的编译单元。 这里既可以是cpp文件,也可以是Cython将为其自动启动的pyx文件,然后是编译器。 库依赖关系通过PEERDIR宏列出。 它只是将相对于存储库根目录的路径写入具有库或内部其他工件的文件夹。
需要一个有用的东西GENERATE_ENUM_SERIALIZATION来生成ToString,FromString方法,以用于传递给此宏的某些头文件中描述的枚举类和枚举。

现在介绍最重要的事情-如何编译和运行某种测试。 存储库的根部是ya脚本,该脚本下载必要的工具包和工具,并且具有ya make命令(make子命令),该命令可让您使用-d开关构建-r发行版,并通过-d开关构建调试版本。 其中的伪像会继续传递并由空格隔开。
为了构建Python,我立即在这里指出了可能有用的标志。 我们正在谈论使用系统Python进行构建,在本例中是使用Python3。如果您突然在便携式计算机或开发计算机上安装了CUDA工具包,则为了加快组装速度,建议您指定-d have_cuda no标志。 CUDA的构建时间相当长,尤其是在4核系统上。

Ya ide应该已经工作了。 这是一个可以为您生成解决方案或qt解决方案的工具。 对于Windows附带的用户,我们有一个Microsoft Visual Studio解决方案,位于msvs文件夹中。
听众:
-是否通过Python包装器进行了所有测试?
Stas:
-不,我们分别在pytest文件夹中有测试。 这些是对我们的CLI界面(即我们的应用程序)的测试。 的确,它们通过pytest进行工作,也就是说,这些是Python函数,在这些函数中我们进行了子进程检查调用,并验证程序不会崩溃并且可以使用某些参数正常工作。
听众:
-C ++中的单元测试呢?
Stas:
-我们还有C ++的单元测试。 它们通常位于ut子文件夹中的lib文件夹中。 它们是这样写的-单元测试或单元测试。 有例子。 有一些用于声明单元测试类的特殊宏,以及用于单元测试功能的单独寄存器。
听众:
-要验证没有任何问题,最好同时启动它们吗?
Stas:
-是的 唯一的是,我们的开源测试仅在Linux上是绿色的。 因此,例如,如果在Mac上进行编译,则如果有五个测试失败,则无需担心。 由于参展商在不同平台上的实施方式不同或其他一些细微差异,因此结果可能会非常不同。

例如,我们将执行一项任务。 我想举一些例子。 我们有一个包含任务的文件-open_problems.md。 让我们从open_problems.md解决问题№4。 它的表述如下:如果用户将学习率设置为零,那么我们必须从TCatBoostException下降。 您需要添加选项验证。
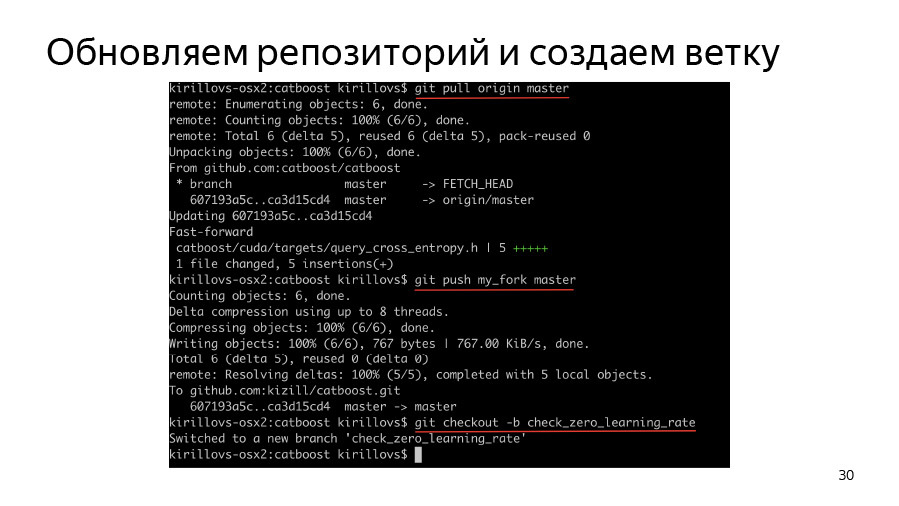
首先,我们需要创建一个分支,克隆我们的fork,克隆origin,pop origin,在fork中运行origin,然后创建一个分支并开始在其中工作。
选项解析如何工作? 就像我说的,我们有一个重要的catboost / libs / options文件夹,用于存储所有选项的解析。

我们将所有选项存储在TOption包装器中,这使我们能够了解该选项是否已被用户覆盖。 如果不是,它将保留一些默认值。 通常,CatBoost会以大型JSON字典的形式来解析所有选项,在解析过程中,字典会变成嵌套的字典和嵌套的结构。

我们以某种方式发现了-例如,通过使用grep搜索或阅读代码-我们在TBoostingOptions中拥有学习率。 让我们尝试编写仅添加CB_ENSURE的代码,使我们的学习率超过std :: numeric_limits :: epsilon,并且用户输入的内容或多或少是合理的。

在这里,我们只使用了CB_ENSURE宏,编写了一些代码,现在我们想添加测试。

在这种情况下,我们在命令行界面上添加一个测试。 在pytest文件夹中,我们有test.py脚本,该脚本中已经有很多测试示例,您可以选择一个看起来像您的任务的示例,将其复制并更改参数,以使其根据您传递的参数而开始下降或不下降。 在这种情况下,我们只需要创建一个简单的两行池即可。 (我们在Yandex中称为数据集池。这是我们的特质。)然后,如果我们通过学习率0.0,则检查二进制文件是否真的丢失了。

我们还为python-package添加了一个测试,该测试位于atBoost/ python-package / ut / medium中。 我们也有与构建python wheel包测试相关的大型测试。

此外,我们还有用于ya make--t和-A的键。 -t运行测试,-A强制所有测试运行,无论它们具有大标签还是中标签。
在这里,为了美观,我还使用了一个名为test的过滤器。 使用-F选项和稍后指定的测试名称进行设置,该名称可能是野生字符。 在这种情况下,我使用了test.py::test_zero_learning_rate*,因为在查看我们的python软件包测试时,您将看到:几乎所有函数都采用任务类型的固定装置。 这样一来,根据代码,我们的python程序包测试在CPU和GPU学习方面看起来都是相同的,并且可以用于GPU和CPU训练程序测试。

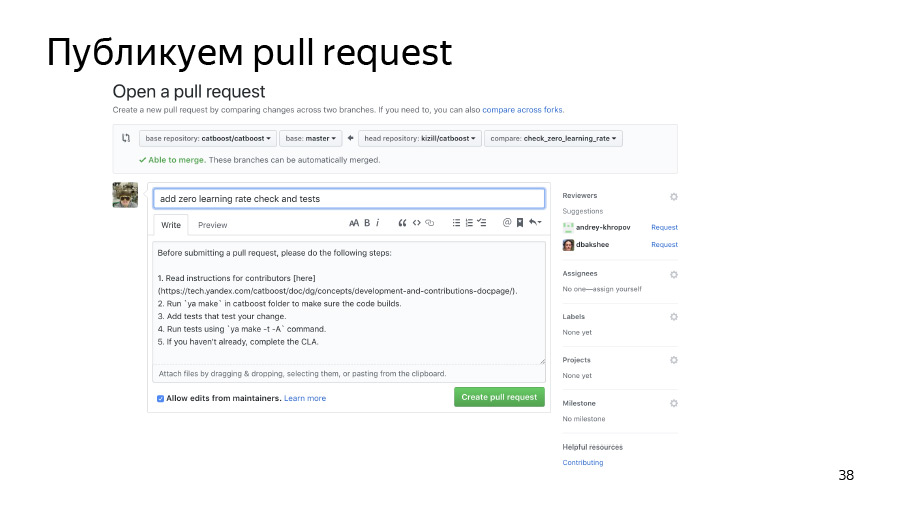
然后提交更改,并将其推送到我们的派生存储库中。 我们发布池请求。 他已经加入,一切都很好。