哈伯,你好。
在过滤掉大量文章,会议和订阅之后,我为您收集了来自机器学习和人工智能领域的所有最重要的指南,文章和生活技巧。 祝您阅读愉快!
1.您今天可以玩的人工智能项目。 您对人工智能和机器学习了解多少? 当前的趋势或潜在强大的力量可以杀死人? 这些流行的概念越来越多地被听到,但是并不是每个人都知道它的真正含义。 是时候使用一种简单而有趣的方法来学习这些技术了-在实践中自行尝试人工智能和神经网络。
→
了解更多2.学习AI,如果您不懂数学。 也许您想更深入地研究并在TensorFlow或Theano中运行图像识别程序? 您可能是一位了不起的开发人员或系统架构师,并且您对计算机非常了解,但是只有一个小问题:您不了解数学。

→
了解更多3.如何构建消息审核系统。 自动审核系统通常嵌入在应处理大量用户消息的Web服务和应用程序中。 这样的系统可以通过实时处理所有用户消息来减少手动审核成本并加快审核速度。 本文将讨论使用机器学习算法的自动审核系统的开发。
→
了解更多4.您今天可以使用的人工智能工具列表仅供个人使用(1/3)。 在几周内,我浏览了成千上万个站点(超过6,000个链接),向您提供了该领域最佳AI产品和最有希望的公司的完整列表。

→
了解更多5.您今天可以使用的人工智能工具清单是针对企业的(2/3)。 该列表包括致力于人工智能和机器学习产品的公司,这些公司主要用于商业目的,而不是针对任何行业。

→
了解更多6.您今天可以使用的人工智能工具列表-用于企业(2/3)。 创建完整列表时,我发现它变得太长且令人困惑,因此我决定将整个列表分为两部分会更容易,以便于理解。

→
了解更多7.您今天可以使用的人工智能工具列表是针对特定行业的(3/3)。 难题的最后一部分是第3部分。这是对使用各种形式的人工智能解决不同市场中真正有趣且特定任务的行业公司的考察。

→
了解更多8.以新的方式处理数据:用Pandas代替SQL。 以前,SQL作为工具就可以用于研究分析:快速的数据检索和初步报告。 现在,数据以多种形式出现,并不总是意味着“关系数据库”。 这些可以是CSV文件,纯文本,Parquet,HDF5等。 这是熊猫图书馆将为您提供帮助的地方。
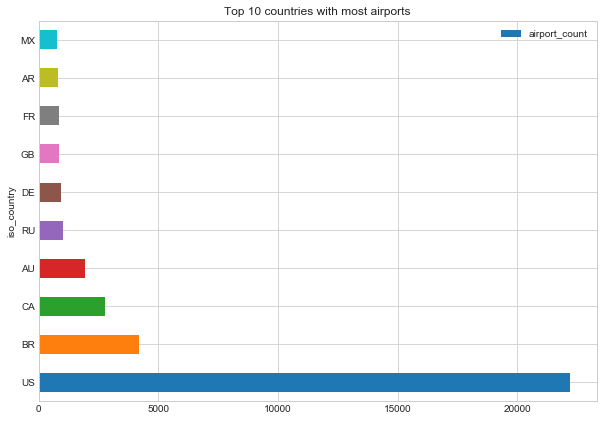
→
了解更多9.机器学习和数据分析的最佳数据集。 数据分析和机器学习需要大量数据。 可以自己组装它们,但是很累。 在这里,各种类别的现成数据集将为我们提供帮助。

→
了解更多10.健康和区块链-智能合约,保险和供应链。 都带有AI的暗示。 为此,可以在区块链网络上实施的智能合约,可以通过操作员进行编程。 这将使您能够快速,有效地使用存储的数据来计算和执行决策,而无需人工处理。

→
了解更多11.如何在2019年提高语音助手的出色技能。 通过查看语音界面和用户体验的一些关键要素,接受正确的技术来开始发展您的下一个技能。
→
了解更多12.为什么,何时以及如何使用Python多线程和多处理。 本教程的目的是解释为什么Python中需要多线程和多处理,何时在另一个之上使用一个,以及如何在程序中使用它们。

→
了解更多13.用于在SAP HANA表格数据中使用Python分析和预测数据的跨领域模型。 该博客可帮助您连接到SAP HANA数据库(版本1.0 SPS12),然后从HANA表中提取数据/使用Python Pandas库查看和分析数据。
→
了解更多14.具有短期记忆(LSTM)的网络体系结构的神秘化。 我们使用长期随机存取存储器(LSTM)和门控循环单元(GRU),它们是解决梯度消失问题的非常有效的解决方案,它们允许神经网络捕获更远的依赖关系。
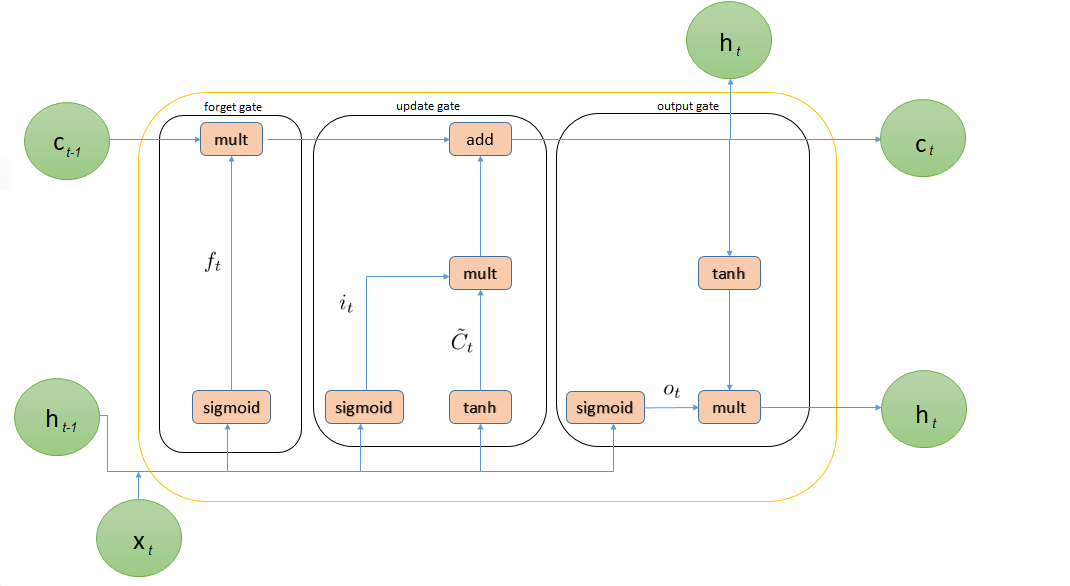
→
了解更多15.在AMD GPU上以每秒50帧的速度进行实时车辆检测。 在这里,我们将重点放在深度学习对象检测模型上,因为它们具有卓越的准确性。
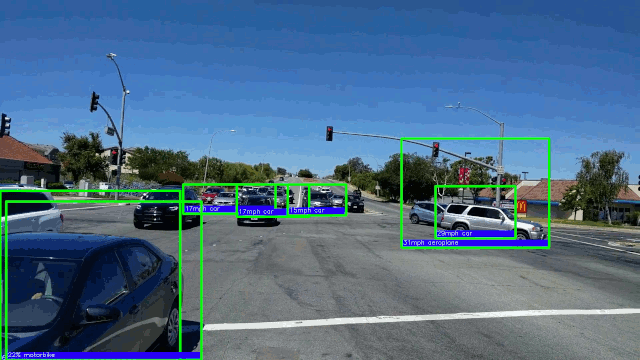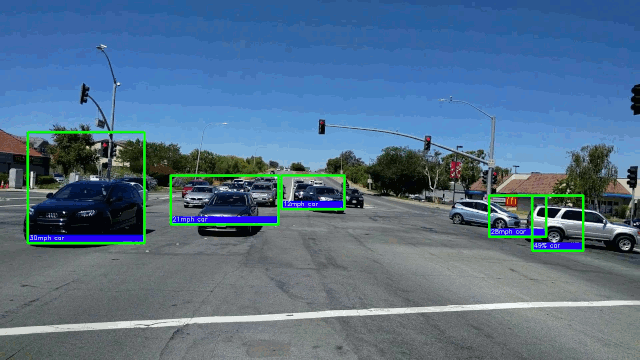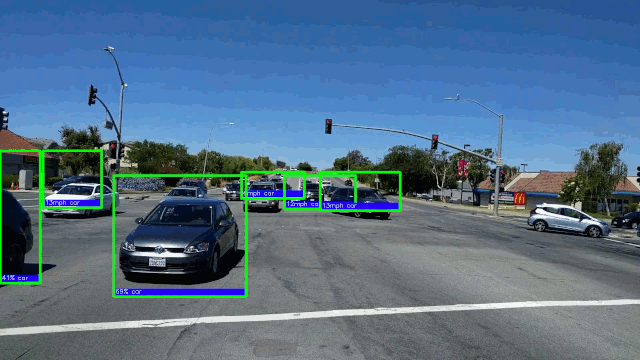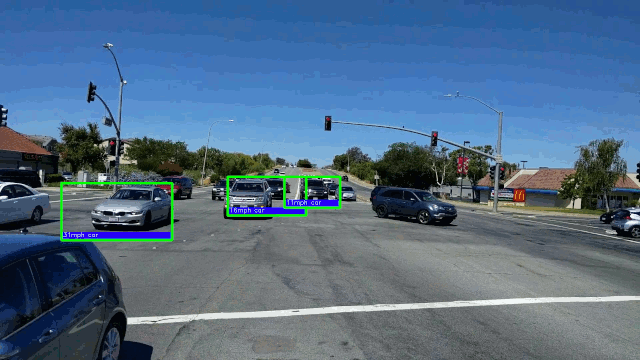
→
了解更多16.使用Scikit-Learn进行机器学习中分类方法的概述。 有很多用Python编写的用于机器学习的库。 今天,我们将看看最受欢迎的游戏之一-Scikit-Learn。 Scikit-Learn简化了创建分类器的过程,并有助于更清楚地突出显示机器学习的概念,并通过一个易于理解,文档完善且可靠的库将其实现。
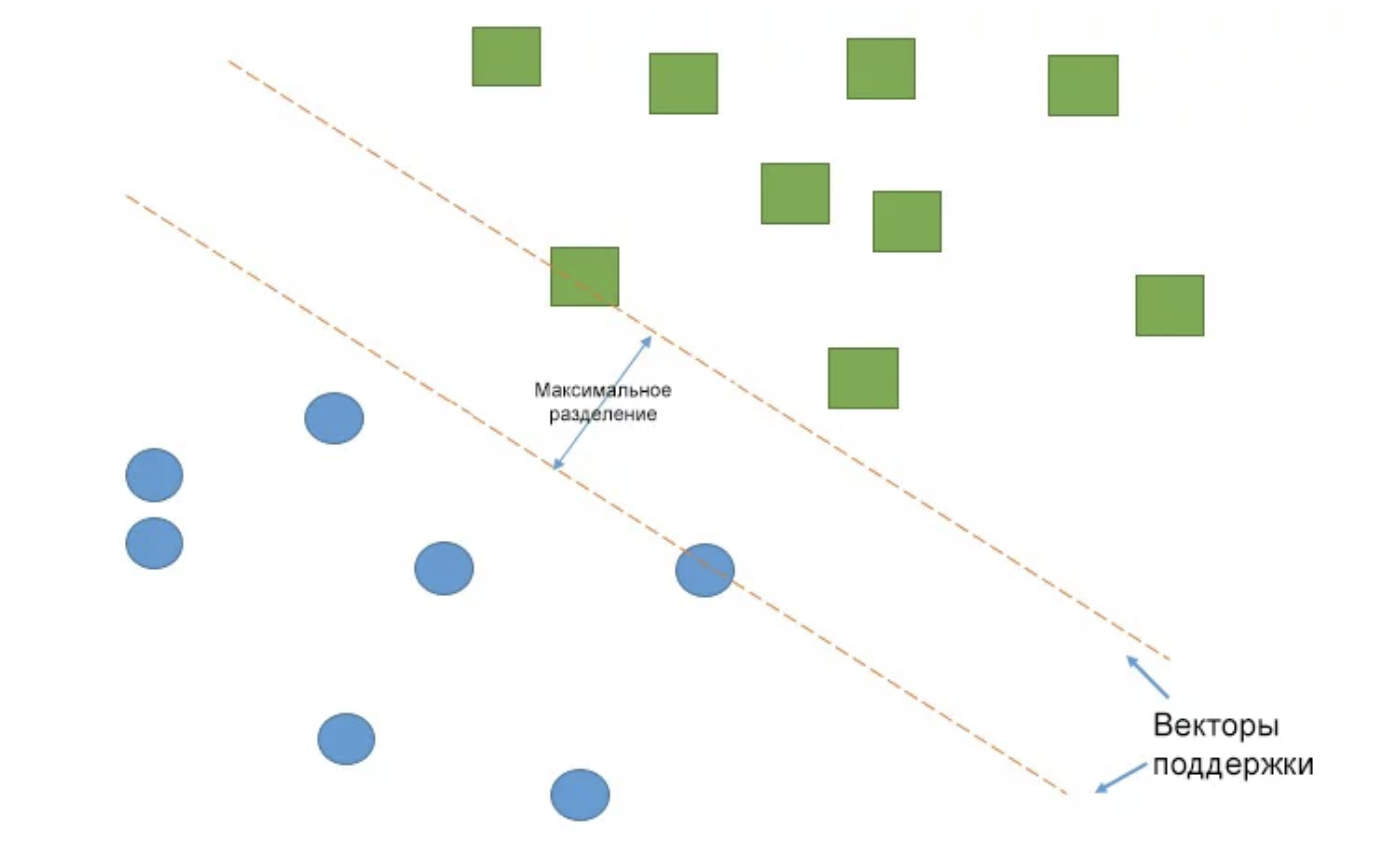
→
了解更多17.法证学导论。 计算机法证学(法证学)是一门应用科学,涉及与计算机信息有关的犯罪的披露,数字证据的研究,查找,获取和修复此类证据的方法。

→
了解更多18.实践中的人工智能:我们创建烧烤准备专家系统。 看起来像这样:系统询问一系列问题,随后的问题取决于收到的答案。 然后,系统做出结论并显示导致它的整个推理链。 也就是说,专家的知识和经验可以被复制,同样重要的是,他的推理过程可以被复制。

→
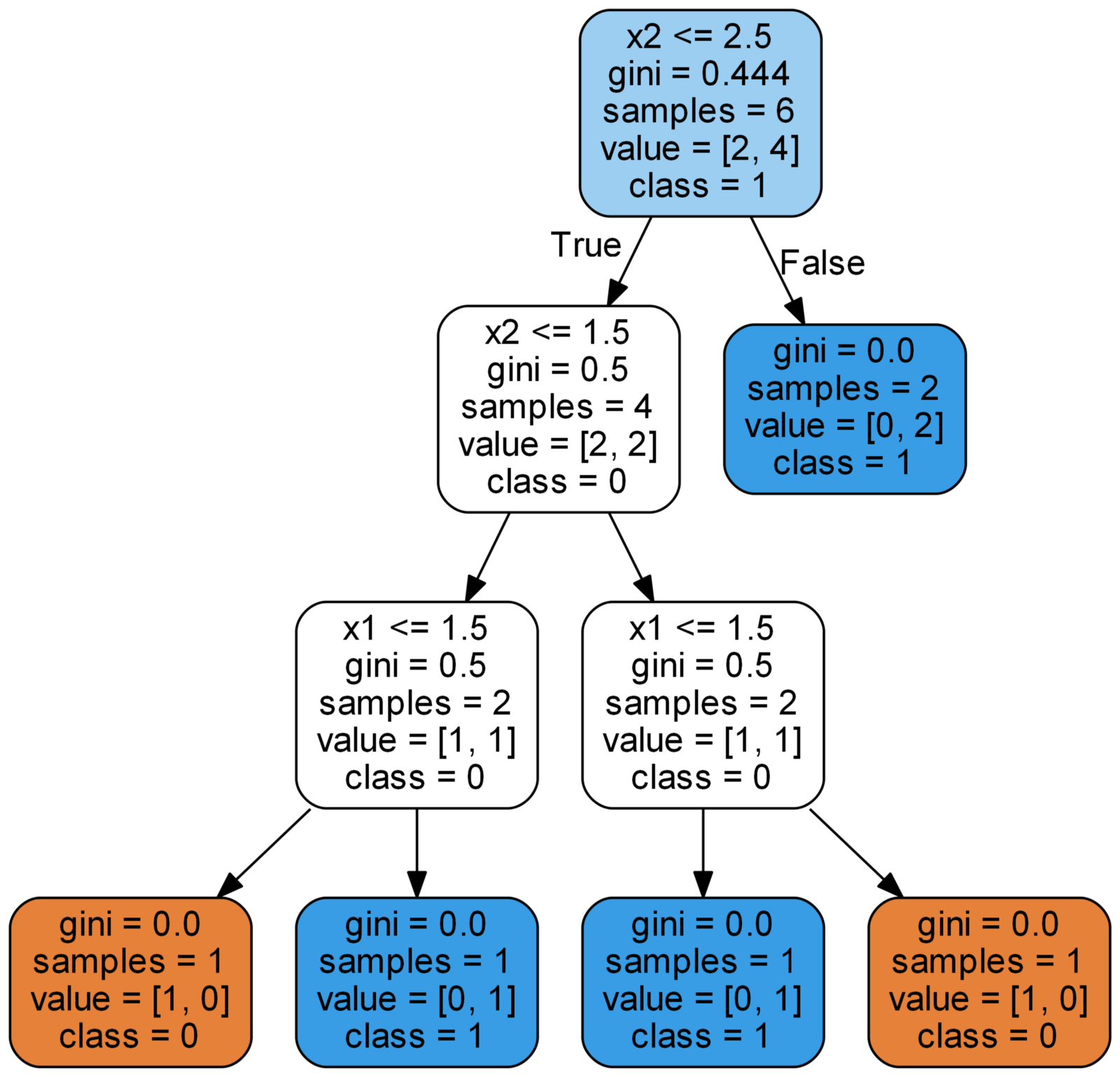
了解更多19. Python中随机森林算法的实现和分析。 在本文中,我们将学习如何在Python中创建和使用随机森林算法。 除了直接研究代码外,我们还将尝试了解模型的原理。 该算法由许多决策树组成,因此首先我们将弄清楚一个这样的树如何解决分类问题。 之后,我们使用一种算法,使用一组真实的科学数据来解决问题。 本文中使用的所有代码都可以在Jupyter Notebook的GitHub上找到。
→
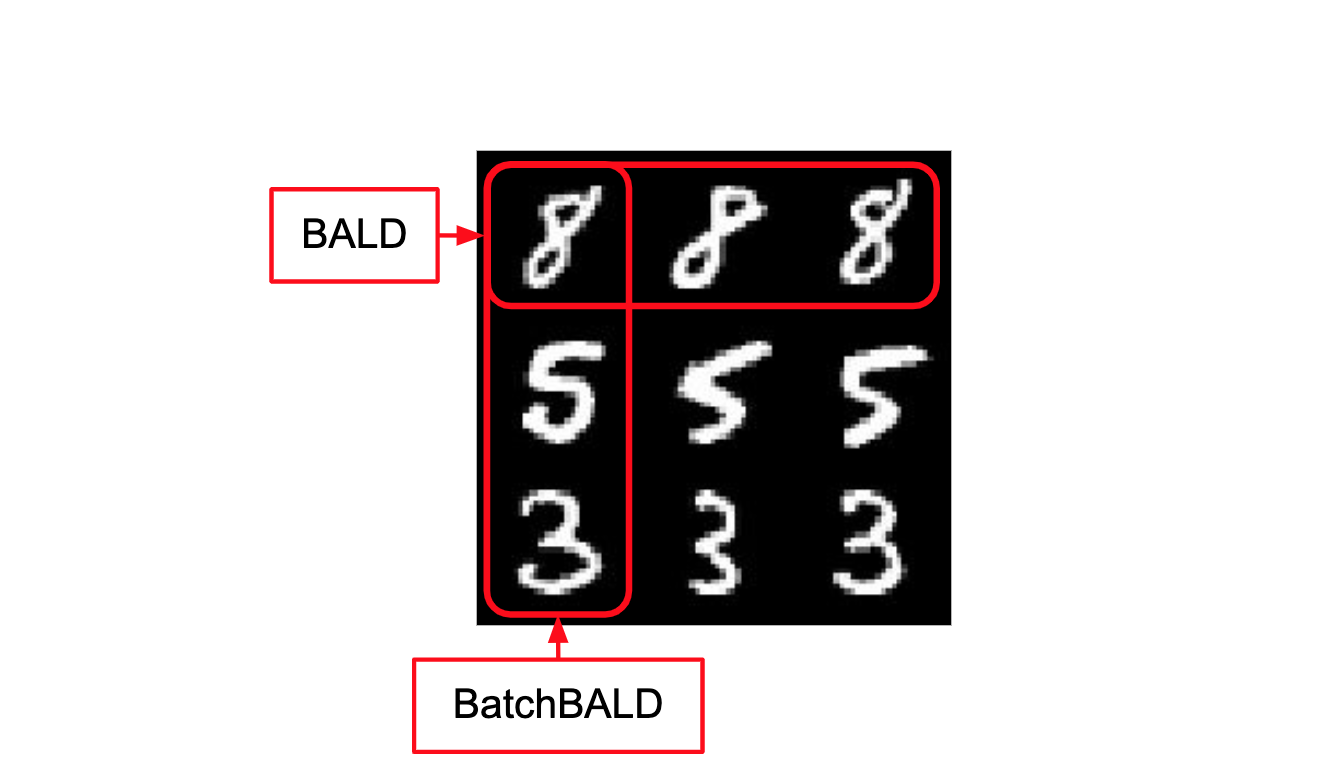
了解更多20.循环中的人:如何减少用于数据标记的资源。 深度学习和大量标记数据的使用使准确模拟各种现象的光谱成为可能。 数据标记是一个资源密集型过程,并非总是将标记的数据放在公共域中。
→
了解更多21.辛普森一家获得了数据可视化。 自然地,当我发现自己可以下载想要的所有情节剧本(通过kaggle)时,我知道该做什么。 可以访问荷马曾经说过的所有内容,我忍不住要为数据研究人员戴上帽子,以表达过去三十年来最引人注目的动画电视节目之一的一些想法。

→
了解更多22.初学者如何创建出色的数据可视化? 对于数据分析师而言,可视化始终是永恒的研究,因为它向我们揭示了构成数据基础的定律。

→
了解更多23.配置AWS Lambda数据管道自动警报。
→
了解更多24.全面的现代图像识别培训工具。 使用fastai和PyTorch库对图像进行快速的多类分类

→
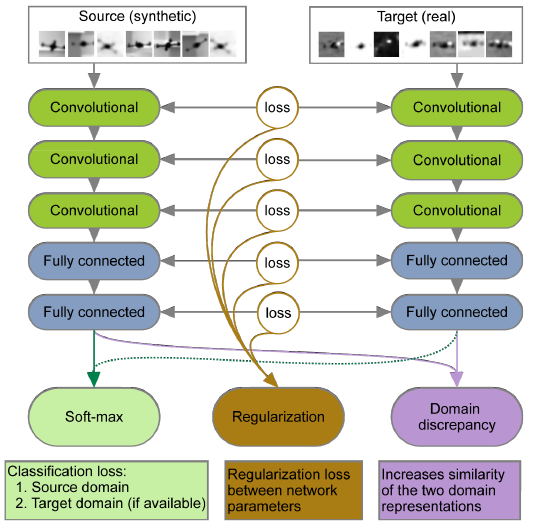
了解更多25.计算机视觉中的深层适应。 在过去的十年中,计算机视觉领域取得了巨大的成功。 这一进展主要归因于卷积神经网络(CNN)不可否认的有效性。 如果使用高质量的带注释的训练数据对CNN进行了预测,那么CNN可以使您做出非常准确的预测。
→
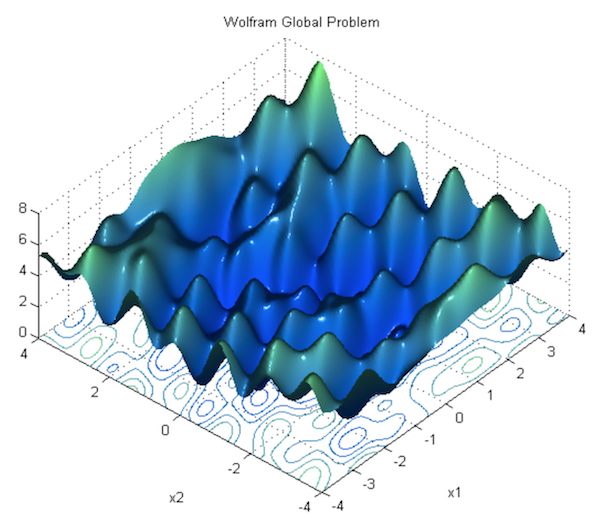
了解更多26.神经网络的优化。 优化程序的覆盖范围,动量,自适应学习速度,批处理规范化等等。
→
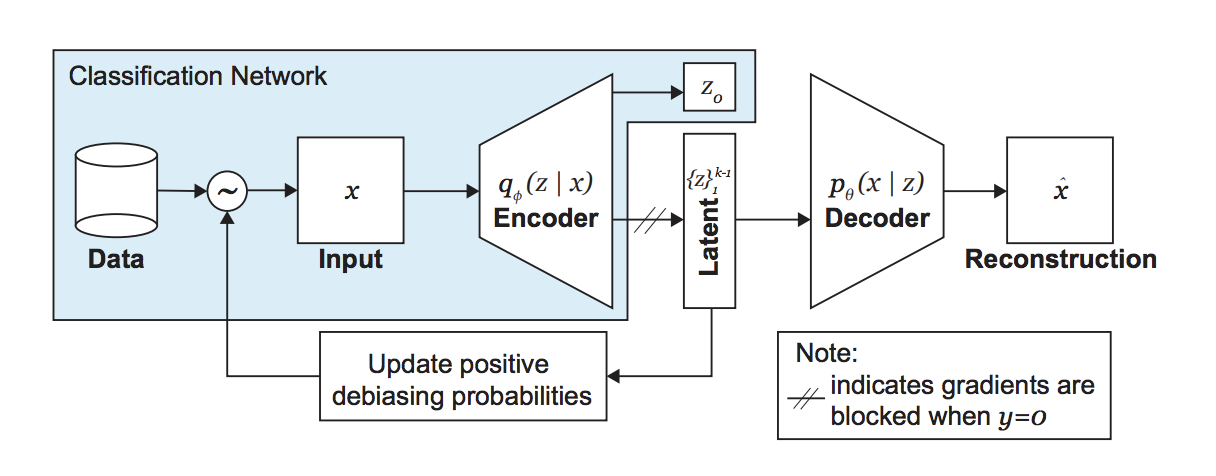
了解更多27.算法偏差的算法解决方案:技术指南。 我想谈谈减轻算法偏差的技术方法。
→
了解更多28.暗示性的计算机设计。 通过机器学习促进设计。

→
了解更多29.数据集生成:使用GAN创建缩略图。 数据是我们的ML和DL模型的基础。 如果没有合适的训练算法数据集,我们将无法创建强大的程序。

→
了解更多谁还没有阅读我6月份的新闻摘要,
请留下链接 。
在此,我们的简短摘要结束了。 添加到书签,与同事共享,得出结论并进行富有成效的工作。 该摘要将不断发布在
电报频道Neuron (@neurondata)中,并在Habré订阅我,请不要错过以下摘要。
所有的知识!