在培训课程中(5月至6月和12月至1月),用户要求我们每分钟检查最多500份文档的借阅。 文档以各种格式出现,使用每种格式的复杂性都不同。 要检查文档是否借用,我们首先需要从文件中提取其文本,并同时处理格式。 任务是实现每分钟格式化的半文本的高质量提取,而很少出现(或者最好完全不掉下来),消耗很少的资源,并且不为最终构想的开发和操作付出银河预算的一半。
是的,是的,当然,我们知道在三件事中-快速,廉价和高效-您需要选择任意两项。 但最讨厌的是我们无法删除任何内容。 问题是我们做得如何...

图片来源: Wikipedia
人们经常被告知,人的命运取决于我们工作的质量。 因此,您必须教育自己的完美主义者。 当然,由于不道德的作者提出了新的解决方法,因此我们(在各个方面)都在不断提高系统的质量。 我希望这一天即将到来,一方面,欺骗的复杂性,另一方面,对做得好的工作的满足感,将促使绝大多数学生放弃他们心爱的四处游荡的愿望。 同时,我们了解到,如果我们突然伪造错误,错误的代价可能是无辜者可能遭受的痛苦。
我为什么 如果我们是完美主义者,我们将以深思熟虑的方式撰写有关反Anti窃制度工作的一系列文章。 我们将努力制定出版计划,以最合乎逻辑和预期的方式向读者陈述所有内容:
- 首先,我们将讨论系统的结构(哈布雷的第五本出版物 ),并描述检查借入文件时处理文件的三个主要阶段:
- 提取文档的文本(您在这里!);
- 搜索贷款( 我们的几篇文章中已经介绍了这些内容 );
- 在文档上生成报告(在计划中)。
- 此外,我们将开始为读者提供有趣的辅助机制,例如寻找可转让借款( 第一篇文章 ),释义的定义( 第四篇 )和主题分类( 第二篇 )。
- 最后,我们进入了搜索引擎-带状疱疹的索引( 第七篇文章 )。
细心的读者一定已经注意到,我们仍然不会遭受过度的完美主义困扰,因此现在该进入第一个阶段了-提取文本和格式化文档。 这就是我们今天要做的事情:思考生命的死亡和隧道尽头的光明,不存在任何理想事物,追求卓越,制定计划并遵循计划以及生活总是使我们趋于妥协的妥协。
一开始是这个词
首先,我们仅从文档中提取了检查借阅所需的最必要文档,即文档本身的文本。 支持的主要格式-docx,doc,txt,pdf,rtf,html。 然后添加了较不常见的ppt,pptx,odt,epub,fb2,djvu,但是,将来有必要拒绝与它们中的大多数一起工作。 它们中的每一个都以自己的方式处理-在单独的库中的某个地方,在其自己的解析器中的某个地方。 平均而言,文本提取持续约数百毫秒。 似乎提取文本的主要困难,而且几乎是唯一的困难是格式本身的“解析”,这对于二进制pdf和doc格式尤其如此(后者的专有性使其使用起来更加成问题)。 但是,已经在现阶段,当我们的愿望仅限于提取文本时,很明显,任何读取所需格式的方式都带有许多令人不愉快的功能。 其中最重要的:
- 即使在处理某些有效文档时也是如此,更不用说对格式错误的“损坏”文档的处理了。 造成更多问题的是本机代码可能崩溃,并且很难在.net代码中处理这种情况;
- 内存消耗不足,可能会损害相邻进程以及当前处理“问题”文档的当前进程(托管或非托管代码中的内存不足);
- 文档处理时间过长,大多数图书馆都缺乏取消机制,有时还需要从托管对象中取消非托管代码调用的复杂性(阅读:几乎不可能),这加剧了该文档的处理;
- “从文档中提取文本。” 生成pdf文档的文本(这种格式是我们的关键),与预期相反,已经进行了解析,这是一项艰巨的任务。 事实是pdf格式最初主要是为印刷材料的电子表示而开发的。 pdf中的文本是位于文档页面上的一组文本块。 此外,块可以是一段文字或单个字符。 从这组块中还原原始形式的文本的任务在于读取文档的库(代码/程序)。 是的,从某种版本开始的格式可以指定块的顺序,但是不幸的是,带有标记的文本块序列的文档很少。 因此,pdf文本阅读库包含许多启发式方法(嗯,这是这里的标准:机器学习,大数据,
区块链等),可让您以一种或另一种程度的正确形式还原文本,并且正如所期望的,每个库获得的结果不同。

底部图片来源: 文章
热门图片来源: 嗯...
需要更多数据!
如果对于分析一个要借用的文档来说,文档的文本背景足以满足我们的需要,那么不从文档中提取其他数据就不可能或很难实现许多新功能。 今天,除了文本背景之外,我们还提取文档格式并渲染页面图像。 我们将后者用于光学文本识别( OCR )以及识别某些类型的旁路。
格式化文档包括页面上所有单词和字符的几何排列以及所有字符的字体大小。 此信息使我们能够:
- 精美显示文件验证报告,将检测到的借款直接画在原始文件上;

- 确定文档块(标题页, 书目 )的准确性更高,并检索其元数据(作者,职称,工作年份和地点等);
- 检测系统旁路尝试。
为了统一处理文档和一组提取的数据,我们将支持的所有格式的文档转换为pdf。 因此,提取文档数据的过程分为两个阶段:
转换为pdf。 图书馆选择
由于将文档转换为pdf文件并不容易,因此我们决定不重新发明轮子,而是探索现成的解决方案,选择最适合我们的解决方案。 那是在2017年。
选择候选人的标准:
- .net上的库,最好是.net核心和跨平台
- 支持所需格式-doc,docx,rtf,odf,ppt,pptx
- 稳定度
- 性能表现
- 技术支持质量
- 发行价
我们分析了可用的解决方案,从中选择了最适合我们任务的6种解决方案:
MS Word Interop,Neevia Document Converter Pro和DynamicPdf要求在生产环境中安装MS Office,这最终可能使我们与Windows紧密结合。 因此,我们不再考虑这些选项。
因此,我们剩下三个主要的候选者,其中只有一个完全支持我们需要的所有格式。 好了,是时候看看他们的能力了。
为了测试这些库,我们形成了一个12万真实用户文档的样本,其中格式的比例大约对应于我们每天在生产中看到的内容。
所以第一轮。 让我们看看可以考虑将多大比例的文档成功转换为pdf库。 在我们的情况下,成功不要抛出异常,满足3分钟的超时时间并返回非空文本。
Syncfusion立即脱颖而出,不仅能够成功处理最少数量的文档,而且还可以将整个过程转储到某些文档上(生成诸如OutOfMemoryException之类的异常或来自本机代码的异常,这些异常是未经手鼓跳舞才被捕获的)。
GroupDocs无法处理的文档数量是DevExpress的5.5倍(所有内容都可以在上面的板上看到)。 尽管有这样一个事实,即GroupDocs的单个开发者许可证比DevExpress的单个开发者许可证贵大约9倍。 顺便说一句,就是这样。
第二个严格的测试是转换时间,相同的12万个文档:
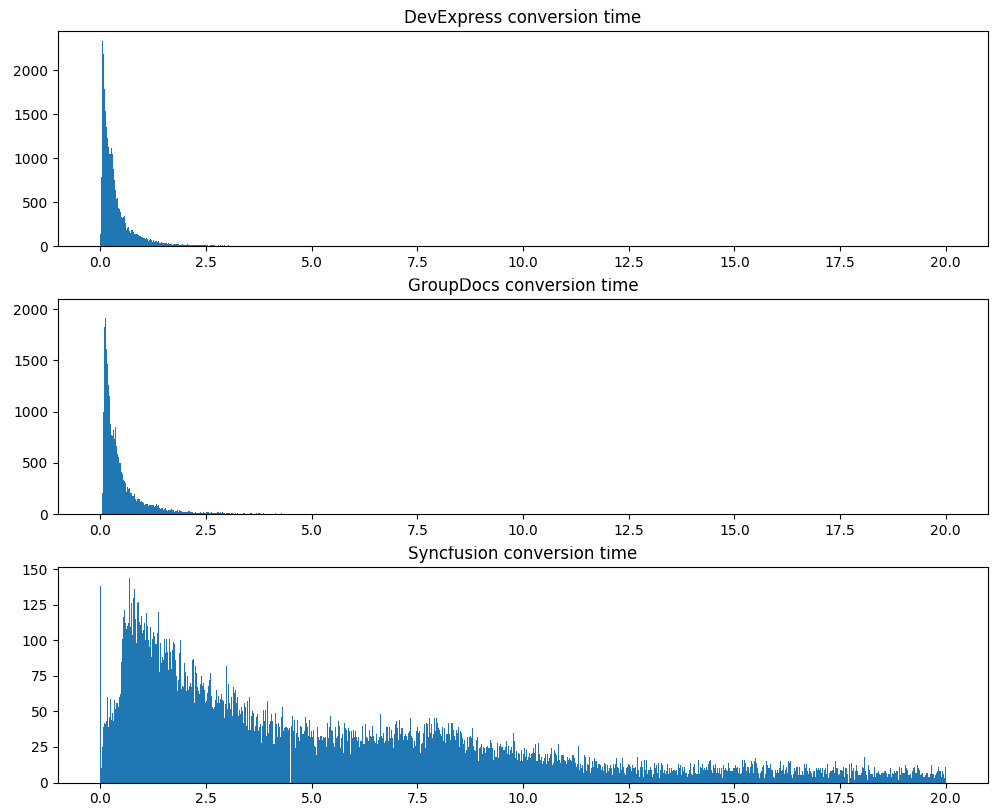
请注意,DevExpress不仅平均可以更快地处理文档,而且显示的处理时间要稳定得多。
但是,如果输出的pdf不好,稳定性和处理速度将毫无意义。 也许DevExpress跳过了一半的文字? 我们检查。 因此,相同的12万个文档,这次我们将计算提取的文本的总容量和字典单词的平均份额(字典中提取的单词越多,垃圾/错误提取的文本越少):
该假设在某种程度上是正确的。 事实证明,与DevExpress不同,GroupDocs可以使用脚注。 在将文档转换为pdf时,DevExpress只是跳过它们。 顺便说一句,是的,在所有情况下都使用DevExpress'a从收到的pdf'ok中提取文本。
因此,我们研究了相关库的速度和稳定性,现在我们仔细评估pdf文档转换的质量。 为此,我们将不仅分析要提取的文本的数量和其中词典词的比例,还要将从接收的pdf中提取的文本与使用MS Word获得的pdf文本进行比较。 我们接受使用MS Word作为参考pdf转换文档的结果。 为该测试准备了大约4,500对“ 文档,参考pdf'ka ”。
对于每对“ 参考pdf,转换结果 ”,我们计算了提取文本的长度和提取词的频率之间的相似度。 当然,仅在转换成功的情况下才能获得这些指标。 因此,我们在这里不考虑Syncfusion的结果。 DevExpress和GroupDocs表现出大致相同的性能。 在DevExpress方面,成功转换的百分比要高得多,而在GD方面,有脚注的正确工作就可以了。
根据结果,选择是显而易见的。 到目前为止,我们正在使用DevExpress的解决方案,并将很快计划升级到其第19版。
有pdf格式的文本提取
因此,我们可以将文档转换为pdf。 现在,我们还有另一个任务:使用DevExpress提取文本,了解每个单词的所有所需信息。 即:
- 这个词在哪一页上?
- 单词在页面上的位置(框住一个矩形);
- 单词的字体大小(单词字符)。
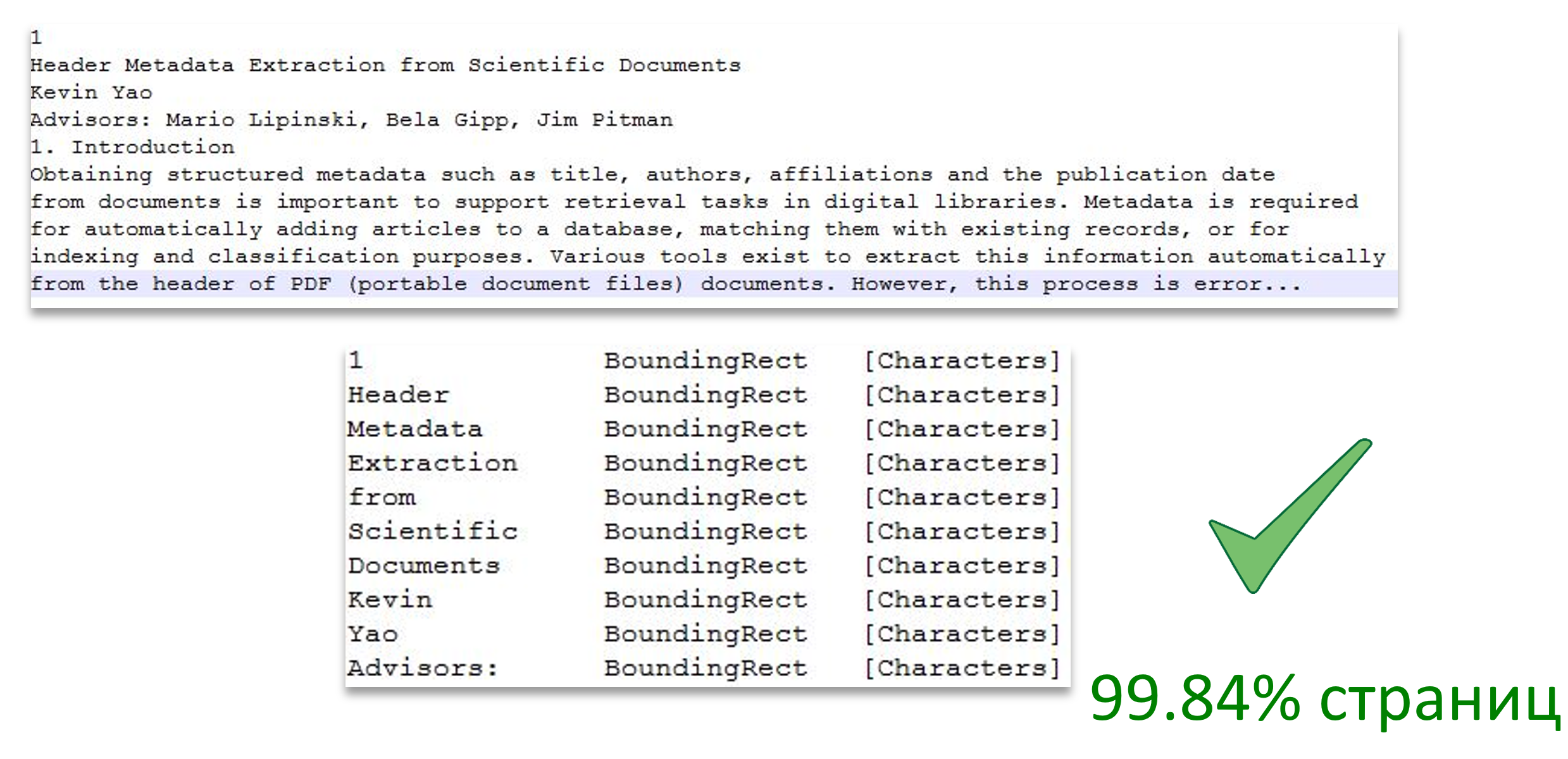
该图像显示了将文本细分为页面的过程,还显示了文本单词与页面区域的对应关系。

图像来源: 从科学文献中提取标头元数据
似乎一切都应该很简单。 我们看一下API DevExpress为我们提供的内容:
- 我们有一个返回整个文档文本的方法。 普通弦 ;
- 我们有能力根据文档进行迭代。 对于每个单词,我们可以获得:
- 文字;
- 单词所在的页面;
- 单词的框架矩形;
- 有关单词各个字符的信息(构成矩形的字符的含义,字体大小等)。
好吧,一切似乎都在那里。 仅在这里,如何获取DevExpress返回的文档文本中每个单词的必要数据? 我们实际上并不希望自己从单词中收集文档的文本,因为例如,我们不知道单词之间只有空格以及换行符在哪里。 我们将不得不根据单词的位置提出启发式方法。。。文本是-在我们面前,这已经是汇编。

图片来源: 尤里卡!
显而易见的解决方案是使单词与文档的文本匹配。 我们看-实际上,在文档的文本中,单词的排列顺序与迭代器根据文档的单词返回的顺序相同。
我们迅速实现了一种简单的算法,用于将单词与文档的文本进行匹配,添加检查内容是否正确匹配,然后开始...
实际上,所有内容在绝大多数页面上都可以正常运行,但是不幸的是,并非在所有页面上都可以正常工作。

热门图片来源: 确定吗?
在文档的一部分上,我们看到文本中的单词在遍历文档的单词时并没有按照它们的顺序排列。 此外,可以看出,单词列表中文本的开头方括号表示为结束括号,并且在另一个“单词”中。 通过在MS Word中打开文档,可以看到此文本片段的正确显示。 更有趣的是,如果您不将文档转换为pdf,而是直接从doc中提取文本,那么我们将获得文本片段的第三个版本,该版本与从库中收到的正确顺序或其他两个顺序都不匹配。 在此片段中,就像在其余大多数片段中一样,也会出现类似的问题,重点是不可见的“ RTL”字符,这些字符会更改相邻字符/单词的顺序。
这里值得回顾的是,在选择库时,我们称技术支持的质量很重要。 如实践所示,在这方面,与DevExpress的交互非常有效。 创建相应的票证后,提交的文档问题很快得到解决。 与异常/高内存消耗/长文档处理有关的许多其他问题也已修复。
但是,尽管DevExpress没有提供直接的方法来获取每个单词具有必要信息的文本,但有时我们会继续进行比较。 如果我们无法在单词和文本之间建立精确的匹配,我们将使用许多启发式方法,允许单词的小的排列。 如果没有帮助,文档将保持不变而不会格式化。 很少,但是这种情况会发生。
再见:)