在过去的三年中,Contour中发生了上千次不同程度的史诗事件。 原因有所不同:例如,有36%是由于质量低劣的发布所致,有14%是由于维护数据中心的铁。 统计数据来自哪里? 每次事件后,都会写一份报告-验尸。 它们是由值班工程师编写的,他们响应了事故通知,并且是第一个了解事故原因的人。 进行事后分析,识别并消除事件的原因,以便将来不再发生此类事件。 但这并非总是如此。
Alexey Kirpichnikov (
BeeVee )自2008年以来一直在Yandex中进行编程。 Yandex.Taxi后端团队负责交通特殊项目的交通堵塞。 自2014年以来,他一直从事
Kontur的 DevOps和基础架构工作-他一直在开发工具,使产品团队的开发人员的工作更加轻松。 编写和分析事后主题的想法是五年前出现的,在此期间,事后主题已被模板,词汇表,备忘录,屏幕截图和分析功能所淹没。 但这并不是最困难的-
克服工程师之间对事件报告含义的惯性,恐惧和误解更加困难 。 最终发生的事情以及“沙发分析”所能带来的无可挽回的好处是破译了Alexey的报告。
 请注意-在不同长度的桌脚下有书“度量”,“测试”和“部署”。
请注意-在不同长度的桌脚下有书“度量”,“测试”和“部署”。在Kontur,雇用后,他们提供了一套纪念品:钢笔,杯子,笔记本。 5年前,我去SKB Kontur时是一个新的基础架构团队,那时该公司已经成立了25年。

当时,也是现在的轮廓是一家产品公司,数十种产品开发了相同数量的团队,在技术和工具选择方面彼此独立。
那时,我首先阅读“ Project” Phoenix”,并受到DevOps实践新思想的启发。 我开始在笔记本上写下改善的想法,现在它是带有咖啡渍和历史记录的人工制品。
- “ 监控! 让我们把Grafana放进去,收集指标并建立图表。 我们会更好地了解生产中正在发生的事情。” 对于2014年,这是一个相当新鲜的新想法,并且是可靠的DevOps实践。”
- “ 自动崩溃!” 可以将多少个zip文件上载到共享文件夹,在服务器上解压缩并在Windows的任务计划程序中运行exe? “让我们介绍一个工业部署系统,并通过它发布发行版本CI!”
- 验尸 ! 如果生产中发生某种事故,让我们所有人找出原因,找出原因,编写报告并更改我们的开发,测试,CI流程,以便将来不再发生此类事故。
五年来,我们在所有这些领域都迈出了第一步。 我们拥有自己的
Moira警报系统,应用程序编排系统和一系列工具。 但是,从以上所有内容来看,
编写事件报告是最难实现的工程实践 。 工程师喜欢各种各样的工具-固定某种托管系统或CI,编写脚本,进行自动化,并且他们不喜欢编写报告,尽管这种做法很有用。
我将告诉您我们如何实施验尸系统以及我们将获得什么好处。 也许我们的耙子将有助于更快地行驶并填充更少的圆锥体。 在开始讨论验尸之前,我们将了解定义。
什么事
这是哪个事件?
- 示例1。 在拥有一百万用户的博客平台上,由于某种错误,一个用户的所有条目都会丢失。
- 示例2 办公室员工的服务在工作日的9点到6点工作,其他时间没有用户。 周六至周日晚上连续两个小时无法使用该服务,没有人注意到。
- 示例3 带有生产指标的Grafana下降了15分钟。 在生产中,一切都没有中断,但是图形不可用。
为了了解这种怪癖,我们转向大师的经验-Google,Atlassian,PagerDuty。 大师知道如何准备班次,值班工程师以及如何编写报告以了解他们。 他们的在线指南中有事件定义。
来自PagerDuty的
定义 。
事件是指任何计划外的服务中断或服务降级,影响用户对服务的可用性。 严重事件是需要多个团队协调响应的任何事件。
听起来合乎逻辑,但定义不明确。 在实践中,了解什么是事件和什么不是事件几乎没有帮助。
Google的《
网站可靠性工程》书中有明确的标准:
- 用户注意到该服务的降级。
- 所有数据均丢失。
- 例如,需要值班工程师的干预才能手动回滚释放。
- 解决问题花费了太多时间。 如果问题在2小时内解决,然后花了一个星期的时间-这是需要调查的事件。
- 监视无效。 例如,您从用户那里了解了一个问题。
Contour没有公开的fakap定义,但是我们已经制定了自己的标准来确定什么构成事件。
外部或内部用户已经注意到该服务的降级 。 带有Grafana的第3个示例很明显。 生产并没有中断,外部用户也没有注意到这一点,但是尽管如此,对于Contour来说,它还是一个缺陷,因为内部工具无法正常工作。
运气 在第2个示例中,为上班族提供的服务在晚上躺了2个小时-幸运的是晚上掉下来了。 下次可能不太幸运,因此夜间事件也需要审判,就好像白天发生一样。
事件涉及几支队伍 。 我们从PagerDuty获取此定义。 解析事件是几个团队一起工作的好理由。 通过联合分析,根除“我们方面,子弹飞了,但是某些东西给您摔了-这是您的错”的文化。
至少一名工程师认为这是事件 。 最模糊,但也是最重要的定义。 一个简单的规则:如果工程师认为值得进行报告,那么值得进行报告。 如果您担心工程师会开始为任何人编写报告并称任何小事为意外,事实并非如此。
工程师是理性的人,请相信他们。用定义和不同类型的损害进行分类。 让我们继续学习如何从事件中受益。
fakap有什么用?
我将进一步给出的简单说明,您可以自己申请,而无需仔细阅读本文。 但还是读到最后。
经典教学
首先找到罪魁祸首。 然后与工程师进行“教育”工作。
- 下次请多加注意。
- 如果没有帮助,请将其发送到再培训课程。 也许他们会学会在那儿更加小心。
- 如果这没有帮助,请从系统的关键部分中删除肇事者。 如果开发人员将其弄乱了,请停止让其投入生产。
- 如果无济于事,请解雇坏人并雇用有能力的人。
如果指令使您烦恼,这是个好消息。
这种方法被认为是传统的垂直型公司的传统,老板会责骂所有人并解雇他。 DevOps运动和DevOps意识形态的基础之一是从垂直集成组织转变为水平组织,对员工的信任度更高。
我将用DevOps运动的负责人之一约翰·阿尔斯帕(John Alspaw)的
指令来说明这种模式转变,他之前曾在Etsy担任首席技术官。 该说明摘自他在2013年的经典文章《无罪的岗位Mortem和正义文化》。
询问工程师:
- 他们观察到了什么事件;
- 什么时候采取什么行动;
- 这些行动预期会产生什么结果;
- 什么假设来自;
- 如发生的事件顺序所了解。
需要询问工程师而不会受到惩罚的威胁。
这是约翰推荐的主要内容。
惩罚的威胁:再培训,从生产中被淘汰或解雇,促使人们撒谎。 真理对我们很重要。 事件报告-这是在开发功能并将其投入生产过程中非常缺少的反馈链接。
在旧的范式中,开发人员进行了开发,将工艺扔到了操作工程师的篱笆上,他们以某种方式设法使它起作用。 他们对任何更新都感到恼火,因为它可能破坏所有内容,而工程师则以如此困难来开始所有更新。
反馈流程有助于更改流程,基础架构,工具和开发方法,从而减少生产中的崩溃。
这将使团队负责人和开发经理相信验尸的有效性。 但是要注意的是,很难让工程师去做他们认为毫无意义和无用的事情。 我们公司拥有一种工程文化,我不能只是来挥舞CEO的命令,并要求每个人都要写验尸报告。 我需要说服工程师。
如何将验尸工程师的想法“出售”给工程师? 为了避开异议,说明事后调查为何如此出色,以证明报告的好处,如果只有老板在后面,这不仅是退订。
异议1:一次
这是拆卸fakap的工程师的第一个问题-战争将结束,然后我们再谈! 当出现问题时,我想尽快修复它,但是我不想写令人费解的无聊和冗长的报告。
为了解决这个问题,有一个人生大计,如何在事故发生时正确地写东西。 他受到阿尔泰米·列别杰夫(Artemy Lebedev)的欢迎:
“有一种组织时间的简单方法-“渐进吉普车”方法。 在任何时候,任何项目都可以100%准备就绪,尽管可能会再提高4%。 根据可用时间,可以将项目设计成一个像素,也可以将其留在概念草图阶段。”
我将使用图片来说明渐进吉普车方法。 在缓慢的Internet上,图片不会立即下载,而是分阶段下载。

发生火灾时,您无需撰写冗长而冗长的报告。 左上角已经足够了。 标记那些很难从内存中恢复的东西就足够了。 当一切都在生产中被破坏时,不要试图写出连贯的文学文本。
执行一个简单的动作-写下事件的时间顺序。
时间表
如果没有立即记录,时间线将很难恢复。 电路中真实事后记录的示例。
15.01.18 17:25 YEKT PrefixSearch 50 . , .
这是一个简短的带时间戳记的观察。 根据此时间顺序,以后很容易恢复事件的顺序并找到故障的原因。 但是,如果您在火灾期间没有直接录制任何内容,那么以后很难或不可能恢复事件。
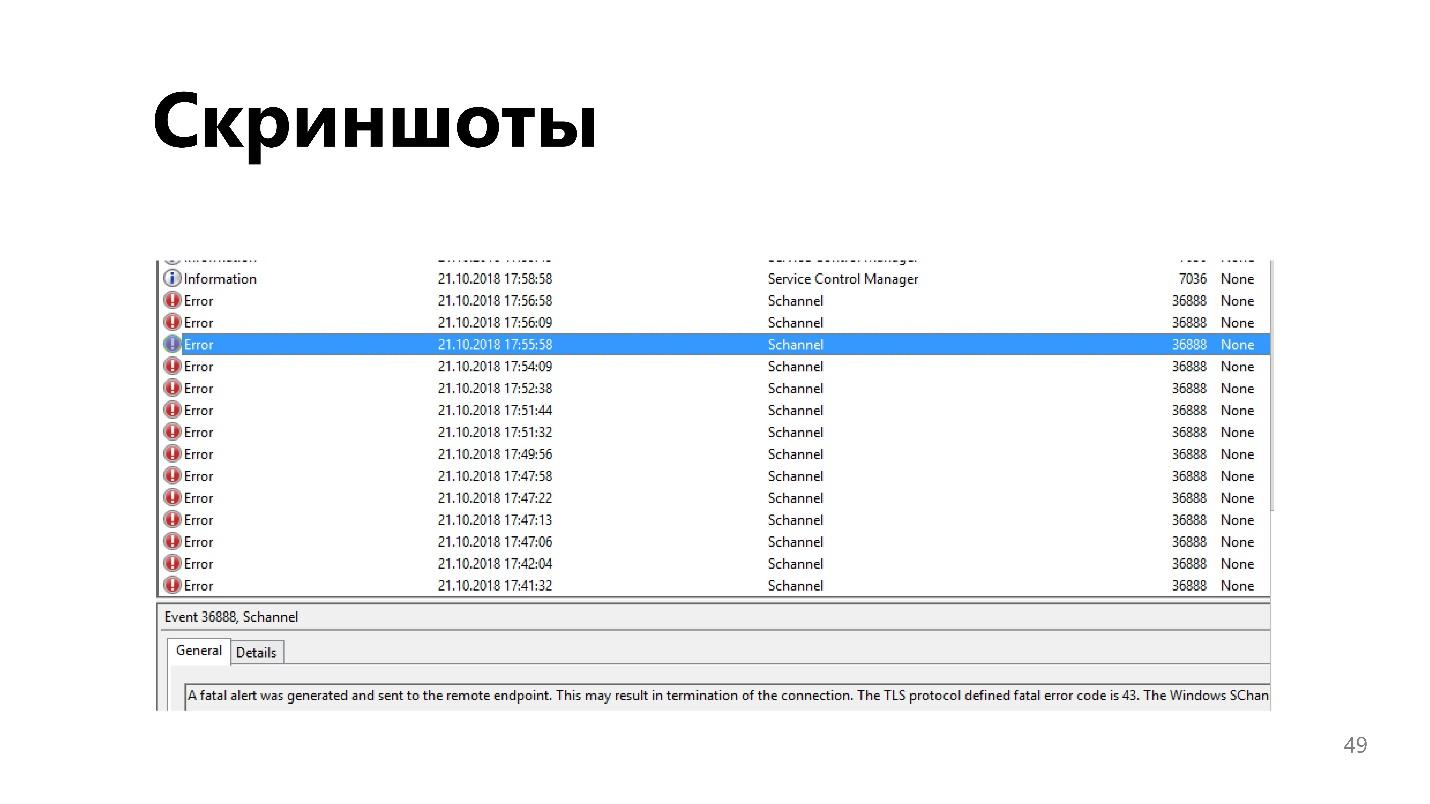
屏幕截图
一件方便的事情,尤其是在使用网站或桌面应用程序时。 这种情况有时很难用语言来描述,而屏幕快照只是热键的一击。
第一个异议解决了。 记录最少的信息,在事件发生时提供小报告并不困难,也不会占用宝贵的时间。 一切结束后,需要在一个易于理解且连贯的文档中完成并执行它。
异议2:懒惰
您有两天没有入睡,并且修复了一次严重的事故,严重落后于本周要完成的所有任务。 但是事实证明还需要做其他事情,但是大火已经扑灭了! 这时,难以想象的懒惰迎头赶上。
要彻底打败这个问题是行不通的。 但是您可以提前进行工作。
模式
这是首要的。 人们非常担心空文件需要填写有意义的文本。 准备模板会容易得多。 通常它由部分和其中的问题组成。 我们在每个部分中输入问题的答案,并填写模板。
事件报告模板很大。 与老师一起详细了解它们。 我引用的所有文档和书籍都包含公司使用的事件模式。 根据我们的经验,我可以添加以下内容。
创建带有示例的备忘录
我们的模板有一个“损坏”部分,并带有小节。
“定性评估”部分。 它描述了工程师填写模板的这一部分时在他面前看到的内容:
- 哪些功能不起作用,使用了多长时间以及针对谁?
- 是否存在数据丢失或损坏。
在模板中到达此位置后,工程师写道:“我们的博客平台中有100万用户,我们丢失了其中一个的所有条目。” 这比在文学课上从头开始写文章要容易得多。
“量化”部分:- 多少个请求消失了;
- 应用程序和客户端应用程序度量标准中增加了多少延迟;
- 丢失了多少个电话;
- 用户对该问题的技术支持的队列大小。
模式就是一组这样的问题。
一个完成的模板的示例。
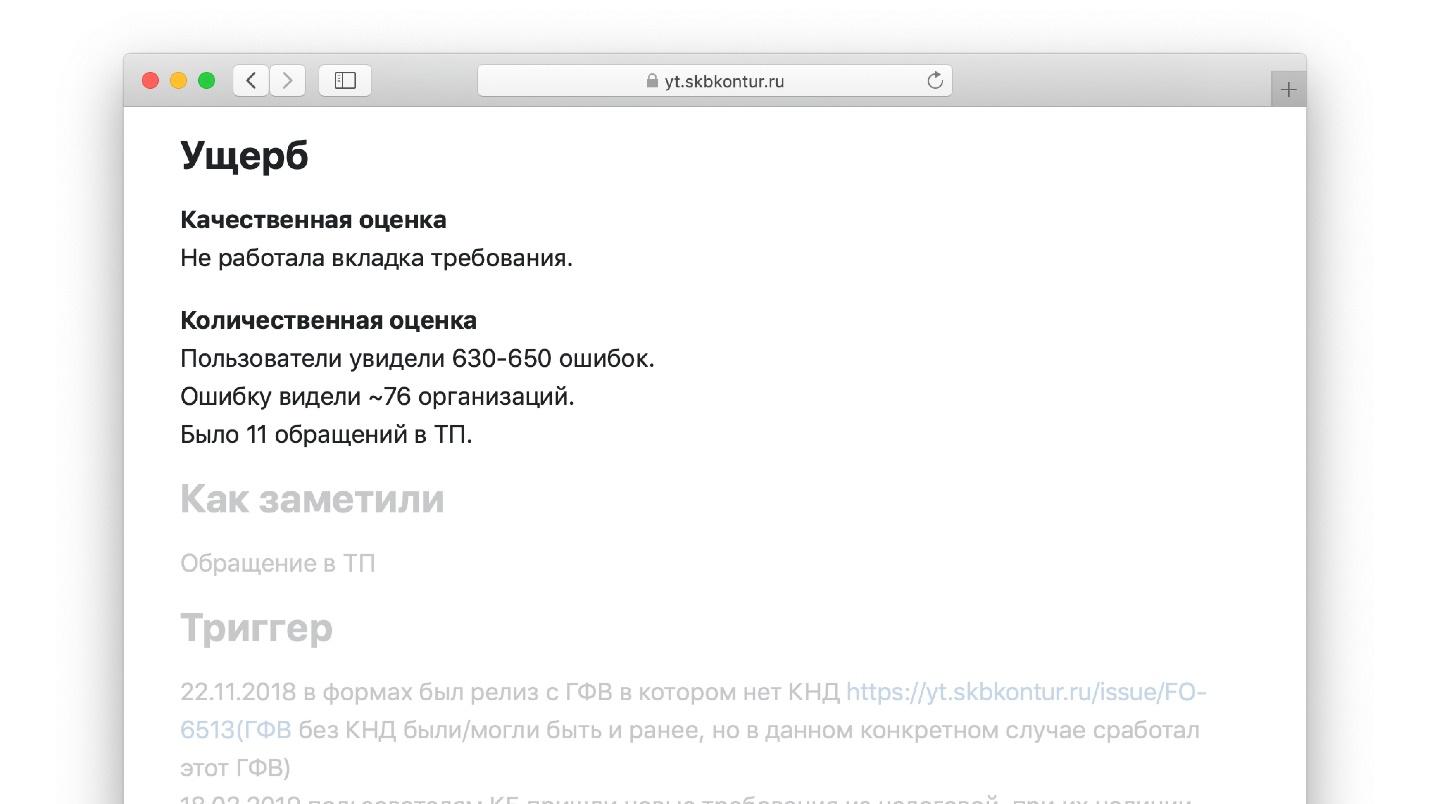
添加词汇表
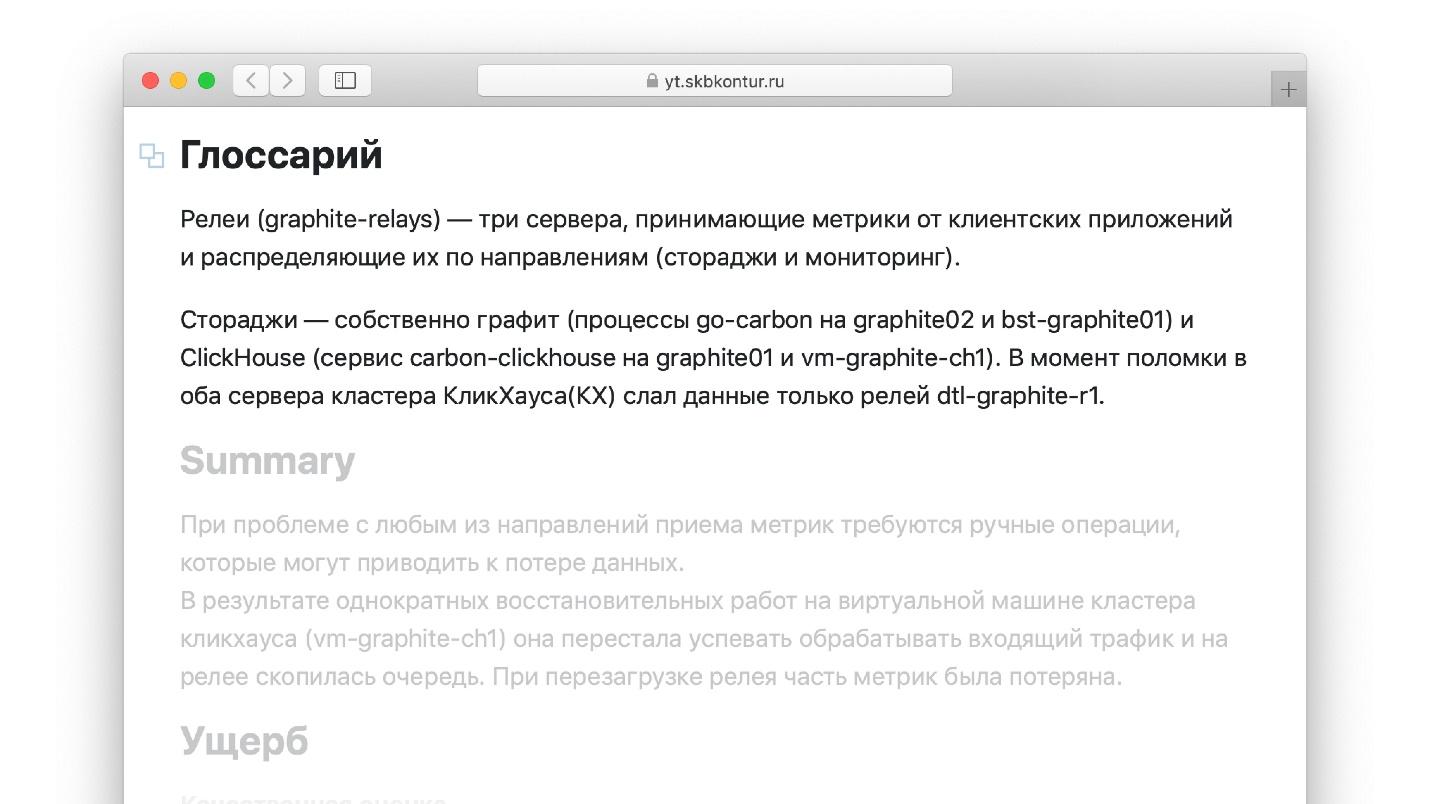
事故报告的另一种生活技巧,我在书中没有与上师见过。 撰写报告时,使用熟悉的术语会很方便。 例如,如果我使用在其中存储度量的Graphite,我将很清楚“中继”是什么。 但是一年内将要阅读该报告的工程师可能并不熟悉该术语。 他不太可能能够阅读由不熟悉的单词组成的报告。 另一方面,如果每个术语和定义在报告中不断出现,那么懒惰只会吓跑它,并且报告将无法完成。
编写一个小的词汇表,描述报告中使用的所有术语。
复制所有工件
如果将工件附加到报告:Grafana中的快照,聊天中的消息历史记录(与其他工程师一起分析了该事件),则会进行复制。 指标可以“淘汰”,聊天功能也可以更改。 一年前,您在Slack中,现在在Telegram中-聊天链接已过时且无法使用,并且保留指标将下降-它们将存储一年。
复制工件-这种生活技巧使填写报告变得容易。
异议3:没人会读
工程师提出的最大且不可理解的问题是:“谁来阅读这些报告?” 假设我克服了懒惰,并写了事故发生的时间顺序。 然后,他发挥了自己的力量,并添加了多页报告,说明发生了什么事以及事故的原因。 但是,如果不了解谁将阅读所有内容以及谁将从中受益,那么就没有意愿填写报告。
验后是对开发过程的持续改进过程的反馈。
在任何大师级书籍中,例如在《
Atlassian事件手册》中 ,都写道,根据每个验尸的结果,要求:
- 制定发展任务;
- 在Bugtracker中创建任务,开发人员将从中获取任务;
- 将验尸链接到这些任务。
反馈已关闭 :这里是事后评估,这里是
行动项 -需要完成的任务,这样才不会再次发生事故。 任务落入团队的积压之中,团队开发它们,然后推出-同样是fakap和验尸。 轮回的轮子已经关闭。
这就是所有大师的融合。 没有什么可争辩的-好处是显而易见的。
实际验尸中动作项目任务的示例。
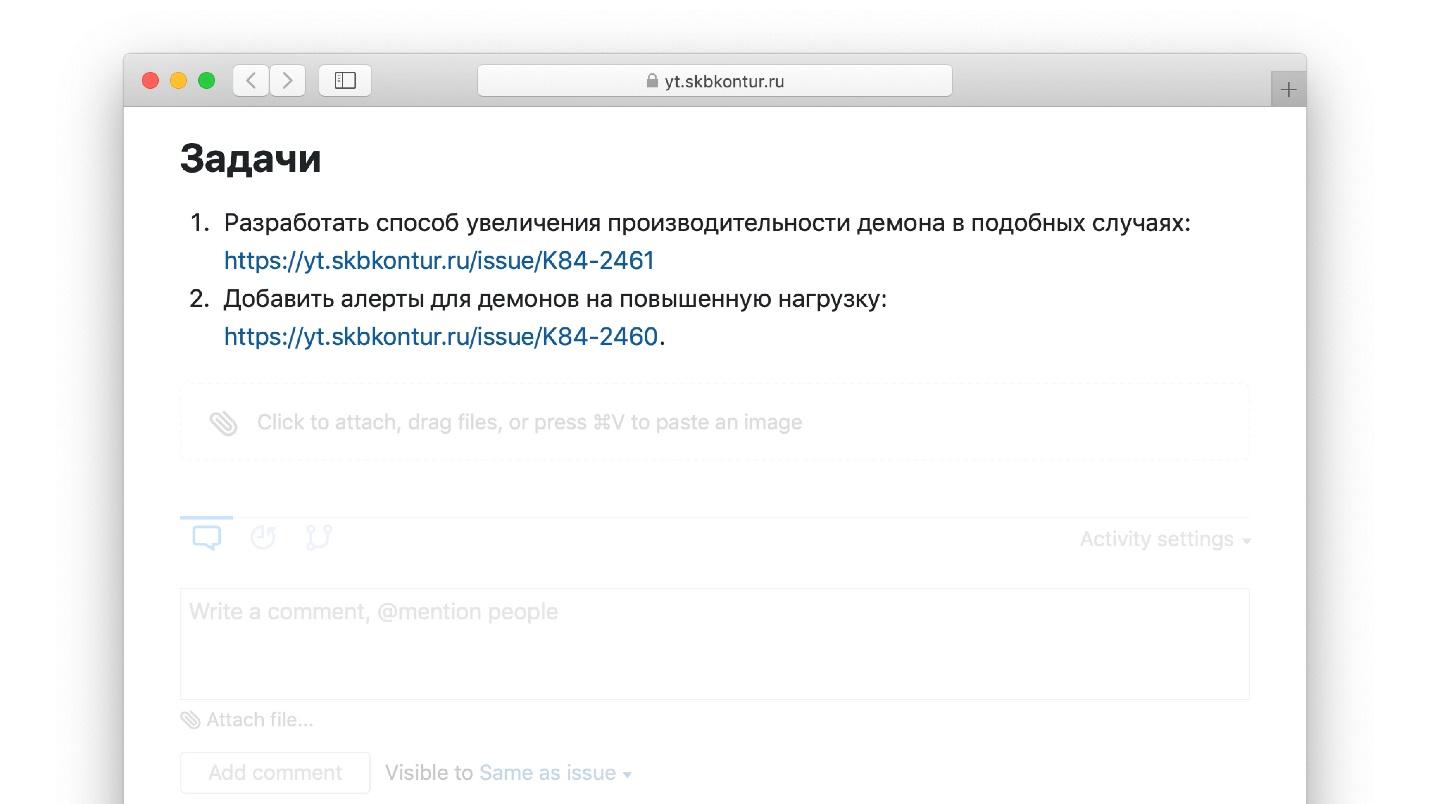
但是我们Kontur对此添加了一位分析师。
沙发分析
我们过去是孤立地分析事件。 失败是由一个团队在一个托管系统中独自发生的,发生了故障,我们进行了修复。
但是有很多事件。 在过去的三年中,赛道中已累积了超过1,000起事件报告。 我想知道是否有可能从全部累积的报告中受益,而不仅仅是从每个报告中受益。 是否有可能在他们的基础上计算系统的统计信息,并查看整个系统的改进之处。
Kontur有一个特殊的基础架构团队,负责进行事后分析,并根据所积累的全部报告发布结果和结论。 我们称其为“沙发分析”。 我将提供团队文章的一部分,这些文章将在我们内部的员工网络上发布。
我们在沙发分析中分析什么?
法卡普持续时间
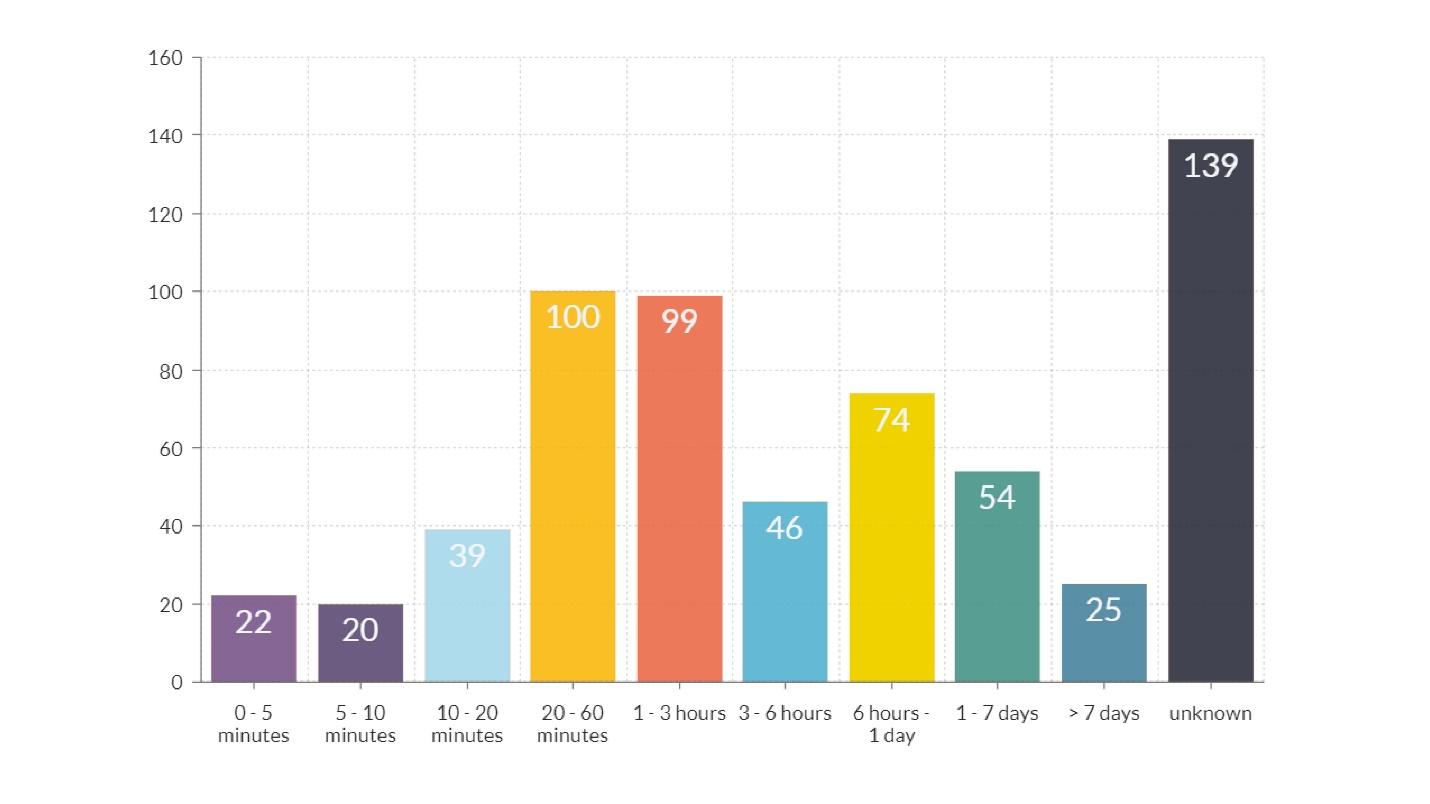 在该图中,除了最后一列(时间未知)外,还有两个更明显的峰。一个小时量级的持续时间
在该图中,除了最后一列(时间未知)外,还有两个更明显的峰。一个小时量级的持续时间 -橙色和红色条形。 这段时间中的大部分时间都花在了传输有关发生的信息上,从注意到事故的工程师到知道如何解决该问题的工程师。
问题是沟通 。
如果我们修复工具,以便解决问题的工程师更快地收到信息,那么fakaps的持续时间及其所造成的损害将大大减少。 通过单独查看任何fakap,这是我们无法识别的。
持续时间约12小时 -黄色栏。 关于许多fakaps持续超过12小时这一事实的解释很简单:他们在晚上推出了该发行版,而在早晨,用户来了,一切都破裂了。 关于减少此类fakaps数量的方法的结论是显而易见的。
质量受损

定性损坏分为几类。 前三名包括:
- 无法访问,错误;
- 刹车,增加等待时间;
- 可见的不正确行为。
根据分析,绝大多数此类错误。 一方面,这是个好消息。 三种最常见的错误很容易发现-我们将指标调整为延迟和错误数量,并迅速注意到这些情况。
坏消息是,其中大多数错误都是错误的。 这些都是简单的技术错误,这意味着我们可以改善管道测试中的某些内容,进行更多的压力测试并改善监控系统。
扳机
这是导致故障的直接原因,不是事故的根本原因,而是“最后一根稻草”:原木填满了磁盘,因此,所有东西都破裂了,被释放了,所有东西都爆炸了。

首先是“更新安装”。 因此,我们可以了解作为基础架构团队的投资方向。 例如,为了改进部署系统并引入Canary部署。 这是作用点,它将对我们的系统质量产生最大的影响。
这是所有分析的重点-了解小型基础架构团队现在应该在资源有限的情况下进行投资。
有什么改进-警报或部署? 做什么-托管还是图的美?
这是另一个很好的见解。 第二位是“原因未知”。 这表明事件报告的报告不佳。
可能的“药丸”
这允许一种简单的技术解决方案来减少某种类型的事故数量。 例如,我们知道减少fakaps数量最重要的事情是来自监视系统的通知。 如果在监视这些事件时有更多警报,那么我们可以预防多少事件? 百分比表示多少:
- 来自客户端的HTTP错误数量-10%;
- 日志中出现了新的错误类型:安装,通知设置-8%;
- 在系统资源上:CPU,内存,磁盘,线程,GC-6%。
如果正确配置了警报,并且所需的工程师按时收到了通知,则24%的事件将不会发生或持续时间短得多。 可以基于对整个事件总数的分析得出该结论。
在这里,我将再次宣传位于开放源代码中的
Moira警报系统。
如果您拥有Graphite,则可以下载并使用它。 我希望事件减少。
推荐建议
团队可以遵循的组织建议,还可以减少事故数量。 我们的前3。
- 测试和战斗地点的相似性 。 5%的事件是由于测试地点与战斗地点不够相似而发生的。
- 发行版中的向后兼容性 。 该版本放气了,与前一个版本不向后兼容,出现了数据迁移-错误的4%。
- 拒绝夜间发布 。 如果您停止传播会破坏的发行版,那么到了晚上,另外4%的事件将消失。
我强调这不是说明,而是关于我们如何收集分析的故事。 您的分析可能会有所不同。
怎么写
如果您意识到事件分析是一件很酷的事情,并且需要编写报告,那么我将告诉您如何做。
在一个Bug跟踪器中发布验尸和任务
在Bugtracker中,与Google Docs或Wiki不同,在固定字段中可以设置一组值。 这有助于以后对统计图形进行分析。
在SRE书中,Google在Google文档中提供了一个模板,他们可以在其中将报告写入内部文档中。 我无法想象我们如何收集从非结构化Google文档中收集的分析数据。
我们可以在与主要任务相同的Bug跟踪器中编写报告,因为我们可以将任务与事后分析联系起来。 让我们研究一下验尸,然后立即查看哪些任务已关闭,哪些任务未完成以及哪些任务尚待完成。
创建特殊字段
我已经讨论过特殊领域。 我们有以下内容。
- fakap的开头和结尾可以自动分析。 如果放置机器可读的时间戳,则可以绘制fakap的持续时间。
- 调查的开始和结束。
- 扳机 设置触发器的下拉列表,更加方便。
- 如前所述。
- 定量和定性的损害。
- 受影响的团队和服务。
来自特殊字段的所有数据使您能够了解基础结构的工作方式。
我们完成的事件报告的示例。

右列的字段仅通过下拉列表中的选择进行填充。
召集一支关心质量的工程师团队
为了获得可以帮助您了解如何开发基础架构的报告,您将需要关心服务质量的人员。 不一定是只从事事后分析的工程师。 这些人非常关心正在发生的事情,这一点很重要。 他们会不时聚集,分析事件的整体,撰写大型文章并带来收益-关闭反馈环。
我们的团队称为Q团队-源自“质量”一词。 它拥有3名员工-该公司最有才能的基础架构工程师之一。
合计
阅读大师 John Allspaw的文章和事件管理书籍:
站点可靠性工程 ,
PagerDuty事后流程 ,
Atlassian事件手册 。
当您明天上班时,只需
采取以下第一步 :
- 在您执行任务的bugtracker中启动fakaps项目;
- 采用任何模板-请勿尝试编写自己的模板,采用我们的模板,也不要尝试从Google的SRE中获取模板;
- 当某些东西爆炸时,就写。
那时,当您编写第一份,第二份,第三份报告时,您将不会获得带有多色列的精美分析。 但是,在一两年后,当数据累积时,您可以回头并感谢您迈出的第一步。
我们希望,那么您会记得并感谢Alexei的经历。 反过来,我们将尝试将新的有用的报告收集到DevOpsConf计划中,并从中提出建议并加以应用。 会议将于2019年9月30日至1日举行,直到8月20日,我们仍在等待DevOps支持者的申请,但是12个已经被批准,也就是说,竞赛将在截止日期之前进一步提高。
如果您想分享自己的经验,请下定决心并发送摘要 。 如果您想接收节目新闻,请订阅我们的新闻和电报频道 。