6月底,卡耐基梅隆大学的一个团队向我们展示了XLNet,并立即布置了
出版物 ,
代码和完成的模型(
XLNet-Large ,带盒装:24层,隐藏
1024、16头)。 这是用于解决自然语言处理各种问题的预训练模型。
他们在出版物中立即指出了他们的模型与Google的
BERT的比较 。 他们写道,XLNet在许多任务上都优于BERT。 并显示了18个最新任务的结果。
BERT,XLNet和变压器
深度学习的最新趋势之一是转移学习。 我们训练模型以解决大量数据上的简单问题,然后使用这些预先训练的模型来解决其他更具体的问题。 BERT和XLNet就是经过预训练的网络,可以用来解决自然语言处理问题。
这些模型提出了“
变形金刚”的概念-当前构建模型以使用序列的主要方法。 非常详细的例子和有关变压器和注意机制的代码实例写在
“带注释的变压器”中 。
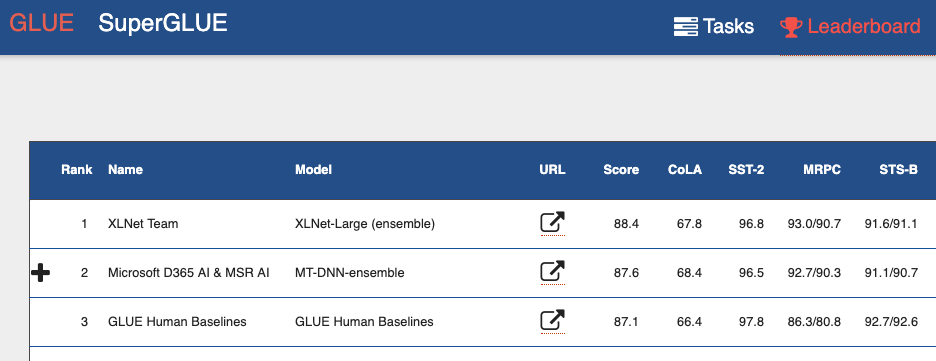
如果您查看
通用语言理解评估(GLUE)基准排行榜 ,则从顶部可以看到许多基于转换器的模型。 包括两个显示出比人类更好的结果的模型。 可以说,借助变形器,我们正在目睹自然语言处理方面的一次小革命。
BERT的缺点
BERT是一种自动编码器(autoencoder,AE)。 他隐藏并破坏了序列中的某些单词,并尝试从上下文中恢复单词的原始序列。
这导致该模型的缺点:
- 每个隐藏的单词都是单独预测的。 我们会丢失有关被屏蔽单词之间可能的关系的信息。 本文提供了一个名为“纽约”的示例。 如果我们尝试根据上下文独立预测这些单词,则不会考虑它们之间的关系。
- 训练BERT模型的阶段与使用预训练的BERT模型的阶段之间不一致。 训练模型时-我们有隐藏的单词([MASK]标记),当我们使用预先训练的模型时,我们尚未向输入中提供此类标记。
然而,尽管存在这些问题,BERT还是在许多自然语言处理任务上显示了最新的结果。
XLNet功能
XLNet是一种自回归语言建模AR LM。 她正在尝试根据先前标记的顺序来预测下一个标记。 在经典的自回归模型中,此上下文序列独立于原始字符串的两个方向获取。
XLNet概括了此方法,并在源序列的不同位置形成了上下文。 他是怎么做到的。 他接受了原始序列的所有(理论上)可能的排列,并根据先前序列预测了序列中的每个标记。
这是文章中的一个示例,该示例如何预测来自原始序列的各种排列的x3令牌。
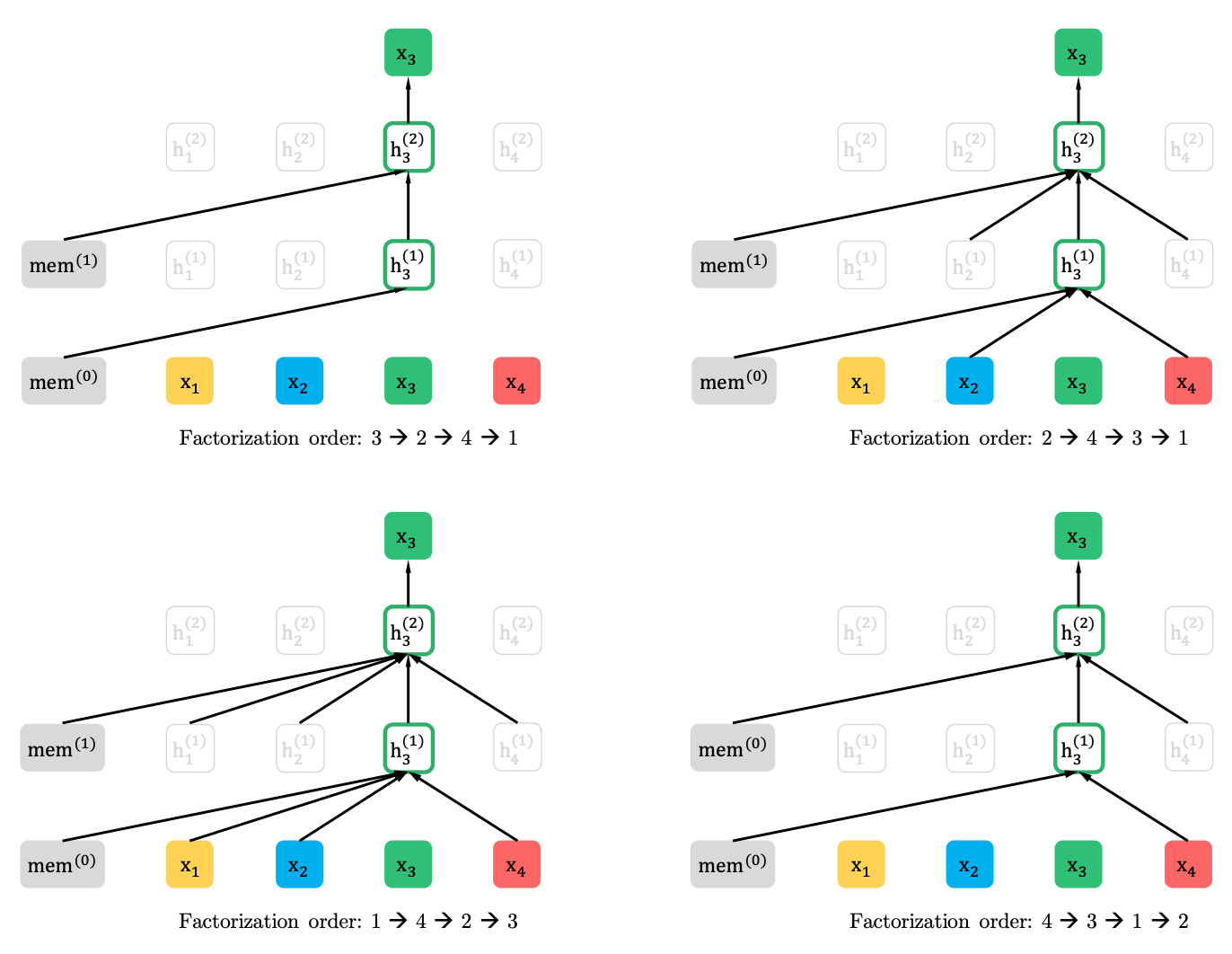
而且,上下文不是一句话。 有关令牌初始顺序的信息也将提供给模型。
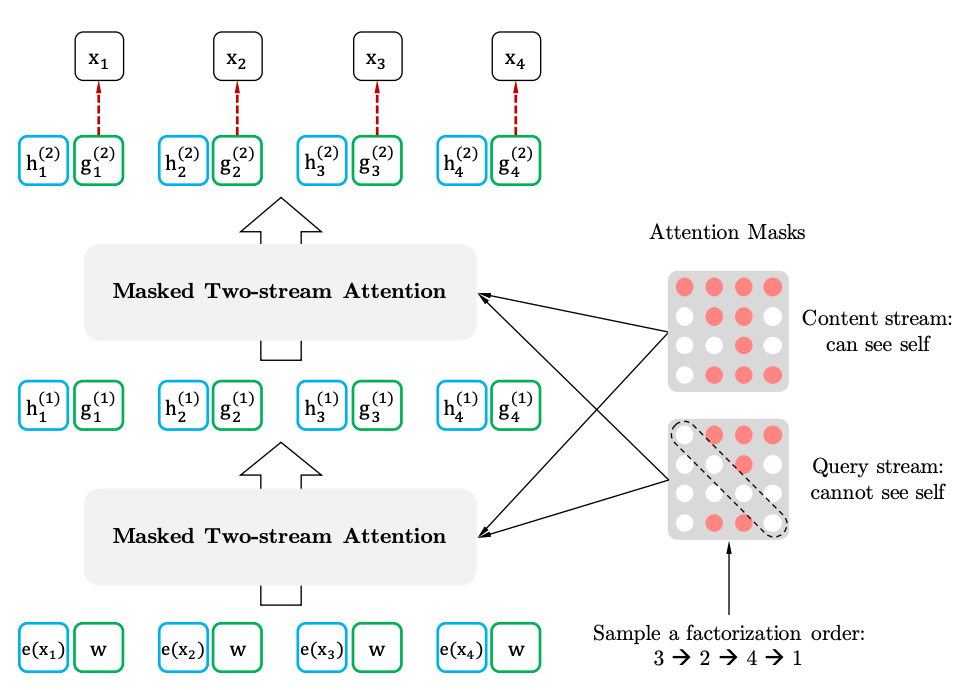
如果我们与BERT进行类比,事实证明我们不是预先屏蔽令牌,而是对不同的排列使用不同的隐藏令牌集。 同时,BERT的第二个问题消失了-使用预训练模型时缺少隐藏令牌。 对于XLNet,已经输入了不带掩码的整个序列。
XL的名称来自何处。 XL-因为XLNet使用了Transformer-XL模型中的Attention机制和想法。 尽管邪恶的语言声称XL暗示了训练网络所需的资源量。
关于资源。 他们在Twitter上发布了使用文章中的参数训练网络所需费用的
计算结果 。 结果是245,000美元。 没错,然后来自Google的工程师来
纠正了这篇文章,提到了512个TPU芯片,其中有四个在设备上。 也就是说,考虑到512个内核,成本已经是62,440美元,甚至32,720美元,本文中也提到了这一点。
XLNet与BERT
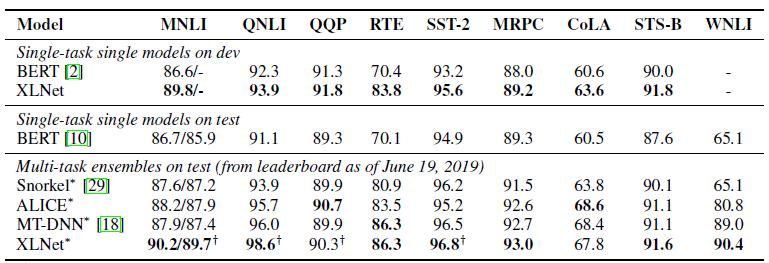
到目前为止,本文仅列出了一种经过预先训练的英语模型(XLNet-Large,Cased)。 但是本文还提到了使用较小模型的实验。 在许多任务中,与类似的BERT模型相比,XLNet模型显示出更好的结果。
BERT的出现,尤其是预训练的模型引起了研究人员的极大关注,并导致了大量相关工作。 现在是XLNet。 有趣的是,它是否会在一段时间内成为NLP中的事实上的标准,反之亦然,将刺激研究人员寻找新的架构和方法来处理自然语言。