大家好 在本文中,我将谈论我们在参加
2019年数据挖掘杯(DMC)数据分析比赛中的经验以及我们如何成功进入前10名球队并参加柏林全日制总决赛。

我将代表我进入的团队(亚历山大·佩列娃洛夫)以及我的同事谢尔盖·鲍勃科夫(Sergey Bobkov)进行讲解。 我们是
彼尔姆理工大学的研究生 ,我们在工作和学习的空闲时间致力于解决数据科学竞赛。
什么是DMC,我们如何找到它
数据挖掘杯是每年举行一次的全球学生数据分析冠军赛。 它的历史可以
追溯到 20年前,比
Kaggle早
得多 ,可以说
DMC在成为主流之前就举行了数据分析比赛 。
DMC
由零售情报公司德国公司
PrudSys托管 。 以前,只允许单手参加锦标赛,然后允许参与者团结大学的团队,顺便说一句,大学的最大团队数量只有2个。大学的会员资格也受到严格控制,要参加比赛,您必须与学生所在的域一起邮寄机构,以及发送学生证的副本。
今天,如果我们比较DMC和Kaggle的参与者水平,当然,Kaggle的水平要高得多。 这是由于DMC中对学生的限制以及Kaggle的普及。 DMC的一个显着特征是
没有排行榜 ,从而消除了安装它的问题。
当我们与来自大学的一群人一起去德国实习时,我了解了数据挖掘杯,当我回到家时,我的朋友和队友邀请我参加,那是4月中旬。 老实说,我对这个想法持怀疑态度,但是得知今年的数据和任务非常简单-我们仍然开始解决它。
我们如何解决任务
在2019年,任务位于自我检查欺诈检测领域。 当然,您已经在超市看到自助收银台。 这些设备既可以在商店员工的监督下工作,也可以全自动运行。 自助收银机使您可以优化人员成本,并最大程度地减少超市中的排队人数。 但是,存在一个问题,人的本性是,人们希望以某种方式“不突破”我们想要在冰箱中看到的商品。 为了避免这种情况,控制是必要的,但是这样也不会使客户感到尴尬或烦扰。
因此,基于关于自助结账交易的标记数据,有必要开发一种数学模型,该数学模型将特定交易自动分类为欺诈性或非欺诈性。 因此,我们解决了二进制分类问题。
数据如下:

训练样本的大小仅为1800个示例,而测试样本的大小为499000个示例。 同样,培训
样本也不均衡 :只有4%的交易是欺诈性的,很明显,
准确性 (正确答案的份额)在这里是无用的。 令人惊讶的是,数据中没有缺失值,并且某些属性分布均匀。 基于此,我们可以得出结论,
数据是人为生成的。此外,组织者还提出了混淆矩阵形式的度量标准,以货币单位衡量:
经过分析,我们发现在这种情况下Precision更为重要,因为
如果我们错误地将诚实的买家称为欺诈者,我们将承担最大的损失。我们的解决方案包括经典阶段:
- 基本数据分析
- 符号分析,描述性统计数据和分布
- 离群值去除
- 角色产生
- 建立模型并设定参数
- 验证和最终预测
包含我们解决方案内容的幻灯片可在以下
网站找到:
www.docdroid.net/2XEDfYg/dmc-2019-1.pdfGitHub上的存储库位于:
github.com/Perevalov/dmc2019 (所有内容分散在不同的分支上,直到有时间将所有内容整理好为止)
组织决赛
在5月初发送了最终决定后,我们开始期待结果。 组织者的条件
是,邀请前10名团队参加在柏林举行
的面对面决赛 ,这是2019年零售情报峰会会议的一部分:智能零售的明智决策。
供参考,
2019年,来自28个国家/地区的114所大学的149个团队参加了DMC。老实说,我们甚至都不希望进入决赛 ,但是现在,5月底,那份珍贵的邀请函到来了。 此外,所有决赛入围者都被要求支付最高500欧元的费用,他们还提供了在举办活动的酒店住一晚的费用。
我们毫不犹豫地买了去柏林的机票,然后去了签证。 作为贫穷的学生,对于我们来说,为期2天的旅行的费用总额相当大。 Perm-Berlin-Perm门票和签证处理的费用约为40,000卢布。 每人,这是500欧元多一点。
由于我们代表大学参加了此次活动,因此我们决定从中获得物质支持。 此外,彼尔姆理工大学还实施了促进俄德关系发展的计划,并大力支持初学者(在我们看来是如此)。 在我们研究部门的负责人的批准和签名下,我们进入了科学与创新部门。 开始了长达一个月的官僚史诗,其结尾如下:
“没有钱,但是你坚持下去 。
” 当然,我们有些沮丧,但并没有灰心。 现在,荒谬的是,阅读了我们大学的高层管理人员有关“需要支持年轻科学家”和其他废话的各种说法。 好吧,是题外话。
我们在短短2周内获得了签证。 同时,我们准备了演讲报告,并于7月2日晚上去了机场。
数据挖掘杯决赛和颁奖典礼上的表演
7月3日早上到达柏林,我们去了会议所在的nHow酒店。 当然,组织水平很高。 的确,参加会议的费用是每人1000欧元(对我们来说是免费的)。 这是酒店的样子:

我们的演出原定于16:30举行。 它在主会议室以自然的英语进行。 顺便说一句,最终的评分没有考虑表演本身,它只是根据最终的评分来计算的,只有组织者才有数据。
前十支队伍中有以下大学:乔治华盛顿大学(美国),日内瓦大学(瑞士),开姆尼茨技术大学(德国),爱荷华大学(美国)等,当然还有彼尔姆国立研究技术大学。
这是会议室的样子:

令我有些尴尬的是,我不得不讲话而不是幻灯片,而是要在屏幕上显示一张海报。 因此,参与者的表现不足以提供信息。 但是,仍有机会接近并查看会议室中每个参与者的纸质海报。 基本上,大多数人都使用
堆叠,混合和集合 (我们也属于其中),一些参与者使用了更高的分类模型
阈值 ,几个团队设法完全不生成特征,并在源代码上构建了模型。
顺便说一句,我们是最小的团队-只有2个人。
表演结束后,盛大的晚宴和奖励开始了。 我们希望获得奖品,但意识到这不太可能,因此我们平凡的愿望是“至少不等于10”。 结果完全符合我们的期望-我们获得了光荣的第9名。 自然,这有点令人讨厌,但是我们在如此认真的大学中进入决赛的事实已经说明了很多。 优胜者是美国爱荷华大学的参与者,尽管您不能说他们来自各州(见图):
 一等奖,二等奖和三等奖分别为2,000欧元,1,000欧元和500欧元。
一等奖,二等奖和三等奖分别为2,000欧元,1,000欧元和500欧元。 最终评分如下:
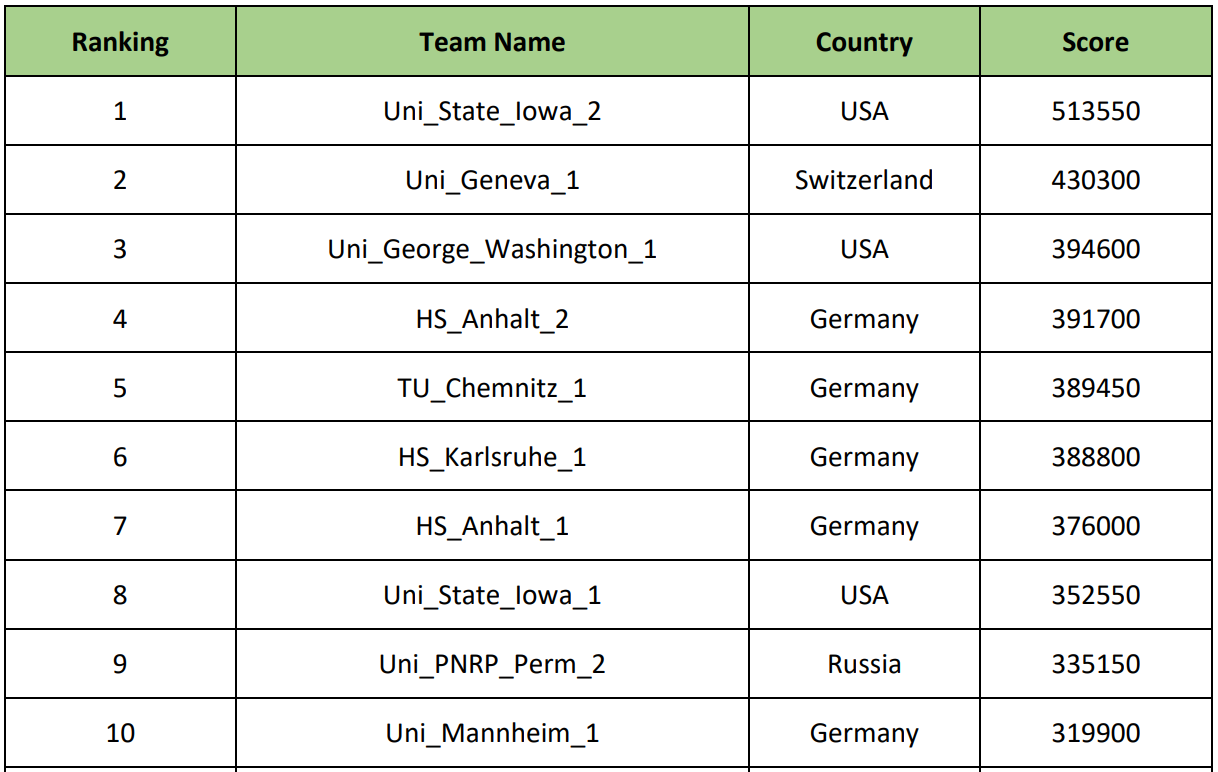
结论
我们不后悔参加了这项比赛有多少。 至少,这是投资组合中的+1成就,是与人们最有用的联系,并且是代表我们的城市和国家参加国际活动的机会。
我建议所有科学家参加此类活动,这很酷!