GitHub托管着300多种编程语言-从常用的语言(例如Python,Java和Javascript)到深奥的语言(例如
Befunge) ,只有很小的社区才知道。
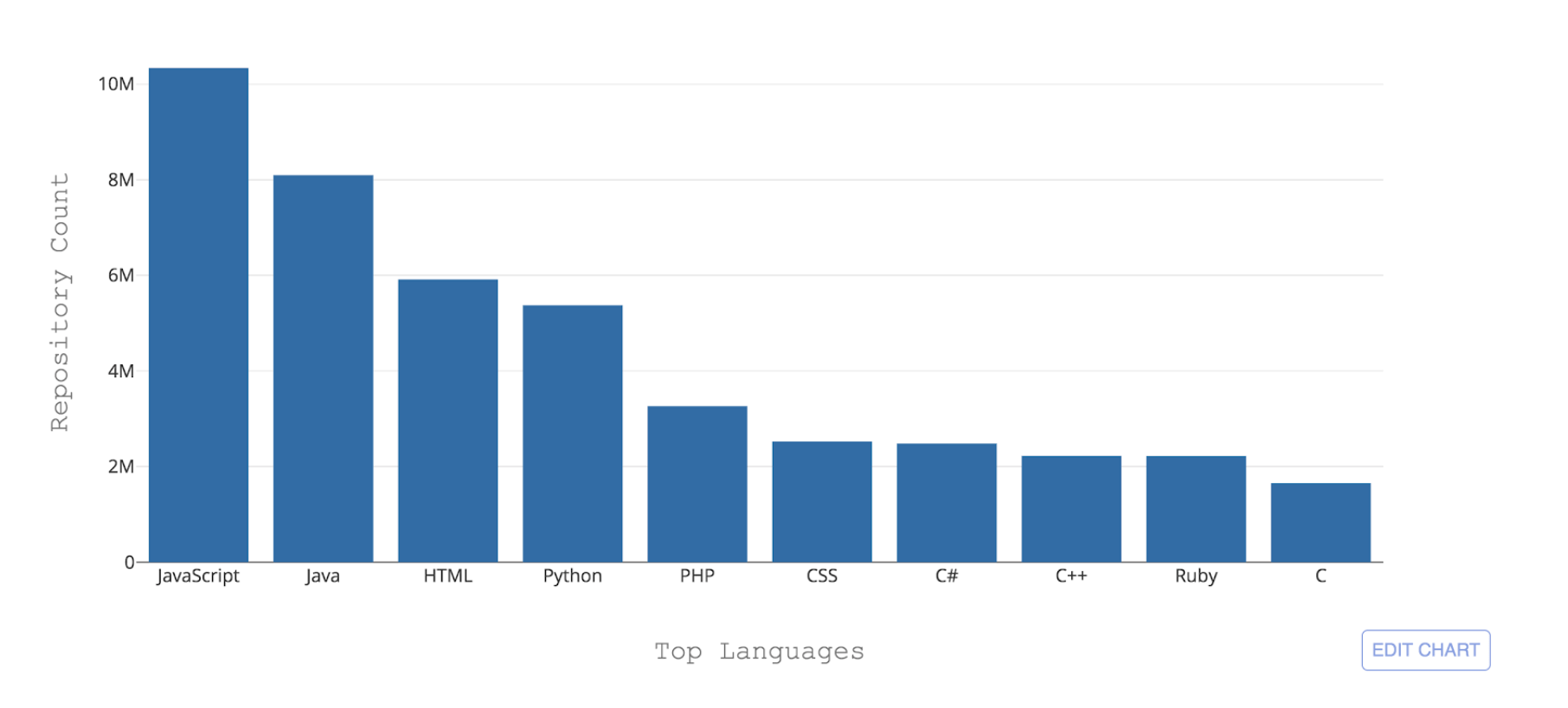 图1:按存储库数量计,GitHub托管的十大编程语言
图1:按存储库数量计,GitHub托管的十大编程语言GitHub面临的必要挑战之一是能够识别这些不同的语言。 将某些代码推送到存储库后,重要的是要识别添加的代码类型,以进行搜索,安全漏洞警报和语法突出显示,并向用户显示存储库的内容分布。
Linguist是我们目前在GitHub上用于检测编码语言的工具。 Linguist是一个基于Ruby的应用程序,该应用程序使用各种策略进行语言检测,利用命名约定和文件扩展名,还考虑到Vim或Emacs的模式行以及文件顶部的内容(shebang)。 语言学家通过启发式方法处理语言歧义,如果失败,则通过对一小部分数据样本进行训练的朴素贝叶斯分类器来解决。
尽管Linguist可以很好地进行文件级语言预测(准确度为84%),但是当文件使用意外的命名约定时,并且至关重要的是,没有提供文件扩展名时,其性能会大大下降。 这使得Linguist不适合GitHub Gist或自述文件,问题和提取请求中的代码段之类的内容。
为了使语言检测从长远来看更加强大和可维护,我们基于人工神经网络(ANN)架构开发了一种名为Octo Lingua的机器学习分类器,该分类器可以在棘手的情况下处理语言预测。 该模型的当前版本能够预测GitHub托管的前50种语言,并且在准确性和性能方面都超过了Linguist。
OctoLingua背后的基本要点
OctoLingua是使用Python,Keras和TensorFlow后端从头开始构建的,并且构建准确,健壮且易于维护。 在本节中,我们描述了OctoLingua的数据源,模型架构和性能基准。 我们还描述了添加对新语言的支持所需的内容。
资料来源
当前版本的OctoLingua接受了从
Rosetta Code和内部众包的高质量存储库中检索的文件的培训。 我们将语言集限制为GitHub上托管的前50种语言。
Rosetta Code是出色的入门数据集,因为它包含以不同编程语言表达的同一任务的源代码。 例如,生成
斐波那契序列的任务用C,C ++,CoffeeScript,D,Java,Julia等表示。 但是,跨语言的覆盖范围并不统一,其中某些语言仅包含少量文件,而某些文件则过于稀疏。 因此,有必要使用一些其他资源来扩充我们的培训集,并大大提高语言覆盖率和性能。
现在,我们添加新语言的过程是完全自动化的。 我们以编程方式从GitHub上的公共存储库中收集源代码。 我们选择满足最低资格标准的存储库,例如具有最少数量的派生,涵盖目标语言和涵盖特定文件扩展名的存储库。 在此阶段的数据收集中,我们使用Linguist中的分类来确定存储库的主要语言。
特点:利用先验知识
传统上,对于神经网络的文本分类问题,经常使用基于内存的体系结构,例如递归神经网络(RNN)和长期短期记忆网络(LSTM)。 但是,由于编程语言在词汇,注释样式,文件扩展名,结构,库导入样式和其他细微差别方面存在差异,因此我们选择了一种更简单的方法,该方法通过以表格形式提取一些相关功能来利用所有这些信息。我们的分类器。 当前提取的功能如下:
- 每个文件的前五个特殊字符
- 每个文件的前20个令牌
- 文件扩展名
- 存在源代码文件中常用的某些特殊字符,例如冒号,花括号和分号
人工神经网络(ANN)模型
我们将以上功能用作使用Keras与Tensorflow后端构建的两层人工神经网络的输入。
下图显示了特征提取步骤为我们的分类器生成了n维表格输入。 随着信息沿着我们网络的各个层移动,它会通过丢弃进行正则化,并最终产生一个51维输出,该输出代表给定代码以GitHub上前50种顶级语言中的每种语言编写的预测概率以及该概率不是用任何这些写的。
图2:我们初始模型的ANN结构(50种语言+ 1种“其他”语言)我们使用了90%的数据集进行了大约八个时期的训练。 此外,在训练步骤中,我们从训练数据中删除了一定百分比的文件扩展名,以鼓励模型从文件的词汇中学习,而不是过度预测文件扩展名功能。
绩效基准
OctoLingua与 语言学家在图3中,我们显示了OctoLingua和Linguist在相同测试集上计算出的
F1得分 (精确度与召回率之间的谐和平均值)(来自原始数据源的10%)。
在这里,我们显示三个测试。 第一个测试是以任何方式保持测试集不变。 第二项测试使用了相同的测试文件集,但文件扩展名信息已删除,而第三项测试也使用了相同的文件集,但是这一次,文件扩展名被打乱,以致混淆了分类符(例如,Java文件可能带有“。”。 txt“扩展名和Python文件可能具有” .java“)扩展名。
在我们的测试集中扰乱或删除文件扩展名的直觉是,当关键功能被删除或造成误解时,评估OctoLingua在文件分类中的鲁棒性。 不高度依赖扩展名的分类器对要点和摘要进行分类非常有用,因为在这种情况下,人们通常不提供准确的扩展名信息(例如,许多与代码相关的要点具有.txt扩展名)。
下表显示了OctoLingua如何在各种条件下保持良好的性能,这表明该模型主要从代码的词汇中学习,而不是从元信息(即文件扩展名)中学习,而Linguist在文件扩展名上的信息一经出现就会立即失败。改变了。
图3:OctoLingua与 语言学家在同一测试集上在培训期间删除文件扩展名的效果如前所述,在培训期间,我们从培训数据中删除了一部分文件扩展名,以鼓励模型从文件词汇中学习。 下表显示了我们的模型的性能,其中在培训期间删除了不同部分的文件扩展名。
 图4:OctoLingua的性能,在我们的三个测试版本中删除了不同百分比的文件扩展名
图4:OctoLingua的性能,在我们的三个测试版本中删除了不同百分比的文件扩展名请注意,在训练期间未删除文件扩展名的情况下,OctoLingua在没有扩展名和随机扩展名的测试文件上的性能明显低于常规测试数据。 另一方面,当在删除了某些文件扩展名的数据集上训练模型时,修改后的测试集的模型性能不会降低太多。 这证实了在训练时从一小部分文件中删除文件扩展名会使我们的分类器从词汇中学习更多。 它还显示了文件扩展名功能,尽管具有很高的预测性,但仍具有占主导地位的趋势,并阻止了将更多权重分配给内容功能。
支持新语言
在OctoLingua中添加新语言非常简单。 首先从获取新语言的大量文件开始(我们可以按照数据源中的描述以编程方式进行此操作)。 这些文件分为训练和测试集,然后通过我们的预处理器和特征提取器运行。 新的培训和测试集已添加到我们现有的培训和测试数据池中。 新的测试集使我们能够验证模型的准确性仍然可以接受。
图5:使用OctoLingua添加新语言我们的计划
到目前为止,OctoLingua处于“高级原型开发阶段”。 我们的语言分类引擎已经强大且可靠,但是尚不支持平台上的所有编码语言。 除了扩展语言支持(这将是非常简单的)之外,我们还旨在实现各种粒度级别的语言检测。 通过对机器学习引擎进行少量修改,我们当前的实现已经允许我们对代码段进行分类。 将模型带到可以可靠地检测和分类嵌入式语言的阶段,并不是一件容易的事。
我们也正在考虑开放模型采购的可能性,如果您感兴趣的话,希望能收到社区的意见。
总结
借助OctoLingua,我们的目标是提供一种服务,该功能能够在从文件级或代码段级到潜在的行级语言检测和分类的多个粒度级别上进行可靠可靠的源代码语言检测。 最终,该服务可以支持代码可搜索性,代码共享,语言突出显示和差异渲染等所有功能,除了帮助他们编写高质量的代码外,还旨在为开发人员的日常开发工作提供支持。 如果您有兴趣利用我们的工作或为我们的工作做出贡献,请随时与Twitter
@github联系 !