4月27日,在
Strike-2019大会上,在DevOps部分的框架内,发表了一份报告,题为``Kubernetes中的自动扩展和资源管理''。 它讨论了如何使用K8来确保应用程序的高可用性并确保其最大性能。

按照传统,我们很高兴提供一个
带有报告的
视频 (44分钟,比文章多得多),并以文本形式进行主要挤压。 走吧
我们将从字眼上分析报告的主题,并从头开始。
Kubernetes
让我们在主机上安装Docker容器。 怎么了 为了确保可重复性和隔离性,这反过来又允许简单,良好的部署CI / CD。 我们有很多这样的带有容器的机器。
在这种情况下,Kubernetes有什么用?
- 我们不再考虑这些机器,而是开始使用“云”,即一组容器或Pod(容器组)。
- 此外,我们甚至不考虑单个吊舱,而是管理更多的大型吊舱。 这样的高级原语使我们可以说,存在一个用于启动特定工作负载的模板,但是需要用于启动它的实例数量。 如果我们随后更改模板,则所有实例也会更改。
- 我们使用声明性API,而不是执行一系列特定命令,而是描述Kubernetes创建的“世界设备”(在YAML中)。 再说一次:当描述改变时,其实际显示也将改变。
资源管理
中央处理器
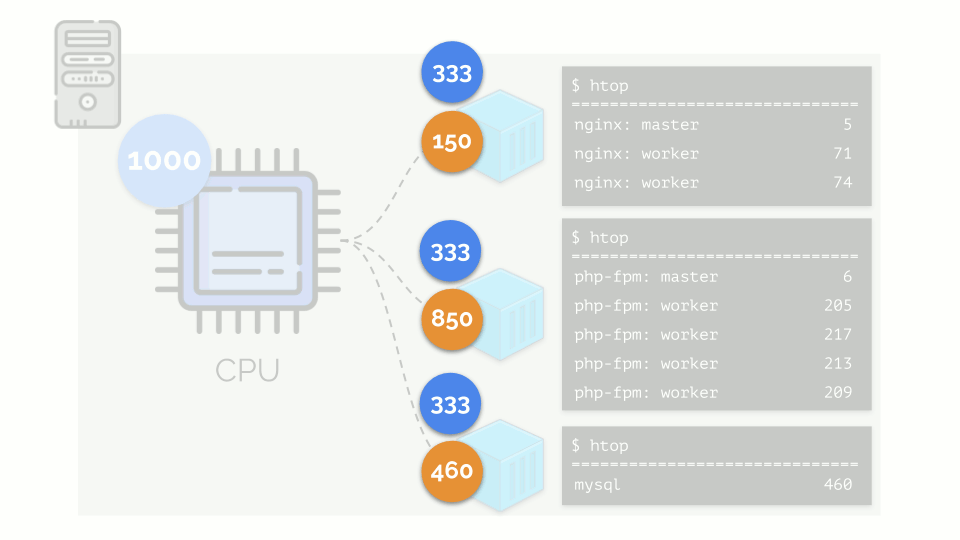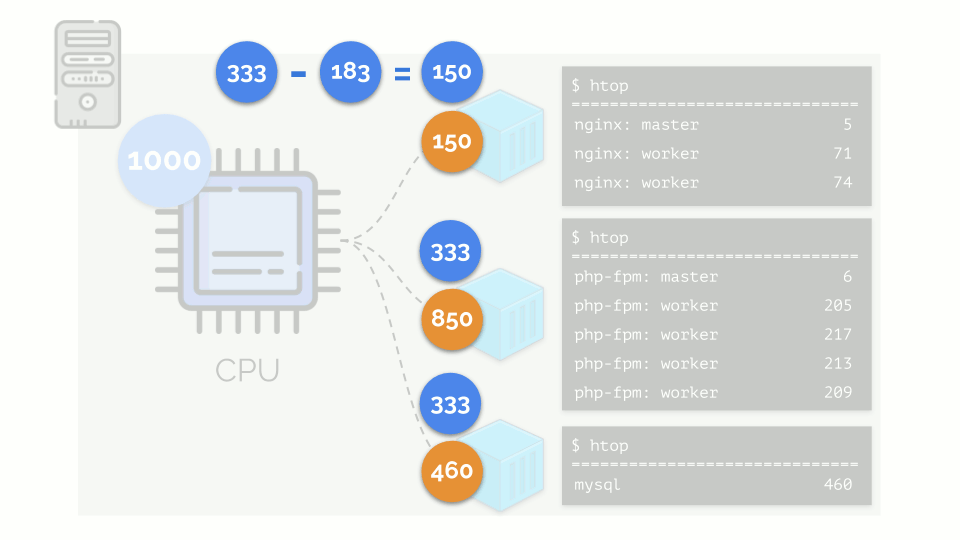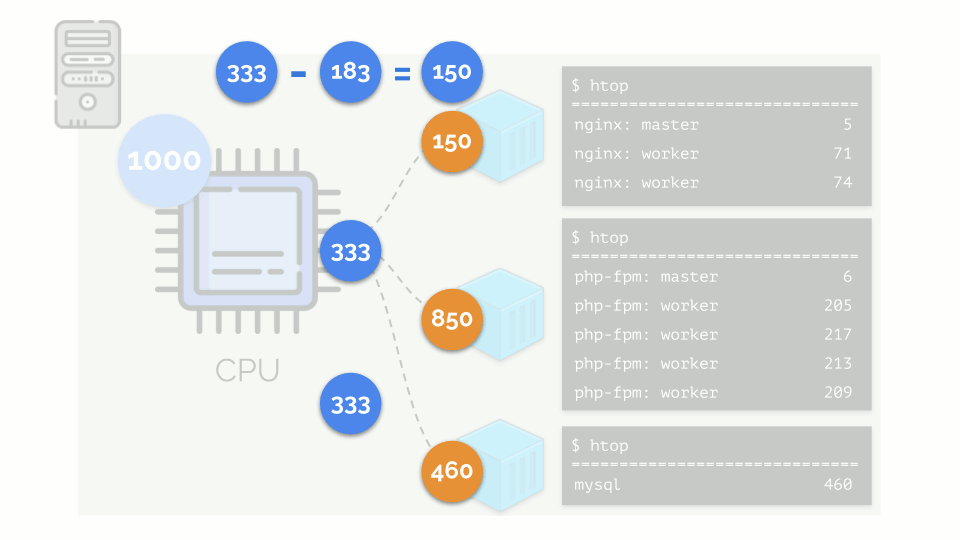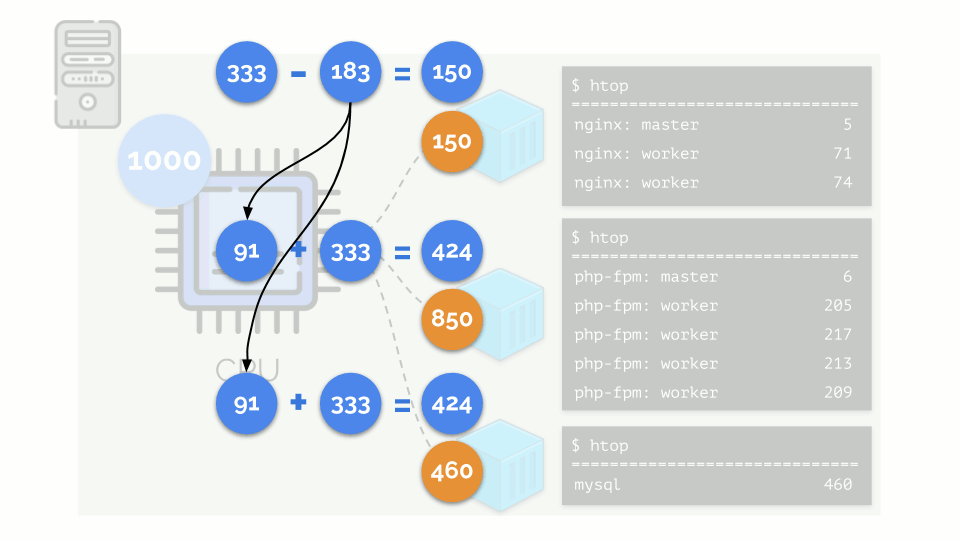
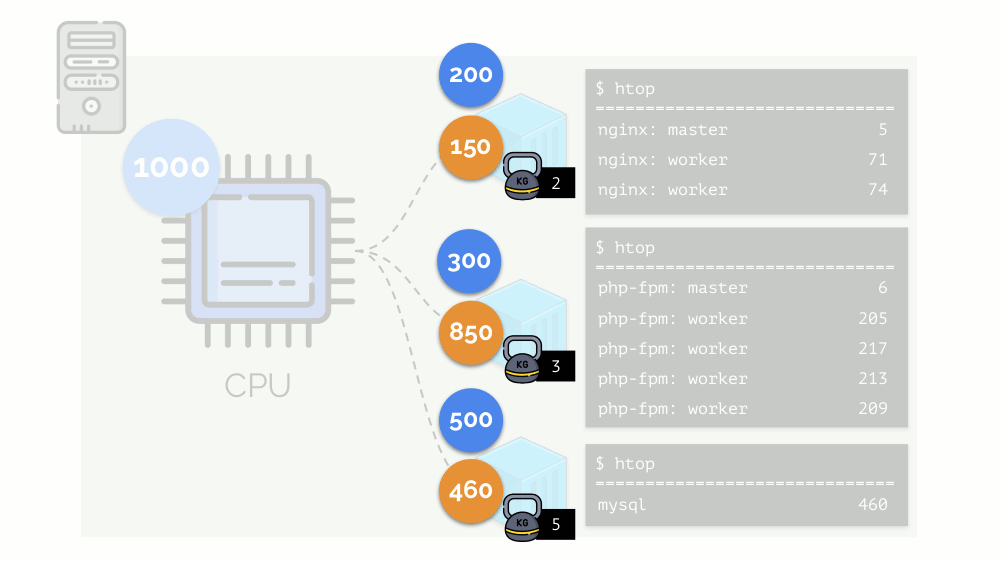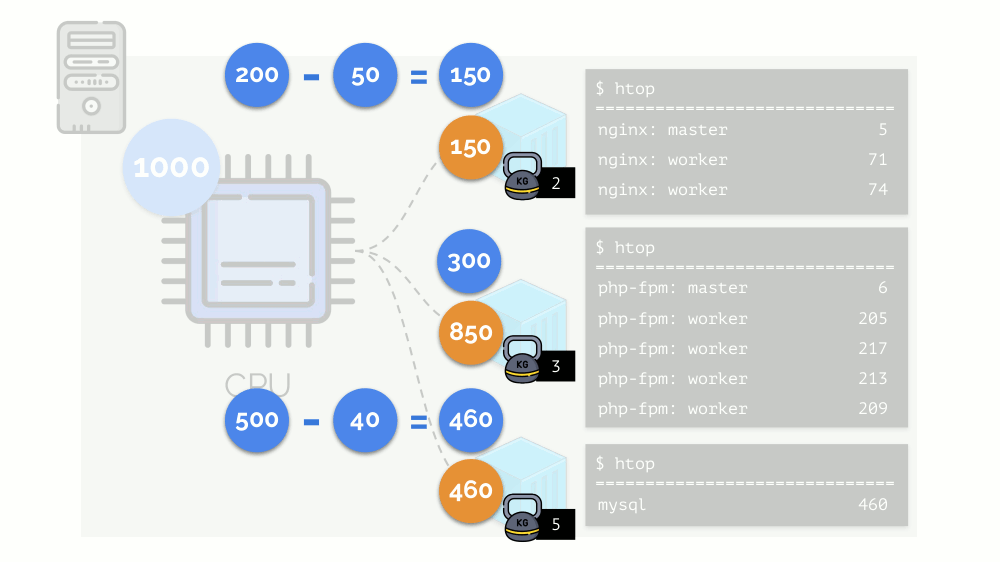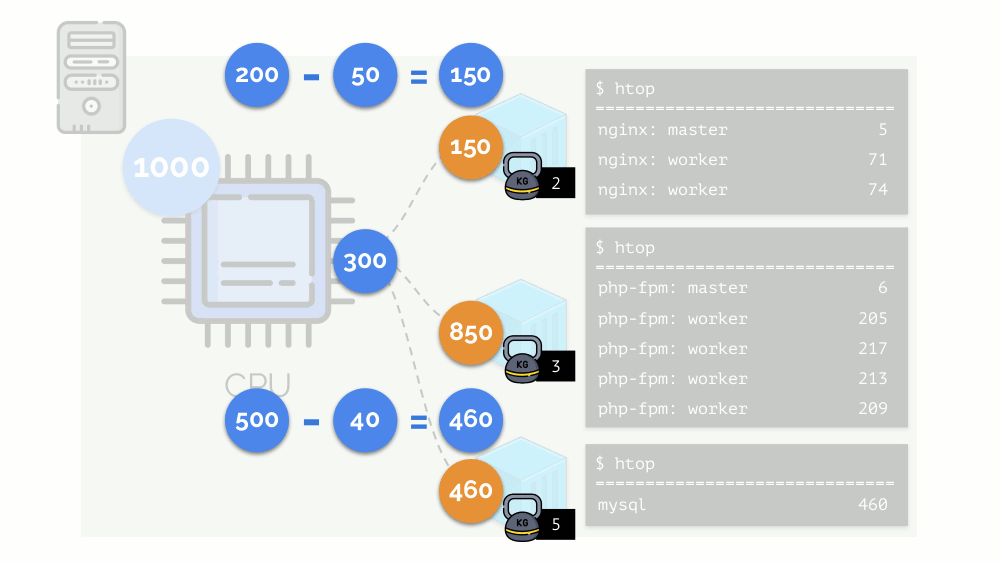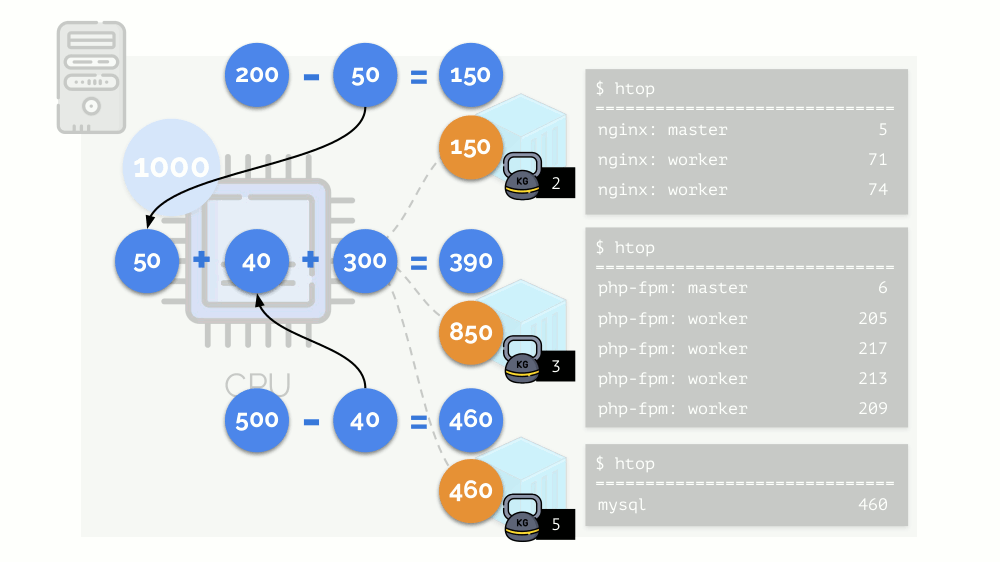
让我们在服务器上运行nginx,php-fpm和mysql。 这些服务实际上将具有更多正在运行的进程,每个进程都需要计算资源:
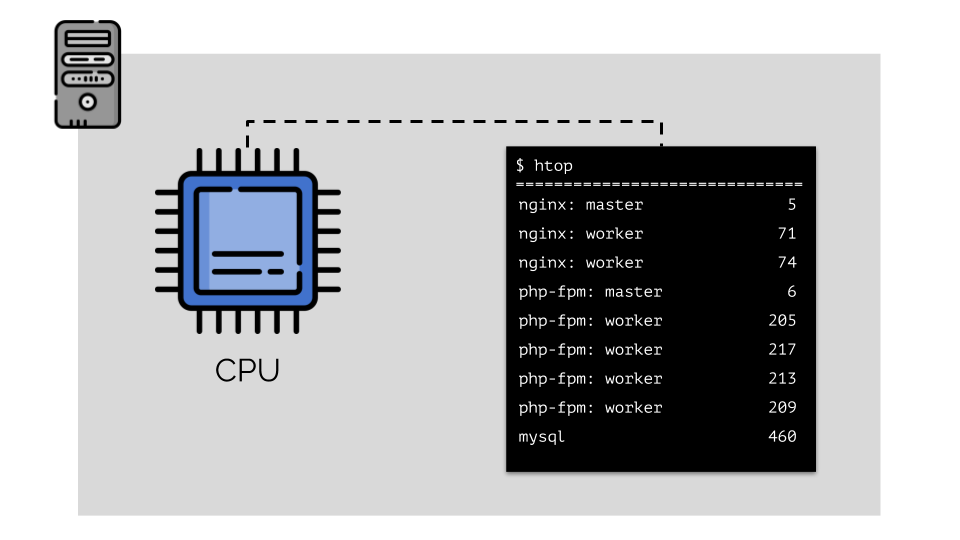 (幻灯片上的数字是“鹦鹉”,这是每个过程计算能力的抽象需求)
(幻灯片上的数字是“鹦鹉”,这是每个过程计算能力的抽象需求)为了方便使用,将进程组合成组是合乎逻辑的(例如,将所有nginx进程组合成一个“ nginx”组)。 一种简单而明显的方法是将每个组放在一个容器中:
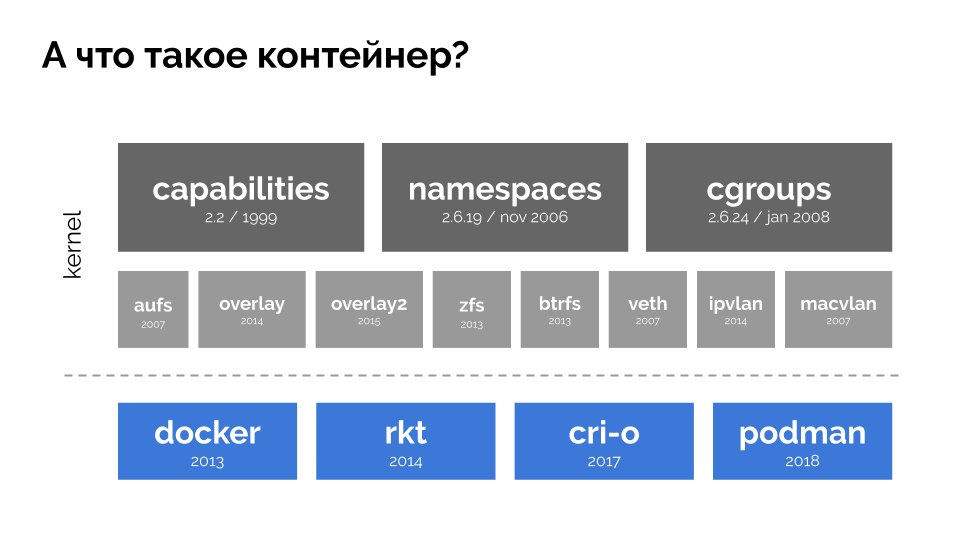
要继续,您需要记住什么是容器(在Linux上)。 内核中的三个关键特性已实现很长时间,这使得它们的出现成为可能:
功能 ,
名称空间和
cgroups 。 其他技术(包括便利的“ shell”,如Docker)为进一步的发展做出了贡献:
在本报告的上下文中,我们仅对
cgroup感兴趣,因为控制组是实现资源管理的容器(Docker等)功能的一部分。 如我们所希望的那样,将过程分组在一起的就是对照组。
让我们返回这些进程以及进程组的CPU需求:
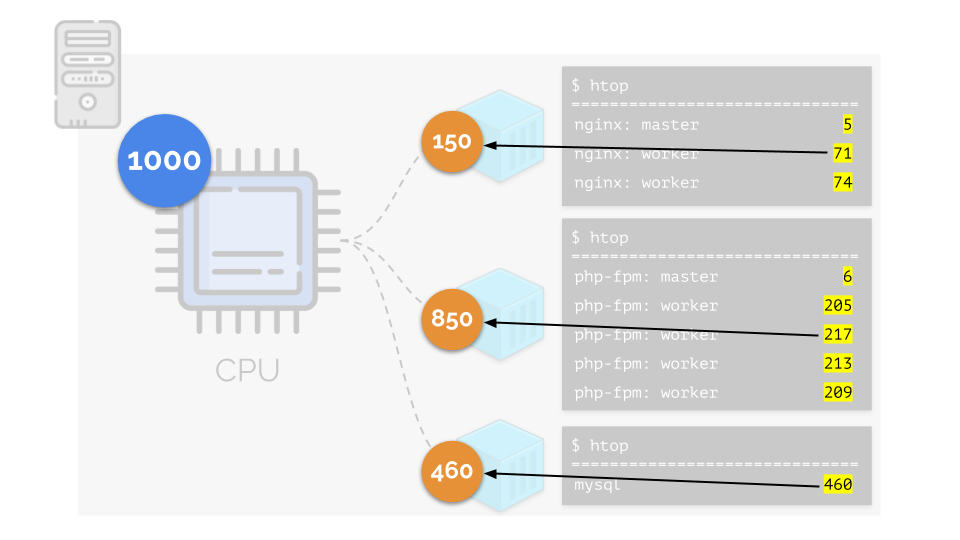 (我重复说所有数字都是资源需求的抽象表达)
(我重复说所有数字都是资源需求的抽象表达)同时,CPU本身具有一定的最终资源
(在示例中为1000) ,可能对于每个人来说都是不够的(所有组的总需求为150 + 850 + 460 = 1460)。 在这种情况下会发生什么?
内核开始分配资源并“诚实”地进行,将相同数量的资源分配给每个组。 但在第一种情况下,它们的数量超出了必要的数量(333> 150),因此剩余的数量(333-150 = 183)仍然保留,这也平均分配给其他两个容器:
结果是:第一个容器有足够的资源,第二个-不够,第三个-不够。 这是
Linux -
CFS中 “诚实”调度程序的结果。 可以通过
为每个容器分配
重量来调节其工作。 例如,像这样:
让我们看一下第二个容器(php-fpm)缺少资源的情况。 所有容器资源在进程之间平均分配。 结果,主流程运行良好,所有工作人员都变慢了,所收到的资源不到所需数量的一半:
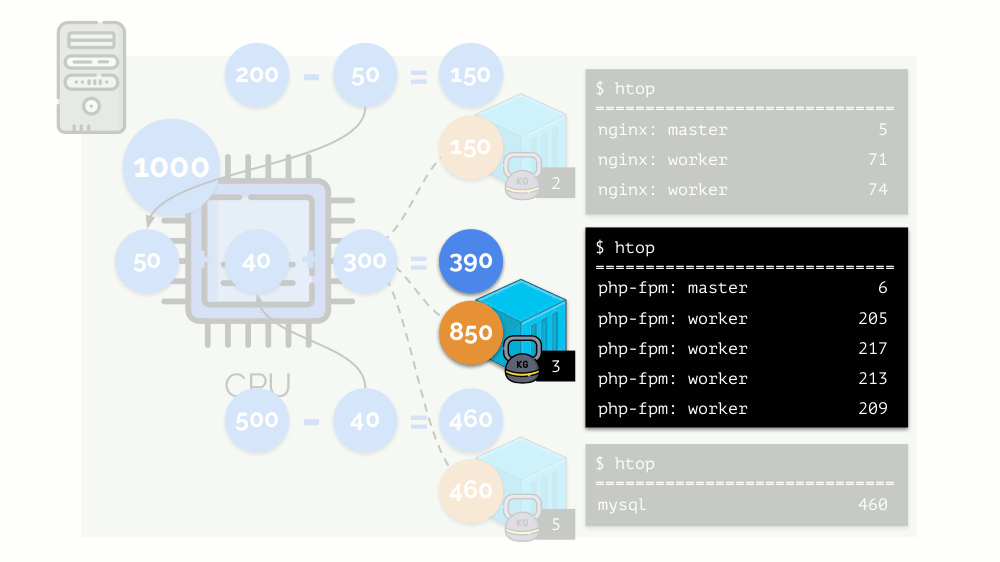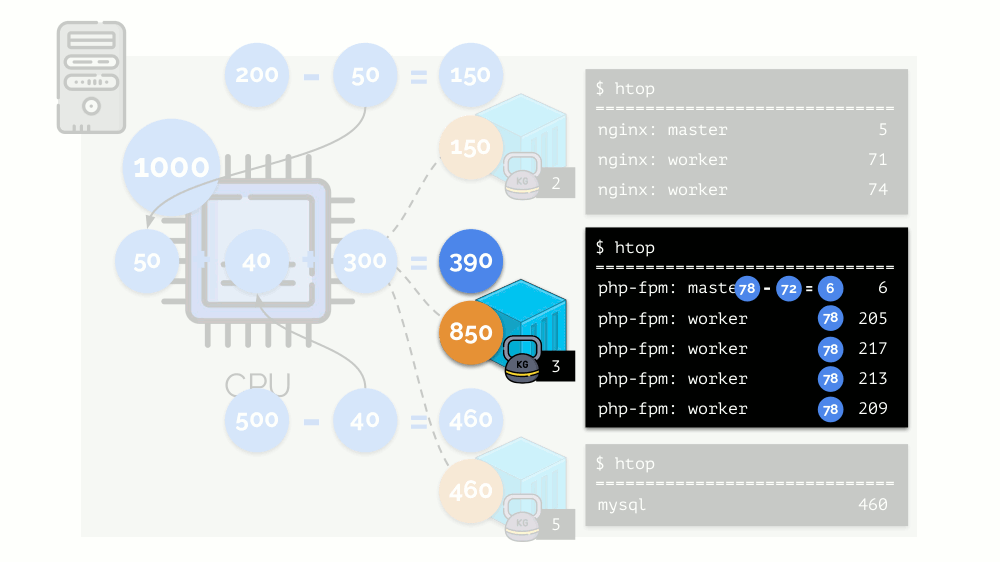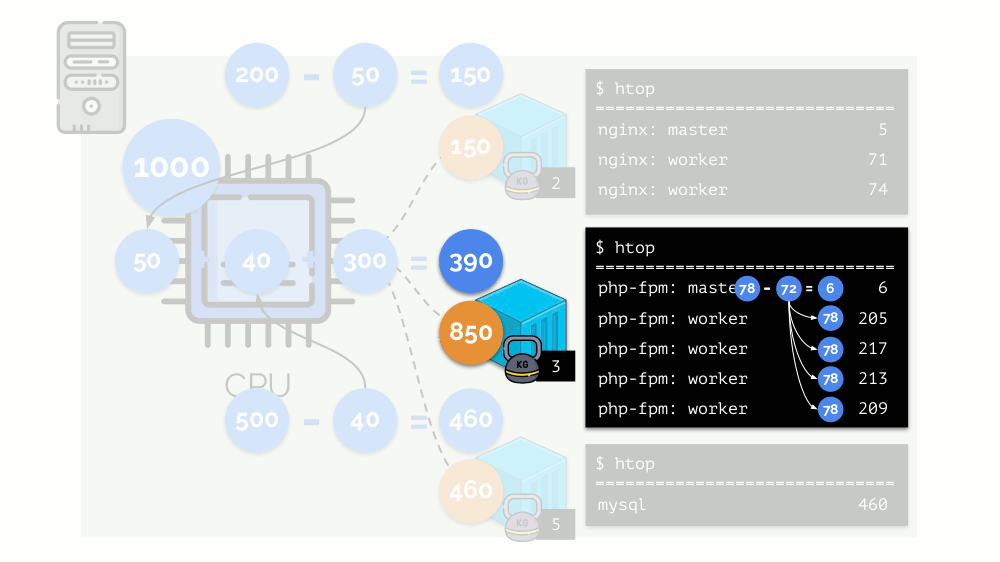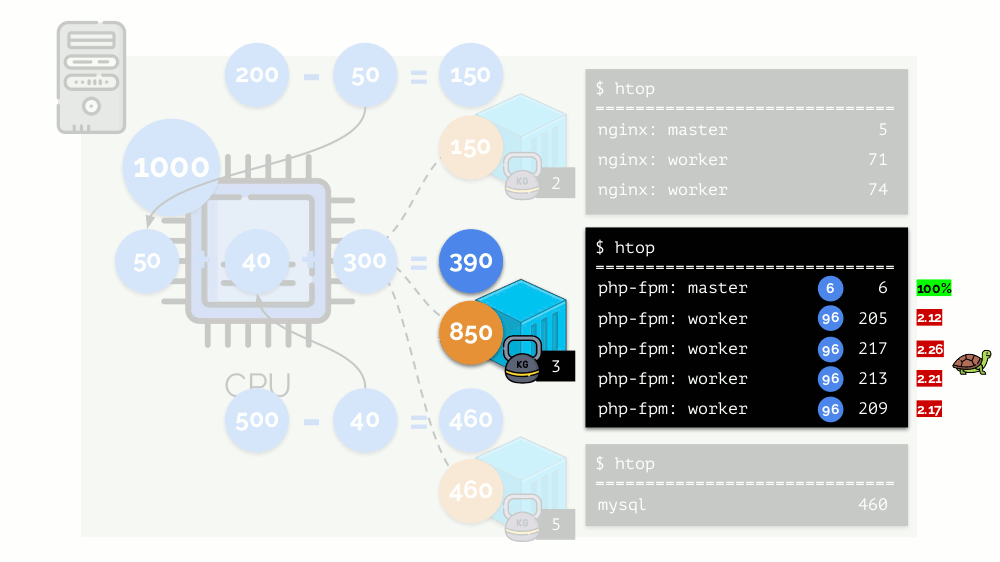
这就是CFS调度程序的工作方式。 我们分配给容器的权重在将来将称为
请求 。 为什么这样-见下文。
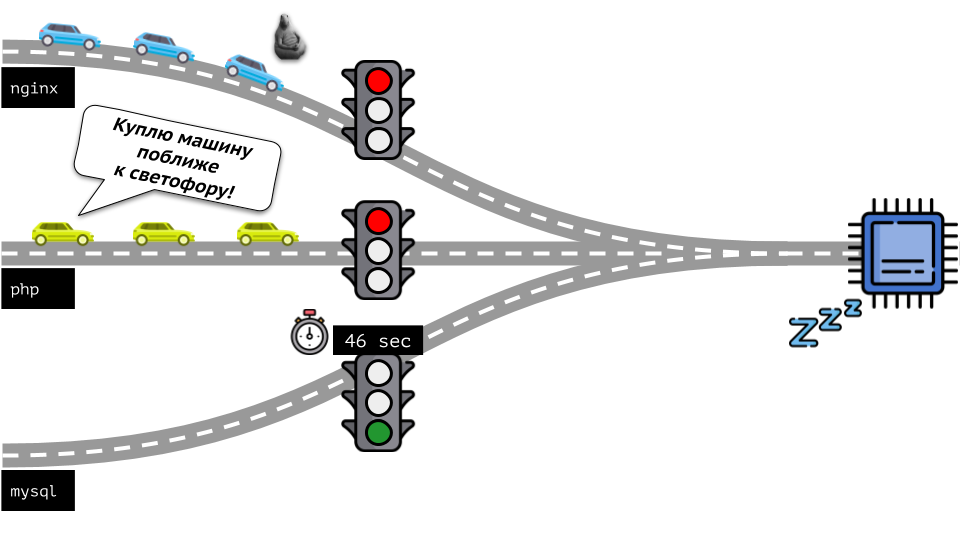
让我们从另一端看整个情况。 如您所知,条条大路通罗马,从计算机到CPU。 一个CPU,很多任务-您需要一个交通信号灯。 管理资源最简单的方法是“交通灯”:它们为一个进程提供对CPU的固定访问时间,然后给下一个进程以此类推。
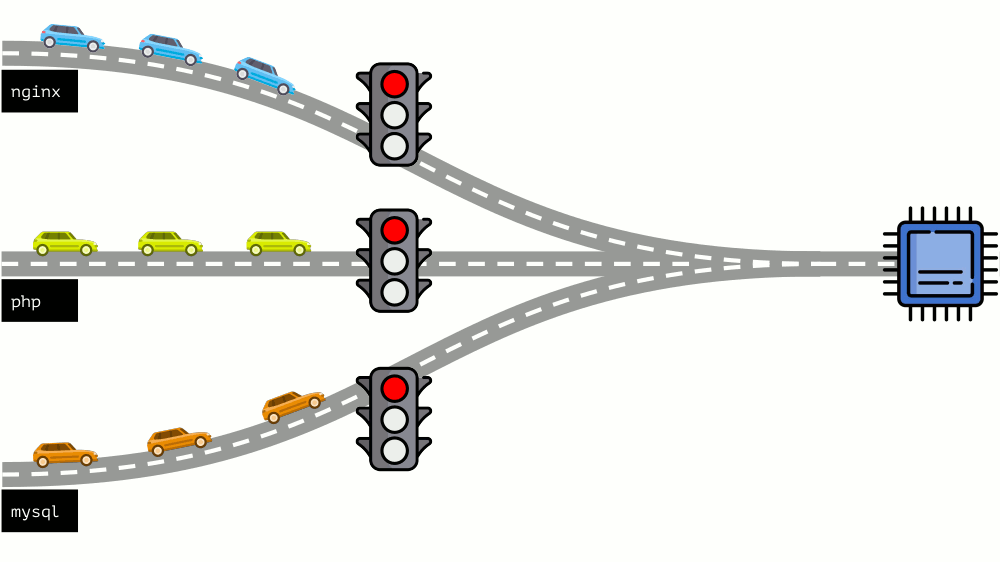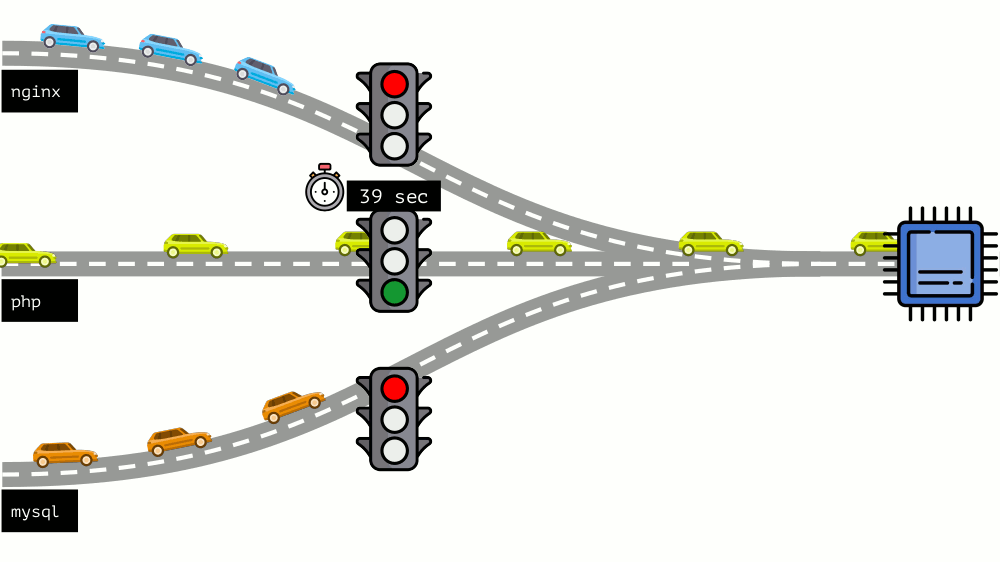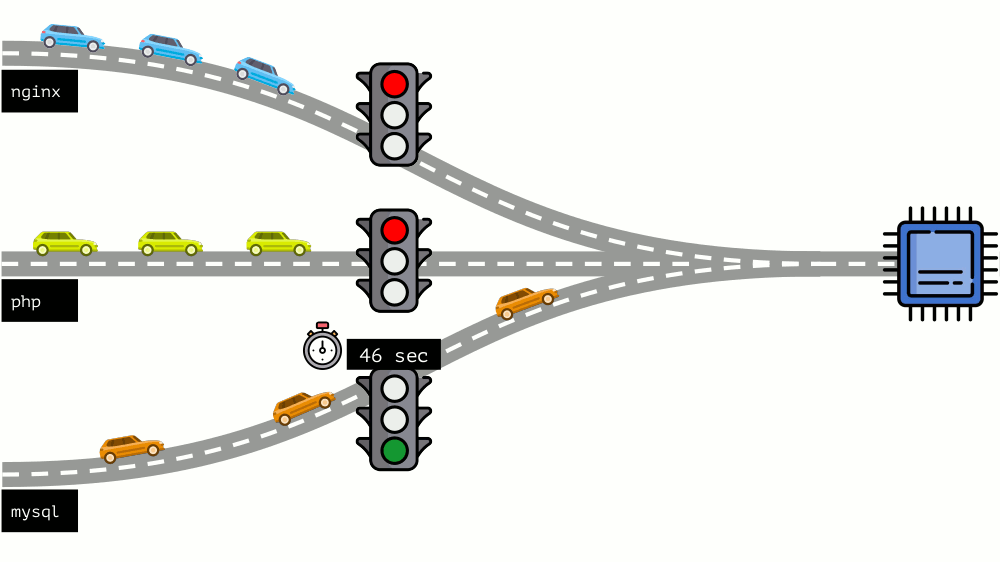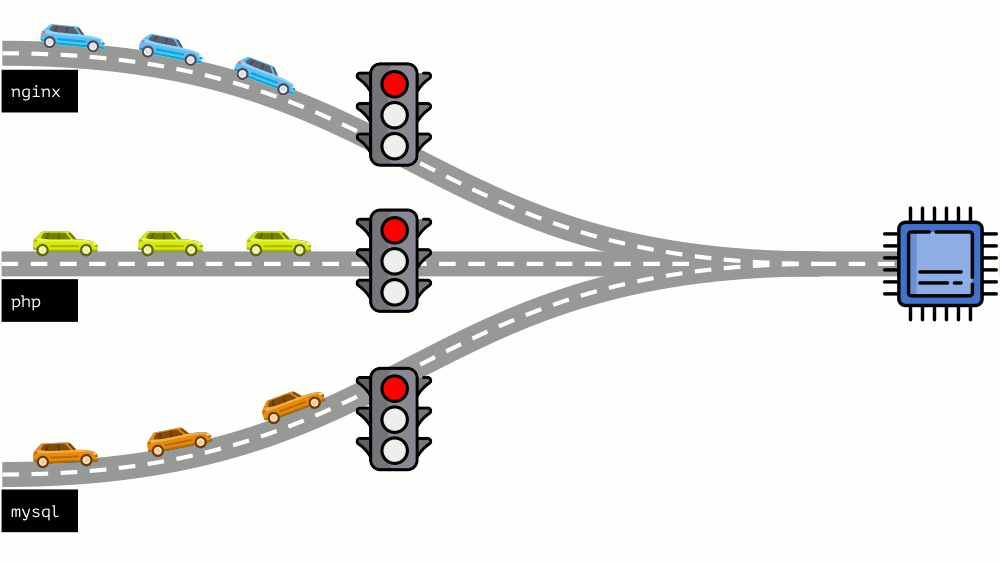
这种方法称为
硬限制 。 记住它只是
极限 。 但是,如果将限制分配给所有容器,则会出现问题:mysql在路上行驶,在某个时候他对CPU的需求终止了,但是所有其他进程都被迫在CPU
空闲时等待。
让我们回到Linux内核及其与CPU的交互-总体情况如下:
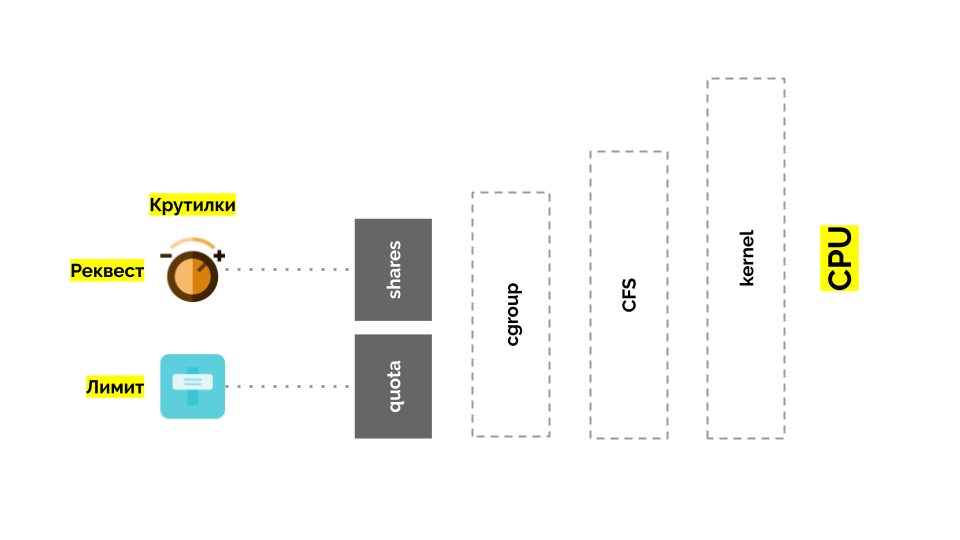
Cgroup有两个设置-实际上,这是两个简单的“扭曲”,可让您确定:
- 容器(请求)的重量为份额 ;
- 用于执行容器任务(限制)的CPU总时间的百分比是quota 。
如何测量CPU?
有不同的方法:
- 没人知道什么是鹦鹉 -每次您都需要同意时。
- 兴趣更明显,但是相对:拥有4个核心和20个核心的服务器中有50%是完全不同的东西。
- 您可以使用Linux知道的已经提到的权重 ,但是它们也是相对的。
- 最合适的选择是在几秒钟内测量计算资源。 即 以秒为单位的处理器时间(相对于实时秒数):他们以1秒钟的时间提供了1秒的处理器时间-这是一个完整的CPU内核。
为了更容易说,他们开始直接在
内核中进行测量,这意味着相对于实际
内核的CPU时间。 由于Linux理解权重而不是处理器时间/内核,因此需要一种从一种到另一种的转换机制。
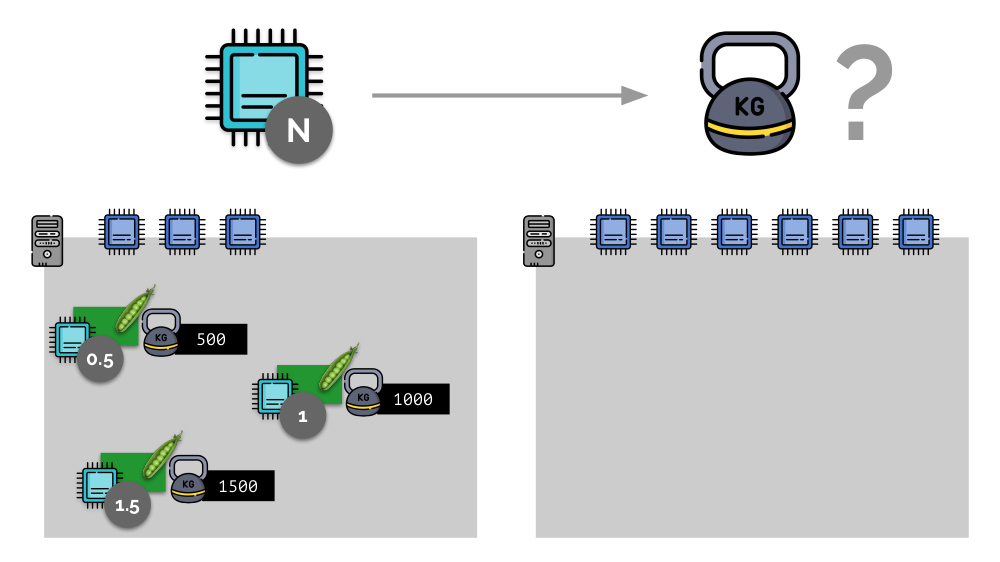
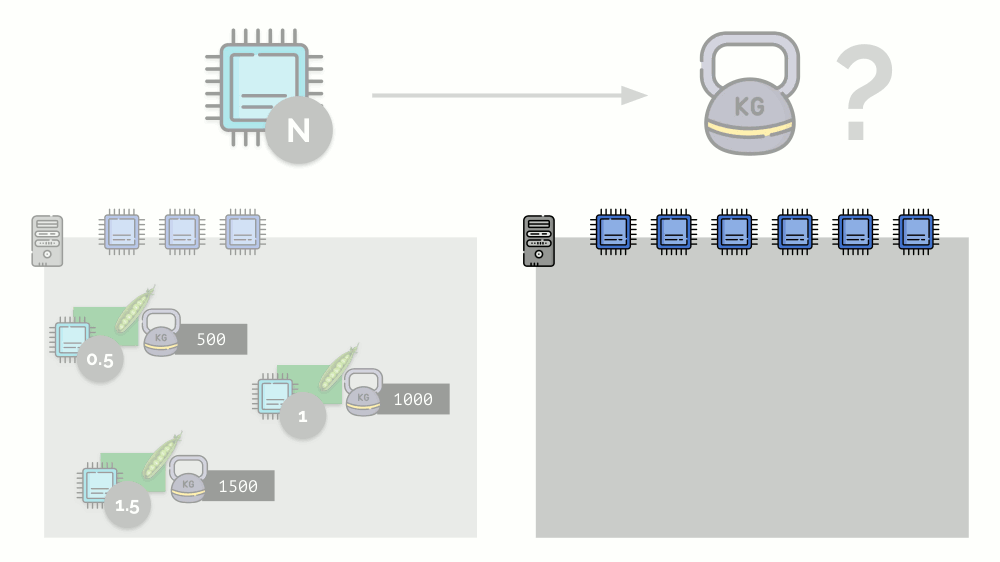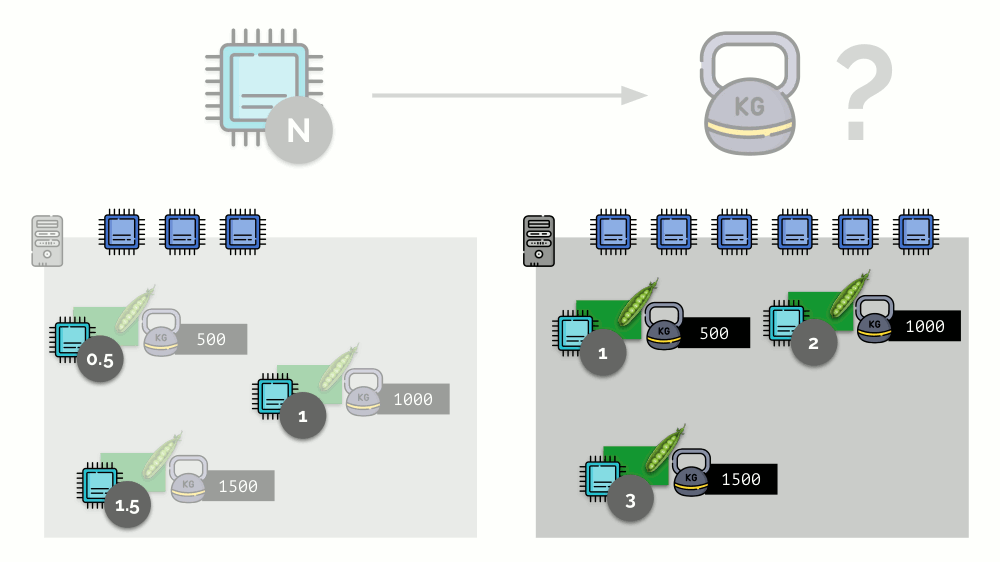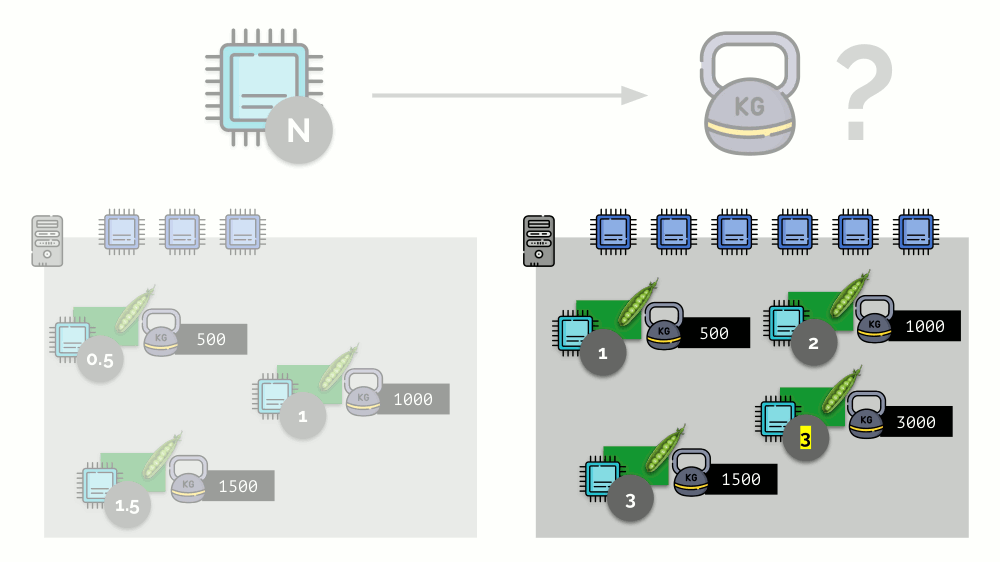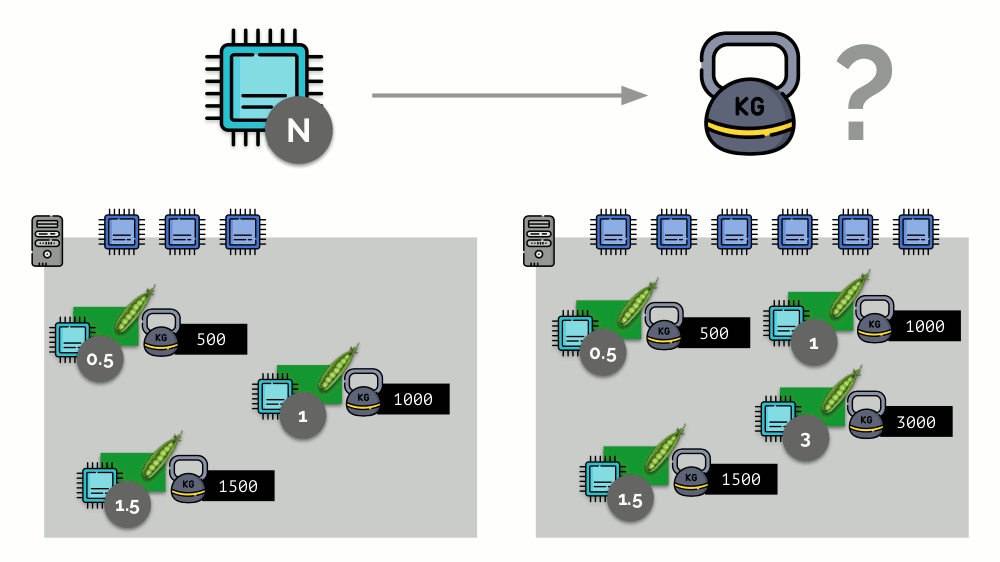
考虑一个带有3个CPU内核的服务器的简单示例,其中三个Pod将选择权重(500、1000和1500),这些权重可以轻松转换为分配给它们的内核的相应部分(0.5、1和1.5)。
如果您使用第二台服务器,其中的核心数(6)会增加一倍,并在其中放置相同的Pod,则只需将其乘以2(分别为1、2和3)就可以轻松计算出核心的分布。 但是重要的一点是,当第四个Pod出现在此服务器上时,为方便起见,其权重可能为3000,占用了一些CPU资源(一半的内核),其余Pod重新计数了(一半):
Kubernetes和CPU资源
在Kubernetes中,CPU资源通常以
毫核心为单位进行衡量,即 0.001粒为基重。
(在Linux / cgroups术语中,相同的东西称为CPU份额,不过,更精确地说,是1000 CPU = 1024 CPU份额。) K8s确保在服务器上放置的Pod不超过权重之和的CPU资源。所有豆荚。
怎么样了 将服务器添加到Kubernetes集群后,它会报告有多少个CPU内核可供使用。 在创建新的Pod时,Kubernetes调度程序会知道此Pod需要多少个内核。 因此,将在具有足够核心的服务器上定义容器。
如果
未指定请求(即,pod无法确定所需的内核数量),将会发生什么? 让我们看看Kubernetes通常如何计算资源。
窗格可以同时指定请求(CFS调度程序)和限制(还记得红绿灯吗?):
- 如果它们相等,则将保证的QoS类分配给Pod。 这样的内核始终可供他使用。
- 如果请求小于限制,则QoS类是可突发的 。 即 例如,我们希望Pod始终使用1个内核,但是此值并没有限制: 有时 Pod可以使用更多的内核(服务器上有可用资源的时候)。
- 还有一个尽力而为的 QoS类-未为其指定请求的那些Pod属于它。 最后将资源提供给他们。
记忆
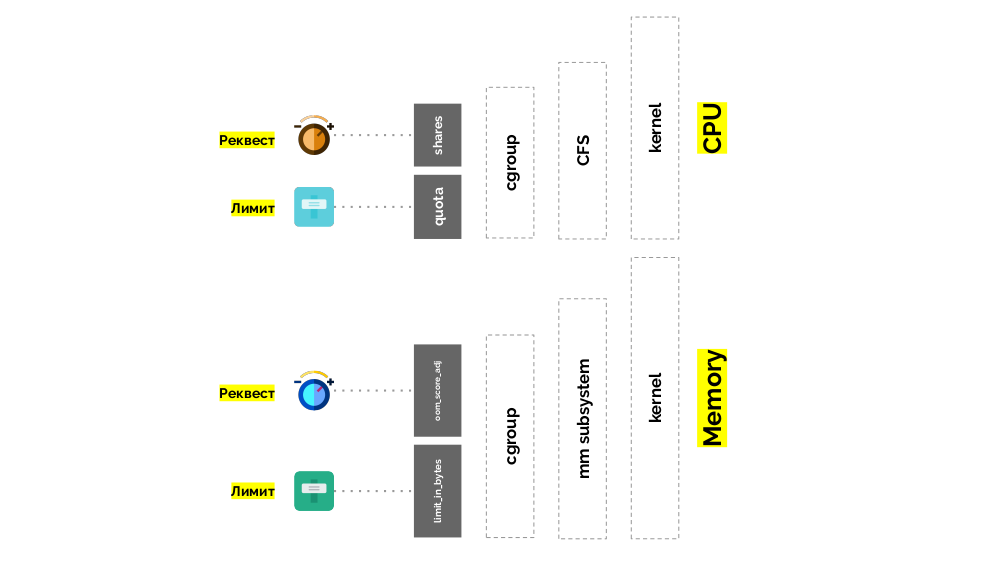
内存的情况与此类似,但有所不同-毕竟,这些资源的性质是不同的。 通常,类比如下:
让我们看看如何在内存中实现请求。 让Pod驻留在服务器上,更改消耗的内存,直到其中一个变得太大而导致内存用完。 在这种情况下,OOM杀手出现并杀死最大的进程:
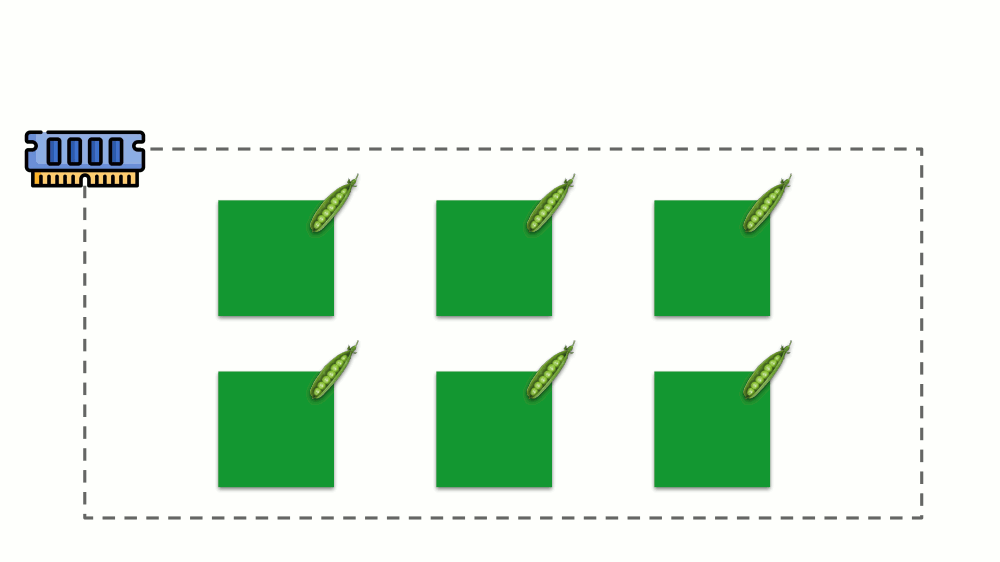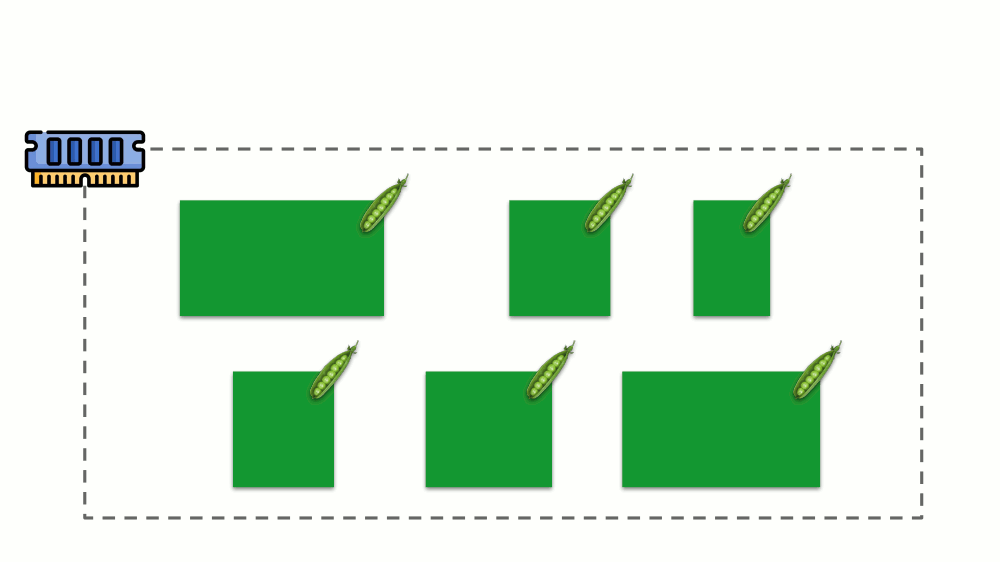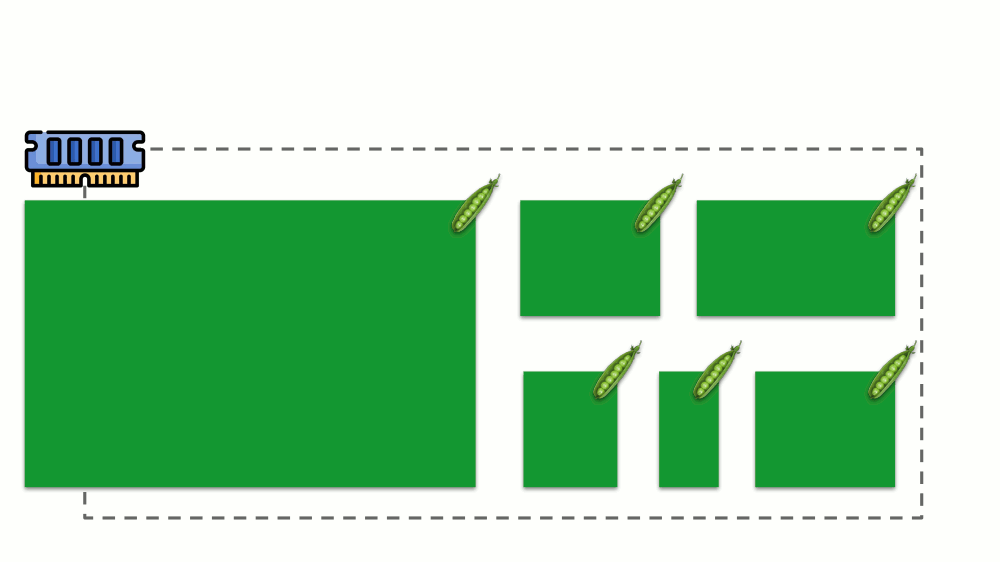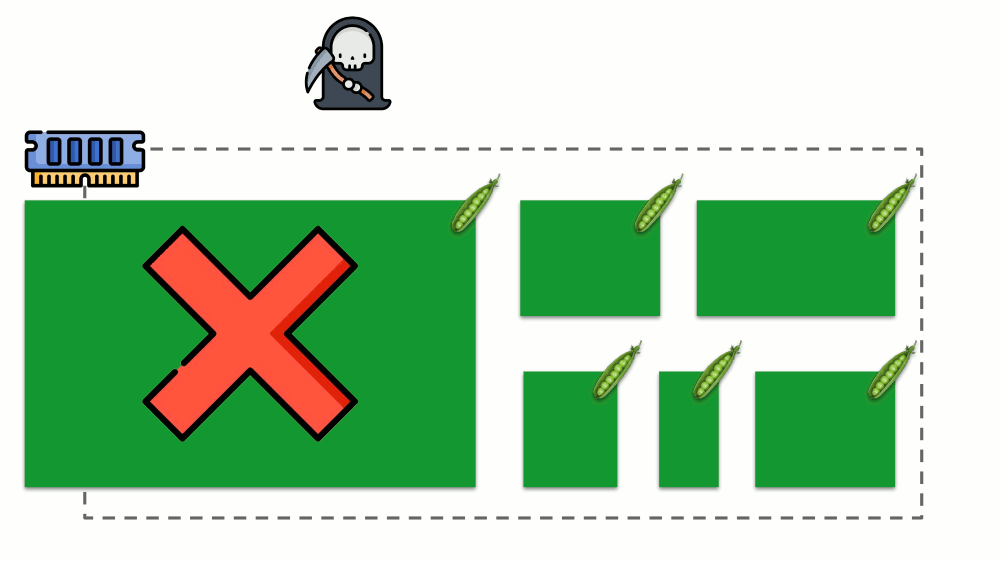
这并不总是适合我们,因此,可以调节哪些过程对我们很重要并且不应被终止。 为此,请使用
oom_score_adj参数。
让我们回到CPU QoS类,并用oom_score_adj值进行类比,该值确定Pod的内存消耗优先级:
- 吊舱的最低oom_score_adj值为-998,这意味着应在最后一个位置杀死此类吊舱,这是可以保证的 。
- 最高的-1000-是最大的努力 ,此类吊舱在其他任何人之前被杀死。
- 为了计算其余的值( 可爆 ),有一个公式的本质可以归结为以下事实:荚请求的资源越多,被杀死的机会就越少。

第二个“扭曲”
-limit_in_bytes-用于限制。 使用它,一切都变得更简单:我们只需分配要发出的最大内存量,并且在这里(与CPU不同)毫无疑问,要测量的是什么(内存)。
合计
为Kubernetes中的每个Pod设置请求和
limits -CPU和内存的参数:
- 根据请求,Kubernetes调度程序可以工作,它可以在服务器之间分配pod。
- 基于所有参数,确定吊舱的QodS类别;
- 相对权重是根据CPU请求计算得出的;
- 根据CPU请求,配置CFS调度程序。
- 根据内存请求,可以配置OOM杀手。
- 根据CPU限制,配置“交通灯”;
- 根据内存限制,在cgroup上设置一个限制。
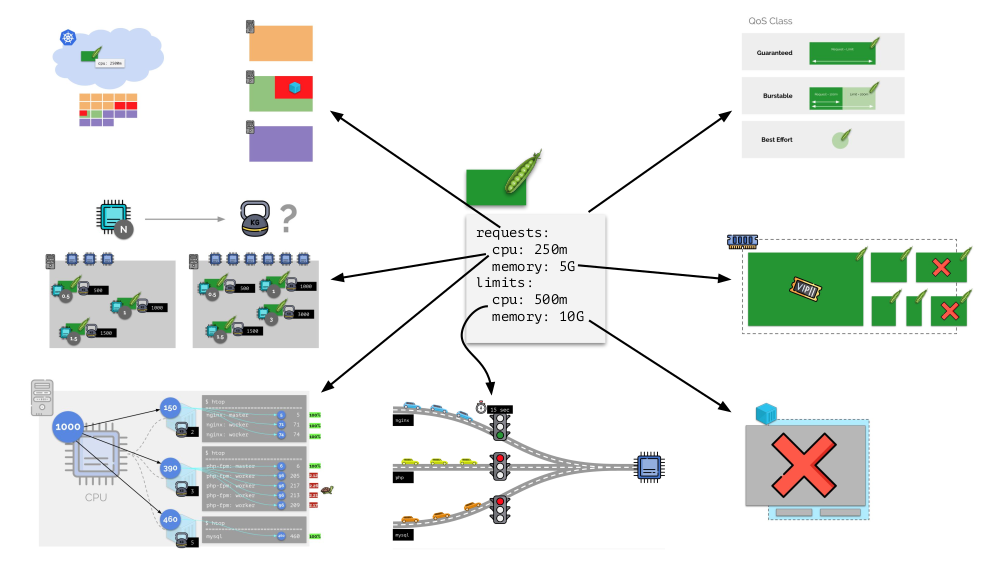
通常,这张图片回答了有关Kubernetes中资源管理的主要部分如何发生的所有问题。
自动缩放
K8s集群自动缩放器
想象一下整个集群已经被占用,必须创建一个新的Pod。 当窗格无法显示时,它将挂起处于
挂起状态。 为使它确实出现,我们可以将新服务器连接到群集或...放置cluster-autoscaler,这将为我们完成:从云提供商订购虚拟机(通过API请求)并将其连接到群集,之后将添加Pod 。
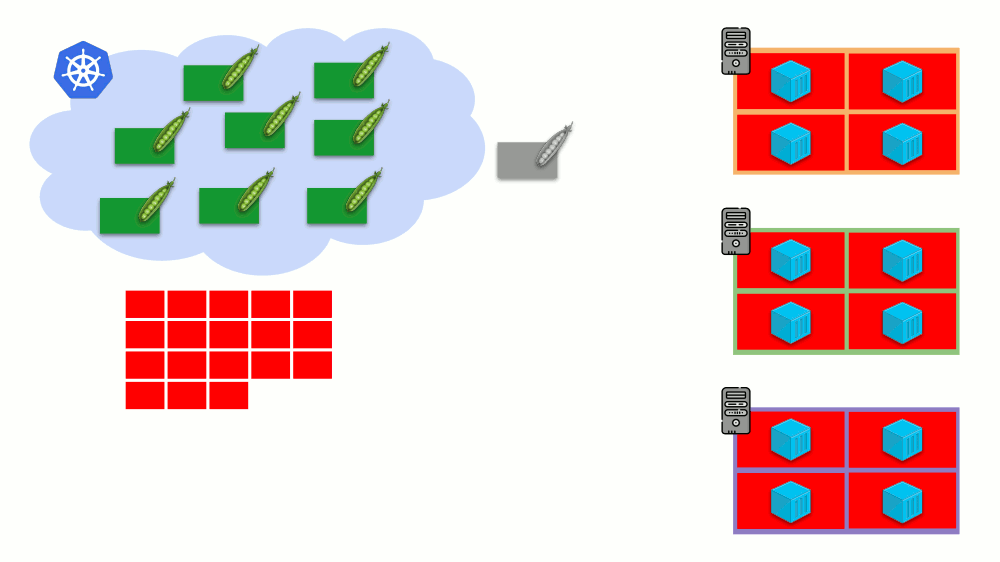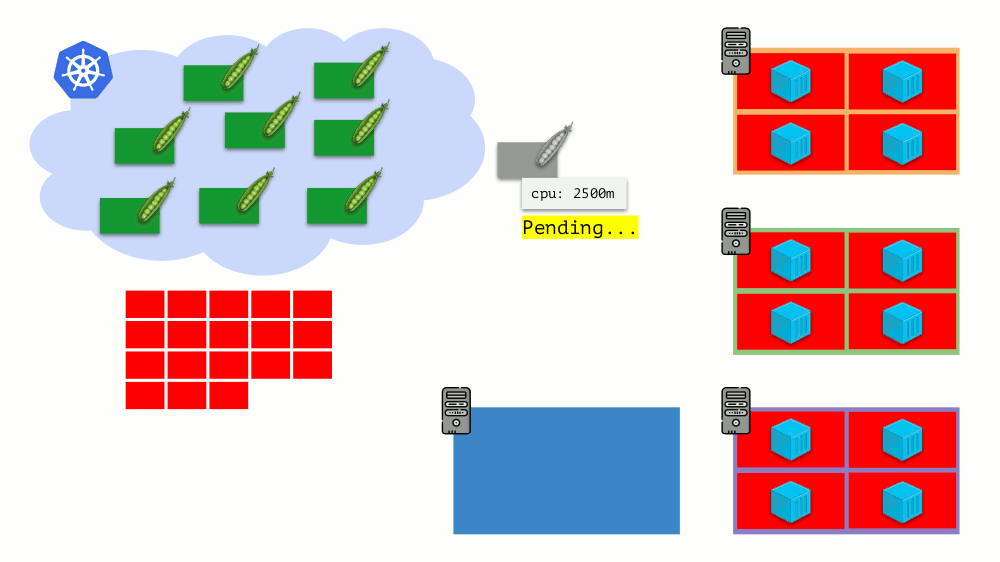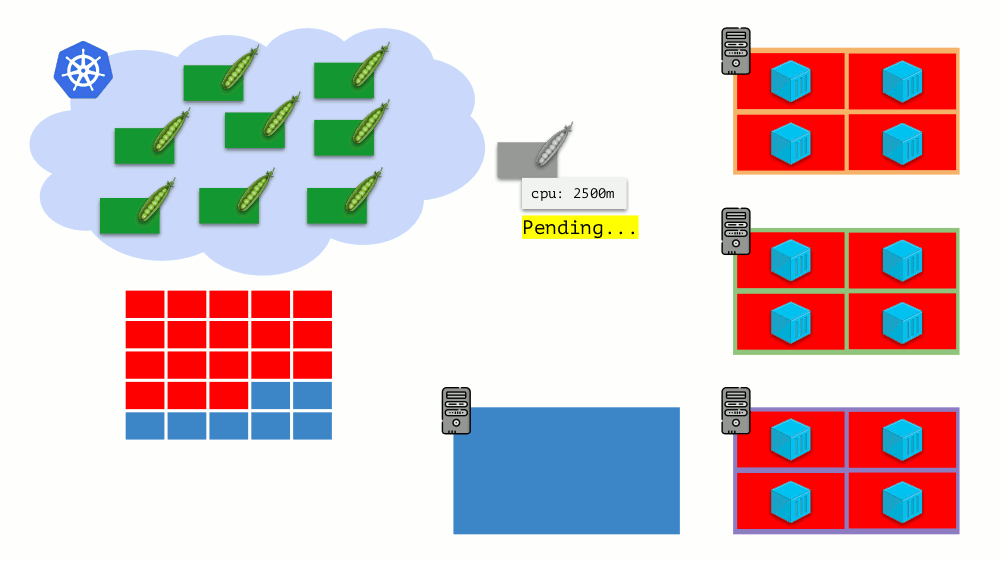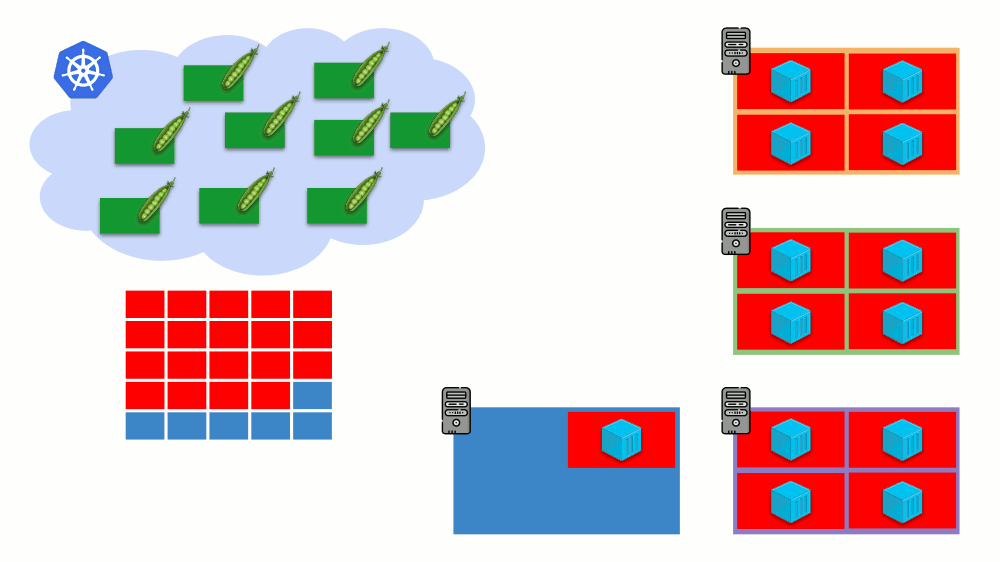
这是Kubernetes集群的自动扩展,效果很好(根据我们的经验)。 但是,和其他地方一样,这里有些细微差别...
在增加群集大小的同时,一切都很好,但是当群集
开始释放时会发生什么? 问题在于,将Pod(迁移到免费主机)在技术上非常困难且资源昂贵。 Kubernetes具有完全不同的方法。
考虑一个由3个服务器组成的群集,其中包含Deployment。 他有6个Pod:现在每个服务器2个。 由于某些原因,我们想关闭其中一台服务器。 为此,请使用
kubectl drain命令,该命令:
- 禁止将新的Pod发送到该服务器;
- 删除服务器上的现有容器。
由于Kubernetes监视Pod数量的维护(6),它将仅在其他节点上
重新创建它们,而不在断开连接的节点上
重新创建它们,因为已经将其标记为无法承载新Pod。 这是Kubernetes的基本机制。

但是,这里有细微差别。 在类似情况下,StatefulSet(而不是Deployment)的操作将有所不同。 现在我们已经有了一个有状态的应用程序-例如,使用MongoDB的三个Pod,其中一个存在某种问题(数据损坏或其他错误导致Pod无法正确启动)。 同样,我们决定断开一台服务器的连接。 会发生什么?
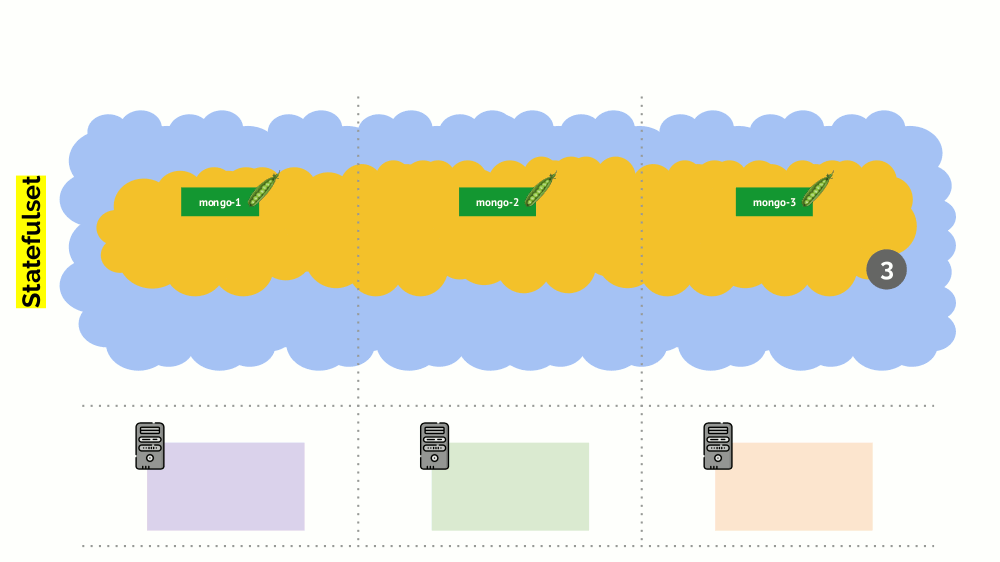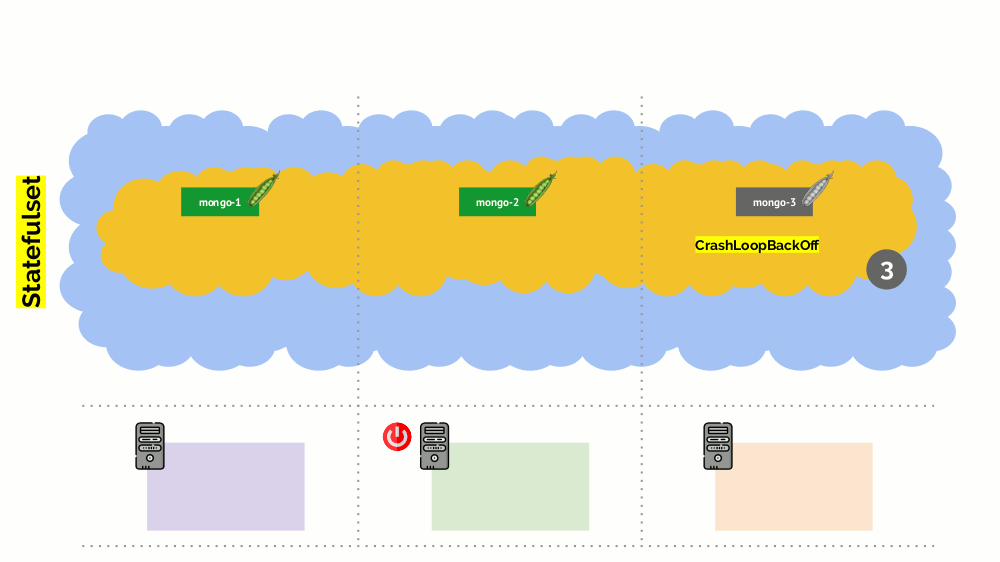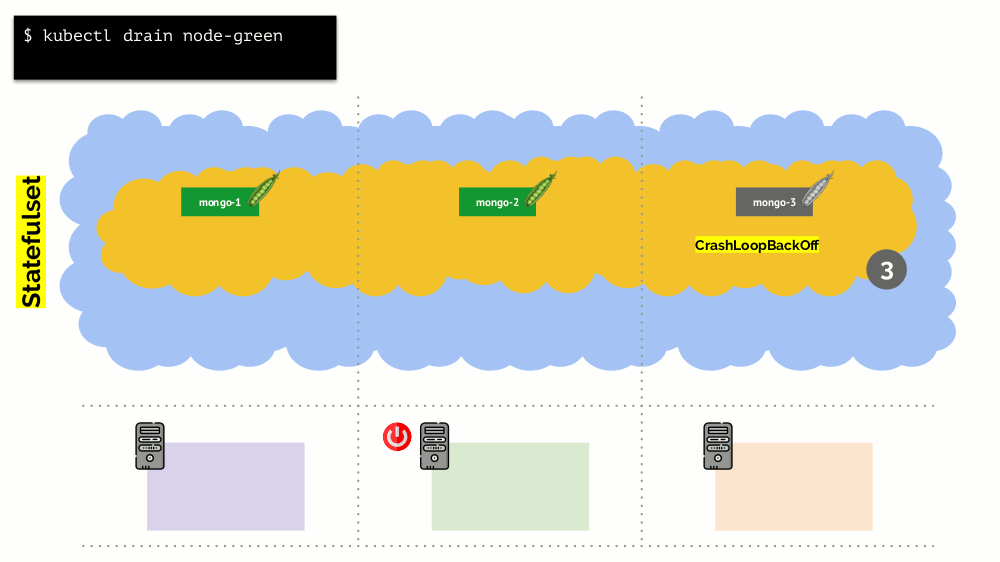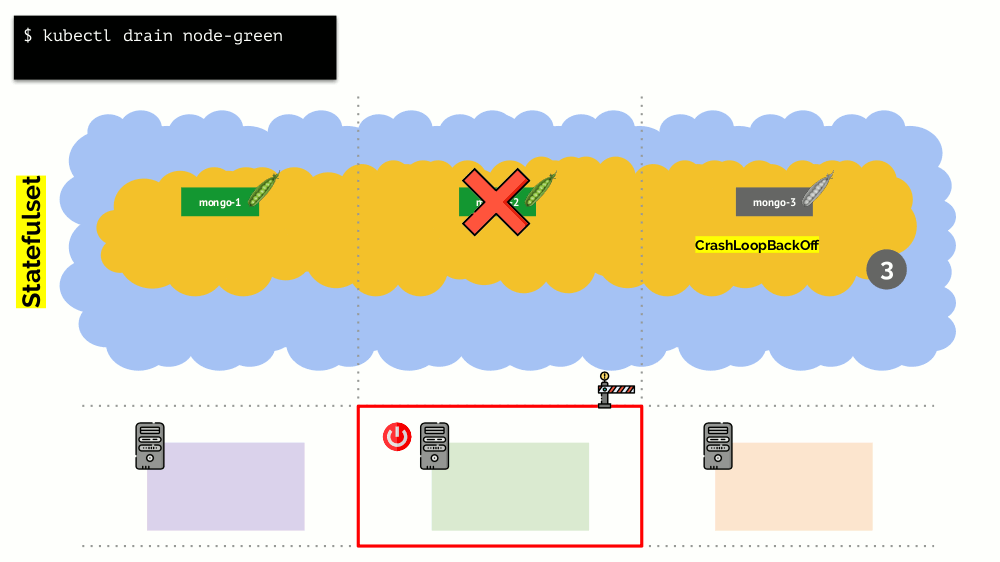
MongoDB
之所以会死是因为它需要一个仲裁:对于三个安装的集群,至少有两个必须运行。 但是,这
不会发生 -感谢
PodDisruptionBudget 。 此参数确定所需的最小工作吊舱数。 知道使用MongoDB的Pod之一不再起作用,并且知道在
minAvailable: 2为MongoDB设置了
minAvailable: 2 ,Kubernetes将不允许您删除该Pod。
底线:为了在释放群集时正确移动(并实际重新创建)吊舱,您需要配置PodDisruptionBudget。
水平缩放
考虑另一种情况。 Kubernetes中有一个作为Deployment运行的应用程序。 用户流量到达了其Pod(例如,其中有三个),我们在其中测量了一个特定指标(例如,CPU负载)。 当负载增加时,我们将其固定在时间表上,并增加用于分发请求的Pod数量。
如今,在Kubernetes中,您无需手动执行此操作:您可以根据测得的负载指示器的值自动增加/减少容器的数量。
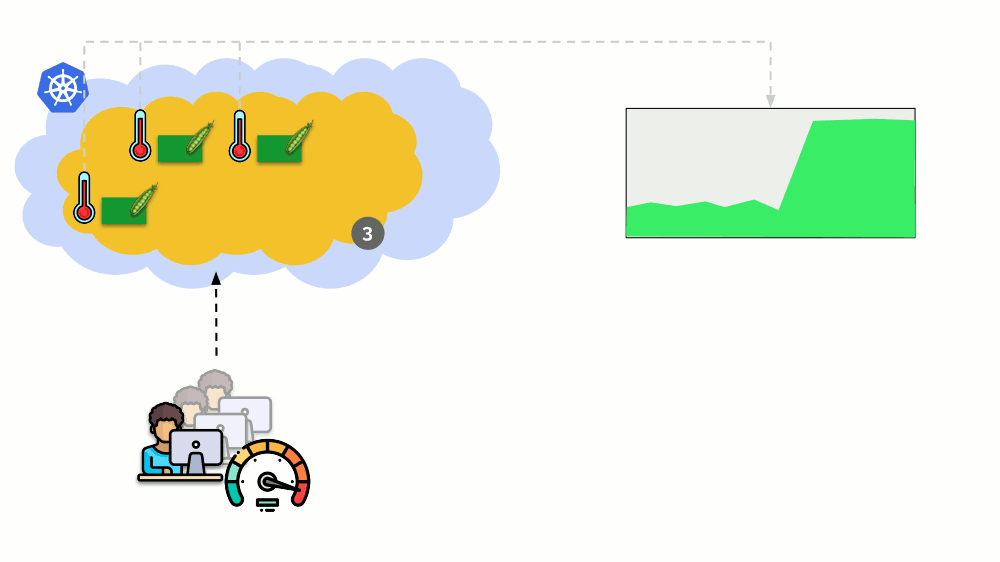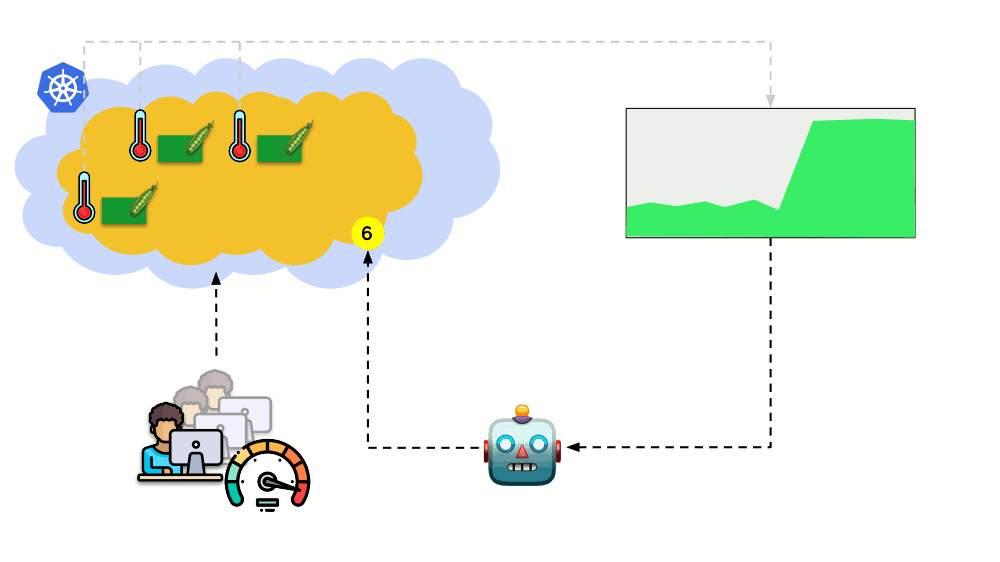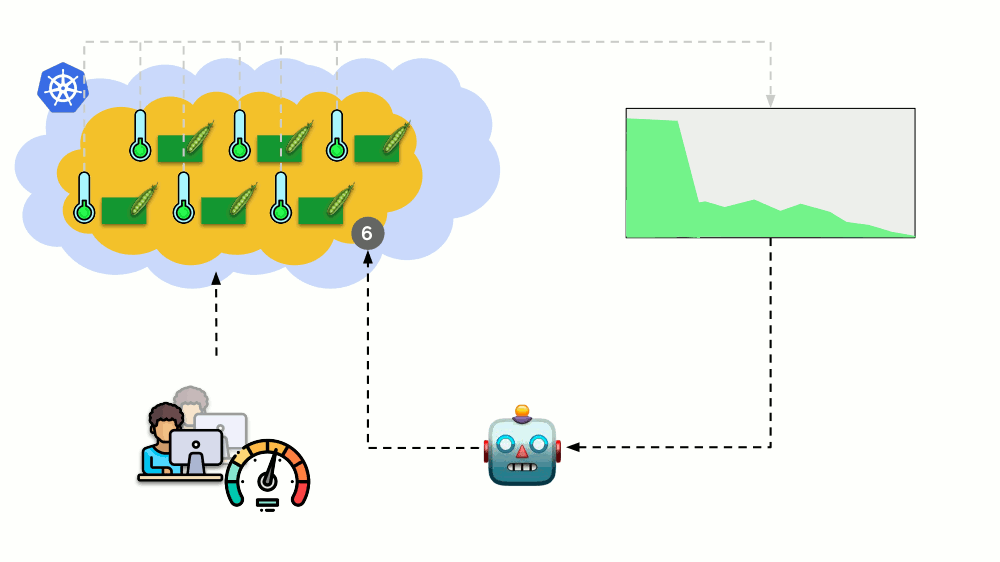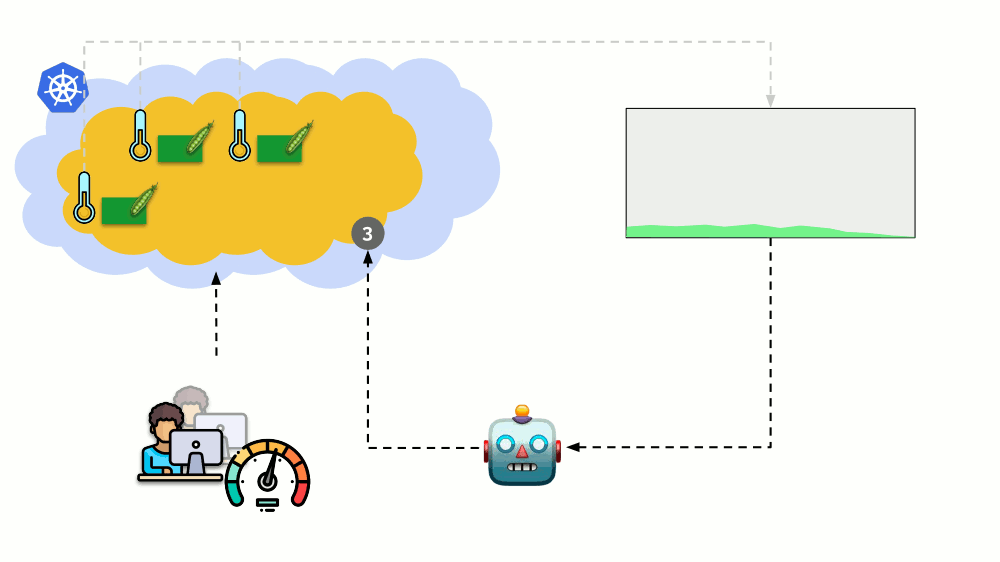
这里的主要问题是
要精确测量什么以及
如何解释所获得的值(以决定更改吊舱数量)。 您可以进行很多测量:

技术上如何做-收集指标等 -我在有关
监控和Kubernetes的报告中详细发言。 选择最佳参数的主要建议是进行
实验 !
有
一个USE (利用率饱和度和错误 )
方法 ,其含义如下。 在什么基础上进行扩展(例如php-fpm)有意义? 基于工人结束的事实,那就是
利用率 。 如果工人结束了工作并且不接受新的联系,那就
饱和了 。 这两个参数都需要测量,并且取决于这些值,应该执行缩放。
而不是结论
该报告有续篇:关于垂直扩展以及如何选择正确的资源。 我将在以后
的YouTube视频中对此进行讨论-订阅,以免错过!
影片和幻灯片
表演视频(44分钟):
报告介绍:
聚苯乙烯
我们博客上的其他Kubernetes报告: