
参赛作品
在开发ML和DL项目的多年中,我们的工作室积累了庞大的代码库,丰富的经验以及有趣的见解和结论。 在开始新项目时,这些有用的知识可帮助您更加自信地开始研究,重用有用的方法并更快地获得第一批结果。
所有这些材料不仅在开发人员的脑海中,而且在磁盘上都具有可读性,这一点非常重要。 这样可以对新员工进行更有效的培训,使他们保持最新状态并使他们沉浸在项目中。
当然,并非总是如此。 我们在初期面临很多问题
- 每个项目的组织方式都不同,特别是如果它们是由不同的人发起的。
- 他们没有跟踪代码在做什么,如何运行代码以及作者是谁。
- 他们没有适当地使用虚拟化,通常会阻止他们的同事安装不同版本的现有库。
- 从图表中得出的结论已经定下来,并死在朱庇特笔记本山上。
- 有关项目结果和进度的报告丢失。
为了一劳永逸地解决这些问题,我们决定需要对项目进行统一而适当的组织,以及虚拟化,单个组件的抽象和有用代码的重用。 逐渐地,我们在这方面的所有进展都成长为一个独立的框架-海洋。
小菜一碟-将项目日志汇总并变成一个漂亮的网站,并使用一个命令自动将其收集。
在本文中,我们将通过一个小小的人工示例来告诉您Ocean的组成部分以及如何使用它。
为什么是海洋
在ML的世界中,我们还考虑了其他选择。 首先,我们需要提及cookiecutter-data-science (以下简称CDS)作为思想上的启发者。 让我们从好的开始:CDS不仅提供了一个方便的项目结构,而且还告诉了如何管理项目以使一切都很好-因此,我们建议您偏离主题并在原始CDS文章中查看此方法的主要关键思想。
在工作草案中配备了CDS,我们立即对其进行了一些改进:我们添加了一个方便的文件记录器,一个负责导航项目的协调器类以及一个Sphinx文档的自动生成器。 此外,一些命令已提交到Makefile,因此即使是项目管理器中未初始化的命令,也可以方便地执行它们。
但是,在此过程中,CDS方法的弊端开始浮出水面:
- 数据文件夹可以增加,但是尚不清楚哪个脚本或笔记本生成下一个文件。 在大量文件中,很容易混淆。 目前尚不清楚在新功能实现的框架内是否有必要使用一些现有文件,因为出于其目的的描述或文档并未存储在任何地方。
- 在数据中,没有足够的功能子文件夹来存储符号:计算出的统计数据,向量和其他特征,将从中收集数据的不同最终表示形式。 这已经在博客文章中非常明显地写了。
- src是另一个问题文件夹。 它具有与整个项目相关的功能,例如,准备和清理src.data模块的数据。 但是,还有src.models模块,其中包含所有实验的所有模型,并且可以有数十种。 结果, src非常频繁地进行更新,并且只进行很小的更改就可以扩展,并且根据CDS的理念,每次更新之后,您都需要重新构建项目,这也是时候了……,-嗯,您知道的。
- 提供了参考文献 ,但仍然存在一个开放的问题:谁,何时以及以何种形式将材料带到那里。 在该项目的过程中,您可以说很多:已经完成了哪些工作,它们的结果是什么,未来的计划是什么。
为了解决上述问题,在Ocean中提出了以下要点: 实验 。 实验是测试某种假设所涉及的所有数据的存储库。 这可能包括:使用了什么数据,产生了什么数据(工件),代码的版本,实验的开始和结束时间,可执行文件,参数,指标和日志。 某些信息可以使用特殊工具(例如MLFlow)进行跟踪。 但是,Ocean中提出的实验结构更丰富,更灵活。
一个实验的模块如下:
<project_root> └── experiments ├── exp-001-Tree-models │ ├── config <- yaml- │ ├── models <- │ ├── notebooks <- │ ├── scripts <- , , train.py predict.py │ ├── Makefile <- │ ├── requirements.txt <- │ └── log.md <- │ ├── exp-002-Gradient-boosting ...
我们共享代码库:在整个项目中相关的可重用的良好代码仍保留在项目级别的src模块中。 它很少更新,因此您很少需要构建项目。 一个实验的脚本模块应包含仅与当前实验相关的代码。 因此,它可以经常更改:它不会影响其他实验中同事的工作。
让我们使用一个抽象的ML / DL项目示例来考虑我们框架的可能性。
项目工作流程
初始化
因此,客户-芝加哥警察-向我们上载了数据和任务:分析了2011-2017年期间在该城市犯下的罪行并得出结论。
让我们开始吧! 我们去终端执行命令:
ocean project new -n Crimes
该框架已创建相应的犯罪项目文件夹。 我们看一下它的结构:
crimes ├── crimes <- src- , ├── config <- , ├── data <- ├── demos <- ├── docs <- Sphinx- ├── experiments <- ├── notebooks <- EDA ├── Makefile <- ├── log.md <- ├── README.md └── setup.py
具有相同名称的模块中的协调器(已经编写并准备就绪)有助于浏览所有这些文件夹。 要使用它,需要对项目进行组装:
make package
这是一个错误 :如果不希望执行make命令,则在其上添加-B标志,例如“ make -B package”。 这适用于所有其他示例。
日志和实验
我们首先将客户数据(在我们的案例中为Crimes.csv文件)放置在data / raw文件夹中。
在芝加哥网站上,有一些地图,其中按城市划分为多个职位 (“节拍”-分配了一辆巡逻车的最小位置),部门(“部门”,由3-5个职位组成), 区域 (“地区”),包括3个区 ), 行政区 (“区”),最后是公共区(“社区区”)。 该数据可用于可视化。 同时,具有每种类型的多边形部分坐标的json文件不是客户发送的数据,因此我们将它们放在data / external中 。
接下来,您需要介绍实验的概念。 一切都很简单:我们将单独的任务视为单独的实验。 需要解析/抽取数据并准备以备将来使用吗? 值得进行实验。 准备大量的可视化和报告? 单独的实验。 通过准备模型来检验假设? 好吧,你明白了。
要从项目文件夹创建第一个实验,我们执行:
ocean exp new -n Parsing -a ivanov
现在,在Crimes / experiments文件夹中出现了一个名为exp-001-Parsing的新文件夹,其结构如上所示。
之后,您需要查看数据。 为此,请在相应的Notebooks文件夹中创建一台笔记本电脑 。 在Surf中,我们遵循“笔记本电脑编号-名称”的命名,创建的笔记本电脑将称为001-Parse-data.ipynb 。 在内部,我们将为进一步的工作准备数据。
数据准备码 import numpy as np import pandas as pd pd.options.display.max_columns = 100
为了使您的同事了解您所做的事情以及他们的结果是否可以被他们使用,您需要在日志中对此进行注释:文件log.md。 日志的结构(本质上是一个熟悉的markdown文件)如下:

用手填充的零件以彩色突出显示。 实验的主要内容(浅李子色)是作者及其任务的说明,以及实验的结果。 链接到过程中已获取和生成的数据(绿色),有助于监视数据文件并了解谁,在什么范围内以及为什么使用它们。 日志本身(黄色)说明工作的结果,结论和推理。 所有这些数据以后将成为项目日志站点的内容。
接下来是EDA阶段( 探索性数据分析-“智能数据分析” )。 也许它将由不同的人来进行,当然,稍后我们将需要报告和图形形式的结果。 这些论据是创建新实验的机会。 我们执行:
ocean exp new -n Eda -a ivanov
在实验的笔记本文件夹中,创建笔记本001-EDA.ipynb 。 完整的代码没有意义,但是例如您的同事就不需要。 但是,您需要图表和结论。 笔记本中产生了很多代码,它本身并不是想要显示给客户的。 因此,我们将在log.md文件中记录我们的发现和见解,并将图形的图片保存在reference中 。
例如,如果命运将您带到那里,那么这里是芝加哥安全区域的地图:
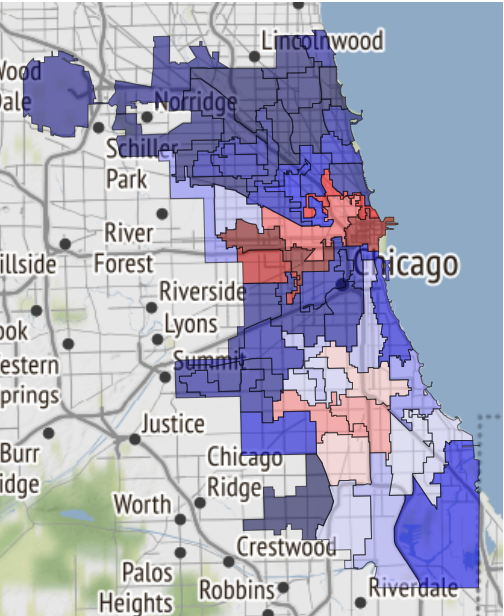
它刚被接收在笔记本中并转移到参考文献中 。
以下条目已添加到日志中:
19.02.2019, 18:15 EDA conclusion: * The most common and widely spread crimes are theft (including burglary), battery and criminal damage done with firearms. * In 1 case out of 4 the suspect will be set free after detention. [!Criminal activity in different beats of the city](references/beats_activity.jpg) Actual exploration you can check in [the notebook](notebooks/001-Eda.ipynb)
请注意:图表的设计就像将图像插入md文件一样。 并且,如果您留下指向笔记本的链接,它将被转换为html格式并保存为网站上的单独页面。
为了从实验日志中收集它,我们在项目级别执行以下命令:
ocean log new
此后,将创建文件夹Crime / project_log ,其中的index.html是项目日志。
这是一个错误 :在Jupyter中显示该网站时,它被作为iframe实施以提高安全性,因此字体无法正确显示。 因此,使用Ocean,您可以立即使用该站点的副本进行存档,以便于下载并在本地计算机上打开它或通过邮件发送它。 像这样:
ocean log archive [-n NAME] [-p PASSWORD]
该文件
让我们看一下使用Sphinx构建文档。 在文件Crimes / my_cool_module.py中创建一个函数并将其记录下来。 请注意,Sphinx使用重组文本格式(RST):
my_cool_module.py def my_super_cool_random(max_value): ''' Returns a random number from [0; max_value) interval. Considers the number to be taken from uniform distribution. :param max_value: Maximum value that defines range. :returns: Random number. ''' return 4
然后一切都非常简单:在项目级别,我们执行了文档生成团队,您已经准备就绪:
ocean docs new
观众的问题 :为什么,如果我们通过make收集项目,您是否必须从ocean收集文档?
答 :文档生成过程不仅是Sphinx命令的执行,还可以将其放置在make 。 Ocean接管了扫描源代码目录的工作,并从中为Sphinx建立了索引,然后Sphinx本身开始工作。
现成的html文档正等着您沿着Crimes / docs / _build / html / index.html前进 。 并且带有注释的模块已经出现在这里:

型号
下一步是建立模型。 我们执行:
ocean exp new -n Model -a ivanov
这次,请看一下实验内部scripts文件夹中的内容。 train.py文件对于将来的培训过程是空白的。 该文件已包含可同时执行多项操作的样板代码。
- 学习功能采用几种文件路径:
- 在配置文件中,可以合理地将模型参数,训练参数和其他易于从外部进行控制的选项传输到配置文件中,而无需深入研究代码。
- 到数据文件。
- 您要在其中保存最终模型转储的目录的路径。
- 在mlflow中跟踪学习过程中获得的指标。 通过在实验文件夹中运行makedashboard命令,可以通过UI mlflow查看提示的所有内容。
- 向您的电报发送警报,通知您学习过程已完成。 为了实现此机制,使用了Alarmerbot bot。 要使此工作有效,您需要做很多事情:将/ start命令发送给bot,然后将bot发出的令牌转移到Crimes /config/alarm_config.yml文件中 。 该字符串可能如下所示:
ivanov: a5081d-1b6de6-5f2762 - 它是从控制台控制的。
为什么要从控制台管理脚本? 一切都井井有条,因此不熟悉实验实现细节的第三方开发人员可以轻松组织学习或获取任何模型的预测的过程。 为了使拼图的所有部分都组装在一起,在设计train.py之后,您需要安排Makefile 。 它包含一个训练命令空白,您只需要正确设置上面列出的所需配置文件的路径,并在username参数值中列出所有想要接收电报警报的人。 特别是,别名all起作用,它将向所有团队成员发送警报。
一旦一切准备就绪,我们的实验就从make train ,简单而优雅。
如果您想使用其他人的神经网络,虚拟环境( venv )将有所帮助。 在实验中创建和删除它们非常容易:
ocean env new将创造一个新的环境。 它不仅在默认情况下处于活动状态,而且还为笔记本电脑和进一步研究创建了一个附加内核(内核)。 它将以与实验名称相同的方式调用。ocean env list显示核心列表。ocean env delete将ocean env delete实验中创建ocean env delete环境。
缺少什么?
- Ocean不是conda的朋友(
因为我们不使用它 ) - 专案范本只有英文。
- 本地化问题仍然适用于该站点:项目日志的构建假定所有日志均为英文。
结论
该项目的源代码在这里 。
如果您有兴趣-太好了! 您可以在Ocean存储库中的自述文件中找到更多信息。
正如他们通常在这种情况下所说的那样,欢迎捐款,只有您参与改进项目,我们才会感到高兴。