使用数据库的主要问题与运行数据库的操作系统设备的功能有关。 Linux现在是数据库的主要操作系统。 Solaris,Microsoft甚至HPUX仍在企业中使用,但即使结合使用,它们也永远不会占据第一位。 由于越来越多的开放源代码数据库,Linux无疑正在获得发展。 因此,与操作系统的数据库交互问题显然与Linux数据库有关。 这叠加在永恒的数据库问题-IO性能上。 近年来,Linux经历了IO堆栈的重大改革,这是个好消息,并且有启发的希望。
Ilya Kosmodemyansky(
hydrobiont )在Data Egret工作,Data Egret是一家
咨询和支持PostgreSQL的公司,并且对OS和数据库之间的交互非常了解。 在有关HighLoad ++的报告中,Ilya使用PostgreSQL示例讨论了IO和数据库的交互,还展示了其他数据库如何与IO一起使用。 我研究了Linux IO堆栈,其中出现了哪些新的好东西,以及为什么一切都不像几年前那样。 提醒您-PostgreSQL和Linux设置的清单,以使新内核中的IO子系统发挥最大性能。
该报告视频包含很多英语,我们在本文中翻译了其中的大多数。为什么要谈论IO?
对于数据库管理员来说,快速I / O是最关键的事情 。 每个人都知道在使用CPU时可以进行哪些更改,可以扩展内存,但是I / O可以破坏所有内容。 如果磁盘损坏,而I / O过多,则数据库会抱怨。 IO将成为瓶颈。
为了使一切正常运行,您需要配置所有内容。
不仅是数据库,还是只有硬件-就是这样。 甚至高级Oracle(在某些地方本身就是操作系统)也需要进行配置。 我们从Oracle阅读了“安装指南”中的说明:更改此类内核参数,更改其他内核参数-有许多设置。 除了在Unbreakable Kernel中,默认情况下,许多已经连接到Oracle Linux。
对于PostgreSQL和MySQL,甚至需要更多更改。 这是因为这些技术依赖于OS机制。 与PostgreSQL,MySQL或现代NoSQL一起使用的DBA必须是Linux操作工程师,并且会扭曲各种OS螺母。
每个想要处理内核设置的人都转向
LWN 。 该资源精巧,简约,包含许多有用的信息,但
由内核开发人员为内核开发人员编写 。 内核开发人员写得怎样? 核心而不是文章,如何使用它。 因此,我将尝试为开发人员向您解释所有内容,并让他们编写内核。
事实上,Linux内核的开发和堆栈处理的发展一直滞后,因此一切都变得很复杂,而近年来它们发展很快。 铁和背后没有文章的开发商都跟不上潮流。
典型数据库
让我们从PostgreSQL的示例开始-这里是缓冲的I / O。 从操作系统的角度来看,它具有共享内存,该共享内存在
用户空间中分配,并且在
内核空间的内核缓存中具有相同的缓存。
 现代数据库的主要任务是
现代数据库的主要任务是 :
- 从内存中的磁盘中提取页面;
- 发生更改时,将页面标记为脏页;
- 写入预写日志;
- 然后同步内存,使其与磁盘一致。
在PostgreSQL情况下,这是一个持续的往返过程:从PostgreSQL在Page Cache内核中控制的共享内存,再到整个Linux堆栈的磁盘。 如果您在文件系统上使用数据库,则该数据库将在任何类似UNIX的系统和任何数据库上均适用于该算法。 差异虽小,但微不足道。
使用Oracle ASM会有所不同-Oracle本身与磁盘进行交互。 但是原理是相同的:使用Direct IO或使用页面缓存,但是任务是
尽可能快地绘制整个I / O堆栈中的页面 。 在每个阶段都会出现问题。
IO的两个问题
虽然所有内容都是
只读的 ,但是没有问题。 它们读取,并且如果有足够的内存,则需要读取的所有数据都放在RAM中。 对于PostgreSQL在
Buffer Cache中的情况是相同的,我们并不十分担心。
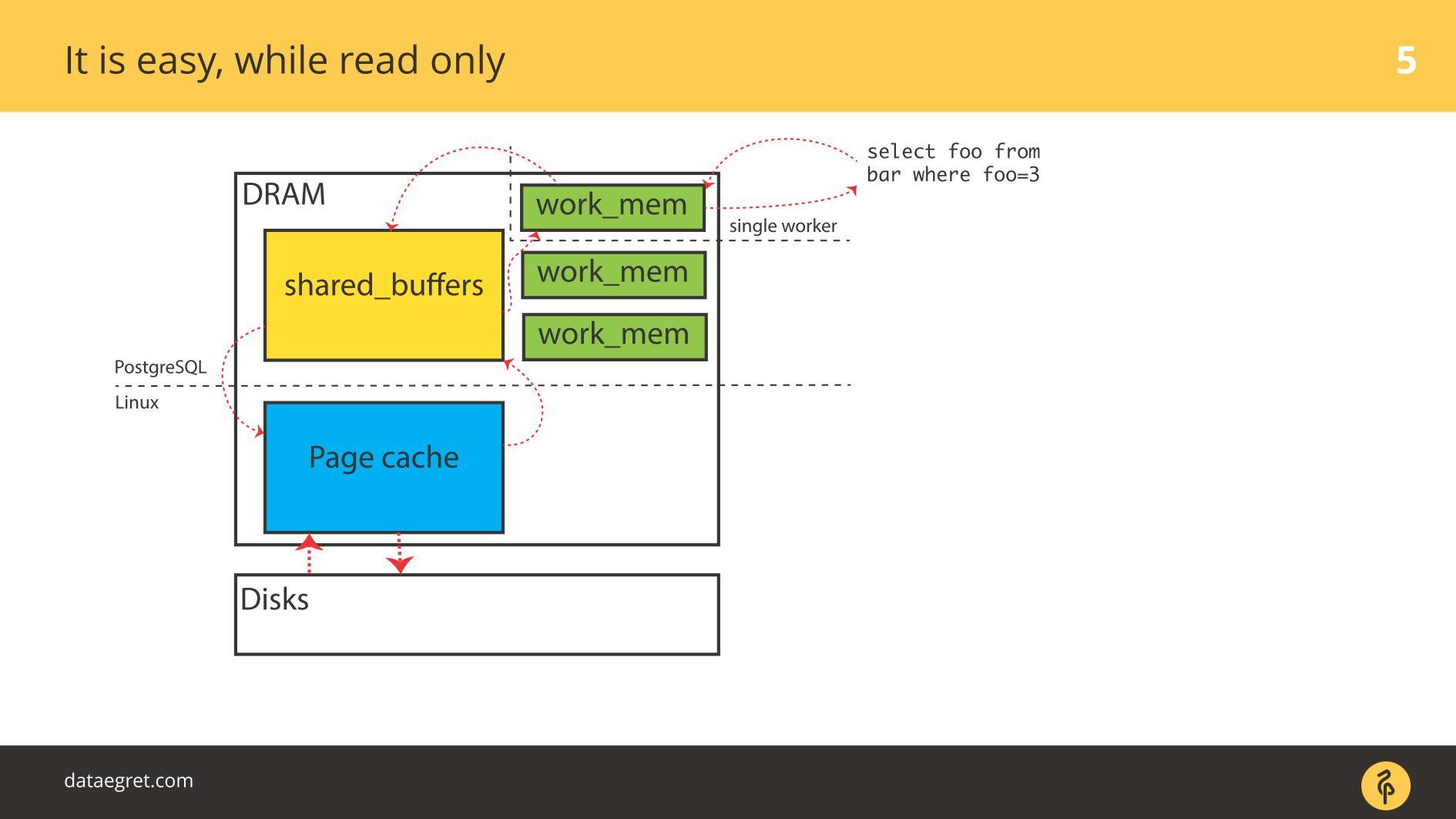 IO的第一个问题是缓存同步。
IO的第一个问题是缓存同步。 在需要记录时发生。 在这种情况下,您将不得不来回驱动更多的内存。
因此,您需要配置PostgreSQL或MySQL,以便它们全部从共享内存进入磁盘。 对于PostgreSQL-您仍然需要微调Linux中脏页的后台作弊,以将所有内容发送到磁盘。
第二个常见问题是“预写日志写入失败” 。 当负载如此强大以至于即使顺序记录的日志也停留在磁盘上时,就会出现该消息。 在这种情况下,还需要快速记录。
这种情况与
缓存同步没有太大区别。 在PostgreSQL中,我们使用大量共享缓冲区,数据库具有有效的预写日志记录机制,并且已对其进行了优化。 要使日志本身更有效,唯一可以做的就是更改Linux设置。
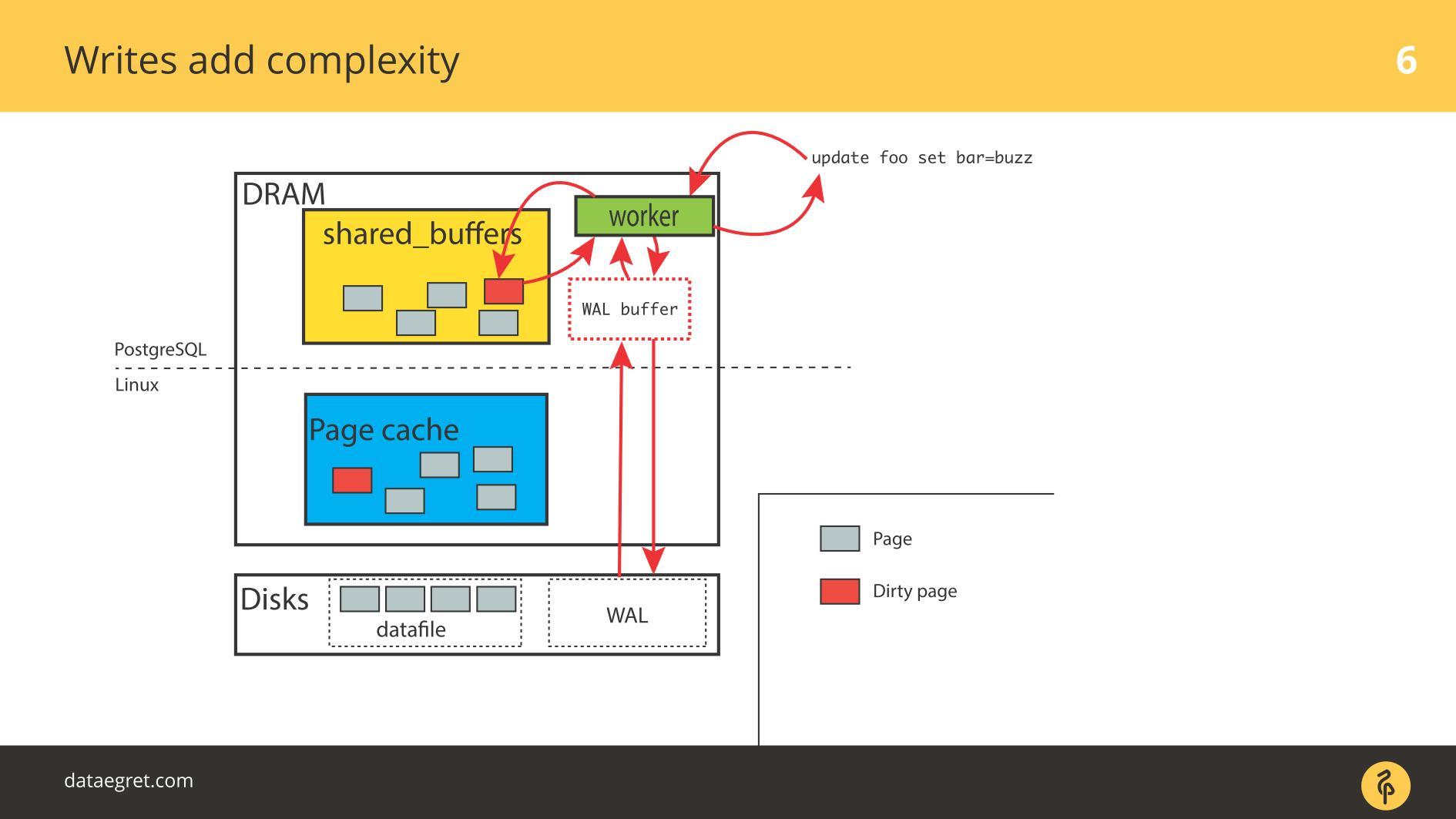
使用数据库的主要问题
共享内存段可能非常大 。 我在2012年的会议上开始谈论这一点。 然后我说,即使有32 GB RAM的服务器,内存的价格也下降了。 在2019年,笔记本电脑可能已经越来越多,服务器128、256等服务器上的频率越来越高。
真的很多记忆 。 常规录制需要时间和资源,而
我们用于此的
技术是保守的 。 数据库很旧,它们已经开发了很长时间,并且正在缓慢发展。 数据库中的机制与最新技术并不完全正确。
将内存中的页面与磁盘同步会导致大量的IO操作 。 当我们同步缓存时,会产生大量的IO,并且会出现另一个问题-
我们无法扭曲某些事物并查看其效果。 在科学实验中,研究人员更改一个参数-获得效果,第二个-获得效果,第三个。 我们不会成功。 我们在PostgreSQL中扭曲了一些参数,配置了检查点-我们没有看到效果。 然后再次配置整个堆栈,以便至少捕获一些结果。 扭转一个参数不起作用-我们被迫一次配置所有东西。
大多数PostgreSQL IO都会生成页面同步:检查点和其他同步机制。 如果您使用PostgreSQL,则可能会在图表上定期出现“锯”时看到检查点峰值。 以前,许多人都遇到过这个问题,但是现在有如何解决它的手册,它变得更加容易。
如今,SSD大大节省了情况。 在PostgreSQL中,很少有东西直接放在值记录上。 一切都取决于同步:当出现检查点时,将调用fsync,并且在另一检查点上存在一种“命中”的情况。 IO过多。 一个检查点尚未结束,尚未完成所有fsync,但是已经获得了另一个检查点,它就开始了!
PostgreSQL有一个独特的功能
-autovacuum 。 这是数据库体系cru脚的悠久历史。 如果自动抽真空失败,他们通常会对其进行设置,以使其主动运行,并且不会干扰其余部分:自动抽真空工作人员很多,经常跳闸一点,迅速处理表格。 否则,DDL和锁将存在问题。
但是,当Autovacuum积极进取时,它就开始咀嚼IO。
如果将自动真空叠加在检查点上,则大多数情况下磁盘的回收率接近100%,这就是问题的根源。
奇怪的是,存在
缓存重新填充问题。 通常,她以DBA闻名。 一个典型的例子是:数据库启动了,一段时间后,一切都缓慢地变慢了。 因此,即使您有很多RAM,也要购买优质的磁盘,以使堆栈预热缓存。
所有这些都会严重影响性能。 问题不是在重新启动数据库后立即开始,而是在以后开始。 例如,通过了检查点,并且整个数据库中很多页面都是脏的。 它们将被复制到磁盘,因为您需要对其进行同步。 然后,请求从磁盘中请求页面的新版本,并且数据库下降。 这些图将显示每个检查点之后的缓存重新填充如何对负载做出一定的百分比。
数据库输入/输出中最不愉快的是
工作人员IO。 当您请求的每个工作程序开始生成其IO。 在Oracle中,使用它比较容易,但是在PostgreSQL中,这是一个问题。
Worker IO出现问题的原因有很多:缓存不足,无法从磁盘“发布”新页面。 例如,碰巧所有缓冲区都是共享的,它们都是脏的,检查点还没有。 为了使工作人员执行最简单的选择,您需要从某个地方获取缓存。 为此,您首先需要将其全部保存到磁盘。 您没有专门的检查指针过程,并且工作程序启动fsync释放并用新的东西填充它。
这就提出了一个更大的问题:工人是非专业人士,整个过程根本没有优化。 可以在Linux级别的某个地方进行优化,但是在PostgreSQL中这是紧急措施。
数据库的主要IO问题
设置东西时我们要解决什么问题? 我们希望最大化脏页在磁盘和内存之间的传输。
但是经常会发生这些事情不会直接接触磁盘的情况。 一个典型的案例-您看到非常大的平均负载。 为什么这样 因为有人在等待磁盘,而所有其他进程也在等待。 似乎没有明确利用光盘的光盘,只是有东西阻塞了光盘,问题仍然出在输入/输出上。
数据库I / O问题并不总是只与磁盘有关。
此问题涉及所有方面:磁盘,内存,CPU,IO调度程序,文件系统和数据库设置。 现在,让我们浏览一下堆栈,看看如何处理堆栈,以及Linux中发明了哪些好东西,以便使一切工作得更好。
磁碟
多年来,磁盘非常慢,并且没有人参与延迟或过渡阶段的优化。 优化fsync没有意义。 光盘在旋转,磁头像留声机唱片一样在移动,而fsyncs是如此之久,以至于问题没有出现。
记忆
在不调整数据库的情况下查看热门查询是没有用的。 您将配置足够数量的共享内存等,并且将有一个新的顶级查询-您将不得不再次配置它。 这是同一个故事。 整个Linux堆栈就是根据此计算得出的。
带宽和延迟
通过最大化吞吐量来最大化IO性能很容易。 在PostgreSQL中发明了一个辅助PageWriter进程来卸载检查点。 工作已经变得并行,但是仍然需要为增加并行性做基础。 最大限度地减少延迟是最后一英里的任务,为此需要超级技术。
这些超级技术是SSD。 当它们出现时,等待时间急剧下降。 但是在堆栈的所有其他阶段,都出现了问题:无论是数据库制造商还是Linux制造商。 需要解决的问题。
数据库开发的重点是最大化吞吐量,Linux内核开发也是如此。 用于优化旋转磁盘的I / O时代的许多方法对于SSD来说并不是很好。
在这之间,我们被迫备份当前的Linux基础架构,但要使用新磁盘。 我们观看了来自制造商的性能测试,其中包含大量不同的IOPS,但数据库并没有得到任何改善,因为数据库不仅与IOPS有关,而且与IOPS无关。 我们经常会每秒跳过50,000 IOPS,这很好。 但是,如果我们不知道延迟,也不知道延迟的分布,那么我们就无法谈及性能。 在某个时候,数据库将开始检查点,并且延迟将大大增加。
与现在一样,很长一段时间以来,这一直是virtuala数据库上的一个大性能问题。 虚拟IO的特点是等待时间不均匀,这当然也会带来问题。
IO堆栈。 和以前一样
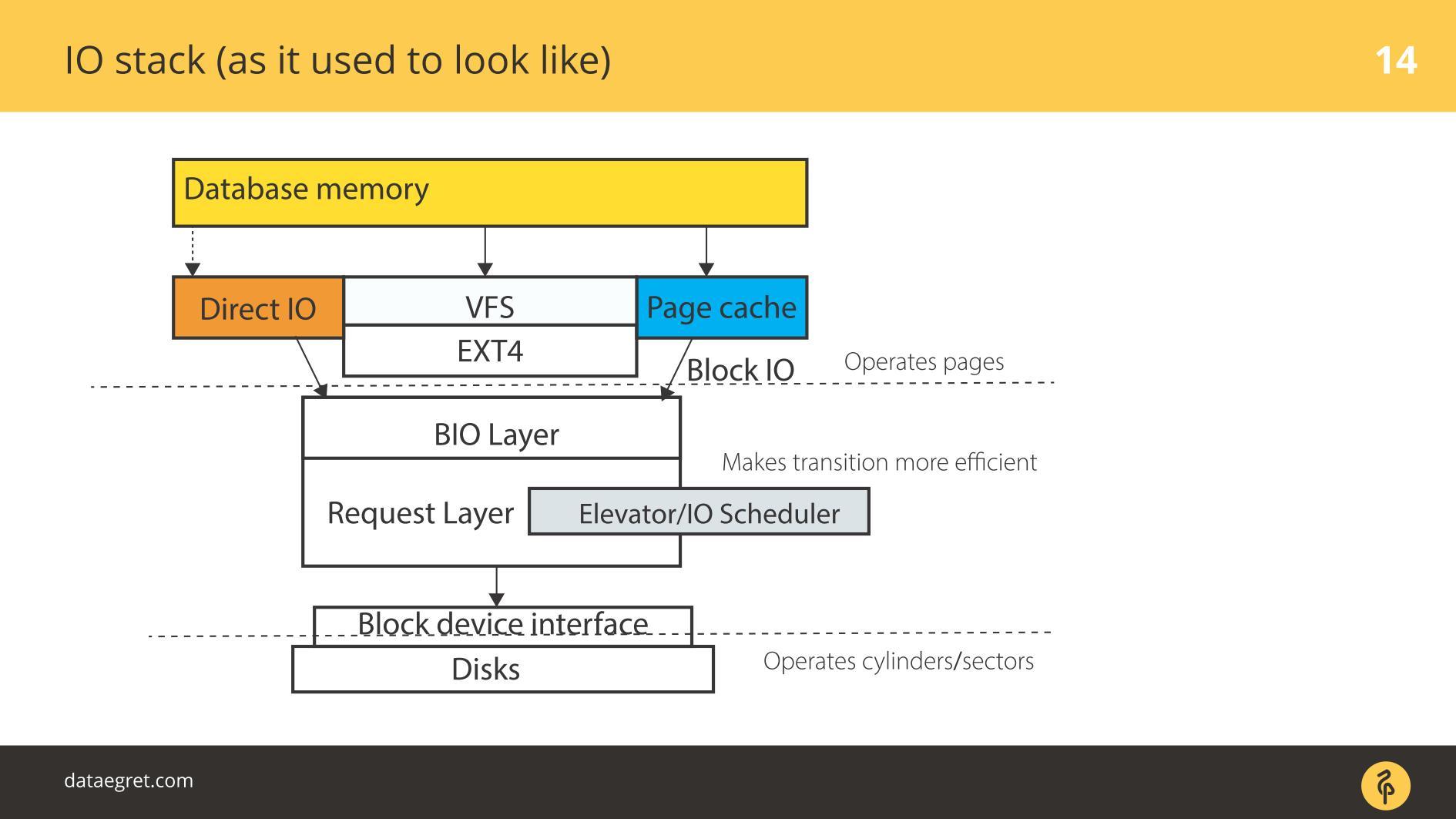
有用户空间-该内存由数据库本身管理。 在经过配置的数据库中,以便一切正常进行。 这可以在单独的报告中完成,甚至可以不做。 然后,一切都会不可避免地通过页面缓存或直接IO接口进入
块输入/输出层 。
想象一下文件系统接口。 缓冲区高速缓存中的页面(最初是数据库中的页面)(即块)会通过数据库释放。 块IO层处理以下内容。 有一个C结构描述内核中的一个块。 该结构获取这些块,并从中收集输入或输出请求的向量(数组)。 BIO层下面是请求者层。 向量收集在这一层上,并且将进一步发展。
长期以来,Linux中的这两层都经过了改进,可以有效地在磁盘上进行记录。 没有过渡就不可能做到。 有一些可以从数据库方便管理的块。 有必要将这些块组合成可方便地写入磁盘的向量,以便它们位于附近的某个位置。 为使此有效地工作,他们提出了“电梯”或“计划程序IO”。
电梯
电梯主要参与矢量的组合和排序。 所有这些都是为了使块SD驱动程序(准磁盘驱动程序)使记录块按对他方便的顺序到达。 驱动程序从块转换为扇区,然后写入磁盘。
问题在于有必要进行多次转换,并且每个转换都要实现自己的最佳过程逻辑。
电梯:内核2.6以下
在内核2.6之前,有Linus Elevator-最原始的IO Scheduler,由您猜猜谁写。 长期以来,他一直被认为绝对不可动摇且善良,直到他们开发出新的东西。
Linus电梯有很多问题。
他 根据如何更有效地记录 进行合并和分类 。 在旋转机械磁盘的情况下,这导致出现“
饥饿”现象 :记录效率取决于磁盘的旋转。 如果突然需要同时有效地读取,但是已经被错误地读取,则很难从这样的磁盘读取数据。
渐渐地,很明显,这是一种低效的方式。 因此,从内核2.6开始,一个完整的调度程序动物园开始出现,该调度程序用于不同的任务。
电梯:2.6至3
许多人将这些调度程序与操作系统调度程序混淆,因为它们的名称相似。
CFQ-完全公平排队与OS调度程序不同。 只是名称相似。 它被称为通用调度程序。
什么是通用调度程序? 您认为您有一个平均负载还是相反的负载? 数据库的通用性很差。 通用负载可以想象成一台普通笔记本电脑。 一切都在那里发生:我们听音乐,玩耍,输入文字。 为此,只编写了通用调度程序。
通用调度程序的主要任务:在Linux中,为每个虚拟终端和进程创建一个请求队列。 当我们想在音频播放器中听音乐时,播放器的IO需要排队。 如果我们要使用cp命令备份某些内容,则涉及其他内容。
如果是数据库,则会出现问题。 通常,数据库是一个启动的进程,在操作过程中出现了并行进程,该进程始终以相同的I / O队列结尾。 原因是这是相同的应用程序,相同的父进程。 对于非常小的负载,这样的调度是合适的,而对于其他负载则没有意义。 如果可能的话,更容易关闭并且不使用它。
逐渐出现了
截止时间调度程序 -它更狡猾,但基本上它是对旋转磁盘进行合并和排序。 给定特定磁盘子系统的设计,我们收集块向量以最佳方式写入它们。 他因
饥饿而遇到的问题较少,但在那里。
因此,接近第三个Linux内核出现
noop或
none ,这与SSD的传播要好得多。 包括调度程序无操作,我们实际上禁用了调度:没有排序,合并以及CFQ和截止日期所做的类似操作。
这对SSD更好,因为SSD本质上是并行的:它具有存储单元。 在一块PCIe板上装载的这些元素越多,它的工作效率就越高。
从SSD的角度来看,Scheduler从其超凡脱俗的角度考虑,收集了一些向量并将其发送到某个地方。 一切都以漏斗结束。 因此,我们会杀死SSD的并发性,请不要完全使用它们。 因此,当向量不经过任何排序而随机进行时,简单的关闭在性能方面会更好。 因此,可以认为在SSD上随机读取,随机写入效果更好。
电梯:3.13起
从内核3.13开始,
出现了blk-mq 。 早些时候有一个原型,但是在3.13中首次出现了工作版本。
Blk-mq最初是作为调度程序,但是很难称其为调度程序-它在架构上是独立的。 这是内核中请求层的替代。 慢慢地,blk-mq的开发导致整个Linux I / O堆栈的重大改进。
想法是这样的:让我们使用SSD的本机功能为I / O进行高效的并发。 根据您可以使用多少个并行I / O流,有诚实的队列,我们可以简单地通过它们写入SSD。 每个CPU都有自己的记录队列。
目前,
blk-mq正在积极开发和工作。 没有理由不使用它。 在
blk-mq到4以上的现代内核中,增益显着-不是5-10%,而是更大。
blk-mq可能是使用SSD的最佳选择。
以当前形式,
blk-mq直接与
NVMe驱动程序Linux绑定。 不仅有Linux的驱动程序,还有Microsoft的驱动程序。 但是制作
blk-mq和NVMe驱动程序的想法正是Linux堆栈的处理,数据库从中受益匪浅。
几家公司组成的财团决定制定一项规范,即本协议。 现在,它已经处于生产版本中,可以很好地用于本地PCIe SSD。 通过光学连接的磁盘阵列的几乎所有解决方案。
blk-mq驱动程序和NVMe不仅仅是一个调度程序。 该系统旨在替换整个请求级别。
让我们深入了解它是什么。 NVMe规格很大,因此我们将不考虑所有细节,而只需要仔细研究它们。
电梯的旧方法

最简单的情况是:有一个CPU,轮到它了,我们以某种方式进入磁盘。
更高级的电梯的工作方式有所不同。 有几个CPU和几个队列。 例如,以某种方式,取决于数据库工作程序从哪个父进程中分离出来,IO在磁盘上排队。
电梯的新方法
blk-mq是一种全新的方法。 每个CPU,每个NUMA区域都依次添加其自己的输入/输出。 此外,由于驱动程序是新的,因此无论如何连接,数据都将落在磁盘上。 没有使用圆柱体,块体概念的SD驱动器。
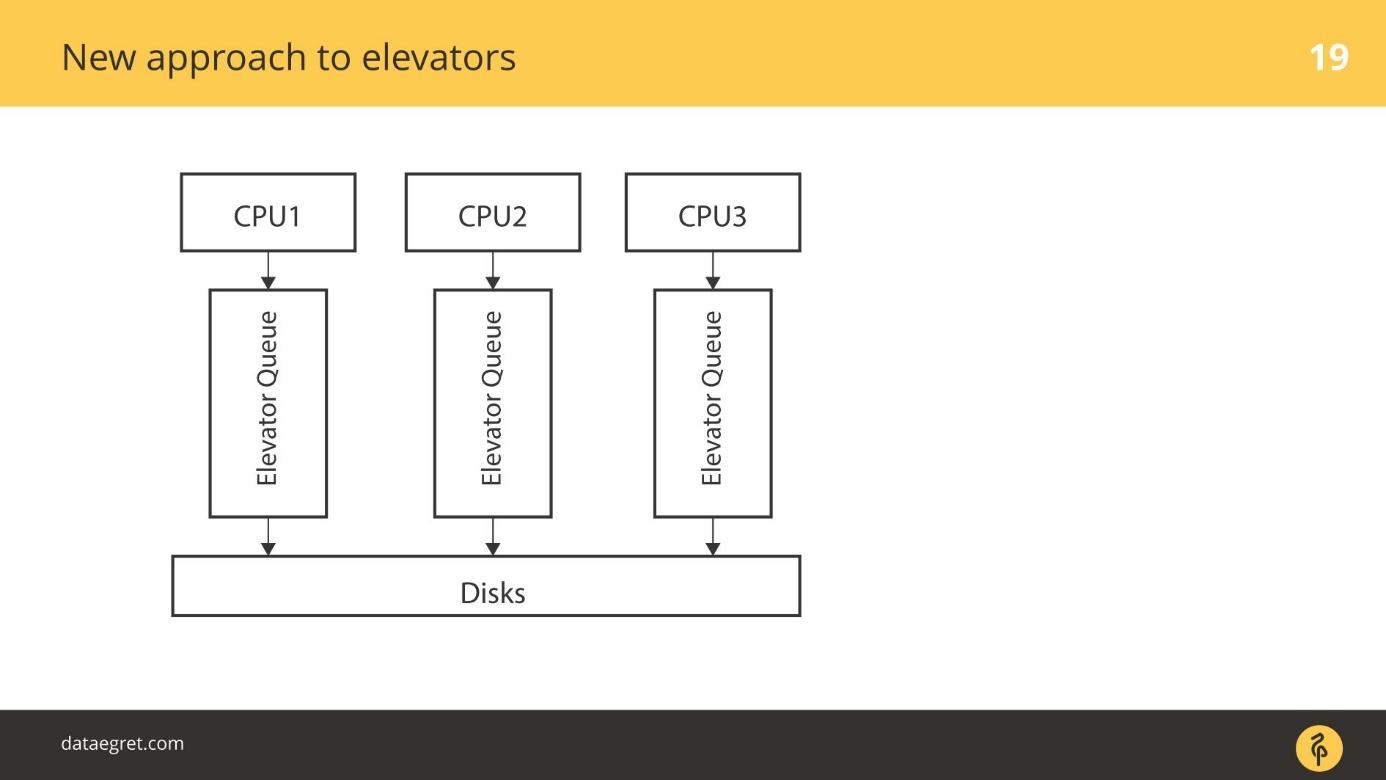
有一个过渡期。 在某个时候,所有RAID阵列供应商都开始销售附加组件,使他们可以绕过RAID缓存。 如果连接了SSD,请直接在其中写入。 他们关闭了对blq-mq等产品使用SD驱动程序的功能。
带blk-mq的新堆栈
这就是堆栈以新形式显示的样子。

从头开始,一切都还保留着。 例如,数据库远远落后。 与以前一样,来自数据库的I / O属于Block IO层。 有一个非常
blk-mq代替查询层,而不是调度程序。
在内核3.13中,整个优化大约在此结束,但是现代内核中使用了新技术。 开始出现用于
blk-mq的特殊调度程序,这些调度程序旨在增强并行性。 Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
, , , Elevators, .
, , .
NVM Express
NVM Express或NVMe是一种规范,是一组标准,可帮助您更好地使用SSD。该规范已在Linux上很好地实现。Linux是该标准的推动力之一。现在正在生产的是第三个版本。根据规范,此版本的驱动程序可以通过每个SSD块大约20 GB / s,而尚不可用的第五版本的NVMe可以高达32 GB / s。SD驱动程序内部既没有接口也没有机制来提供这种带宽。该规范比以前的任何规范都快得多。
一旦为旋转磁盘编写了数据库并将它们定向到数据库之后,这些数据库就具有例如B树形式的索引。 问题出现了:
数据库是否已准备好用于NVMe ? 数据库是否可以承受如此大的负担?
尚未,但他们正在适应。 PostgreSQL邮件列表最近有几个
pwrite()和类似的事情。 PostgreSQL和MySQL开发人员与内核开发人员进行交互。 当然,我想要更多的互动。
最新动向
在过去的一年半中,NVMe增加了
IO轮询 。
最初,转盘具有高延迟。 然后是更快的SSD。 但是有一个障碍:fsync继续进行,记录开始,并且级别很低-在驱动程序深处,一个请求被直接发送到硬件-记下来。
机制很简单-他们发送了它,我们等待直到中断被处理。 与写入旋转磁盘相比,等待中断处理不是问题。 等待时间太长,以至于录制结束后,中断便开始起作用。
由于SSD写入速度非常快,因此强制出现了一种用于轮询有关记录的硬件的机制。 在第一个版本中,由于我们不等待中断,但I / O速度的提高达到了50%,但我们正在积极地询问这一记录。
这种机制称为IO轮询 。
它是在最新版本中引入的。 在版本4.12中,出现了
IO调度程序 ,特别针对与
blk-mq和NVMe配合使用而进行了优化,我对
Kyber和BFQ进行了介绍 。 它们已经正式在内核中,可以使用。
现在以可用形式存在所谓的
IO标记 。 大多数情况下,云和虚拟机制造商将为这一发展做出贡献。 粗略地说,可以处理来自特定应用程序的输入并将其赋予优先级。 数据库尚未为此做好准备,但请继续关注。 我认为它将很快成为主流。
直接IO注释
PostgreSQL不支持Direct IO,并且有很多问题使支持变得困难 。 现在,仅在值未启用复制的情况下才支持此功能。 需要
编写许多特定于OS的代码 ,现在每个人都对此表示弃权。
尽管Linux对Direct IO及其实现方式非常拥护,但所有数据库都存在。 在Oracle和MySQL中,大量使用Direct IO。 PostgreSQL是Direct IO不容许的唯一数据库。
检查清单
如何保护自己免受PostgreSQL中的fsync意外影响:
- 将检查点设置为不频繁且较大。
- 设置背景编写器以帮助检查点。
- 拉Autovacuum,以便没有不必要的虚假I / O。
按照传统,在11月,我们正在Skolkovo上等待HighLoad ++上的高负载服务的专业开发人员。 申请报告还有一个月的时间,但是我们已经接受了该计划的第一份报告。 订阅我们的新闻通讯,并直接了解新主题。