 图 取自www.extremetech.com/wp-content/uploads/2016/07/MegaProcessor-Feature.jpg
图 取自www.extremetech.com/wp-content/uploads/2016/07/MegaProcessor-Feature.jpg大家身体健康!
在上一篇文章中,我研究了使用具有C ++的CortexM内核的微控制器的寄存器访问问题,并展示了一些问题的简单解决方案。
今天,我想展示一下如何使用从SVD文件生成的C ++类,在不牺牲效率的情况下确保安全访问寄存器及其字段。
您感兴趣的每个人都欢迎加入。 会有很多代码。
引言
在
C ++硬件寄存器访问Redux文章中,Ken Smith演示了如何安全有效地使用寄存器,甚至以
github.com/kensmith/cppmmio为例进行了
演示 。
然后,几个人提出了这个想法,例如,
尼古拉斯·豪瑟 (
Niklas Hauser)进行了精彩的评论,并提出了另外几种安全访问寄存器的方法。
其中一些思想已经在各种库中实现,尤其是在
modm中 。 永远可以在现实生活中使用所有这些句子。 但是在开发这些库时,外围设备和寄存器的描述才刚刚开始标准化,因此,为了使寄存器描述的主要工作由程序员来完成,已经做了一些事情。 同样,某些解决方案在代码和微控制器资源方面也不有效。
如今,ARM微控制器的每个制造商都以SVD格式提供了所有寄存器的描述。 头文件可以从这些描述中生成;因此,可以创建一个简单的寄存器描述,而不是一个简单的寄存器描述,但是同时创建,可以提高代码的可靠性。 而且,输出文件可以使用任何语言(C,C ++甚至是
D)都非常好但是,让我们先来了解一下什么是通常安全访问寄存器的原因,以及为什么根本没有必要。 可以通过简单的综合(最有可能的是但很可能的示例)上显示说明:
int main(void) {
所有这些情况在实践中都是可能的,我肯定从我的学生那里看到了类似的情况。 如果您可以避免犯这样的错误,那将是很好的。
在我看来,当代码看起来很整洁并且不需要注释时,它会更加令人愉悦。 例如,即使您非常了解STM32F411微控制器,也不总是可能了解这段代码中发生的事情:
int main() { uint32 temp = GPIOA->OSPEEDR ; temp &=~ GPIO_OSPEEDR_OSPEED0_Msk ; temp = (GPIO_OSPEEDR_OSPEED0_0 | GPIO_OSPEEDR_OSPEED0_1) ; GPIOA->OSPEEDR = temp; }
没有评论在这里不能做。 该代码将GPIOA.0端口的工作频率设置为最大(来自
mctMaks的澄清:实际上,此参数会影响前端的上升时间(即其陡峭度),并且意味着该端口可以正常处理给定的数字信号(VeryLow \ Low \ Medium \(高)频率)。
让我们尝试摆脱这些缺点。
注册抽象
首先,您需要从程序员和程序的角度弄清楚寄存器是什么。
寄存器具有地址,长度或大小,访问方式:某些寄存器可以写入,某些只能读取,而大多数则可以读写。
另外,寄存器可以表示为一组字段。 一个字段可以由一位或几位组成,位于寄存器的任何位置。
因此,以下字段特征对我们很重要:长度或大小(
width或
size ),距寄存器开头的
偏移量 (
offset )和值。
字段值是字段可以占用的所有可能数量的空间,它取决于字段的长度。 即 如果该字段的长度为2,则有4个可能的字段值(0,1,2,3)。 像寄存器一样,字段和字段值也具有访问模式(读,写,读和写)
为了更加清楚,让我们从STM32F411微控制器获取TIM1 CR1寄存器。 从示意图上看,它看起来像这样:
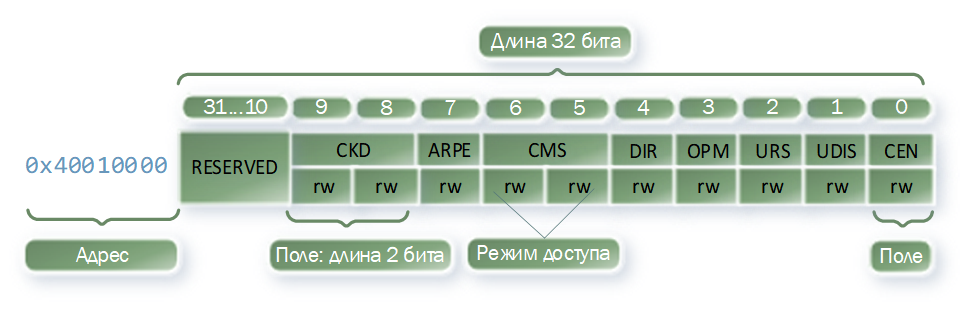
- Bit 0 CEN:启用计数器
0:计数器使能: 禁用
1:计数器关闭: 启用
- UDIS位1:启用/禁用UEV事件
0:启用UEV事件: 启用
1:UEV事件关闭: 禁用
- URS位2:选择UEV事件生成源
0:溢出或设置UG时生成UEV: 任意位
1:仅在溢出时生成UEV: 溢出
- Bit 3 OPM:一次性操作
0:在UEV: ContinueAfterUEV事件之后,计时器继续计数
1:在UEV: StopAfterUEV事件后计时器停止
- Bit 4 DIR:计数方向
0:直接帐户: 递增帐户
1: 倒数 : 倒数
- 位6:5 CMS:对齐模式
0:对齐模式0: CenterAlignedMode0
1:对齐模式1: CenterAlignedMode1
2:对齐方式2: CenterAlignedMode2
3:对齐模式3: CenterAlignedMode3
- Bit 7 APRE:ARR寄存器的预加载模式
0:TIMx_ARR寄存器未缓冲: ARRNotBuffered
1:TIMx_ARR寄存器未缓冲: ARRBuffered
- 位8:9 CKD:时钟分频器
0:tDTS = tCK_INT: ClockDevidedBy1
1:tDTS = 2 * tCK_INT: ClockDevidedBy2
2:tDTS = 4 * tCK_INT: ClockDevidedBy4
3:保留: 保留
例如,此处的CEN是一个1位字段,相对于寄存器的开头偏移为0。
启用 (1)和
禁用 (0)是其可能的值。
我们不会专注于该寄存器的每个字段专门负责什么,对于我们来说重要的是,每个字段和字段值都有一个名称,该名称带有语义负载,并且从中我们可以从原则上理解它的作用。
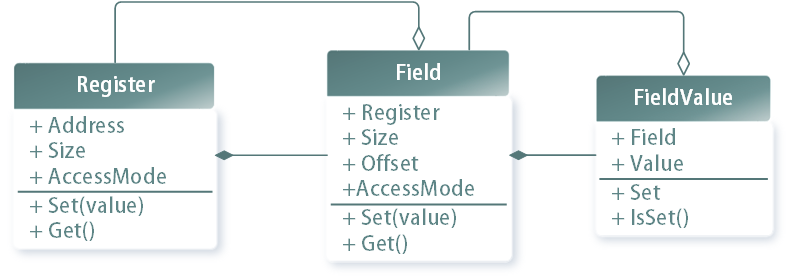
我们必须同时访问寄存器和字段及其值。 因此,以非常近似的形式,寄存器抽象可以由以下类表示:

除了类之外,对我们来说也很重要的是,寄存器和各个字段都具有某些属性,寄存器具有地址,大小,访问方式(只读,只写或两者兼有)。
该字段具有大小,偏移量以及访问模式。 另外,该字段应包含指向其所属寄存器的链接。
字段值必须具有到该字段的链接和一个附加属性-值。
因此,在更详细的版本中,我们的抽象将如下所示:

除了属性之外,我们的抽象还应该具有修改和访问方法。 为简单起见,我们只限于安装/编写和阅读方法。
当我们决定大小写抽象时,我们需要检查这种抽象如何对应于SVD文件中描述的内容。
系统视图描述(SVD)文件
CMSIS系统表示描述格式(CMSIS-SVD)是基于ARM Cortex-M处理器的微控制器寄存器的正式描述。 系统表示形式的描述中包含的信息实际上与设备参考手册中的数据相对应。 在这种文件中对寄存器的描述既可以包含高级信息,也可以包含寄存器中字段的单个位的用途。
在示意图上,可以通过以下方案(
位于Keil网站上)来描述此类文件中信息的详细程度:

说明SVD文件由制造商提供,并在调试期间用于显示有关微控制器和寄存器的信息。 例如,IAR使用它们在“视图”->“注册”面板中显示信息。 文件本身位于文件夹Program Files(x86)\ IAR Systems \ Embedded Workbench 8.3 \ arm \ config \ debugger中。
JetBrains的Clion还在调试期间使用svd文件显示寄存器信息。
您始终可以从制造商的网站下载说明。
在这里您可以获取STM32F411微控制器的SVD文件通常,SVD格式是制造商支持的标准。 让我们看看SVD中的描述级别是什么。
总共区分出5个级别:设备级别,微控制器级别,寄存器级别,字段级别,枚举值级别。
- 设备级别 :系统视图的顶级描述是设备。 在此级别上,将描述与整个设备有关的属性。 例如,设备名称,描述或版本。 最小可寻址单元以及数据总线的位深度。 可以在此级别为整个设备设置寄存器属性的默认值,例如寄存器大小,重置值和访问权限,并由较低级别的描述隐式继承。
- 微控制器级别: CPU部分描述了微控制器的内核及其功能。 如果使用SVD文件创建设备头文件,则此部分是必需的。
- 外围层 :外围设备是寄存器的命名集合。 外围设备被映射到设备地址空间中的特定基址。
- 寄存器级别 :寄存器是属于外围设备的命名可编程资源。 寄存器被映射到设备地址空间中的特定地址。 该地址是相对于基本外围设备地址的。 另外,对于寄存器,指示访问模式(读/写)。
- 字段级别 :如上所述,寄存器可以分为不同功能的位-字段。 此级别包含同一寄存器内唯一的字段名称,它们的大小,相对于寄存器开头的偏移量以及访问模式。
- 枚举字段值的级别 :实际上,它们是命名字段值,可在C,C ++,D等中使用,以方便使用。
实际上,SVD文件是带有系统完整描述的普通xml文件。 例如,
这里有svd文件转换器到C代码,可为每个外围设备和寄存器生成C友好的头文件和结构。
还有一个用Phyton编写的
cmsis-svd SVD文件解析器,它的作用类似于将文件中的数据反序列化为Phython类对象,然后可以方便地在代码生成程序中使用。
可以在扰流板下面查看STM32F411微控制器的寄存器描述示例:
寄存器CR1定时器TIM1的示例 <peripheral> <name>TIM1</name> <description>Advanced-timers</description> <groupName>TIM</groupName> <baseAddress>0x40010000</baseAddress> <addressBlock> <offset>0x0</offset> <size>0x400</size> <usage>registers</usage> </addressBlock> <registers> <register> <name>CR1</name> <displayName>CR1</displayName> <description>control register 1</description> <addressOffset>0x0</addressOffset> <size>0x20</size> <access>read-write</access> <resetValue>0x0000</resetValue> <fields> <field> <name>CKD</name> <description>Clock division</description> <bitOffset>8</bitOffset> <bitWidth>2</bitWidth> </field> <field> <name>ARPE</name> <description>Auto-reload preload enable</description> <bitOffset>7</bitOffset> <bitWidth>1</bitWidth> </field> <field> <name>CMS</name> <description>Center-aligned mode selection</description> <bitOffset>5</bitOffset> <bitWidth>2</bitWidth> </field> <field> <name>DIR</name> <description>Direction</description> <bitOffset>4</bitOffset> <bitWidth>1</bitWidth> </field> <field> <name>OPM</name> <description>One-pulse mode</description> <bitOffset>3</bitOffset> <bitWidth>1</bitWidth> </field> <field> <name>URS</name> <description>Update request source</description> <bitOffset>2</bitOffset> <bitWidth>1</bitWidth> </field> <field> <name>UDIS</name> <description>Update disable</description> <bitOffset>1</bitOffset> <bitWidth>1</bitWidth> </field> <field> <name>CEN</name> <description>Counter enable</description> <bitOffset>0</bitOffset> <bitWidth>1</bitWidth> </field> </fields> </register> <register>
如您所见,除了字段的特定位的值的描述之外,还有所有抽象所需的信息。
并非所有制造商都希望花时间对他们的系统进行完整的描述,因此,正如您所看到的,ST不想描述字段值并将此负担转移给客户程序员。 但是TI会照顾客户,并完整描述系统,包括字段值的描述。
上面显示了SVD描述的格式与我们的案例抽象非常一致。 该文件包含所有必要的信息,以完整描述寄存器。
实作
报名
现在,我们已经对寄存器进行了抽象,并且以制造商的svd形式对寄存器进行了描述,该描述非常适合这种抽象,我们可以直接进行实现。
我们的实现应与C代码一样有效且用户友好。 我希望对寄存器的访问看起来尽可能清晰,例如:
if (TIM1::CR1::CKD::DividedBy2::IsSet()) { TIM1::ARR::Set(10_ms) ; TIM1::CR1::CEN::Enable::Set() ; }
回想一下,为了访问整数寄存器地址,您需要使用reinterpret_cast:
*reinterpret_cast<volatile uint32_t *>(0x40010000) = (1U << 5U) ;
上面已经描述了寄存器类,它必须具有地址,大小和访问方式,以及两个
Get()和
Set()方法:
我们将地址,寄存器长度和访问模式传递给模板参数(这也是一个类)。 使用
SFINAE机制,即
enable_if元函数,我们将为不支持它们的寄存器“抛出”
Set()或
Get()访问函数。 例如,如果寄存器是只读的,那么我们将把
ReadMode类型
ReadMode给模板参数,
enable_if将检查access是否是
ReadMode的后继
ReadMode ,如果不是,它将创建一个受控错误(类型T无法显示),并且编译器将不包括
Set()方法。
Set()这样的寄存器。 仅用于写入的寄存器也是如此。
对于访问控制,我们将使用以下类:
寄存器的大小不同:8、16、32、64位,我们分别设置类型:
寄存器类型取决于大小 template <uint32_t size> struct RegisterType {} ; template<> struct RegisterType<8> { using Type = uint8_t ; } ; template<> struct RegisterType<16> { using Type = uint16_t ; } ; template<> struct RegisterType<32> { using Type = uint32_t ; } ; template<> struct RegisterType<64> { using Type = uint64_t ; } ;
之后,对于TIM1计时器,您可以通过以下方式定义CR1寄存器和例如EGR寄存器:
struct TIM1 { struct CR1 : public RegisterBase<0x40010000, 32, ReadWriteMode> { } struct EGR : public RegisterBase<0x40010014, 32, WriteMode> { } } int main() { TIM1::CR1::Set(10) ; auto reg = TIM1::CR1::Get() ;
由于编译器仅针对从
ReadMode继承访问模式的寄存器显示
Get()方法,而对于从
ReadMode继承访问模式的寄存器显示
Set()方法,如果错误使用访问方法,则在编译阶段会收到错误消息。 而且,如果您使用现代开发工具(例如Clion),那么即使在编码阶段,您也会在代码分析器中看到警告:

好了,现在访问寄存器变得更加安全,我们的代码不允许您执行该寄存器不可接受的操作,但是我们想走得更远,而不是引用整个寄存器,而是引用其字段。
领域
该字段而不是地址具有相对于寄存器开头的移位值。 另外,为了知道字段值必须带到的地址或类型,它必须具有指向寄存器的链接:
之后,已经可以执行以下操作:
struct TIM1 { struct CR1 : public RegisterBase<0x40010000, 32, ReadWriteMode> { using CKD = RegisterField<TIM1::CR1, 8, 2, ReadWriteMode> ; using ARPE = RegisterField<TIM1::CR1, 7, 1, ReadWriteMode> ; using CMS = RegisterField<TIM1::CR1, 5, 2, ReadWriteMode> ; using DIR = RegisterField<TIM1::CR1, 4, 1, ReadWriteMode> ; using OPM = RegisterField<TIM1::CR1, 3, 1, ReadWriteMode> ; using URS = RegisterField<TIM1::CR1, 2, 1, ReadWriteMode> ; using UDIS = RegisterField<TIM1::CR1, 1, 1, ReadWriteMode> ; using CEN = RegisterField<TIM1::CR1, 0, 1, ReadWriteMode> ; } } int main() {
尽管总体上看起来一切都不错,但仍不清楚
TIM1::CR1::CKD::Set(2)含义是什么,传递给
Set()函数的魔术二是什么意思?
TIM1::CR1::CEN::Get()方法返回的数字
TIM1::CR1::CEN::Get()什么
TIM1::CR1::CEN::Get() ?
无缝移动到字段值。
栏位值
字段值的抽象本质上也是一个字段,但是只能接受一个状态。 将属性添加到字段抽象中-实际值和到该字段的链接。 设置字段值的
Set()方法与设置字段的
Set()方法相同,不同之处在于,不需要将值本身传递给该方法,这是预先已知的,只需要对其进行设置即可。 但是
Get()方法没有任何意义;相反,最好检查是否设置了此值,用
IsSet()方法替换此方法。
现在可以通过一组值来描述register字段:
定时器TIM1的CR1寄存器字段的值 template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_CKD_Values: public RegisterField<Reg, offset, size, AccessMode> { using DividedBy1 = FieldValue<TIM_CR_CKD_Values, 0U> ; using DividedBy2 = FieldValue<TIM_CR_CKD_Values, 1U> ; using DividedBy4 = FieldValue<TIM_CR_CKD_Values, 2U> ; using Reserved = FieldValue<TIM_CR_CKD_Values, 3U> ; } ; template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_ARPE_Values: public RegisterField<Reg, offset, size, AccessMode> { using ARRNotBuffered = FieldValue<TIM_CR_ARPE_Values, 0U> ; using ARRBuffered = FieldValue<TIM_CR_ARPE_Values, 1U> ; } ; template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_CMS_Values: public RegisterField<Reg, offset, size, AccessMode> { using CenterAlignedMode0 = FieldValue<TIM_CR_CMS_Values, 0U> ; using CenterAlignedMode1 = FieldValue<TIM_CR_CMS_Values, 1U> ; using CenterAlignedMode2 = FieldValue<TIM_CR_CMS_Values, 2U> ; using CenterAlignedMode3 = FieldValue<TIM_CR_CMS_Values, 3U> ; } ; template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_DIR_Values: public RegisterField<Reg, offset, size, AccessMode> { using Upcounter = FieldValue<TIM_CR_DIR_Values, 0U> ; using Downcounter = FieldValue<TIM_CR_DIR_Values, 1U> ; } ; template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_OPM_Values: public RegisterField<Reg, offset, size, AccessMode> { using ContinueAfterUEV = FieldValue<TIM_CR_OPM_Values, 0U> ; using StopAfterUEV = FieldValue<TIM_CR_OPM_Values, 1U> ; } ; template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_URS_Values: public RegisterField<Reg, offset, size, AccessMode> { using Any = FieldValue<TIM_CR_URS_Values, 0U> ; using Overflow = FieldValue<TIM_CR_URS_Values, 1U> ; } ; template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_UDIS_Values: public RegisterField<Reg, offset, size, AccessMode> { using Enable = FieldValue<TIM_CR_UDIS_Values, 0U> ; using Disable = FieldValue<TIM_CR_UDIS_Values, 1U> ; } ; template <typename Reg, size_t offset, size_t size, typename AccessMode> struct TIM_CR_CEN_Values: public RegisterField<Reg, offset, size, AccessMode> { using Disable = FieldValue<TIM_CR_CEN_Values, 0U> ; using Enable = FieldValue<TIM_CR_CEN_Values, 1U> ; } ;
然后,CR1寄存器本身将被描述如下:
struct TIM1 { struct CR1 : public RegisterBase<0x40010000, 32, ReadWriteMode> { using CKD = TIM_CR1_CKD_Values<TIM1::CR1, 8, 2, ReadWriteMode> ; using ARPE = TIM_CR1_ARPE_Values<TIM1::CR1, 7, 1, ReadWriteMode> ; using CMS = TIM_CR1_CMS_Values<TIM1::CR1, 5, 2, ReadWriteMode> ; using DIR = TIM_CR1_DIR_Values<TIM1::CR1, 4, 1, ReadWriteMode> ; using OPM = TIM_CR1_OPM_Values<TIM1::CR1, 3, 1, ReadWriteMode> ; using URS = TIM_CR1_URS_Values<TIM1::CR1, 2, 1, ReadWriteMode> ; using UDIS = TIM_CR1_UDIS_Values<TIM1::CR1, 1, 1, ReadWriteMode> ; using CEN = TIM_CR1_CEN_Values<TIM1::CR1, 0, 1, ReadWriteMode> ; } ; }
现在,您可以设置并直接读取寄存器字段的值:例如,如果要在帐户上启用计时器,只需对计时器TIM1的寄存器CR1的CEN字段的
Enable值调用
Set()方法:
TIM1::CR1::CEN::Enable::Set() ; 。 在代码中,它将如下所示:
int main() { if (TIM1::CR1::CKD::DividedBy2::IsSet()) { TIM1::ARR::Set(100U) ; TIM1::CR1::CEN::Enable::Set() ; } }
为了进行比较,使用C头文件是相同的: int main() { if((TIM1->CR1 & TIM_CR1_CKD_Msk) == TIM_CR1_CKD_0) { TIM1->ARR = 100U ; regValue = TIM1->CR1 ; regValue &=~(TIM_CR1_CEN_Msk) ; regValue |= TIM_CR1_CEN ; TIM1->CR1 = regValue ; } }
因此,进行了主要改进,我们可以对寄存器及其字段和值进行简单且可理解的访问。
访问在编译级别进行控制,并且如果寄存器,字段或值不允许进行写入或读取,则即使在将代码闪存到微控制器之前,也将清除该访问权限。但是,仍然有一个缺点,不可能同时将多个字段值放入寄存器中。想象一下您需要执行以下操作: int main() { uint32_t regValue = TIM1->CR1 ; regValue &=~(TIM_CR1_CKD_Msk | TIM_CR1_DIR) ; regValue |= (TIM_CR1_CEN | TIM_CR1_CKD_0 | TIM_CR1_CKD_0) ; TIM1->CR1 = regValue ; }
为此,我们需要在寄存器Set(...)中创建一个具有可变数量参数的方法,或者尝试指定需要在模板中设置的字段的值。即
实现以下选项之一: int main() {
由于具有可变参数个数的选项不会总是由编译器优化,并且实际上所有参数都将通过寄存器和堆栈传输,这可能会影响RAM的速度和开销,因此我选择了第二种方法,即在该阶段进行要设置的位掩码的计算编译。我们将使用带有可变数量参数的模板。值列表作为类型列表传递:
为了在寄存器中设置所需的值,我们需要:- 从整个值集中形成一个掩码,以重置寄存器中的所需位。
- 从整个值集中,生成一个值以设置所需的位。
这些应该是constexpr方法,这些方法将在编译阶段执行所有必要的操作:
仅定义公共方法Set()和IsSet():
几乎所有事情,还有一个小问题,我们可以做到这样的愚蠢: int main() {
显然,您需要以某种方式检查我们的值集是否区分大小写,做到这一点非常简单,只需在template参数中添加一个附加类型,我们称之为FieldValueBaseType。现在,该寄存器和可以在该寄存器中设置的字段的值应为同一FieldValueBaseType类型:向该寄存器添加对字段值所有权的检查 template<uint32_t address, size_t size, typename AccessMode, typename FieldValueBaseType, typename ...Args> class Register { private:
设置多个字段值时,SFINAE机制将再次检查此值是否与寄存器字段允许的类型相同,如果是,则由编译器显示该方法,否则,编译时会出现错误。TIM1的CR1寄存器的完整描述如下所示: struct TIM1 { struct TIM1CR1Base {} ; struct CR1 : public RegisterBase<0x40010000, 32, ReadWriteMode> { using CKD = TIM_CR_CKD_Values<TIM1::CR1, 8, 2, ReadWriteMode, TIM1CR1Base> ; using ARPE = TIM_CR_ARPE_Values<TIM1::CR1, 7, 1, ReadWriteMode, TIM1CR1Base> ; using CMS = TIM_CR_CMS_Values<TIM1::CR1, 5, 2, ReadWriteMode, TIM1CR1Base> ; using DIR = TIM_CR_DIR_Values<TIM1::CR1, 4, 1, ReadWriteMode, TIM1CR1Base> ; using OPM = TIM_CR_OPM_Values<TIM1::CR1, 3, 1, ReadWriteMode, TIM1CR1Base> ; using URS = TIM_CR_URS_Values<TIM1::CR1, 2, 1, ReadWriteMode, TIM1CR1Base> ; using UDIS = TIM_CR_UDIS_Values<TIM1::CR1, 1, 1, ReadWriteMode, TIM1CR1Base> ; using CEN = TIM_CR_CEN_Values<TIM1::CR1, 0, 1, ReadWriteMode, TIM1CR1Base> ; } ; }
因此,现在可以单独更改和检查寄存器字段的任何值,您可以一次设置和检查多个字段值。您可以更改并获取该字段或寄存器的值,同时绝对确保您不会混淆任何东西,并且将无法进行无效的操作,或者在寄存器字段中写入错误的位。现在让我们回到C的原始版本,在那里我们做了很多废话:并尝试使用新方法执行相同操作: int main(void) {
在每种情况下,我们在编译阶段都会遇到错误,这正是我们所实现的。好吧,我们提供了一个美丽,安全的访问寄存器及其字段的通道,但是速度如何?性能表现
为了进行比较,我们的方法有多理想,我们将使用C和C ++代码将时钟馈送到端口A,将三个端口设置为输出模式,并在这三个端口中设置输出端口:C代码: int main() { uint32_t res = RCC->AHB2ENR; res &=~ RCC_AHB1ENR_GPIOAEN_Msk ; res |= RCC_AHB1ENR_GPIOAEN ; RCC->AHB2ENR = res ; res = GPIOA->MODER ; res &=~ (GPIO_MODER_MODER5 | GPIO_MODER_MODER4 | GPIO_MODER_MODER1) ; res |= (GPIO_MODER_MODER5_0 | GPIO_MODER_MODER4_0 | GPIO_MODER_MODER1_0) ; GPIOA->MODER = res ; GPIOA->BSRR = (GPIO_BSRR_BS5 | GPIO_BSRR_BS4 | GPIO_BSRR_BS1) ; return 0 ; }
C ++代码: int main() { RCC::AHB1ENR::GPIOAEN::Enable::Set() ; GPIOA::MODERPack< GPIOA::MODER::MODER5::Output, GPIOA::MODER::MODER4::Output, GPIOA::MODER::MODER1::Output>::Set() ; GPIOA::BSRRPack< GPIOA::BSRR::BS5::Set, GPIOA::BSRR::BS4::Set, GPIOA::BSRR::BS1::Set>::Write() ; return 0 ; }
我正在使用IAR编译器。让我们看看两种优化模式:没有优化和中等优化:没有优化的C代码和汇编程序表示形式:没有优化的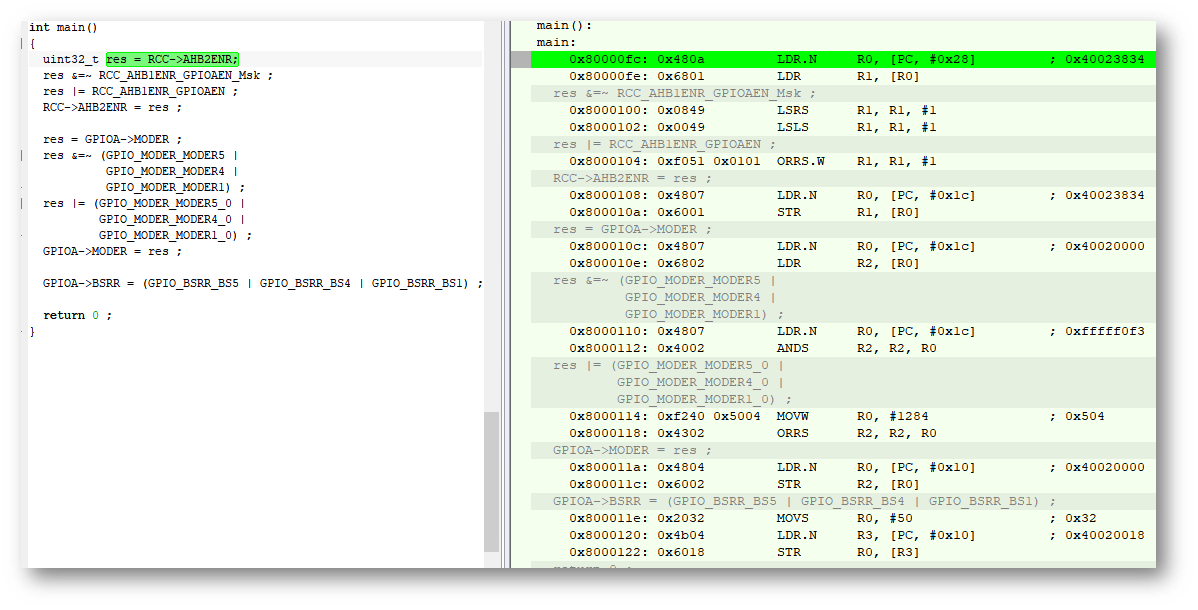 C ++代码和汇编程序表示形式:
C ++代码和汇编程序表示形式: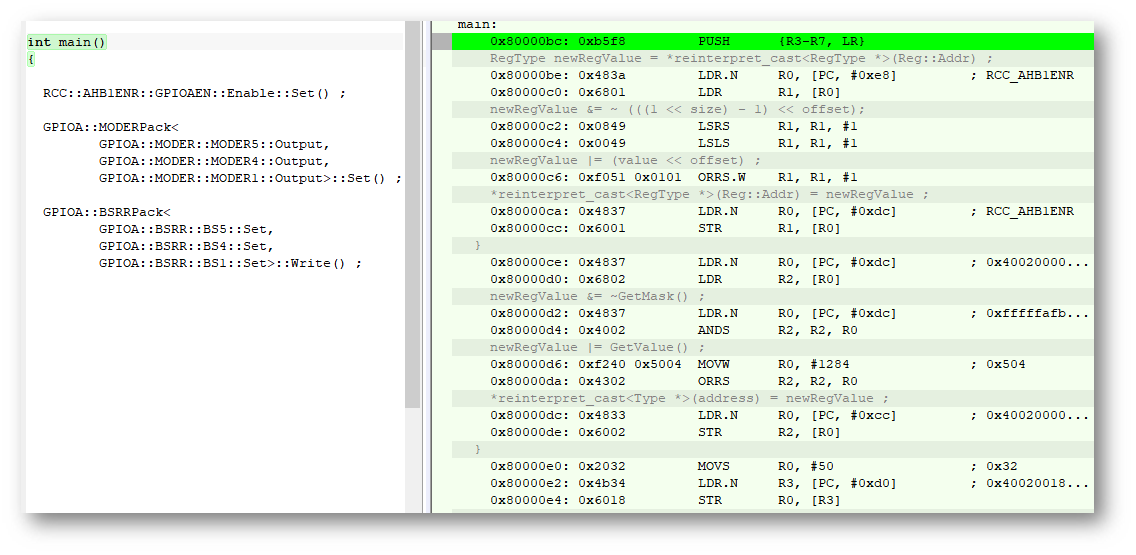 两种情况下的18行汇编器和代码几乎相同,实际上这并不奇怪,因为它是这就是我们所取得的成就。我们检查平均优化,C中的代码:
两种情况下的18行汇编器和代码几乎相同,实际上这并不奇怪,因为它是这就是我们所取得的成就。我们检查平均优化,C中的代码: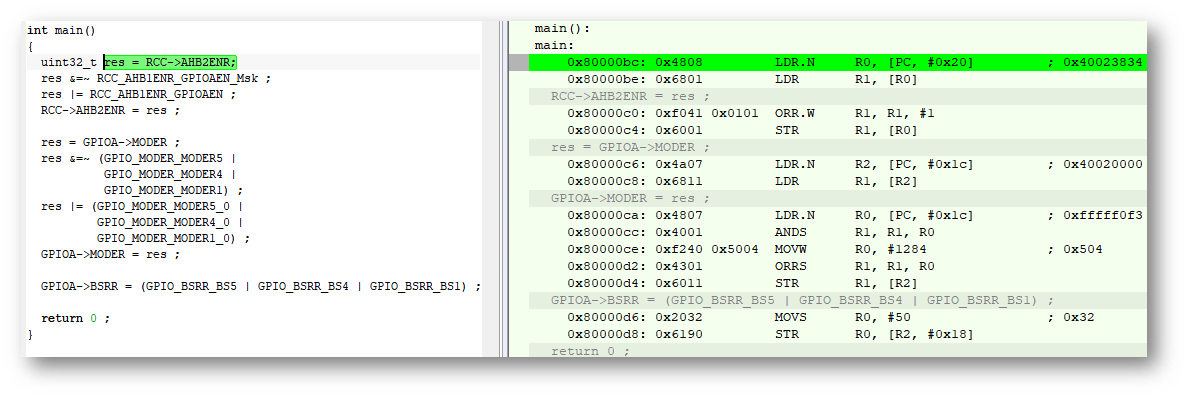 预期已经只有13条汇编器行。而且C ++代码平均而言是优化的:
预期已经只有13条汇编器行。而且C ++代码平均而言是优化的: 再次,情况是相同的:没有开销,并且在代码可读性方面有明显的优势。好了,所有任务都解决了,最后一个问题出现了。以这种形式描述所有寄存器需要多少时间和精力?
再次,情况是相同的:没有开销,并且在代码可读性方面有明显的优势。好了,所有任务都解决了,最后一个问题出现了。以这种形式描述所有寄存器需要多少时间和精力?如何描述所有寄存器
我们获得了可靠,方便,快捷的寄存器访问权限。仍然有一个问题。如何描述所有寄存器,对于单片机也有不到一百个。这是描述所有寄存器所需的时间,因为在这样的例行工作中您可能会犯很多错误。是的,您不需要手动执行此操作。相反,我们将使用SVD文件中的代码生成器,正如我在本文开头所指出的那样,它完全涵盖了我接受的寄存器抽象。我完成了一个同事的脚本,基于这个想法,脚本也做了相同的工作,但是使用枚举代替字段值的类要容易一些。该脚本仅用于测试和检查想法,因此并不是最佳选择,但它允许您生成类似的内容。 谁在乎脚本在这里
谁在乎脚本在这里总结
结果,程序员的工作只是正确地连接生成的文件。如果您需要使用寄存器,例如gpioa或rcc模块,则只需包含所需的头文件: #include "gpioaregisters.hpp"
重复一遍,可以从制造商的网站下载SVD文件,您可以将其拉出开发环境,然后将其提交到脚本输入中,仅此而已。但是,正如我上面所说,并不是所有的制造商都关心他们的消费者,因此并不是每个人都在SVD文件中进行枚举,因此,ST微控制器的所有枚举在生成后都是这样的: template <typename Reg, size_t offset, size_t size, typename AccessMode, typename BaseType> struct GPIOA_MODER_MODER_Values: public RegisterField<Reg, offset, size, AccessMode> { using Value0 = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 0U> ; using Value1 = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 1U> ; using Value2 = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 2U> ; using Value3 = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 3U> ; } ;
在需要使用它们的那一刻,您可以查看文档并更改“值”一词,以获得更易理解的信息: template <typename Reg, size_t offset, size_t size, typename AccessMode, typename BaseType> struct GPIOA_MODER_MODER_Values: public RegisterField<Reg, offset, size, AccessMode> { using Input = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 0U> ; using Output = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 1U> ; using Alternate = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 2U> ; using Analog = FieldValue<GPIOA_MODER_MODER_Values, BaseType, 3U> ; } ;
之后,您所有的字段值都将具有一个清晰的名称。我希望将来ST仍能描述所有字段值,那么手工工作通常将为0。公平地说,在大多数情况下,程序员应该手动创建枚举枚举,以加深理解。实际上,一切都欢迎任何建议和评论。IAR 8.40.1下的项目位于此处,源代码本身位于此处 “在线GDB”代码PS:感谢putyavka提供的方法中发现的错误,以及Ryppka提供的具有assert的错误。RegisterField::Get()文章中使用的链接和文章
Typesafe Register Access in C++One Approach to Using Hardware Registers in C++SVD Description (*.svd) Format