现在,Vision框架能够识别真实的文本,而不是以前那样。 我们期待将其应用于Dodo IS。 同时,翻译了有关识别棋盘游戏《魔力聚集》中的牌并从中提取文本信息的文章。
Vision框架与iOS 11一起于2017年在WWDC上首次向公众介绍。
创建Vision是为了帮助开发人员分类和识别对象,水平面,条形码,面部表情和文本。
但是,文本识别存在一个问题:Vision可以找到文本所在的位置,但是实际的文本识别并没有发生。 当然,很高兴看到单个文本片段周围的边界框,但是随后必须将其拉出并独立识别。
此问题已在iOS 13中包含的Vision更新中得到解决。现在,Vision框架提供了真正的文本识别。
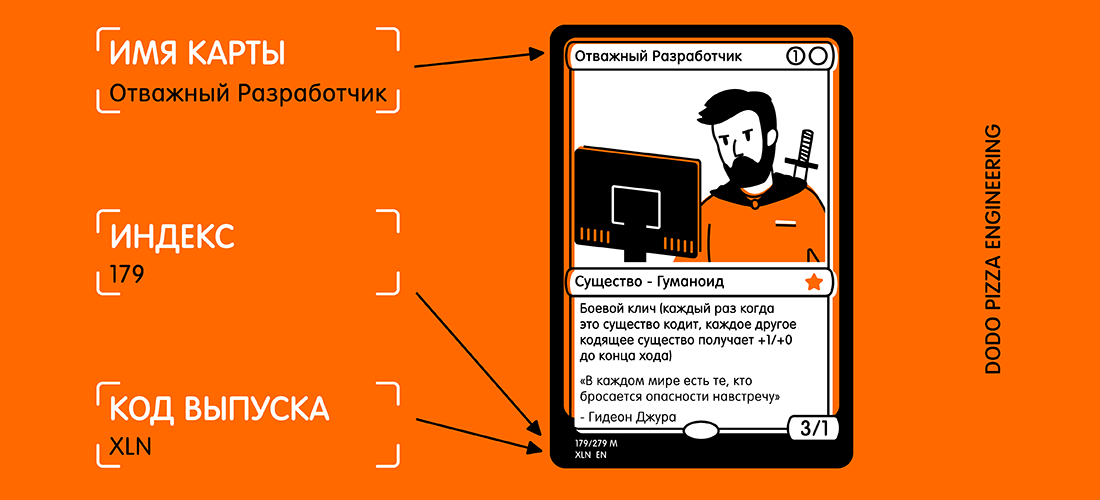
为了测试这一点,我创建了一个非常简单的应用程序,该应用程序可以识别棋盘游戏《 The Gathering》中的一张卡片,并从中提取文本信息:
这是我想接收的地图和所选文本的示例。

看着卡,您可能会想:“此文本很小,此外卡上还有很多其他文本可能会干扰。” 但是对于Vision来说,这不是问题。
首先,我们需要创建一个
VNRecognizeTextRequest 。 本质上,这是对我们希望识别的内容的描述,以及识别语言的设置和准确性级别:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText) request.recognitionLevel = .accurate request.recognitionLanguages = ["en_GB"]
完成块的格式为
handleDetectedText(request: VNRequest?, error: Error?) 。 我们将其传递给
VNRecognizeTextRequest构造函数,然后设置其余属性。
有两种识别精度级别:
.fast和
.accurate 。 由于我们的卡片底部有一个很小的文字,因此我选择了更高的准确性。 较快速的选项可能更适合于大量文本。
由于我的所有卡片都包含在其中,因此我将识别仅限于英语,您可以指定几种语言,但是您需要了解,每种其他语言的扫描和识别可能需要更长的时间。
还有两个属性值得一提:
customWords :您可以在内置词典的顶部添加要使用的字符串数组。 如果文本中有任何不正常的单词,这将很有用。 我没有在该项目中使用该选项。 但是,如果我要开发商业化的Magic The Gathering卡识别应用程序,则会添加一些最复杂的卡(例如Fblthp,The Lost )以避免出现问题。minimumTextHeight :这是一个浮点值。 它指示相对于图像高度的大小,在该高度处不再应识别文本。 如果我创建此扫描仪只是为了获取地图名称,则删除不需要的所有其他文本将很有用。 但是我需要最小的文本,因此现在我已经忽略了此属性。 显然,如果忽略小文本,则识别速度会更高。
现在我们有了请求,我们必须将其与图片一起传递给请求处理程序:
let requests = [textDetectionRequest] let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:]) DispatchQueue.global(qos: .userInitiated).async { do { try imageRequestHandler.perform(requests) } catch let error { print("Error: \(error)") } }
我直接从相机使用图像,将其从
UIImage转换为
CGImage 。 在
VNImageRequestHandler其与方向标志一起使用,以帮助处理程序了解其应识别的文本。
作为此演示的一部分,我仅以纵向方向使用手机。 很自然地,我添加了
.right方向。 太棒了!
事实证明,相机在设备上的方向与设备的旋转方向完全独立,并且始终被认为是向左移动(如2009年的默认设置,要拍照,您需要使手机保持横向)。 当然,时代已经变了,我们基本上以人像格式拍摄照片和录像,但是相机仍然对准左侧。
一旦配置了处理程序,我们就以
.userInitiated优先级进入流,并尝试满足我们的请求。 您可能会注意到,这是一个查询数组。 发生这种情况是因为您可以尝试一次性提取多条数据(即,从同一张图片中识别出面孔和文字)。 如果没有错误,则在检测到文本之后将调用使用我们的请求创建的回调:
func handleDetectedText(request: VNRequest?, error: Error?) { if let error = error { print("ERROR: \(error)") return } guard let results = request?.results, results.count > 0 else { print("No text found") return } for result in results { if let observation = result as? VNRecognizedTextObservation { for text in observation.topCandidates(1) { print(text.string) print(text.confidence) print(observation.boundingBox) print("\n") } } } }
我们的处理程序返回我们的查询,该查询现在具有results属性。 每个结果都是一个
VNRecognizedTextObservation ,对我们来说,该结果有多个选项(以下简称为候选项)。
对于每个识别的文本单元,您最多可以获取10个候选字,并且它们以置信度降序排列。 如果您有某些术语在第一次尝试时解析器会错误地识别出来,则这很有用。 但是即使他对结果的正确性信心不足,也可以稍后正确地确定。
在这个例子中,我们只需要第一个结果,因此我们遍历了
observation.topCandidates(1)并提取了文本和置信度。 虽然候选人本人具有不同的文字和信心,但
.boundingBox保持不变。
.boundingBox使用归一化坐标系,其原点位于左下角,因此,如果将来要在UIKit中使用它,则为了方便起见,需要对其进行转换。
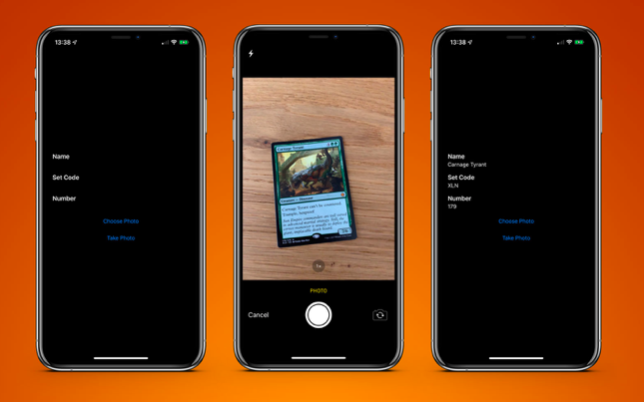
这几乎就是您所需要的。 如果我通过这张
照片运行
卡的
照片,则可以在不到0.5秒的时间内在iPhone XS Max上获得以下结果:
Carnage Tyrant 1.0 (0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786) Creature 1.0 (0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635) Dinosaur 1.0 (0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364) Carnage Tyrant can't be countered. 1.0 (0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906) Trample, hexproof 0.5 (0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653) Sun Empire commanders are well versed 1.0 (0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302) in advanced martial strategy. Still, the 1.0 (0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136) correct maneuver is usually to deploy the 1.0 (0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009) giant, implacable death lizard. 1.0 (0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258) 7/6 0.5 (0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593) 179/279 M 1.0 (0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193) XLN: EN N YEONG-HAO HAN 0.5 (0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319) TN & 0 2017 Wizards of the Coast 1.0 (0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
这太不可思议了! 识别出每个文本,将其放置在其自己的边界框中,并以1.0的置信度返回结果。
即使很小的版权也基本上是正确的。 所有这些操作都是在30MBx4032的图像上完成的,其大小为3.1 MB。 如果我先缩小图像,则过程会更快。 还值得注意的是,在具有特殊神经引擎的新型A12仿生芯片上,该过程要快得多。
识别文本后,最后要做的就是提取我需要的信息。 我不会在此处放置所有代码,但关键逻辑是
.boundingBox每个
.boundingBox确定位置,以便我可以选择左下角和左上角的文本,而忽略右侧的任何内容。
最终结果是扫描卡应用程序,并在不到一秒钟的时间内将结果返回给我。
PS实际上,我只需要一个发布代码和一个收集号(它是一个索引)。 然后可以在Scryfall服务API中使用它们来获取有关此地图的所有可能信息,包括游戏规则和成本。
 GitHub上
GitHub上提供了一个示例应用程序。