对于前端开发人员来说,最重要的是浏览器显示模块,它也是渲染引擎(以下称为RE)。
在本文中,我想做一个简单的页面,并完成所有与RE一起的步骤,从接收第一个字节到将内容绘制到屏幕上。 和往常一样,我将使用Chrome浏览器。
首先,让我们看看浏览器还包含哪些其他模块,以了解RE与之交互。
考虑该方案:
 图1用户界面,用户界面(以下
图1用户界面,用户界面(以下称为
UI) -
用户的外部浏览器API:地址栏,导航,菜单,书签,按钮“更新”和“主页”。
浏览器机制浏览器引擎(以下称为BE)是用户界面和显示模块之间的一层。
渲染引擎显示模块 。 稍后我们将对其进行更详细的分析。
网络组件,网络负责网络请求。 RE从网络接收数据。 数据以8Kb的部分接收,RE不会等到所有数据到达后,才开始处理它。
JS Interpreter模块负责解释脚本并执行它。
UI后端用于呈现基本的图形元素和小部件,例如窗口和组合框。 警报或提示窗口的简单示例。
数据存储是cookie,indexDB和其他浏览器存储。
现在我们已经基本了解了浏览器的组成,接下来我们可以继续研究感兴趣的组件-渲染引擎。
通过一个特定的示例可以更轻松,更轻松地理解它,因此,让我们看一个带有一个外部css和js文件的简单html页面(脚本与async属性相关联,然后我们将分析原因)。 让我们看看RE如何处理它们以及执行了哪些步骤,然后才能在屏幕上看到我们需要的内容。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <link rel="stylesheet" href="./style.css"></link> <title>Document</title> </head> <body> <div>Hello Habr!</div> <div>I'am Rendering Engine</div> <script async src="./script.js"></script> </body> </html>
(function() { window.addEventListener('load', () => { console.log('all resources were loaded'); }); })();
* { margin: 0; padding: 0; box-sizing: border-box; } body { font-family: Helvetica, sans-serif; line-height: 1.5; background-color: #9BD4F4; padding: 16px; }
为此,请转到Chrome DevTools,打开性能标签并启动该过程。 重新加载页面并分析了发生的情况之后,我们观察到以下图片:
 图2
图2在“网络”选项卡中-通过网络下载数据的顺序(蓝色框-index.html)。
“时间”选项卡显示发生DCL事件时的标记(加载DOM内容,FP-第一绘画,FCP-第一内容,绘画,FMP-第一有意义绘画,L-加载)。 让我们看看这些事件是什么。
DOMContentLoaded-浏览器加载了HTML,对其进行了解析并构建了DOM树。 该事件在文档上触发,您可以轻松地对其进行订阅并通过JavaScript使用DOM(在我们的脚本中,我们将无法订阅DOMContentLoaded事件,因为它发生在脚本解析之前,请参
见图 )。
另外,DOMContentLoaded有几个细微差别:
- 如果脚本连接时没有异步/延迟标签(同步),则它将阻止HTML解析。 但是,浏览器最近使用了推测性解析,在这种情况下,他们仍然会提前下载此脚本并进行解析。 这不会影响DOM树的结构,但是可以减少RE的工作时间。 下图显示了如何通过同步脚本连接来增加DCL和所有其他渲染事件的时间
- 解析锁(您猜对了)可以使用async / defer属性来规避,该属性使您可以继续解析HTML,而无需等待脚本下载和执行
- 此外,DCL事件可能会由于加载样式而延迟。 在执行脚本的过程中,浏览器可以看到我们想通过JavaScript访问元素的样式。 如果当前已解析或加载此元素的样式,则此脚本将被阻止
- 同样在Chrome中,例如在DCL上,表格是自动完成的。
 图3第一次绘制
图3第一次绘制 -浏览器呈现了页面上的第一个像素。
第一个内容丰富的
绘画 -浏览器在页面上呈现了第一个内容。
第一个有意义的绘画 -事件在RE确定渲染的内容可能对用户有用之后触发。
加载整个页面,并加载其中的资源,包括iframe。
关于FP,FCP,FMP在
Google面向开发人员的官方文档中写得很好。
现在我们已经弄清楚发生了什么事件,我们可以转到Call树(参见
图1 )并更详细地分析何时以及为什么发生这些事件。
解析HTML-HTML解析。 您可以撰写有关此内容的另一篇文章。 更好的是,阅读
规范,我们只需要了解基于HTML的浏览器就可以创建文档的对象模型-DOM。 并且,当它准备好并且不再可以影响它时,它将触发DOMContentLoaded事件。
合成层是将来自不同来源的视觉元素组合成单个图像,从而产生一种幻觉,即所有这些元素都是同一场景的一部分。
重新计算样式。 对DOM的任何更改,无论是添加或删除元素,更改属性,类还是使用动画工具,都将导致浏览器重新计算元素的样式,并在许多情况下重新计算整个页面或其部分的布局。 此过程称为样式计算。
适用于开发人员的Google解析样式表。 解析后,如果RE看到HTML启用了CSS,它将开始提前下载和解析。 在解析之后,RE构建CSS对象模型,即CSS对象模型。
接下来是附件阶段,在该阶段RE将CSS映射到OM和DOM,我们得到了一个渲染树。
更新图层树(布局)-图层树的布局或仅布局。 匹配CSS OM和DOM之后,我们可以找到元素的位置及其大小。
通常,流中较低的元素不会影响上方元素的位置,因此布局通常是顺序执行的-从上到下以及从左到右。 因此,HTML标准提供了文档布局的流模型。
绘画-将内容呈现到屏幕上。 只有完成所有这些步骤,我们才能在屏幕上看到该站点的内容:D
这是RE中所有步骤的简要概述:
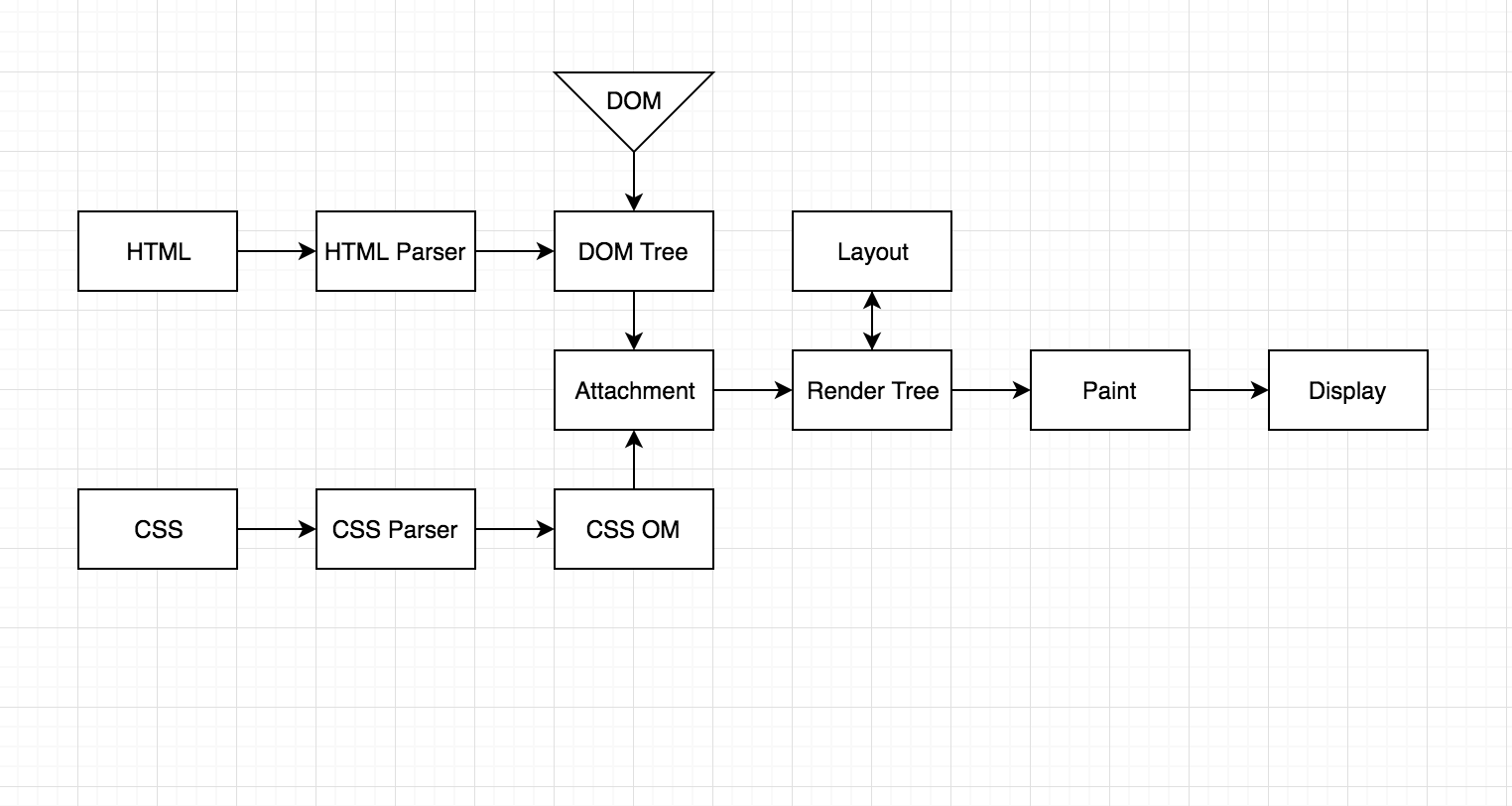 图4
图4我们总结:
RE中的数据分批来自网络模块。 收到此数据后,RE开始使用它,即HTML解析。
当RE看到HTML中遇到了外部资源时,他会与Network谈论它,然后开始下载它,然后再次将其交给RE。
根据RE标准满足<script>标记将停止解析,并等待该脚本下载并执行,然后才继续解析和构建DOM树。 这可以通过异步/延迟属性解决。 您可以
在此处详细了解它们之间的区别,主要是要了解它们使无需等待脚本处理就可以继续解析HTML。
此外,如果浏览器(在我们的示例中为Chrome)尝试(通过JavaScript)与当前正在处理其样式的元素的CSS配合使用,则可以阻止脚本的执行。
在RE理解所有同步脚本都已下载并可以工作之后,HTML被完全解析并且不再困扰我们,它引发DOMContentLoaded事件,并且我们在可以使用的浏览器中获得了一个#document对象。
接下来,在完成CSS解析并构建CSS对象模型之后,将进行附加阶段,在该阶段将构建渲染树并进行布局(块的大小和位置的布局)。 好吧,在“布局”之后,屏幕上将出现一个图形-“绘画”。 渲染引擎经过很长的路要走,以至于您和我看到以下内容:
 图5
图5仅此而已!
希望本文对您有所帮助,现在您了解了渲染引擎的工作原理。
再见:)很快再见。 如果喜欢,喜欢并订阅我的频道:)