神经网络-这是一个引起极大兴趣并渴望了解它的话题。 但是,不幸的是,它并不适合所有人。 当您看到大量晦涩难懂的文学作品时,您会失去学习的欲望,但您仍想了解正在发生的事情。
最后,在我看来,没有比找出并创建自己的小项目更好的方法了。
您可以通过展开文本来阅读抒情背景,也可以跳过该内容而直接进入
神经网络的
描述。做项目的重点是什么。优点:
- 您更好地了解神经元的排列方式
- 您更好地了解如何使用现有库
- 并行学习新知识
- 发痒自我,创造属于自己的东西
缺点:
- 您正在制造一辆自行车,它可能比现有自行车更差
- 没有人关心您的项目。
语言的选择。在选择语言时,我或多或少了解C ++,并且熟悉Python的基础知识。 使用Python处理神经元更加容易,但是C ++了解得更多,并且没有比OpenMP更容易进行计算并行化了。 因此,我选择了C ++,并且为了避免打扰,用于Python的API将创建一个在Windows和Linux上
均可使用的工具。 (
有关如何使用C ++代码制作Python库
的示例 )
OpenMP和GPU加速。目前,Visual Studio中安装了OpenMP 2.0版,其中仅具有CPU加速功能。 但是,从3.0版开始,OpenMP还支持GPU加速,而指令的语法并不复杂。 它仅需等待所有编译器都支持OpenMP 3.0。 同时,为简单起见,仅CPU。
我的第一把耙子。计算神经元的值有以下几点:在计算激活函数之前,我们需要将权重的乘积与输入数据相加。 如何在大学里学习如何做到这一点:在对一个大的小数目的向量求和之前,必须将其按升序排序。 所以在这里。 在神经网络中,除了将程序减慢N次之外,这没有任何作用。 但是只有当我已经在MNIST上测试了我的网络时,我才意识到这一点。
将项目放在GitHub上。我不是第一个在GitHub上发布我的作品的人。 但是在大多数情况下,通过该链接,您只能在README.md中看到一堆带有铭文的代码:
“这是我的神经网络,请仔细研究 。
” 为了至少比其他更好,他或多或少描述了
README.md并填写了
Wiki 。 消息很简单-
填写Wiki。 一个有趣的发现:如果GitHub上Wiki中的标题是用俄语编写的,则此标题的
锚点将不起作用。
执照当您创建小型项目时,许可证又是一种挠挠自我的方式。 这是有关许可证用途的有趣
文章 。 我选择了
APACHE 2.0 。
网络说明。
特点
我的库的主要优点是使用一行代码创建了一个网络。
不难发现,在线性层中,一层中的神经元数量等于下一层中的输入参数数量。 另一个明显的说法-最后一层的神经元数量等于网络的输出值数量。
让我们创建一个在输入端接收三个参数的网络,该网络具有三个带有5、4和2个神经元的层。
import foxnn nn = foxnn.neural_network([3, 5, 4, 2])
如果看图片,您将看到:前三个输入参数,然后是具有5个神经元的层,然后是具有4个神经元的层,最后是具有2个神经元的最后一层。
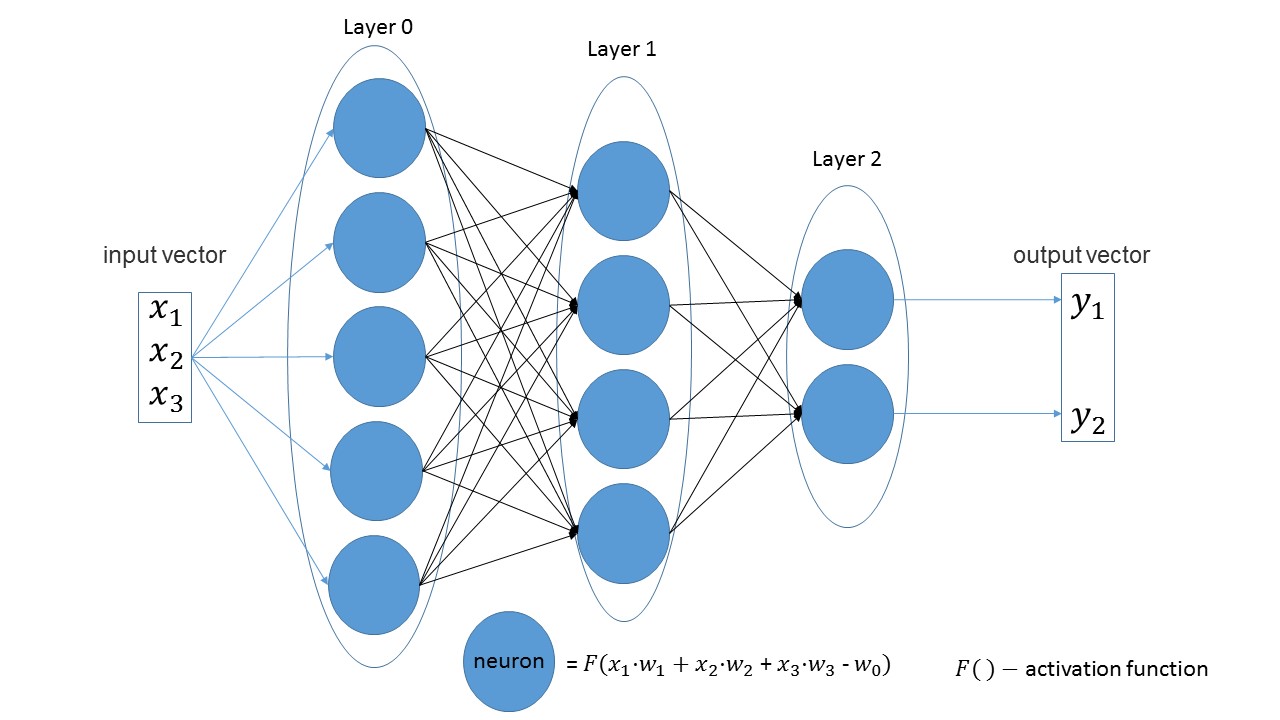
默认情况下,所有激活功能均为S型(我更喜欢它们)。
如果需要,可以将任何层上的功能更改为其他功能。
nn.get_layer(0).set_activation_function("gaussian")
易于创建训练集。 第一个向量是输入数据,第二个向量是目标数据。
data = foxnn.train_data() data.add_data([1, 2, 3], [1, 0])
网络培训:
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98)
启用优化:
nn.settings.set_mode("Adam")
还有一种只获得网络价值的方法:
nn.get_out([0, 1, 0.1])
关于方法名称的一点点。另外, get转换如何获取 , out表示 输出 。 我想获得名称“ 赋予输出值 ”,并得到它。 直到后来我才注意到原来是滚蛋 。 但这更有趣,于是决定离开。
测试中
测试基于
MNIST的任何网络已经成为一种不成文的传统。 我也不例外。 所有带有注释的代码都可以在
这里找到。
创建一个训练样本: from mnist import MNIST import foxnn mndata = MNIST('C:download/') mndata.gz = True imagesTrain, labelsTrain = mndata.load_training() def get_data(images, labels): train_data = foxnn.train_data() for im, lb in zip(images, labels): data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
创建一个网络:三层,784个输入参数,10个输出参数: nn = foxnn.neural_network([784, 512, 512, 10]) nn.settings.n_threads = 7
我们训练: nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98)
发生了什么:
在大约10分钟内(仅CPU加速),可以获得75%的精度。 通过Adam优化,可以在5分钟内获得88%的精度。 最后,我设法达到了97%的准确性。
主要缺点(已经有修订计划):- 在Python中,尚未发生错误,即 在python中,错误不会被拦截,程序只会退出并显示错误。
- 虽然训练是在迭代中指示的,而不是在其他网络中惯常的时代。
- 没有GPU加速
- 尚无其他类型的图层。
- 我们需要将项目上传到PyPi。
对于项目的一点完成,缺少这篇文章。 如果至少有十个人感兴趣并玩游戏,那么已经有胜利了。 欢迎来到我的
github 。
PS:如果您需要自己创建一些东西才能弄清楚,请不要害怕并创建。