多年来,作为SQL Server DBA进行服务器管理,然后进行性能优化。 总的来说,我想在空闲时间为Universe和我们的同事做一些有用的事情。 因此,最终我们得到了一个用于SQL Server和Azure的小型
开源索引维护
工具 。
主意
有时,当他们按优先顺序进行工作时,人们可能会像手指式电池一样-仅一次闪光便有足够的动力,然后就可以了。 直到最近,我对生活的观察也不例外。 我经常会被创意所吸引,以创造属于自己的东西,但是优先事项发生了变化,一切都没有结束。
Kharkov公司Devart的工作对我的动机和专业发展产生了相当大的影响,该公司从事用于SQL Server,MySQL和Oracle数据库开发和管理的软件的创建。
在接触他们之前,我对创建自己的产品的具体细节一无所知,但是在此过程中,我已经获得了许多有关SQL Server内部结构的知识。 经过一年多的优化其产品系列中的元数据请求,我逐渐开始了解市场上最需要哪种功能。
在某个阶段,这个想法产生了,以创建一种新的利基产品,但是由于环境的原因,这个想法没有成功。 当时,对于新项目,公司内部没有足够的自由资源,而又不会损害核心业务。
当他在一个新地方工作并尝试独自完成该项目时,他不得不不断做出一些妥协。 制作功能齐全的大型产品的最初想法很快消失了,并逐渐转变为另一个方向-将计划的功能分解为单独的微型工具,并使它们彼此独立实现。
结果,
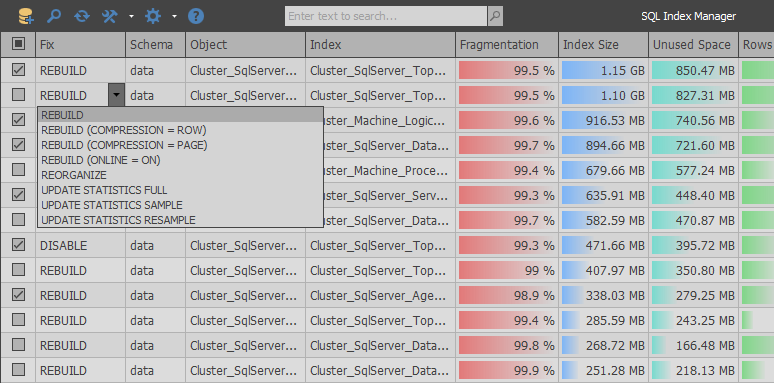
SQL索引管理器诞生了-用于SQL Server和Azure的免费索引维护工具。 主要思想是将RedGate和Devart的商业替代品作为基础,并尝试改善其功能。 为初学者和有经验的用户提供方便地分析和维护索引的能力。
实作
换句话说,一切总是听起来很简单……他看了看一些激动人心的维多西科夫,站在架子上,开始制作很酷的产品。 但是实际上,并不是所有事情都那么乐观,因为使用sys.dm_db_index_physical_stats系统表函数时会遇到很多陷阱,并且结合使用,这是从中可以获得有关索引碎片的相关信息的唯一地方。
从开发的第一天开始,就有很大的机会在标准方案之间走出一条沉闷的道路,复制竞争应用程序工作中已经调试好的逻辑,同时增加一点麻烦。 但是在分析了对元数据的需求之后,我想做一些更优化的事情,由于大公司的官僚作风,它们永远不会出现在他们的产品中。
分析RedGate SQL索引管理器(1.1.9.1378-$ 155)时,您可以看到该应用程序使用了一种非常简单的方法:通过一个查询,我们获得了用户表和视图的列表,在第二次查询后,返回了所选数据库中所有索引的列表。
SELECT objects.name AS tableOrViewName , objects.object_id AS tableOrViewId , schemas.name AS schemaName , CAST(ISNULL(lobs.NumLobs, 0) AS BIT) AS ContainsLobs , o.is_memory_optimized FROM sys.objects AS objects JOIN sys.schemas AS schemas ON schemas.schema_id = objects.schema_id LEFT JOIN ( SELECT object_id , COUNT(*) AS NumLobs FROM sys.columns WITH (NOLOCK) WHERE system_type_id IN (34, 35, 99) OR max_length = -1 GROUP BY object_id ) AS lobs ON objects.object_id = lobs.object_id LEFT JOIN sys.tables AS o ON o.object_id = objects.object_id WHERE objects.type = 'U' OR objects.type = 'V' SELECT i.object_id AS tableOrViewId , i.name AS indexName , i.index_id AS indexId , i.allow_page_locks AS allowPageLocks , p.partition_number AS partitionNumber , CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex FROM sys.indexes AS i JOIN sys.partitions AS p ON p.index_id = i.index_id AND p.object_id = i.object_id JOIN ( SELECT COUNT(*) AS numPartitions , object_id , index_id FROM sys.partitions GROUP BY object_id , index_id ) AS c ON c.index_id = i.index_id AND c.object_id = i.object_id WHERE i.index_id > 0 -- ignore heaps AND i.is_disabled = 0 AND i.is_hypothetical = 0
然后,在一个循环中,针对索引的每个部分发送一个请求,以确定其大小和碎片级别。 扫描结束时,权重小于入口阈值的索引将在客户端上被丢弃。
EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 1, @partitionNr = 1 EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 2, @partitionNr = 1 EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 3, @partitionNr = 1
在分析此应用程序的逻辑时,您会发现许多缺点。 例如,如果发现小故障,则在发送请求之前,不会检查当前节是否包含字符串以排除空节。
但是从另一个方面来看,问题最严重:服务器请求的数量将大约等于sys.partitions中的总行数。 考虑到实际数据库可以包含数以万计的部分,因此这种细微差别可以导致对服务器的大量类似请求。 在数据库是远程的情况下,由于每个请求(即使是最简单的请求)的网络延迟增加,扫描时间将变得更长。
与RedGate不同,在Devart中开发的类似产品-用于SQL Server的dbForge索引管理器(1.10.38-$ 99)在一个大型查询中接收信息,然后在客户端上显示所有内容:
SELECT SCHEMA_NAME(o.[schema_id]) AS [schema_name] , o.name AS parent_name , o.[type] AS parent_type , i.name , i.type_desc , s.avg_fragmentation_in_percent , s.page_count , p.partition_number , p.[rows] , ISNULL(lob.is_lob_legacy, 0) AS is_lob_legacy , ISNULL(lob.is_lob, 0) AS is_lob , CASE WHEN ds.[type] = 'PS' THEN 1 ELSE 0 END AS is_partitioned FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s JOIN sys.partitions p ON s.[object_id] = p.[object_id] AND s.index_id = p.index_id AND s.partition_number = p.partition_number JOIN sys.indexes i ON i.[object_id] = s.[object_id] AND i.index_id = s.index_id LEFT JOIN ( SELECT c.[object_id] , index_id = ISNULL(i.index_id, 1) , is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END) , is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END) FROM sys.columns c LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id AND i.index_id > 0 WHERE c.system_type_id IN (34, 35, 99) OR c.max_length = -1 GROUP BY c.[object_id], i.index_id ) lob ON lob.[object_id] = i.[object_id] AND lob.index_id = i.index_id JOIN sys.objects o ON o.[object_id] = i.[object_id] JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id WHERE i.[type] IN (1, 2) AND i.is_disabled = 0 AND i.is_hypothetical = 0 AND s.index_level = 0 AND s.alloc_unit_type_desc = 'IN_ROW_DATA' AND o.[type] IN ('U', 'V')
我们设法摆脱了竞争产品中相同类型查询的面纱的主要问题,但是此实现的缺点是没有将额外的参数传递给sys.dm_db_index_physical_stats函数,该函数可以限制对显然不必要的索引的扫描。 实际上,这导致在扫描阶段获得有关系统中所有索引的信息以及额外的磁盘负载。
重要的是要注意,从sys.dm_db_index_physical_stats获得的数据不会永久地缓存在缓冲池中,因此,在获取有关索引碎片的信息时将物理读数最小化是开发过程中的优先任务之一。
经过几次实验,结果证明将两种方法结合起来,将扫描分为两个部分。 首先,一个大型查询确定节的大小,并预先过滤那些不在过滤范围内的节:
INSERT INTO #AllocationUnits (ContainerID, ReservedPages, UsedPages) SELECT [container_id] , SUM([total_pages]) , SUM([used_pages]) FROM sys.allocation_units WITH(NOLOCK) GROUP BY [container_id] HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize
接下来,我们仅获取那些包含数据的节,以避免从空索引进行不必要的读取操作。
SELECT [object_id] , [index_id] , [partition_id] , [partition_number] , [rows] , [data_compression] INTO #Partitions FROM sys.partitions WITH(NOLOCK) WHERE [object_id] > 255 AND [rows] > 0 AND [object_id] NOT IN (SELECT * FROM #ExcludeList)
根据设置,仅获得用户要分析的那些索引类型(支持使用堆,集群/非集群索引和列指示符)。
INSERT INTO #Indexes SELECT ObjectID = i.[object_id] , IndexID = i.index_id , IndexName = i.[name] , PagesCount = a.ReservedPages , UnusedPagesCount = a.ReservedPages - a.UsedPages , PartitionNumber = p.[partition_number] , RowsCount = ISNULL(p.[rows], 0) , IndexType = i.[type] , IsAllowPageLocks = i.[allow_page_locks] , DataSpaceID = i.[data_space_id] , DataCompression = p.[data_compression] , IsUnique = i.[is_unique] , IsPK = i.[is_primary_key] , FillFactorValue = i.[fill_factor] , IsFiltered = i.[has_filter] FROM #AllocationUnits a JOIN #Partitions p ON a.ContainerID = p.[partition_id] JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id] AND p.[index_id] = i.[index_id] WHERE i.[type] IN (0, 1, 2, 5, 6) AND i.[object_id] > 255
在那之后,一点魔力开始了:对于所有小索引,我们通过重复调用sys.dm_db_index_physical_stats函数并完整指示所有参数来确定碎片级别。
INSERT INTO #Fragmentation (ObjectID, IndexID, PartitionNumber, Fragmentation) SELECT i.ObjectID , i.IndexID , i.PartitionNumber , r.[avg_fragmentation_in_percent] FROM #Indexes i CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r WHERE i.PagesCount <= @PreDescribeSize AND r.[index_level] = 0 AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA' AND i.IndexType IN (0, 1, 2)
接下来,我们将所有可能的信息返回给客户端,以过滤掉多余的数据:
SELECT i.ObjectID , i.IndexID , i.IndexName , ObjectName = o.[name] , SchemaName = s.[name] , i.PagesCount , i.UnusedPagesCount , i.PartitionNumber , i.RowsCount , i.IndexType , i.IsAllowPageLocks , u.TotalWrites , u.TotalReads , u.TotalSeeks , u.TotalScans , u.TotalLookups , u.LastUsage , i.DataCompression , f.Fragmentation , IndexStats = STATS_DATE(i.ObjectID, i.IndexID) , IsLobLegacy = ISNULL(lob.IsLobLegacy, 0) , IsLob = ISNULL(lob.IsLob, 0) , IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT) , IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT) , FileGroupName = fg.[name] , i.IsUnique , i.IsPK , i.FillFactorValue , i.IsFiltered , a.IndexColumns , a.IncludedColumns FROM #Indexes i JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id] LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID AND a.IndexID = i.IndexID LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID AND f.IndexID = i.IndexID AND f.PartitionNumber = i.PartitionNumber LEFT JOIN ( SELECT ObjectID = [object_id] , IndexID = [index_id] , TotalWrites = NULLIF([user_updates], 0) , TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0) , TotalSeeks = NULLIF([user_seeks], 0) , TotalScans = NULLIF([user_scans], 0) , TotalLookups = NULLIF([user_lookups], 0) , LastUsage = ( SELECT MAX(dt) FROM ( VALUES ([last_user_seek]) , ([last_user_scan]) , ([last_user_lookup]) , ([last_user_update]) ) t(dt) ) FROM sys.dm_db_index_usage_stats WITH(NOLOCK) WHERE [database_id] = @DBID ) u ON i.ObjectID = u.ObjectID AND i.IndexID = u.IndexID LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID AND lob.IndexID = i.IndexID LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id] AND i.PartitionNumber = dds.[destination_id] JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id] WHERE o.[type] IN ('V', 'U') AND ( f.Fragmentation >= @Fragmentation OR i.PagesCount > @PreDescribeSize OR i.IndexType IN (5, 6) )
此后,点查询确定大索引的碎片级别。
EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'') WHERE [index_level] = 0 AND [alloc_unit_type_desc] = ''IN_ROW_DATA''' , N'@ObjectID int,@IndexID int,@PartitionNumber int' , @ObjectId = 1044198770, @IndexId = 1, @PartitionNumber = 1 EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'') WHERE [index_level] = 0 AND [alloc_unit_type_desc] = ''IN_ROW_DATA''' , N'@ObjectID int,@IndexID int,@PartitionNumber int' , @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1
由于这种方法,在生成查询时,可以解决竞争对手应用程序中遇到的扫描性能问题。 这可以完成,但是在开发过程中,逐渐出现了新的想法,可以扩展您产品的应用范围。
最初,实现了对使用WAIT_AT_LOW_PRIORITY的支持,然后可以使用DATA_COMPRESSION和FILL_FACTOR重建索引。

该应用程序因以前未计划的功能(例如为专栏作家提供服务)而显得过于拥挤:
SELECT * FROM ( SELECT IndexID = [index_id] , PartitionNumber = [partition_number] , PagesCount = SUM([size_in_bytes]) / 8192 , UnusedPagesCount = ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) / 8192 , Fragmentation = CAST(ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) * 100. / SUM([size_in_bytes]) AS FLOAT) FROM sys.fn_column_store_row_groups(@ObjectID) GROUP BY [index_id] , [partition_number] ) t WHERE Fragmentation >= @Fragmentation AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize
或基于dm_db_missing_index中的信息创建非聚集索引的功能:
SELECT ObjectID = d.[object_id] , UserImpact = gs.[avg_user_impact] , TotalReads = gs.[user_seeks] + gs.[user_scans] , TotalSeeks = gs.[user_seeks] , TotalScans = gs.[user_scans] , LastUsage = ISNULL(gs.[last_user_scan], gs.[last_user_seek]) , IndexColumns = CASE WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NOT NULL THEN d.[equality_columns] + ', ' + d.[inequality_columns] WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NULL THEN d.[equality_columns] ELSE d.[inequality_columns] END , IncludedColumns = d.[included_columns] FROM sys.dm_db_missing_index_groups g WITH(NOLOCK) JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle] JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle] WHERE d.[database_id] = DB_ID()
总结
经过六个月的积极开发阶段,我很高兴这些计划还没有结束,因为我想进一步开发该产品。 下一步是添加功能以搜索重复或未使用的索引,并在SQL Server中实现对服务统计的全面支持。
基于市场上有许多付费解决方案的事实,我想相信由于自由定位,更优化的元数据描述以及对某人有用的各种小东西的存在,该产品肯定会在日常任务中变得有用。
该应用程序的当前版本可以在
GitHub上下载。 来源在同一个地方。