不久前,在关于SObjectizer发行版之一的讨论中,我们被问到:“是否有可能使DSL来描述数据处理管道?” 换句话说,是否可以这样写:
A | B | C | D
并获得一条工作流水线,其中消息从A到B,再到C,再到D。在控制之下,B接收了A所返回的确切类型。 C恰好收到B返回的那种类型。 依此类推。
使用令人惊讶的简单解决方案,这是一项有趣的任务。 例如,这就是管道创建的样子:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
或者,在更复杂的情况下(将在下面讨论):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
在本文中,我们将讨论这种管道DSL的实现。 我们将通过几个使用C ++模板的示例来讨论与stage() , broadcast()和operator|()函数有关的大部分内容。 因此,我希望即使对于不了解SObjectizer的读者来说,它也会很有趣(如果您从未听说过SObjectizer, 这里是此工具的概述)。
关于二手演示的几句话
本文中使用的示例受到了我在SCADA领域的过往(甚至是被遗忘的)经历的影响。
该演示的想法是处理从某些传感器读取的数据。 需要一段时间才能从传感器获取数据,然后必须对该数据进行验证(应忽略不正确的数据)并将其转换为一些实际值。 例如,从传感器读取的原始数据可以是两个8位整数值,并且这些值应转换为一个浮点数。
然后,应将有效值和转换后的值存档,分布在某个位置(例如,在不同的节点上以进行可视化),检查“警报”(如果值超出安全范围,则应进行特殊处理)。 这些操作是独立的,可以并行执行。
与检测到的警报相关的操作也可以并行执行:应启动“警报”(这样,当前节点上的SCADA部分可以对此作出反应),有关“警报”的信息应分发到其他地方(例如:存储到历史数据库和/或在SCADA操作员的显示屏上可视化)。
这种逻辑可以用文本形式表示:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
或者,以图形形式:

这是一个比较人为的示例,但是我想展示一些有趣的东西。 首先是流水线中存在并行阶段broadcast()正是由于这个原因而存在broadcast()操作broadcast() )。 第二个是在某些阶段存在状态。 例如,alarm_detector是有状态阶段。
管道功能
管道是从不同的阶段构建的。 每个阶段都是以下格式的函数或函子:
opt<Out> func(const In &);
或
void func(const In &);
返回void阶段只能用作管道的最后阶段。
阶段被捆绑在一起。 每个下一个阶段都接收上一个阶段返回的对象。 如果上一级返回空的opt<Out>值,则不调用下一级。
有一个特殊的broadcast阶段。 它是由多个管道构成的。 broadcast阶段从上一阶段接收对象,并将其广播到每个辅助管道。
从管道的角度来看, broadcast阶段看起来像以下格式的函数:
void func(const In &);
因为broadcast阶段没有返回值,所以broadcast阶段只能是管道中的最后一个阶段。
为什么管道阶段返回一个可选值?
这是因为需要删除一些传入的值。 例如,如果原始值不正确,那么validate阶段将不返回任何内容,并且没有任何处理意义。
另一个示例:如果当前的可疑值未产生新的警报情况,则alarm_detector阶段不返回任何内容。
实施细节
让我们从与应用程序逻辑相关的数据类型和功能开始。 在讨论的示例中,以下数据类型用于将信息从一个阶段传递到另一阶段:
raw_value的实例将进入管道的第一阶段。 该raw_value包含以raw_measure对象的形式从传感器获取的信息。 然后将raw_value转换为valid_raw_value 。 然后,将valid_raw_value转换为sensor_value并将实际传感器的值形式为calulated_measure 。 如果sensor_value的实例包含可疑值,则将生成suspicious_value的实例。 而且该suspicious_value可以在以后转换为alarm_detected实例。
或者,以图形形式:

现在,我们可以看一下流水线阶段的实现:
只需跳过stage_result_t , make_result和make_empty ,我们将在下一部分中讨论。
我希望这些阶段的代码相当简单。 唯一需要一些其他说明的部分是alarm_detector阶段的实现。
在该示例中,仅在25ms时间窗口中至少有两个suspicious_values时才发出警报。 因此,我们必须记住在alarm_detector阶段前一个suspicious_value实例的时间。 这是因为alarm_detector通过函数调用运算符实现为有状态函子。
阶段返回SObjectizer的类型,而不是std ::可选
我之前告诉过阶段可以返回可选值。 但是代码中没有使用std::optional ,在执行阶段可以看到不同类型的stage_result_t 。
这是因为SObjectizer的某些特定功能在这里发挥了作用。 返回的值将作为消息在SObjectizer的代理(也称为actor)之间分发。 SObjectizer中的每个消息都作为动态分配的对象发送。 因此,我们在此处进行了某种“优化”:而不是返回std::optional然后分配新的消息对象,我们只是分配一个消息对象并返回指向它的智能指针。
实际上, stage_result_t只是SObjectizer的shared_ptr模拟的typedef:
template< typename M > using stage_result_t = message_holder_t< M >;
并且make_result和make_empty只是用于构造stage_result_t辅助函数,内部是否带有实际值:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
为简单起见,可以肯定地说validation阶段可以这样表示:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
但是,由于SObjectizer的特定性,我们不能使用std::shared_ptr而必须处理so_5::message_holder_t类型。 并且我们将具体的隐藏在stage_result_t , make_result和make_empty帮助器后面。
stage_handler_t和stage_builder_t分离
流水线实现的一个重点是阶段处理程序和阶段构建器概念的分离。 这样做是为了简化。 这些概念的出现使我在管道定义中有两个步骤。
第一步,用户描述流水线阶段。 结果,我收到一个stage_t实例,该实例将所有管道阶段保存在其中。
第二步,创建一组基础SObjectizer的代理。 这些代理接收带有上一阶段结果的消息,并调用实际的阶段处理程序 ,然后将结果发送到下一阶段。
但是要创建这组代理,每个阶段都必须有一个阶段构建器 。 阶段构建器可以看作是创建基础SObjectizer代理的工厂。
因此,我们具有以下关系:每个管道阶段都产生两个对象: 阶段处理程序 ,其保存与阶段相关的逻辑;以及阶段构建器 ,其创建基础SObjectizer的代理以在适当的时间调用阶段处理程序 :

阶段处理程序以以下方式表示:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
其中handler_traits_t的定义方式如下:
阶段构建器仅由std::function :
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
帮手类型lambda_traits_t和callable_traits_t
因为阶段可以由自由函数或函子表示(例如, alarm_detector类的实例或表示lambda的匿名编译器生成的类的实例),所以我们需要一些帮助程序来检测阶段的参数和返回值的类型。 为此,我使用了以下代码:
我希望对于具有C ++知识的读者来说,这段代码是可以理解的。 如果没有,请随时在评论中问我,我将很高兴详细解释lambda_traits_t和callable_traits_t背后的逻辑。
阶段(),广播()和运算符|()函数
现在,我们可以查看主要的管道构建功能。 但是在此之前,有必要查看一下模板类stage_t的定义:
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
这是一个非常简单的结构,仅stage_bulder_t实例。 模板参数未在stage_t内部stage_t ,那么为什么要在此处使用它们?
它们是在管道阶段之间进行类型兼容性的编译时检查所必需的。 我们很快就会看到。
让我们看一下最简单的管道构建函数, stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
它接收一个实际的阶段处理程序作为单个参数。 它可以是指向函数,lambda函数或函子的指针。 由于callable_traits_t模板后面的“模板魔术”,自动推导出了舞台的输入和输出类型。
在内部创建了一个阶段构建器的实例,该实例作为stage()函数的结果返回到一个新的stage_t对象中。 实际的阶段处理程序由阶段构建器 lambda捕获,然后将其用于构建基础SObjectizer的代理(我们将在下一节中讨论)。
下一个要检查的函数是operator|() ,它将两个阶段连接在一起并返回一个新阶段:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
解释operator|()的逻辑的最简单方法是尝试绘制图片。 假设我们有表达式:
stage(A) | stage(B) | stage(C) | stage(B)
该表达式将以这种方式转换:

在这里,我们还可以看到编译时类型检查的工作方式: operator|()的定义要求第一阶段的输出类型是第二阶段的输入。 如果不是这种情况,则不会编译代码。
现在,我们来看一下最复杂的管道构建功能,即broadcast() 。 该函数本身非常简单:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
普通阶段和广播阶段之间的主要区别在于,广播阶段必须拥有辅助阶段构建者的向量。 因此,我们必须创建该矢量并将其传递到广播级的主级构建器中。 因此,我们可以在broadcast()函数内的lambda捕获列表中看到对collect_sink_builders的调用:
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
如果我们查看collect_sink_builder我们将看到以下代码:
编译时类型检查在这里也起作用:这是因为对类型为move_sink_builder_to的调用move_sink_builder_to显式参数化。 这意味着以collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...)进行的调用将导致编译错误,因为编译器禁止调用move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) 。
我还可以注意到,由于broadcast()的子管道的数量在编译时是已知的,因此我们可以使用std::array而不是std::vector ,并且可以避免一些内存分配。 但是这里std::vector只是为了简单起见。
阶段与SObjectizer的代理/ mbox之间的关系
实施管道背后的想法是为每个管道阶段创建一个单独的代理。 代理接收传入的消息,将其传递到相应的阶段处理程序 ,分析结果,如果结果不为空,则将结果作为传入消息发送到下一个阶段。 可以通过以下序列图进行说明:

必须至少简短地讨论一些与SObjectizer相关的事情。 如果您对此类详细信息不感兴趣,则可以跳过以下部分,直接查看结论。
合作社是一组一起工作的代理商
代理不是单独引入到SObjectizer中,而是以名为coops的组引入。 合作社是一组应该一起工作的特工,如果缺少该组特工中的一个,则没有继续工作的感觉。
因此,将代理引入SObjectizer的过程就像创建coop实例,用适当的代理填充该实例,然后在SObjectizer中注册该coop。
因此, 阶段构建器的第一个参数是对新合作社的引用。 此合作社是在make_pipeline()函数中创建的(下面讨论),然后由舞台构建器填充并进行注册(再次在make_pipeline()函数中)。
留言框
SObjectizer实现了几个与并发相关的模型。 演员模型只是其中之一。 因此,SObjectizer可以与其他参与者框架有很大的不同。 区别之一是消息的寻址方案。
SObjectizer中的消息不是针对参与者,而是消息框 (mbox)。 参与者必须从mbox订阅消息。 如果演员从mbox订阅了特定的消息类型,它将收到该类型的消息:
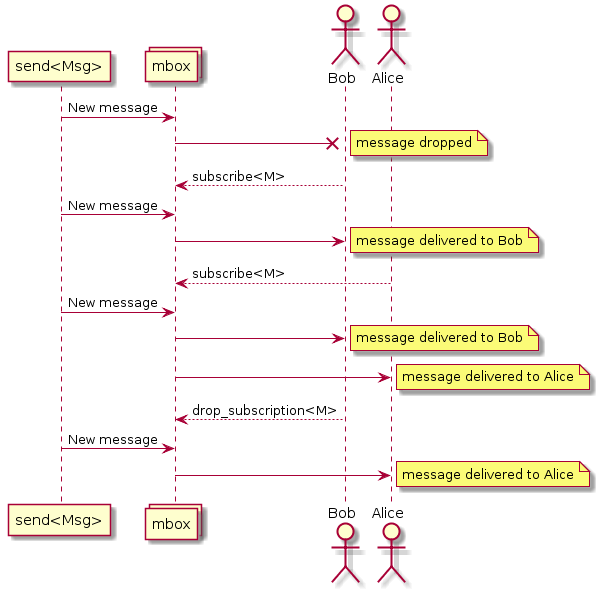
这一事实至关重要,因为有必要将消息从一个阶段发送到另一个阶段。 这意味着每个阶段都应该有其mbox,并且上一个阶段应该知道mbox。
SObjectizer中的每个actor(aka代理)都有直接的mbox 。 该mbox仅与所有者代理关联,并且不能被任何其他代理使用。 为阶段创建的代理的直接mbox将用于阶段交互。
该SObjectizer的特定功能规定了一些管道实现细节。
首先是舞台构建器具有以下原型的事实:
mbox_t builder(coop_t &, mbox_t);
这意味着阶段构建器将接收下一个阶段的mbox,并应创建一个新代理,该代理会将阶段的结果发送到该mbox。 阶段构建器应返回新代理的mbox。 该mbox将用于创建上一阶段的代理。
第二个事实是,阶段代理已按备用订单创建。 这意味着如果我们有管道:
stage(A) | stage(B) | stage(C)
首先创建阶段C的代理,然后将其mbox用于阶段B的代理创建,然后将B阶段代理的mbox用于创建阶段A的代理。
还需要注意的是, operator|()不会创建代理:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
operator|()创建一个仅调用其他构建器但不引入其他代理的构建器。 因此,对于这种情况:
stage(A) | stage(B)
仅将创建两个代理(用于A阶段和B阶段),然后在operator|()创建的阶段构建器中将它们链接在一起。
没有用于broadcast()实现的代理
实现广播阶段的一种明显方法是创建一个特殊代理,该代理将接收传入的消息,然后将该消息重新发送到目标mbox列表。 在描述的管道DSL 的第一个实现中使用了这种方式。
但是我们的配套项目so5extra现在具有mbox的一个特殊变体:广播一个。 该mbox完全满足此处的要求:它接收一条新消息,并将其传递到一组目标mbox。
因此,无需创建单独的广播代理,我们可以仅使用so5extra的广播mbox:
实施阶段代理
现在我们来看看阶段代理的实现:
如果您了解SObjectizer的基础知识,那将是微不足道的。 如果不是,那么很难用几句话来解释(所以请随时在评论中提问)。
a_stage_point_t代理的主要实现创建对In类型消息的预订。 当此类消息到达时,将调用阶段处理程序 。 如果阶段处理程序返回实际结果,则将结果发送到下一个阶段(如果存在该阶段)。
当相应的阶段是终端阶段而没有下一个阶段时,还有a_stage_point_t的版本。
a_stage_point_t的实现可能看起来有些复杂,但是请相信我,它是我编写的最简单的代理之一。
make_pipeline()函数
现在该讨论最后一个管道构建函数make_pipeline() :
template< typename In, typename Out, typename... Args > mbox_t make_pipeline(
这里没有魔术,也没有惊喜。 我们只需要为管道的底层代理创建一个新的合作社,通过调用顶级阶段构建器将该合作社填充到代理中,然后将该合作社注册到SObjectizer中即可。 就这样
make_pipeline()的结果是make_pipeline()最左侧(第一级make_pipeline()的mbox。 该mbox应该用于将消息发送到管道。
仿真与实验
因此,现在我们有了应用程序逻辑的数据类型和函数,以及将这些函数链接到数据处理管道的工具。 让我们看一下结果:
int main() {
如果运行该示例,我们将看到以下输出:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
可以用
但是,我们的管道的各个阶段似乎相继工作,不是吗?
是的,是的。 这是因为所有管道代理都绑定到默认的SObjectizer的调度程序。 该调度程序仅使用一个工作线程来处理所有代理的消息处理。
但这很容易改变。 只需将另一个参数传递给make_pipeline()调用即可:
这将创建一个新的线程池,并将所有管道代理绑定到该池。 每个代理将独立于其他代理由池服务。
如果运行修改后的示例,我们将看到类似的内容:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
因此,我们可以看到管道的不同阶段并行工作。
但是是否可以走得更远,并有能力将阶段绑定到不同的调度程序?
是的,这是可能的,但是我们必须为stage()函数实现另一个重载:
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
This version of stage() accepts not only a stage handler but also a dispatcher binder. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
In that case stages archiving , distribution , alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer , try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us , and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
PS。 The source code for that example can be found in that repository .