如果您发布的版本速度快,自动化且可靠,那么您可能不会阅读本文。
以前,我们的发布过程是手动,缓慢且有错误的。
在sprint之后,我们使sprint失败了,因为我们没有时间为下一个Sprint Review制作和布局功能。 我们讨厌发布。 他们经常持续三到四天。
在本文中,我们将介绍“停线”实践,该实践有助于我们集中精力解决布局问题。 在短短三个月内,我们设法将部署率提高了10倍。 今天,我们的部署是完全自动化的,并且发布整体仅需4-5个小时。
停止生产线。 团队发明的实践
我记得我们是如何想到“停止生产线”的。 在一般回顾中,我们讨论了导致无法实现冲刺目标的长时间发布。 我们的一位开发人员建议:
-[谢尔盖]让我们限制发行量。 这将帮助我们测试,修复错误并更快地部署。
-[Dima]我们可以对进行中的工作施加限制(在制品限制)吗? 例如,一旦我们完成10个任务,我们就停止开发。
-[开发人员]但是任务的大小可能有所不同。 这不会解决大量发行的问题。
-[I]让我们根据发布的持续时间而不是任务数量来引入限制。 如果发布花费太多时间,我们将停止开发。
我们决定,如果发布持续超过48小时,那么我们将打开闪光灯并停止所有团队在整体业务功能方面的工作。 所有从事整体工作的团队都应停止开发,并专注于推动当前版本的销售或消除延迟发布的原因。 当该发行版被卡住时,创建新功能毫无意义,因为它们仍将很快推出。 目前,即使在单独的分支中,也禁止编写新代码。
我们还在简单的活动挂图上介绍了“停止线路板”。 在它上面,我们编写了一些任务,这些任务要么有助于推送当前版本,要么有助于避免其延迟的原因。
当然,停止生产线不是一个容易的决定,但是这种做法是迈向持续交付和真正的DevOps的重要一步。
Dodo IS的历史(技术序言)Dodo IS主要是在.Net框架上编写的,其UI在React / Redux上,放在jQuery上,并穿插在Angular中。 Swift和Kotlin上仍然有适用于iOS和Android的应用程序。
Dodo IS体系结构是继承的整体组件和大约20种微服务的混合体。 我们在单独的微服务中开发新的业务功能,这些微服务可以在每次提交时(连续部署),或者根据请求(业务需要时)至少每五分钟(连续交付)进行部署。
但是,我们仍然有很大一部分业务逻辑是在整体架构中实现的。 整体是最难部署的。 在每个发行版之前,组装整个系统(构建工件重约1 GB),运行单元测试和集成测试以及执行手动回归需要花费时间。 发行本身也很慢。 每个国家都有自己的整体副本,因此我们必须为12个国家部署12个副本。
持续集成(CI)是一种实践,可帮助开发人员不断按工作顺序维护代码,逐步扩展产品,在具有许多自动测试的CI版本的支持下至少每天将其集成到一个分支中。
当多个团队使用相同的产品并实践CI时,总部门中的变更数量迅速增长。 您积累的更改越多,此更改将包含更多隐藏的缺陷和潜在问题。 这就是团队更喜欢频繁部署变更的原因,这导致了持续交付(CD)的实践是CI之后的下一个逻辑步骤。
CD练习使您可以随时在产品中部署代码。 此实践基于部署管道-一组自动或手动步骤,用于检查产品在运送到产品的过程中的增量。
我们的部署管道如下所示:
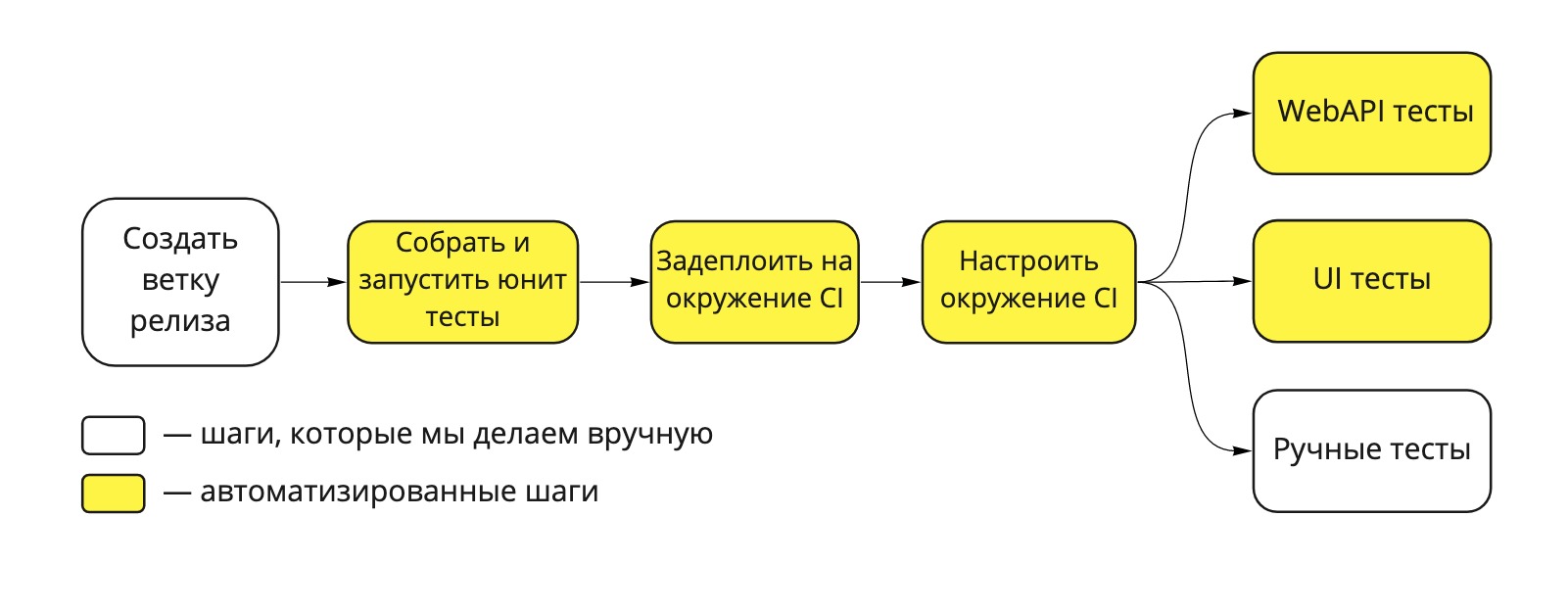
图 1. Dodo IS部署管道
让我们快速发布:从问题到改编的“停止生产线”实践
缓慢释放的痛苦。 他们为什么那么长? 分析方法
极限编程(XP)有一个黄金法则:如果有什么不好的地方,请尽可能多地做。 我们的发行历来都是痛苦的。 我们花了几天的时间来部署测试环境,还原数据库,运行测试(通常进行几次),弄清为什么会失败,修复错误并最终发布。
Sprint持续2周,发布持续3天。 为了能够在周五的Sprint评论之前发布它,您应该以一种很好的方式在周一开始发布。 这意味着我们正在努力仅冲刺50%的时间。 如果我们每天都可以释放,那么工作的工作时间将增长到80-90%。
我们的平均发布时间通常需要两到三天。 最初,有六个团队在常规dev分支中处理代码(随着公司的发展,团队数量增加到了九个)。 在发布之前,我们对发布分支进行了早午餐。 在测试和回归该分支时,团队将继续在常规dev分支中发展。 在发行分支销售之前,团队将编写大量代码。
增量中的更改越多,不同团队所做的更改相互影响的可能性就越大,这意味着必须更仔细地测试增量,并且释放它所花费的时间也就越多。 这是一个自我强化的周期(见图2)。 版本(“马”版本)中的更改越多,回归时间越长。 回归时间越长,两次发布之间的时间就越多,团队在下一次发布之前所做的更改就越多。 我们称其为“马生马”。 以下CLD图(因果循环图)说明了这种关系:
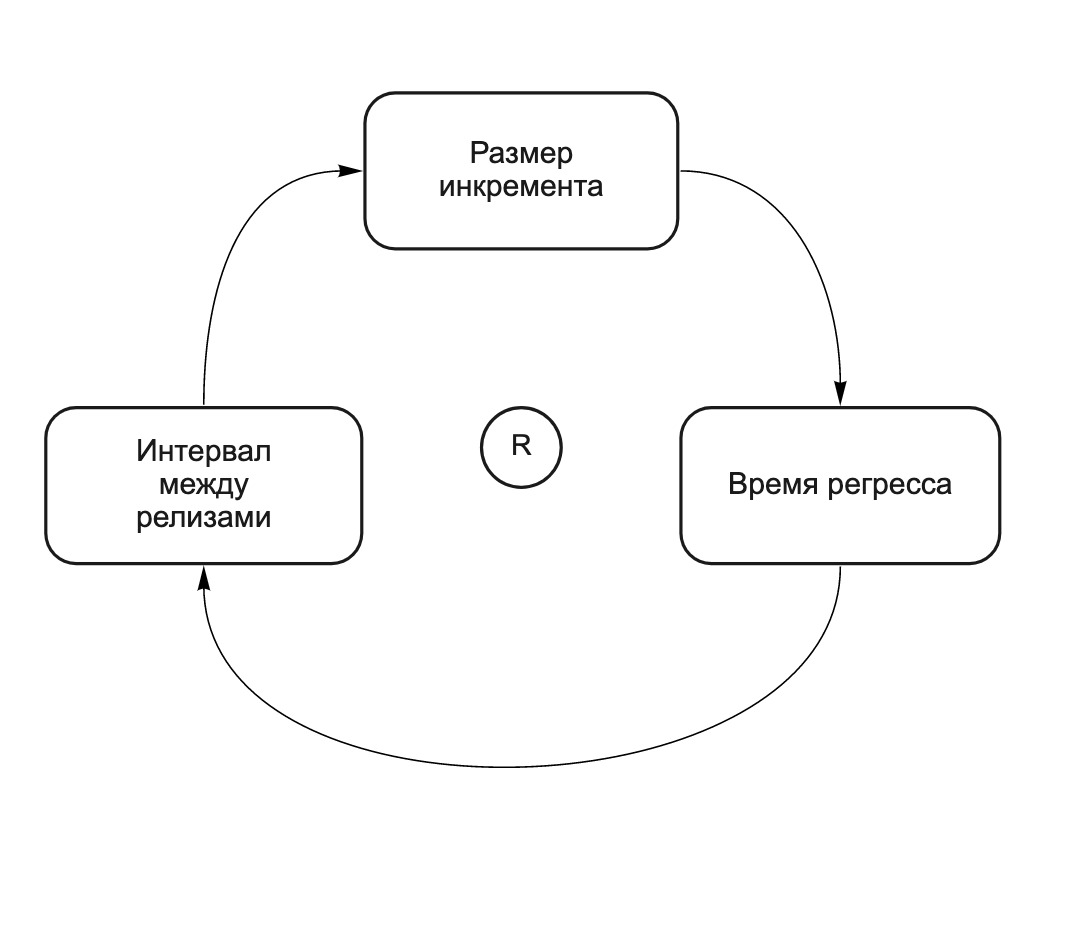
图 2. CLD图:长发布导致更长的发布
使用QA命令进行回归自动化
构成发布的步骤- 环境设置。 我们恢复了销售基础(675 GB),加密个人数据并清理RabbitMQ队列。 数据加密是非常耗时的操作,大约需要1个小时。
- 运行自动测试。 某些UI测试不稳定,因此我们不得不多次运行它们直到通过。 修复闪烁测试需要大量关注和纪律。
- 手动验收测试。 一些团队更愿意在代码正式发布之前获得最终的认可。 这可能需要几个小时。 如果他们发现错误,我们会给团队两个小时的时间来修复它们,否则他们必须回滚更改。
- 在产品上部署。 由于每个国家/地区都有Dodo IS的单独副本,因此部署过程会花费一些时间。 在第一个国家/地区完成部署后,我们会查看日志一段时间,查找错误,然后继续在其他国家/地区进行部署。 整个过程通常需要大约两个小时,但有时可能需要更长的时间,特别是如果您必须回滚发行版时。
最初,我们决定摆脱手动回归测试,但是通往这一目标的道路漫长而艰难。 两年前,Dodo IS手动回归持续了整整一周。 然后,我们有一个完整的手动测试人员团队,他们一周又一周地在10个国家/地区测试相同的功能。 您不会羡慕这种工作。
2017年6月,我们成立了质量检查小组。 团队的主要目标是使最重要的业务运营自动化:接收订单和制造产品。 一旦我们有了足够的测试以开始信任我们,我们便完全放弃了手动测试。 但这只是在我们开始回归自动化1.5年后才发生。 之后,我们解散了质量检查团队,质量检查团队加入了开发团队。
但是,UI测试具有明显的缺点。 由于它们取决于数据库中的实际数据,因此必须配置此数据。 一个测试可能破坏另一测试的数据。 测试可能失败,不仅是因为某些逻辑被破坏,还可能是因为网络速度较慢或缓存中的数据过时。 我们不得不花费很多精力来摆脱闪烁测试,并使它们可靠且可重复。
停止生产线的第一步。 #IReleaseEveryDay Initiative
我们创建了一个#IReleaseEveryDay志趣相投的社区,并集思广益如何加快部署流程。 最初的动作如下:
- 通过淘汰重复的和不必要的测试,我们大大减少了UI测试的数量。 这将测试时间减少了数十分钟;
- 由于数据库的初步恢复和数据加密,我们大大减少了建立环境的时间。 例如,现在我们在晚上创建数据库的备份副本,并且一旦发布开始,我们将在几秒钟内将测试环境切换到备份数据库。
由于上述解决方案,我们减少了平均发布时间,但仍然令人讨厌。 现在该进行系统更改了。
如果...
我们引入了以下规则:如果发布持续超过48小时,那么我们将打开闪光灯,并停止所有团队在整体业务方面的工作。 所有从事整体工作的团队都应停止开发,并专注于将当前发行版推向销售阶段,或消除延迟发行的原因。
当该发行版被卡住时,创建新功能毫无意义,因为它们仍将很快推出。 目前,即使在单独的分支中,也禁止编写新代码。 马丁·福勒(Martin Fowler)的连续交付文章中描述了这一原则:“如果布局出现问题,您的团队应该在开发新功能之前优先考虑这些问题的解决方案。”
随行闪光
在“停止生产线”期间,办公室中的橙色闪光灯会亮起。 来到Dodo IS的开发人员所在的三楼的任何人都可以看到此视觉信号。 我们决定不让开发人员因警报声而疯狂,而只留下令人讨厌的闪烁灯光。 如此构思。 发布有问题时,我们如何感到舒适?

图 3.眨眼停线
团队抵抗和小破坏
最初,Stop the Line喜欢所有团队,因为这很有趣。 小时候每个人都很高兴,并布置了应急灯的照片。 但是当它连续燃烧3-4天时,就变得不那么有趣了。 有一天,其中一个团队违反了规则,并在Stop the Line期间将代码上传到dev分支,以保存其sprint目标。 违反规则最容易使您无法工作。 这是进行业务功能的一种快速而肮脏的方法,而忽略了系统问题。
作为Scrum Master,我不能忍受违反规则的行为,因此我在一般回顾中提出了这个问题。 我们进行了艰难的交谈。 大多数团队都同意规则适用于所有人。 我们同意,即使每个团队都不遵守规则,也必须遵守规则。 同时,您还可以更改规则而无需等待下一次回顾。
什么没有按预期进行?
最初,开发人员并不专注于使用部署流水线解决系统问题。 当发布卡住时,他们倾向于开发不受“停止在线”规则约束的微服务,而不是帮助消除造成延迟的原因。 微服务是好的,但是整体的问题无法解决。 为了解决这些问题,我们引入了Stop The Line积压。
一些解决方案是解决问题而不是解决问题的快速解决方案。 例如,许多测试是通过增加超时或添加重传来修复的。 这些测试之一进行了21分钟。 该测试在没有索引的表中查找最近创建的员工。 程序员没有纠正请求的逻辑,而是增加了3次重试。 结果,慢速测试变得更加慢。 当Stop The Line提出一个专注于测试问题的所有者团队时,在接下来的三个冲刺中,他们设法加快了2-3倍的测试速度。
练习停线后球队的表现如何?
以前,只有一个团队在发布方面遇到问题-一个支持发布的问题。 团队试图尽快摆脱这种令人不快的职责,而不是进行长期的改进。 例如,如果对测试环境的测试下降了,则可以在本地重新启动它们;如果测试通过,则继续发布。 随着Stop The Line的推出,团队现在有时间稳定测试。 我们重写了测试准备代码,用API测试替换了一些UI测试,并消除了不必要的超时。 现在,几乎所有测试都可以在任何环境下快速通过。
以前,团队没有系统地参与技术债务。 现在,我们在“停产线”期间分析了积压的技术改进。 例如,我们重写了.Net Core上的测试,这使我们能够在Docker中运行它们。 在Docker中运行测试使我们能够使用Selenium Grid来并行化测试并进一步减少其执行时间。
以前,团队依靠质量检查团队进行测试,而基础架构团队则进行部署。 现在除了他们之外没有人可以依靠。 团队自己测试并发布生产中的代码。 这些是真实的,不是伪造的DevOps。
停线方法的演变
在一般的Sprint回顾中,我们正在审查实验。 在接下来的一些回顾中,我们对“停线”规则进行了许多更改,例如:
- 发布频道。 有关当前版本的所有信息都在单独的Slack频道中。 该频道包含其变更包含在版本中的所有团队。 在此频道上,发行人寻求帮助。
- 发布杂志。 负责发布的人员记录其操作。 这有助于找到延迟发布的原因并发现模式。
- 五分钟的规则。 在宣布“停止生产线”之后的五分钟内,团队代表聚集在应急灯周围。
- 积压停止生产线。 墙上有一个活动挂图,上面有一个活动挂图的活动挂图-线路停止时团队可以执行的任务列表。
- 不考虑冲刺的最后一个星期五。 比较两个发行版是不公平的,例如,一个发行于星期一开始,另一个发行于星期五开始。 第一小组可以花整整两天的时间来支持发布,而第二小组在星期五(Sprint审查,团队回顾,一般回顾)和下周一(大会和Team Sprint计划)将有很多活动,因此星期五团队有较少的时间来进行发布。发布支持。 周五发布将比周一停止的可能性更大。 因此,我们决定从公式中排除冲刺的最后一个星期五。
- 消除技术债务。 几个月后,团队决定停下来可以解决技术债务,而不仅仅是加快部署流程。
- 所有者停下来。 一名开发商自愿成为Stop The Line的所有者。 他沉迷于发布延迟的原因,并管理Stop the Line积压。 生产线停止时,所有者可以吸引任何团队参与“停止生产线”积压工作中的各个要素。
- 验尸。 Stop the Line的所有者在每次停止后都会举行一次验尸。
损失成本
由于停止生产线,我们尚未实现几个冲刺目标。 业务代表对我们的进展不太满意,并在Sprint评论中提出了很多问题。 遵循透明性原则,我们讨论了“停线”是什么,以及为什么您应该等待更多的冲刺。 在每个Sprint评论中,我们都向团队和利益相关者展示了由于停线而造成的损失。 成本计算为停机期间开发团队的总工资。
•十一月-2106 000羽
•十二月-503504羽
•1月-1 219 767羽
•2月-2 002 278羽
•3月-0页。
•4月-0页。
•五月-361138羽
这种透明性会带来健康的压力,并促使团队立即解决部署管道问题。 看着这些数字,我们的团队知道没有免费的东西,而且每条Stop the Line都会给我们带来很多收益。
结果
实际上,“停止生产线”实践将一个自我强化循环(图2)转换为两个平衡循环(图4)。 停线可以帮助我们专注于改善部署流程,因为部署流程太慢了。 在短短的4个冲刺中,我们:
- 下降了12个稳定版本
- 减少30%的构建时间
- 稳定的UI和API测试。 现在,它们可以在所有环境中传播,甚至可以在本地传播。
- 摆脱闪烁的测试
- 开始信任我们的测试。
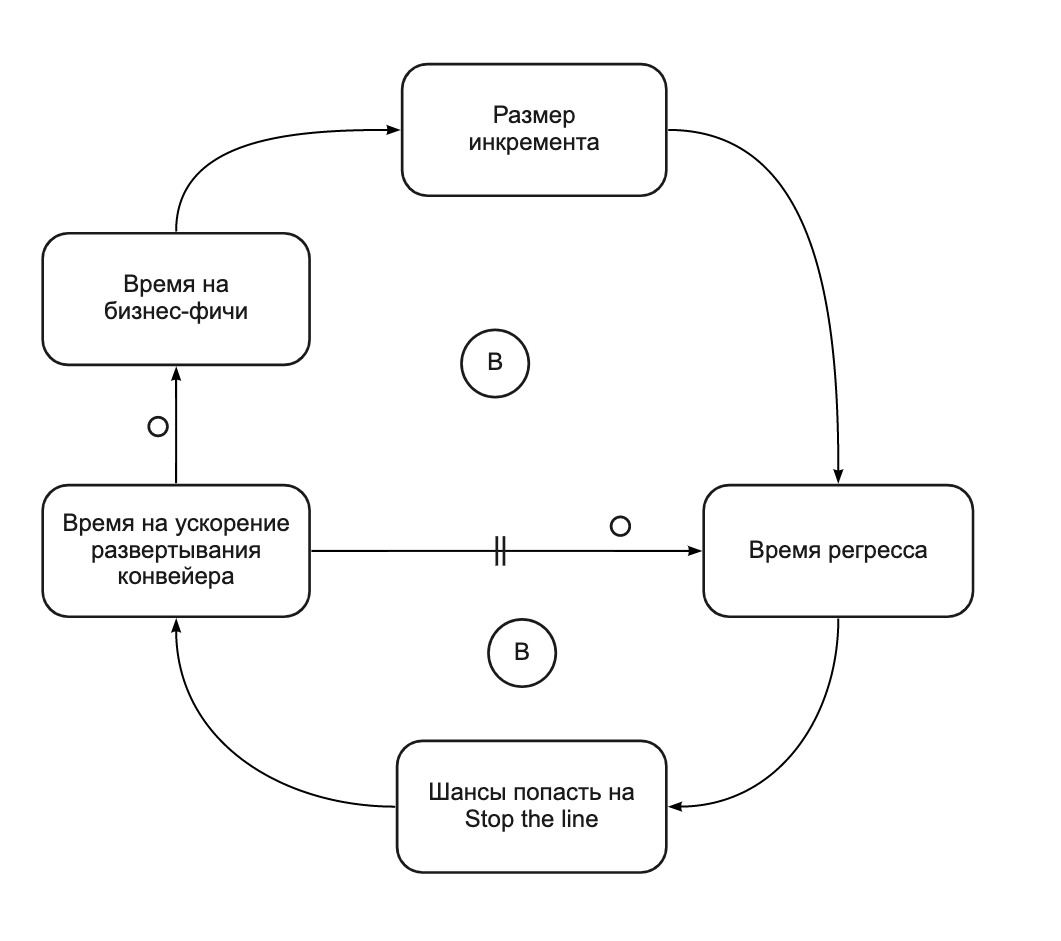
图 4. CLD图表:停止线余额释放时间
Scrum Master的结论
Stop The Line是开发团队自己发明的强大解决方案的典型示例。 Scrum Master不能仅仅采用并为团队带来出色的新实践。
只有团队自己提出实践,实践才能奏效。这需要有利的条件:信任的气氛和实验的文化。当然,需要业务的信任和支持,这只有在完全透明的情况下才有可能。反馈(例如与所有团队代表进行定期的一般性回顾)有助于发明,实施和修改新的实践。随着时间的流逝,停止生产线的做法应该会自杀。我们停止线路的次数越多,我们对部署管道的投入就越多,发布变得越稳定,越快,停止的原因就越少。最后,除非我们决定将阈值从48小时降低到24小时,否则生产线将永远不会停止。但是,由于这种做法,我们极大地改善了发行程序。这些团队不仅在开发方面积累了经验,而且还在产品的快速交付方面获得了经验。这些是真正的DevOps。接下来是什么?
我不知道 也许我们会很快放弃这种做法。团队将决定。但是很明显,我们将继续朝着持续交付和DevOps迈进。有一天,我每天释放几次巨石的梦想将实现。